Command Palette
Search for a command to run...
pi0.7 : un modèle de fondation robotique généraliste et pilotable présentant des capacités émergentes
pi0.7 : un modèle de fondation robotique généraliste et pilotable présentant des capacités émergentes
Résumé
Nous présentons un nouveau modèle de fondation robotique, nommé π0.7, capable d'offrir des performances robustes « out-of-the-box » dans une large gamme de scénarios. π0.7 peut suivre des instructions linguistiques diversifiées dans des environnements inédits, notamment pour des tâches multi-étapes impliquant divers appareils de cuisine. Il permet également une généralisation cross-embodiment en zero-shot — par exemple, en permettant à un robot de plier du linge sans avoir jamais été exposé à cette tâche auparavant — et peut accomplir des tâches complexes, telles que l'utilisation d'une machine à expresso dès sa sortie de boîte, avec un niveau de performance comparable à celui de modèles beaucoup plus spécialisés et affinés par RL (Reinforcement Learning).L'idée principale derrière π0.7 repose sur l'utilisation d'un conditionnement de contexte diversifié durant l'entraînement. Ces informations de conditionnement, intégrées dans le prompt, permettent de piloter précisément le modèle afin qu'il exécute de nombreuses tâches selon différentes stratégies. Le modèle n'est pas seulement conditionné par une commande linguistique décrivant l'action à accomplir, mais aussi par des informations multimodales supplémentaires décrivant la manière ou la stratégie d'exécution, incluant des métadonnées sur la performance de la tâche ainsi que des images de sous-objectifs (subgoal images). Cela permet à π0.7 d'exploiter des données extrêmement diversifiées.
One-sentence Summary
pi0.7 is a steerable generalist robotic foundation model utilizing diverse context conditioning with multimodal prompt information to precisely steer task strategies, delivering strong out-of-the-box performance in unseen environments and zero-shot cross-embodiment generalization for tasks like laundry folding while matching specialized RL-finetuned models on challenging tasks such as operating an espresso machine.
Key Contributions
- The paper introduces π0.7, a robotic foundation model designed to deliver strong out-of-the-box performance across a wide range of scenarios without task-specific post-training.
- The method utilizes diverse context conditioning during training by augmenting language commands with strategy metadata and subgoal images to resolve ambiguity in diverse datasets.
- Evaluation results demonstrate zero-shot cross-embodiment generalization and the ability to perform challenging tasks at a level matching specialized RL-finetuned models.
Introduction
Physical intelligence seeks to establish generalist capabilities in robotics similar to large language models, but prior vision-language-action models lack compositional generalization and often require task-specific fine-tuning. Training on diverse datasets often leads models to average out different strategies, resulting in suboptimal performance. The authors introduce pi_0.7, a steerable generalist robot foundation model that leverages diverse context conditioning to resolve ambiguity in mixed-quality data. By enriching prompts with detailed language, subgoal images, and strategy metadata, the model learns to compose skills effectively without fine-tuning, enabling zero-shot cross-embodiment transfer and robust performance on complex dexterous tasks.
Dataset

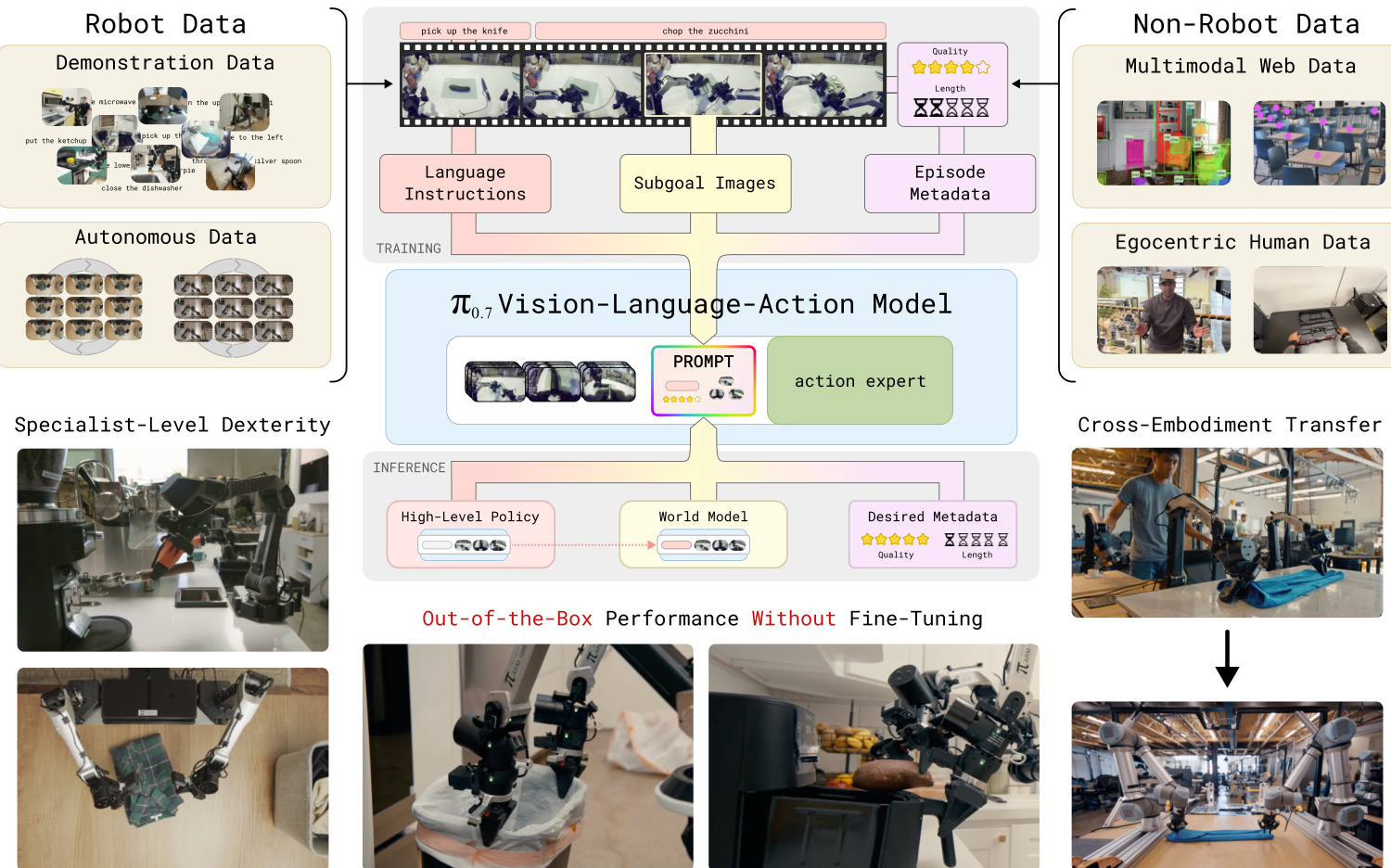
- Composition and Sources: The authors aggregate demonstration data from diverse robot platforms (static, mobile, single, and bimanual) operating in lab, home, and wild environments. The mixture also includes autonomous data from policy evaluations, human interventions, open-source robot datasets, egocentric human videos, and auxiliary web data for visual question answering and object prediction.
- Suboptimal Data Strategy: Departing from classic pipelines, the dataset intentionally includes lower quality demonstrations, failure episodes, and trajectories from prior model versions. This approach enables the model to distill capabilities from RL-trained specialists and improves robustness across varied states.
- Metadata Processing: Episode metadata is constructed to label task execution attributes. Speed is discretized into 500-step intervals, quality receives a score from 1 to 5, and human annotators identify mistake segments within action sequences.
- Training and Usage: Context modalities including instructions, images, and metadata undergo dropout during training to ensure flexible prompting. At inference, the model uses ground-truth metadata to condition performance on desired speed, quality, and accuracy.
Method
The π0.7 model is a Vision-Language-Action (VLA) foundation model designed for generalist robot manipulation. It builds upon the π0.6 architecture and the MEM memory system, extending them with multi-modal context conditioning. The model consists of a 4B-parameter VLM backbone initialized from Gemma 3, which includes a 400M-parameter SigLIP vision encoder, and a separate 860M-parameter action expert. The total parameter count is approximately 5B.
The authors leverage a flow matching objective for the action expert to predict continuous action chunks. The VLM backbone processes visual observations and language inputs, while the action expert attends to these activations to generate robot commands. This separation allows for fast inference at runtime while maintaining stable training for the backbone via discrete cross-entropy loss on FAST tokens, a technique known as Knowledge Insulation.
Refer to the architecture diagram below for a detailed view of the model components and data flow.
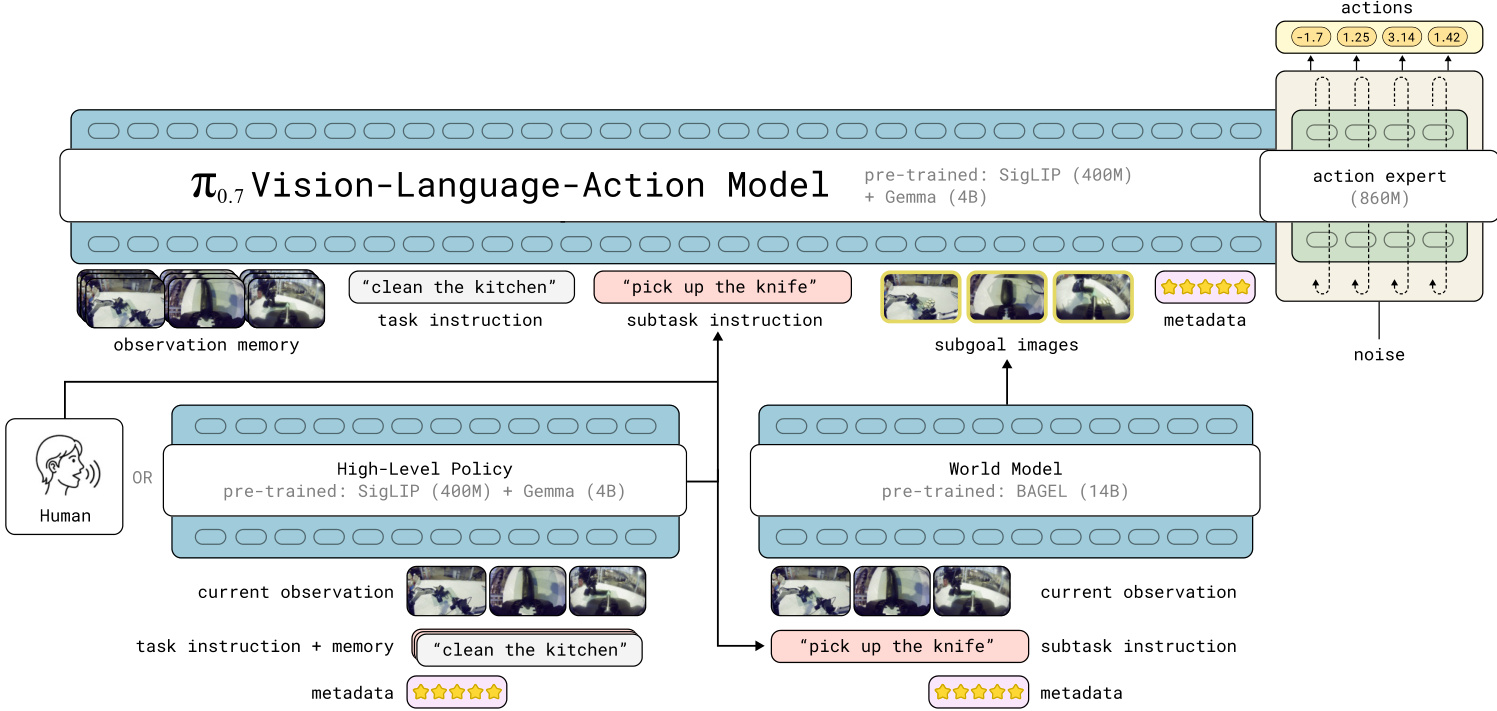
A key innovation in π0.7 is the expansion of the context prompt Ct beyond simple language instructions. The model accepts a rich set of inputs including multi-view observation memory, task instructions, subtask instructions, episode metadata, and subgoal images. This multi-modal prompting enables the model to learn from diverse and heterogeneous datasets, including suboptimal behaviors and failures.
The system integrates a high-level policy and a world model to generate these contextual elements at runtime. The high-level policy produces semantic subtask instructions, while the world model generates subgoal images that depict the desired near-future state of the scene. These subgoal images provide spatial grounding that language alone may lack.
Refer to the system overview below illustrating how robot and non-robot data feed into the training pipeline and how the model operates during inference.
During training, the model is exposed to a combination of real future images and generated subgoal images. To handle the variability in image quality and delay, the authors employ a specific sampling scheme where real images are sampled from future timesteps or generated by the world model. The training objective maximizes the log-likelihood of the action chunk given the observations and context:
maxθED[logπθ(at:t+H∣ot−T:t,Ct)]
The model utilizes a block-causal masking scheme where observation and subgoal tokens use bidirectional attention, while text tokens use causal attention. This structure is visualized in the attention mask diagram below.
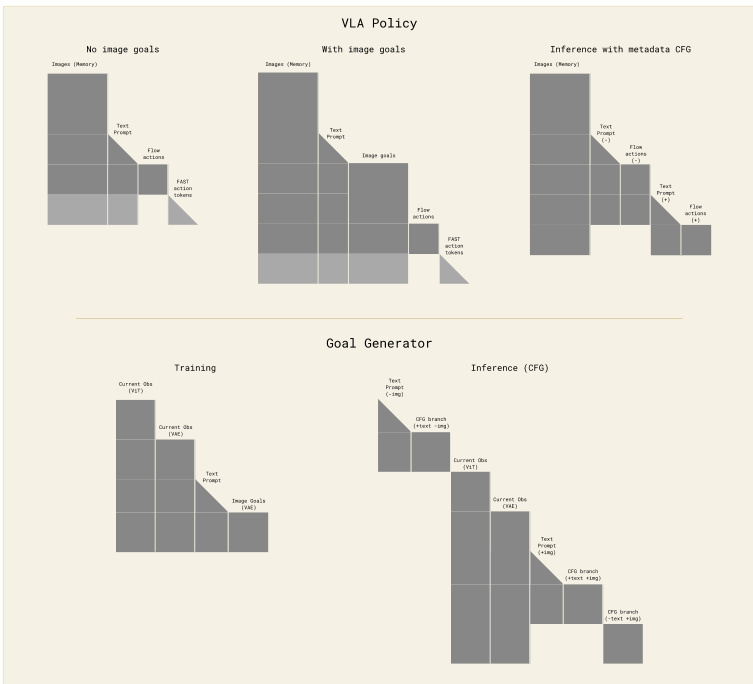
At inference time, the model supports Classifier-Free Guidance (CFG) on the episode metadata to elicit specific behaviors such as higher speed or quality. The subtask instructions and subgoal images are refreshed whenever the semantic intent changes or after a fixed time interval. The following sequence demonstrates the model executing a complex task involving an air fryer using step-by-step verbal coaching and subtask instructions.

Experiment
The evaluation assesses the π0.7 model across diverse robot platforms and tasks, specifically testing out-of-the-box dexterity, instruction following, cross-embodiment transfer, and compositional generalization. Results demonstrate that π0.7 matches specialized fine-tuned models on complex manipulation tasks without post-training and successfully transfers skills to unseen robot morphologies by adapting manipulation strategies. Furthermore, the model exhibits superior language following capabilities that allow it to overcome dataset biases and perform new long-horizon tasks through verbal coaching, while effectively leveraging large, mixed-quality datasets for improved generalization.