Command Palette
Search for a command to run...
F5-E2 TTS Clone n'importe Quel Son En Seulement 3 Secondes
Date
Balises
URL du document
Licence
CC BY-NC-SA 3.0
GitHub
1. Introduction au tutoriel

Ce tutoriel comprend deux modèles d'utilisation de démonstration, à savoir F5-TTS et E2 TTS.
F5-TTS est un système de synthèse vocale (TTS) haute performance, développé en open source conjointement en 2024 par l'Université Jiao Tong de Shanghai, l'Université de Cambridge et l'Institut de recherche automobile Geely (Ningbo). Il repose sur une méthode de génération non autorégressive utilisant la correspondance de flux, combinée à la technologie de transformation par diffusion (DiT). Des articles de recherche associés sont disponibles. F5-TTS : un conteur de fées qui simule un discours fluide et fidèle grâce à la correspondance de flux Ce système génère rapidement une parole naturelle, fluide et fidèle à partir du texte original grâce à un apprentissage automatique sans supervision. F5-TTS prend en charge la synthèse multilingue, notamment le chinois et l'anglais, et peut synthétiser efficacement la parole de textes longs. De plus, F5-TTS intègre un contrôle des émotions, ajustant l'expression émotionnelle de la parole synthétisée en fonction du contenu du texte, et permet de régler la vitesse de lecture. Le système a été entraîné sur un vaste ensemble de données de 100 000 heures, démontrant d'excellentes performances et une grande capacité de généralisation. Les principales fonctionnalités de F5-TTS incluent le clonage vocal automatique, le contrôle de la vitesse et des émotions, la synthèse de textes longs et la prise en charge multilingue. Ses principes techniques reposent sur la correspondance de flux, le Diffusion Transformer (DiT), l'amélioration de la représentation textuelle par ConvNeXt V2, une stratégie d'échantillonnage Sway et une conception système de bout en bout. F5-TTS possède un large éventail d'applications, notamment les livres audio, les assistants vocaux, l'apprentissage des langues, la diffusion d'actualités et le doublage de jeux, offrant de puissantes capacités de synthèse vocale pour diverses utilisations commerciales et non commerciales.
E2 TTS, acronyme de « Embarrassingly Easy Text-to-Speech » (Synthèse vocale incroyablement facile), est un système de synthèse vocale (TTS) avancé qui atteint un niveau de naturel et de similarité avec la voix humaine grâce à un processus simplifié. Le principe fondamental d'E2 TTS réside dans son caractère non autorégressif : il peut générer la séquence vocale complète en une seule fois, sans génération par étapes, ce qui améliore considérablement la vitesse de génération tout en conservant une qualité vocale optimale. Articles de recherche associés :… E2 TTS : TTS Zero-Shot entièrement non autorégressif et incroyablement simpleE2 TTS, accepté par SLT 2024, transforme le texte saisi en une séquence de caractères avec des marqueurs de remplissage. Un générateur de spectrogrammes Mel, basé sur la correspondance de flux, est ensuite entraîné pour le remplissage audio. Contrairement à de nombreux travaux antérieurs, il ne requiert aucun composant supplémentaire (par exemple, modèles de durée, conversion caractères-phonèmes) ni technique complexe (par exemple, recherche d'alignement monotone). Malgré sa simplicité, E2 TTS offre des performances de synthèse vocale zéro-shot de pointe, comparables voire supérieures à celles de travaux antérieurs tels que Voicebox et NaturalSpeech 3. La simplicité d'E2 TTS permet également une grande flexibilité dans la représentation des entrées.
该教程支持如下模型和功能: 2 个模型检查点: F5-TTS E2 TTS 3 个功能:单人语音生成(Batched TTS): 根据上传的音频进行文本生成。 双人语音生成(Podcast Generation):根据双人音频模拟双人对话。多种语音类型生成(Multiple Speech-Type Generation):可根据同一讲话人不同情绪下的音频,生成不同情绪的音频。
Ce tutoriel utilise une seule carte RTX 5090 comme ressource.
2. Exemples de projets
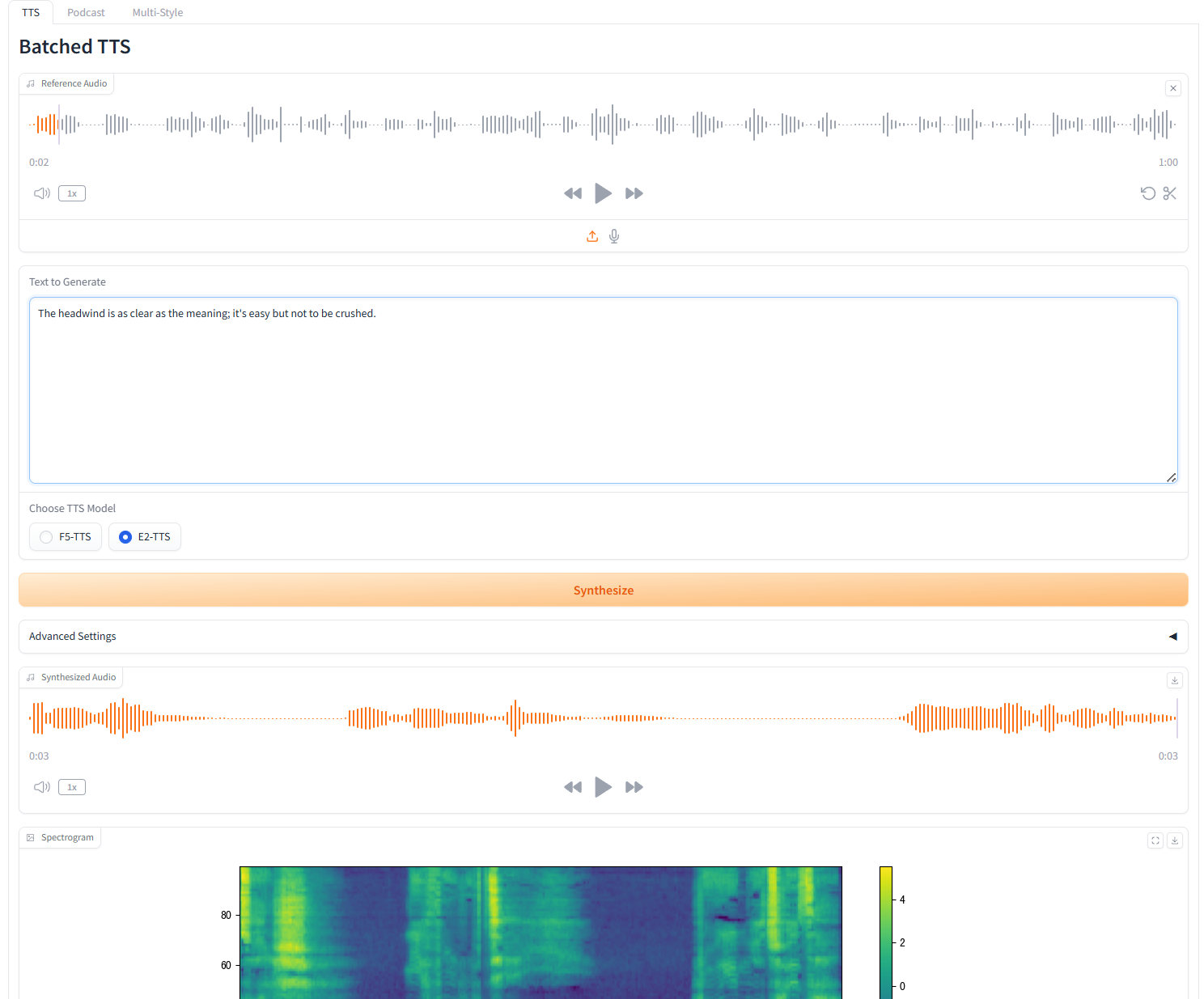
1. TTS par lots
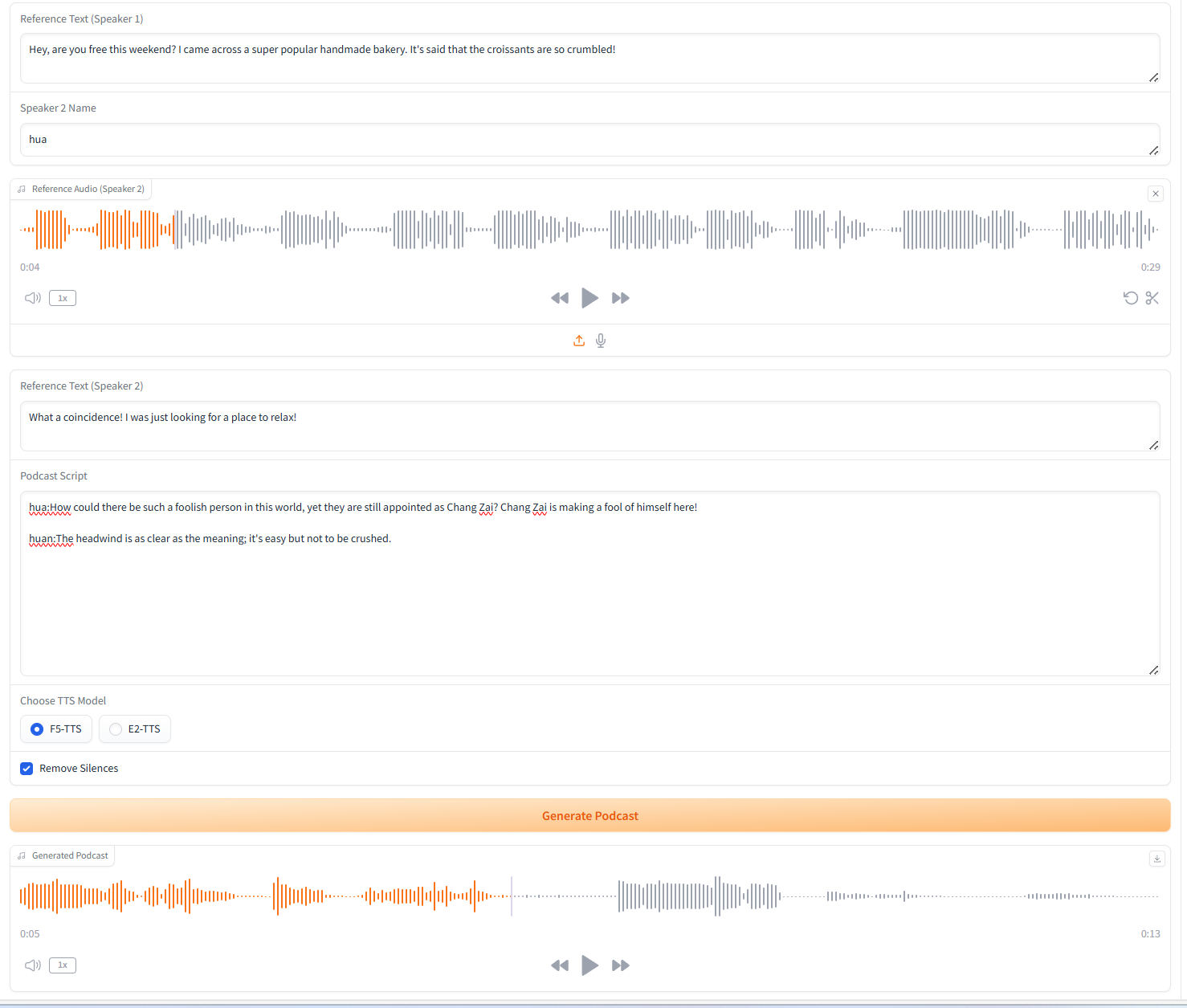
2. Génération de podcasts
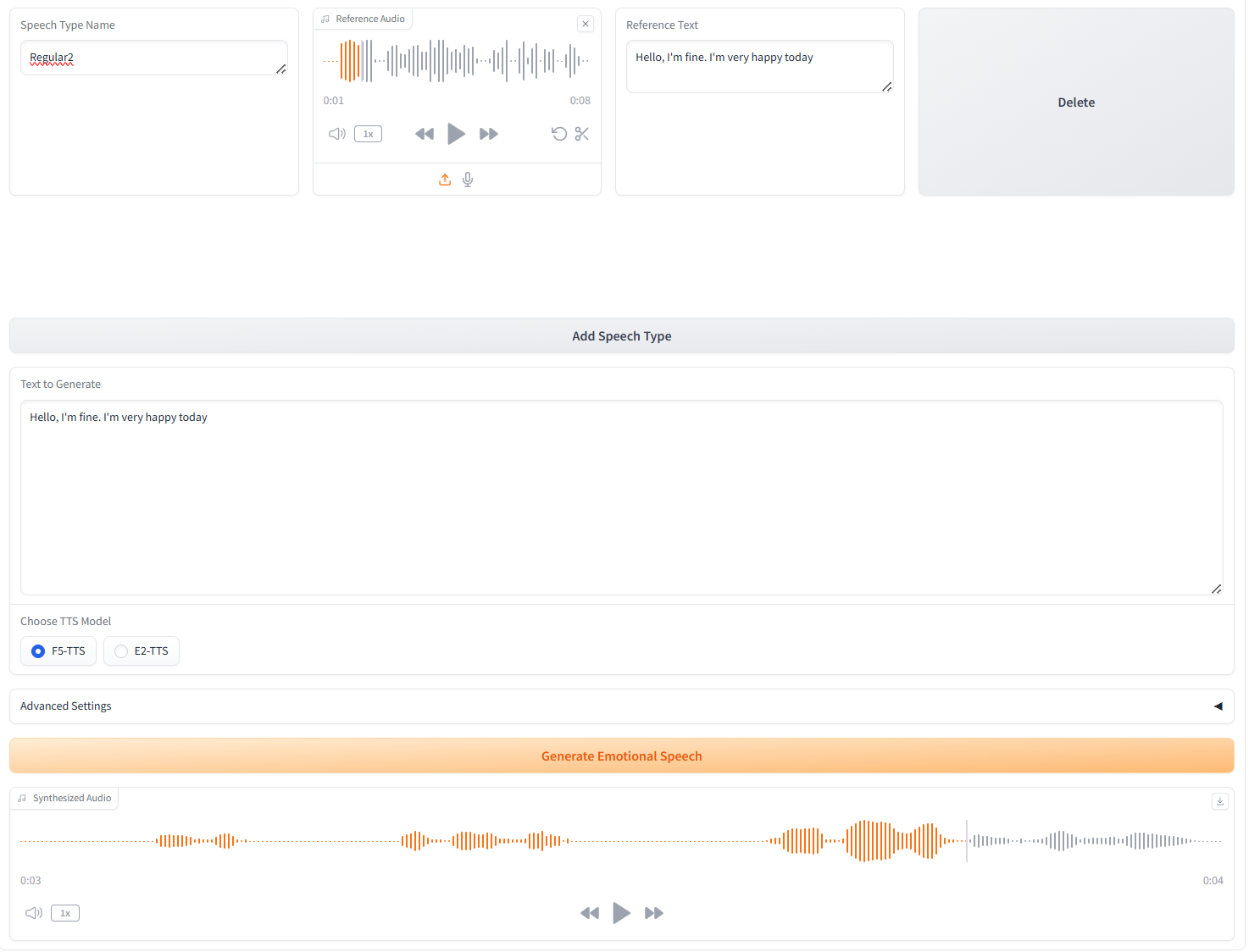
3. Génération de plusieurs types de discours
3. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
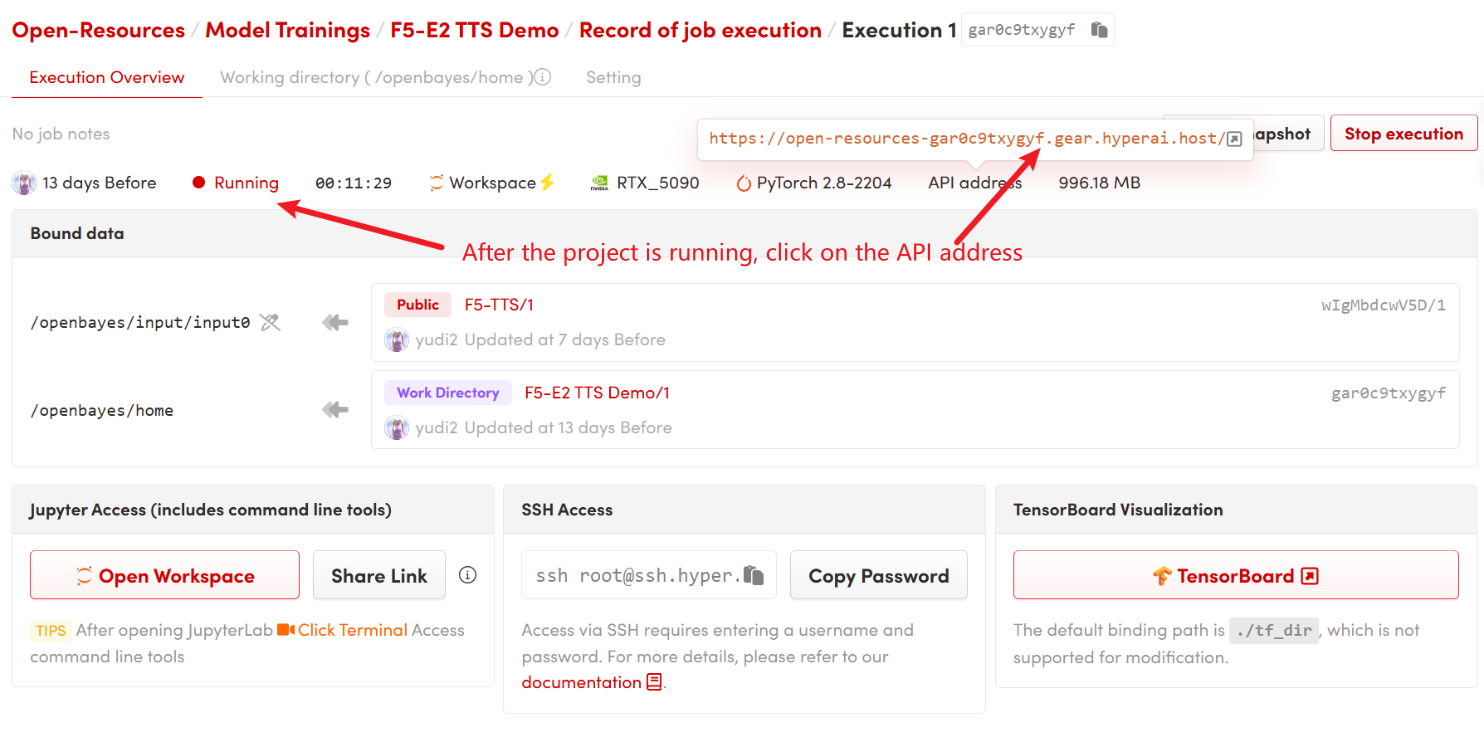
2. Étapes d'utilisation
Si le message « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Ce modèle étant volumineux, veuillez patienter environ 9 minutes, puis actualiser la page.
Lorsque vous utilisez le navigateur Safari, l'audio peut ne pas être lu directement et doit être téléchargé avant la lecture.
1. TTS par lots
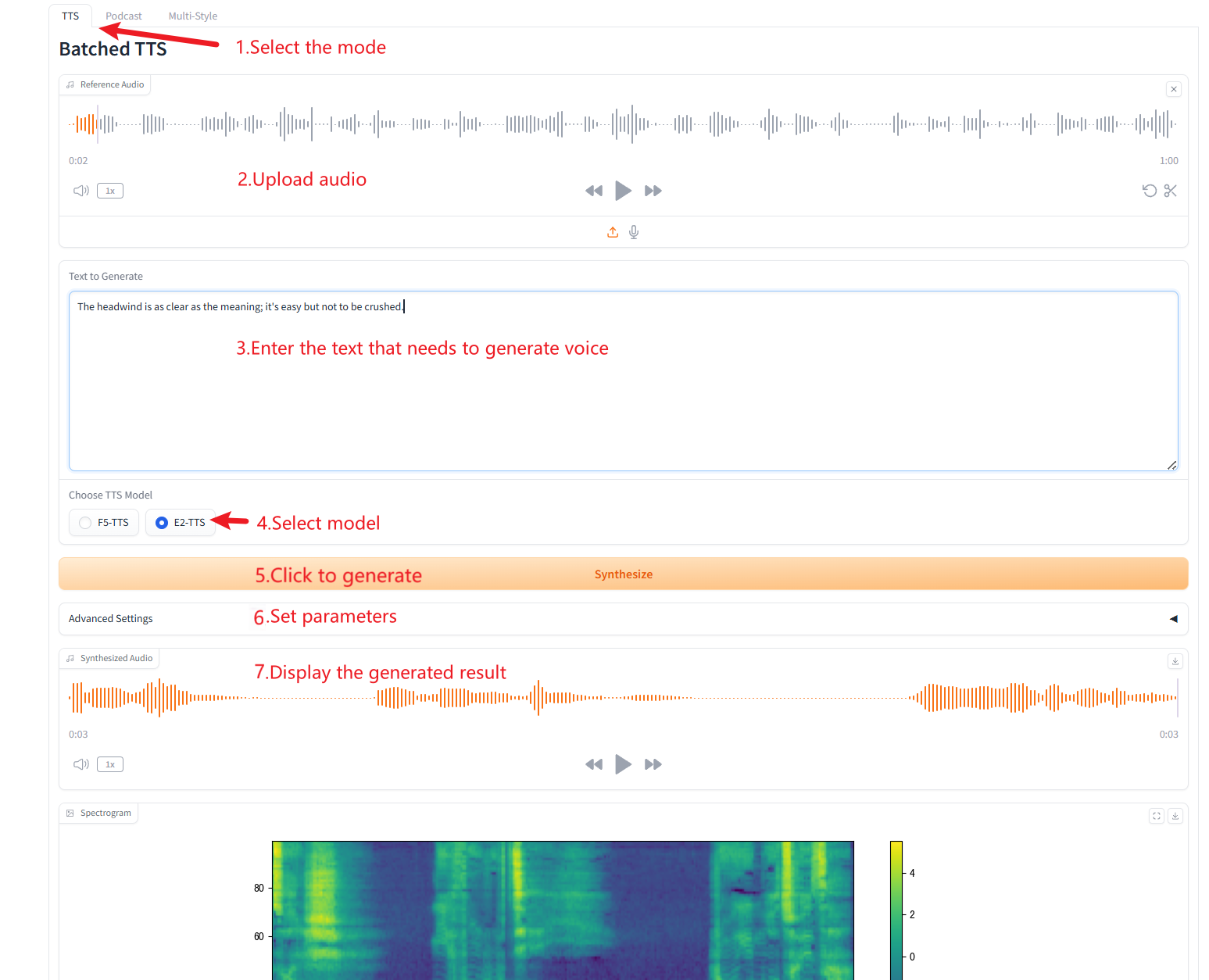
Description des paramètres
- Texte de référence: Laissez vide pour transcrire automatiquement l'audio de référence. Si vous saisissez du texte, il remplacera la transcription automatique.
- Supprimer les silences:Ce modèle a tendance à produire du silence, en particulier sur les fichiers audio plus longs. Nous pouvons supprimer manuellement le silence si nécessaire. Veuillez noter qu'il s'agit d'une fonctionnalité expérimentale et qu'elle peut produire des résultats étranges. Cela augmentera également le temps de construction.
- Mots séparés personnalisés: Saisissez les mots personnalisés à diviser, séparés par des virgules. Laissez vide pour utiliser la liste par défaut.
- vitesse:Contrôler la vitesse de la parole générée
2. Génération de podcasts
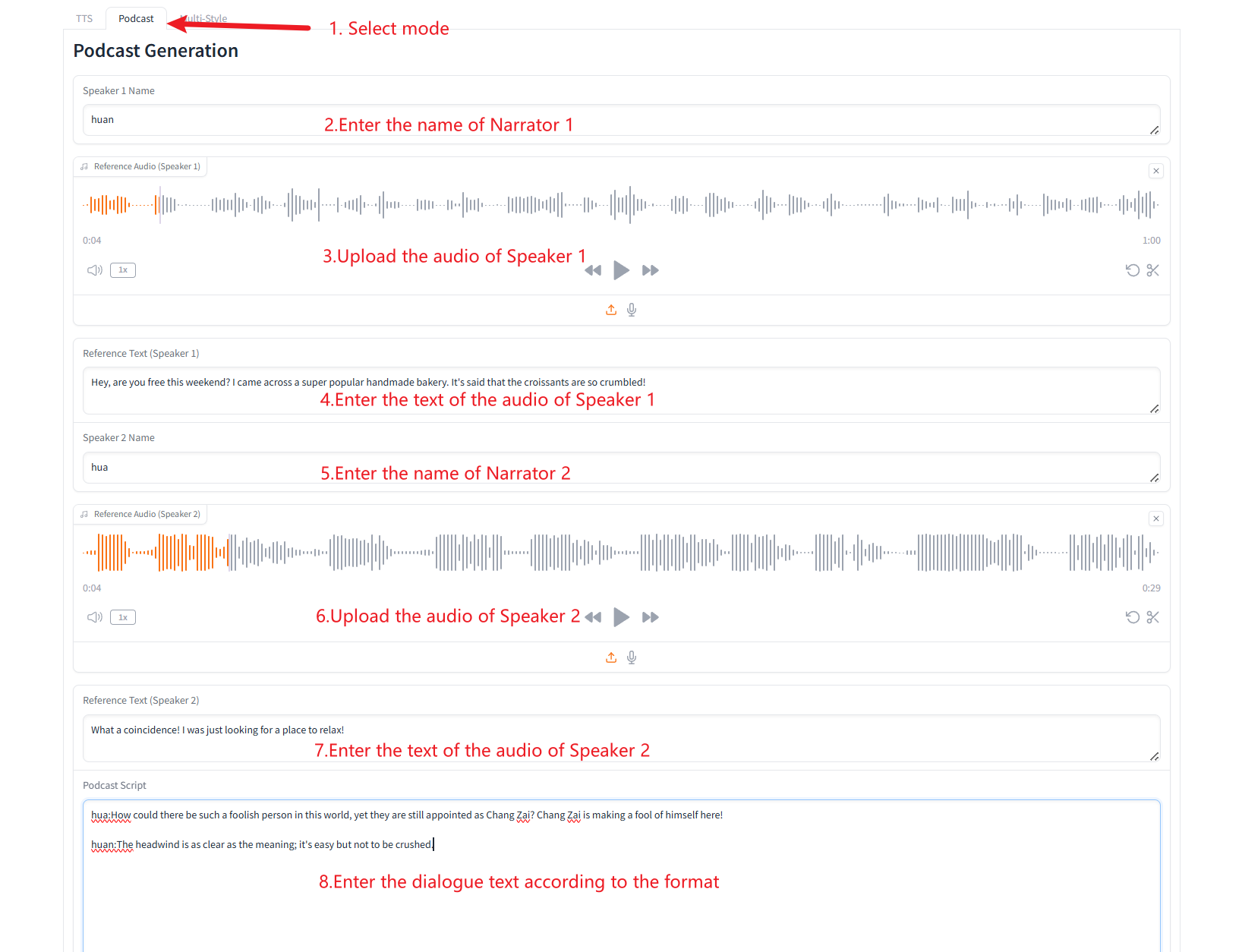
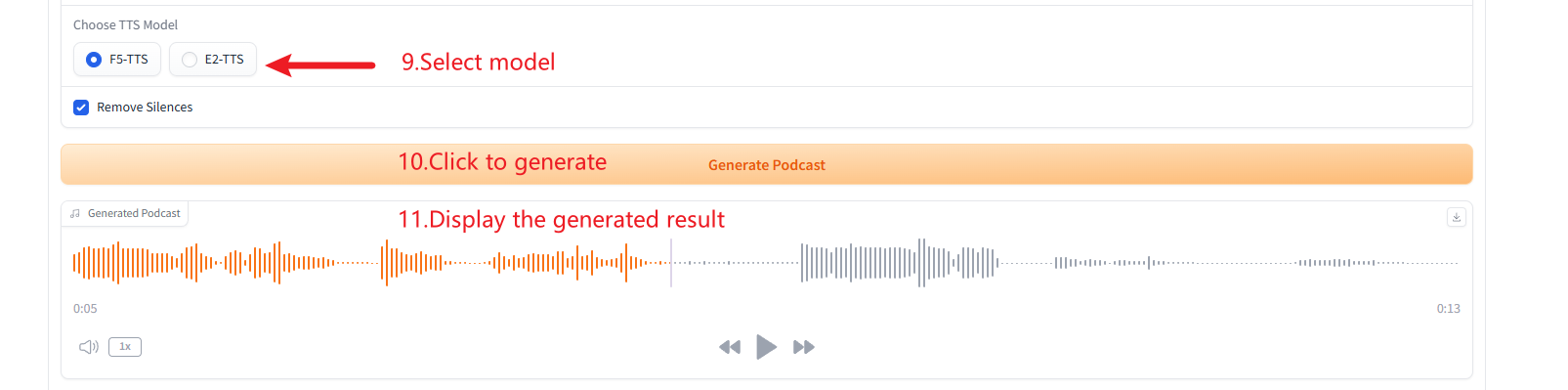
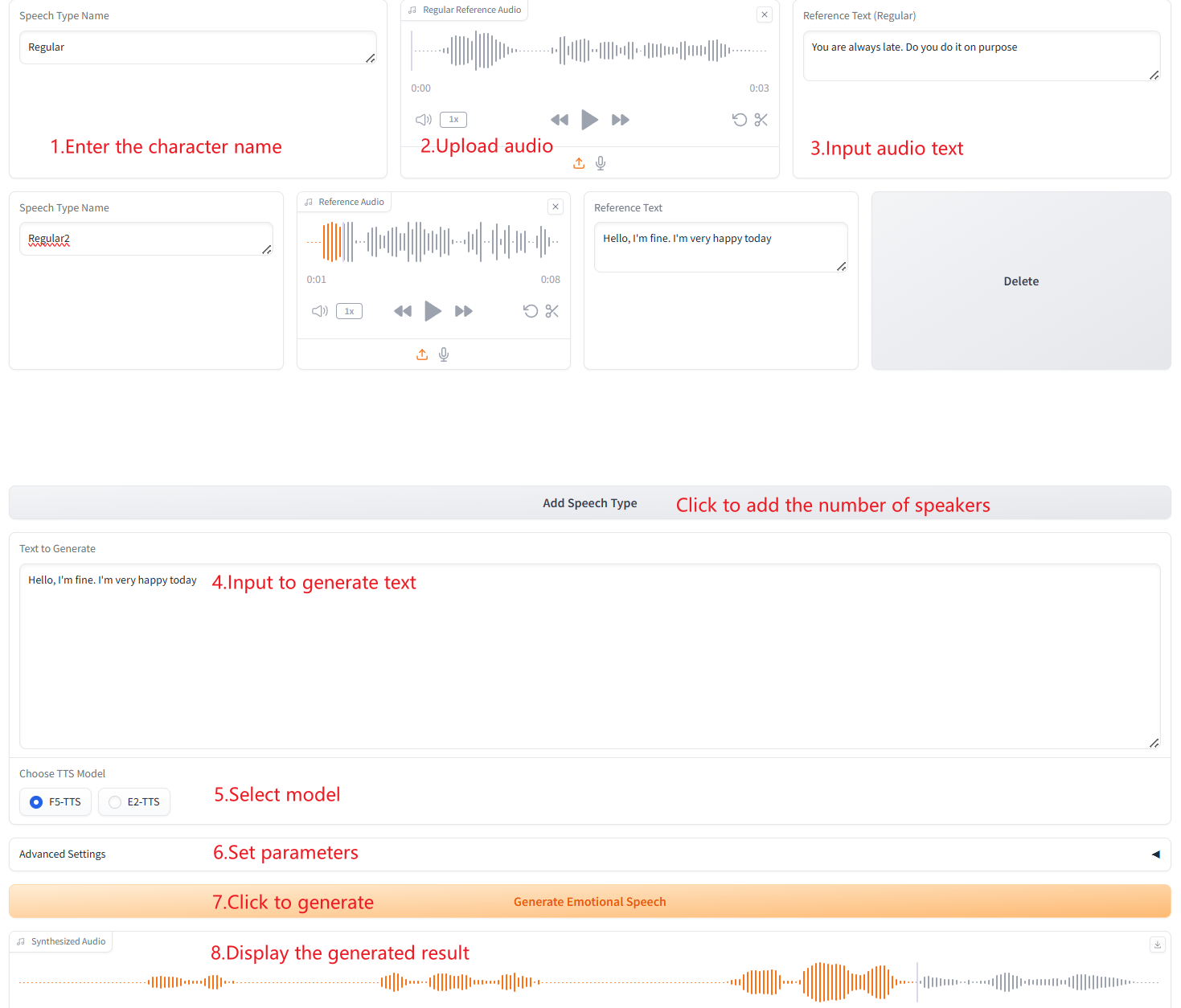
3. Génération de plusieurs types de discours
Informations sur la citation
@article{chen-etal-2024-f5tts,
title={F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching},
author={Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen},
journal={arXiv preprint arXiv:2410.06885},
year={2024},
}Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.