Command Palette
Search for a command to run...
Ingénierie de boucle : Le manuel Anthropic pour concevoir des systèmes qui interrogent vos agents
Ingénierie de boucle : Le manuel Anthropic pour concevoir des systèmes qui interrogent vos agents
Peter Steinberger Boris Cherny Addy Osmani
Résumé
Au cours des deux dernières années, une série de termes liés à l'« ingénierie XX » a suivi le rythme des sorties de modèles. Cette note examine le plus récent d’entre eux, l’ingénierie par boucle (Loop Engineering), un concept qui a émergé indépendamment en juin 2026 chez Peter Steinberger, Boris Cherny et Addy Osmani, et qui a été formalisé par écrit par ce dernier. Contrairement à l’ingénierie de prompt, de context ou de harness, l’ingénierie par boucle n’apprend pas au praticien à mieux effectuer le travail ; elle le déleste totalement de cette tâche. Nous définissons ce terme, le positionnons comme une quatrième couche au-dessus du harness, et décomposons un cycle unique de la boucle en cinq mouvements — découverte, transfert, vérification, persistance et planification — ainsi qu’en six composantes qui les implémentent. Nous accordons une attention particulière à la séparation générateur/évaluateur : empiriquement, un agent chargé de noter ses propres résultats a tendance à les louer, tandis que l’ajustement d’un évaluateur indépendant et sceptique est nettement plus maniable que la tentative de rendre un générateur critique à l’égard de son propre travail. Nous passons en revue trois boucles en opération réelle, allant de la triade matinale d’un ingénieur unique à la pipeline entreprise de Stripe qui fusionne plus de 1 300 pull requests générés par machine chaque semaine, et nous cataloguons quatre coûts qui s’accumulent silencieusement : la dette de vérification, la dégradation de la compréhension, l’abandon cognitif et l’explosion du nombre de tokens. Nous concluons par une recette concrète pour construire une première boucle. L’affirmation centrale est que les boucles rendent la génération presque gratuite et font du jugement la ressource rare ; une même boucle, construite par deux personnes différentes, peut produire des résultats opposés.
One-sentence Summary
In this note, Peter Steinberger, Boris Cherny, and Addy Osmani introduce Loop Engineering as a fourth layer above harness engineering that removes practitioners from performing work by designing self-prompting agent loops, decomposing each turn into discovery, handoff, verification, persistence, and scheduling, crucially separating generator from evaluator because agents grading their own output tend to self-praise, and surveying real-world loops from a personal morning triage to Stripe’s pipeline merging over 1,300 machine-written pull requests per week, demonstrating that loops make generation nearly free while judgment becomes the scarce resource and the same loop can produce opposite outcomes in different hands.
Key Contributions
- The note defines loop engineering as a fourth layer above harness engineering, decomposing a single loop turn into five moves (discovery, handoff, verification, persistence, scheduling) and six constituent parts.
- It introduces a generator/evaluator separation, empirically showing that agents overpraise their own outputs and that an independently tuned skeptical evaluator is far more tractable than making a generator self-critical.
- The note surveys three real-world loops, catalogs four hidden costs (verification debt, comprehension rot, cognitive surrender, token blowout), provides a concrete build recipe, and establishes that loops make generation nearly free, concentrating engineering value into judgment as the scarce resource.
Introduction
The authors examine a new paradigm called Loop Engineering, which shifts the practitioner from directly prompting AI coding agents to designing autonomous systems that prompt themselves. This matters because earlier approaches—prompt, context, and harness engineering—all kept a human in the loop, limiting scalability and requiring constant attention. The key limitation of prior work is that the human must act as the clock and decision-maker, unable to step away. The authors’ main contribution is a formal definition of loop engineering, a decomposition of a loop’s turn into five moves (discovery, handoff, verification, persistence, and scheduling), and an emphasis on the generator/evaluator split to maintain judgment while automating generation.
Method
Theauthors propose a hierarchical framework for engineering AI agents, culminating in a self-running loop architecture. This framework stacks four distinct layers, each expanding the scope of concern. As shown in the figure below, the stack progresses from Prompt Engineering at the base, through Context and Harness Engineering, to Loop Engineering at the top.
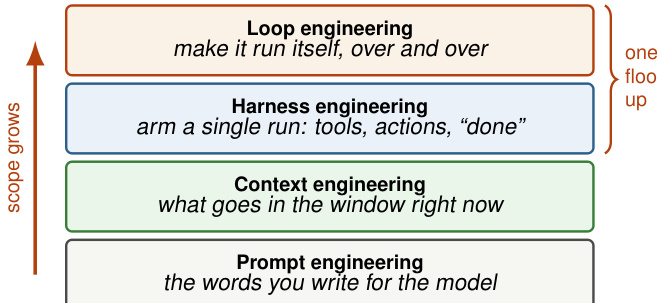
Prompt Engineering manages the wording for a single exchange. Context Engineering curates the model's field of view. Harness Engineering equips a single run with tools and actions. Loop Engineering automates the entire process, allowing the system to wake on a schedule, spawn sub-agents, and feed its own output back as input for subsequent rounds.
A functional loop executes a concrete cycle of five moves rather than spinning idly. As illustrated in the diagram below, these moves form a continuous turn that feeds the next iteration.
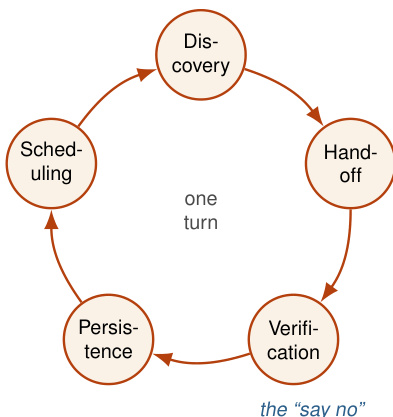
First, Discovery identifies work worth doing, such as reading CI failures, allowing the agent to find its own tasks. Second, Handoff moves the task to an isolated environment, like a git worktree, to prevent collisions during parallel execution. Third, Verification checks the result, serving as the critical mechanism to reject poor output. Fourth, Persistence saves state to disk so the loop survives context window clearing. Finally, Scheduling triggers the next turn automatically.
To enable these moves, the architecture relies on six structural parts. Automations trigger the loop based on time or events. Worktrees provide isolation for parallel agents. Skills store permanent project knowledge to reduce intent debt. Connectors link the loop to external tools via protocols like MCP. Sub-agents split the writer from the judge. Memory ensures state persists across days outside the conversation window.
The most critical architectural decision involves the verification module. The authors note that agents tend to praise their own work, leading to a nodding loop where errors accumulate. To solve this, the framework leverages a Maker-Checker principle. As shown in the figure below, the architecture structurally splits the agent into a Generator and an Evaluator.
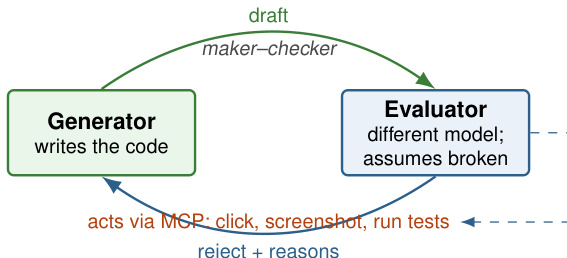
The Generator writes the code. The Evaluator, often a different model instructed to assume the code is broken, reviews it. Crucially, the Evaluator acts by running tests or inspecting the DOM rather than just reading code.
The stop condition is managed by a fresh model checking if a specific goal is met. The code snippet below demonstrates this logic, where a small fast model checks the condition after each turn.

For large-scale reliability, the authors describe the Stripe Minions pipeline. This architecture interleaves deterministic gates with probabilistic LLM steps. As depicted in the pipeline diagram, the process begins with a human trigger, followed by a deterministic orchestrator assembling context.
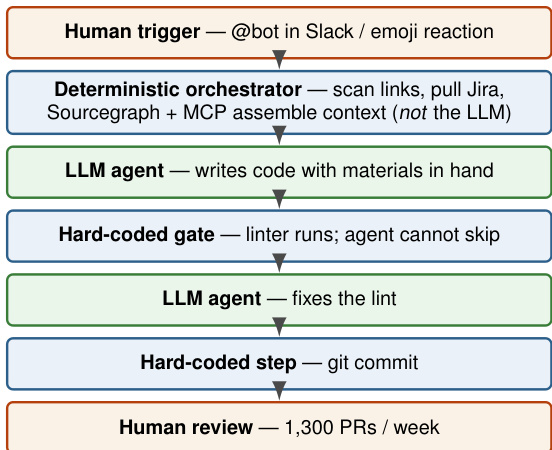
The LLM agent writes code, but a hard-coded gate runs immediately after; the agent cannot skip this step. If the lint fails, the agent fixes it. Finally, a hard-coded step commits the code, followed by human review. This structure ensures reliability comes from the quality of constraints rather than just model size.
Experiment
The evaluation contrasts local loop/desktop scheduled tasks with cloud routines and GitHub Actions schedule triggers for running background work while the user sleeps. Local scheduling demands that the machine remain powered on but enables frequent execution and direct access to local files, whereas cloud scheduling runs untethered from local state at the cost of a one-hour minimum interval and a clean clone each time. The comparison shows that no single scheduler meets all requirements, and it warns that widely circulated secondhand metrics should be treated as rough references, highlighting the greater reliability of firsthand sources.