Command Palette
Search for a command to run...
DeepSeek-V4 : Vers une intelligence contextuelle hautement efficace à un million de tokens
DeepSeek-V4 : Vers une intelligence contextuelle hautement efficace à un million de tokens
Déploiement en un clic de DeepSeek-V4-Flash
Résumé
Nous présentons une version préliminaire de la série DeepSeek-V4, comprenant deux modèles de langage performants basés sur l'architecture Mixture-of-Experts (MoE) : DeepSeek-V4-Pro, doté de 1,6T de paramètres (dont 49B activés), et DeepSeek-V4-Flash, doté de 284B de paramètres (dont 13B activés). Les deux modèles prennent en charge une longueur de contexte d'un million de tokens.La série DeepSeek-V4 intègre plusieurs améliorations clés au niveau de l'architecture et de l'optimisation : (1) une architecture d'attention hybride combinant la Compressed Sparse Attention (CSA) et la Heavily Compressed Attention (HCA) afin d'améliorer l'efficacité du contexte long ; (2) des Manifold-Constrained Hyper-Connections (mHC) qui optimisent les connexions résiduelles conventionnelles ; (3) et l'optimiseur Muon, permettant une convergence plus rapide et une plus grande stabilité lors de l'entraînement. Nous avons pré-entraîné les deux modèles sur plus de 32T de tokens diversifiés et de haute qualité, suivis d'un pipeline de post-entraînement complet qui permet de libérer et de renforcer davantage leurs capacités. DeepSeek-V4-Pro-Max, le mode de raisonnement maximal de DeepSeek-V4-Pro, redéfinit l'état de l'art pour les modèles ouverts, surpassant ses prédécesseurs dans les tâches fondamentales. Parallèlement, la série DeepSeek-V4 se distingue par sa grande efficacité dans les scénarios de contexte long. Dans une configuration de contexte d'un million de tokens, DeepSeek-V4-Pro ne nécessite que 27 % des FLOPs d'inférence par token unique et 10 % du KV cache par rapport à DeepSeek-V3.2. Cela nous permet de prendre en charge de manière routinière des contextes d'un million de tokens, rendant ainsi les tâches à long horizon ainsi que l'extension de l'échelle au moment du test (test-time scaling) plus réalisables.Les checkpoints du modèle sont disponibles à l'adresse suivante : https://huggingface.co/collections/deepseek-ai/deepseek-v4.
One-sentence Summary
The DeepSeek-V4 series introduces two Mixture-of-Experts models, DeepSeek-V4-Pro with 1.6T parameters (49B activated) and DeepSeek-V4-Flash with 284B parameters (13B activated), that support one million tokens through a hybrid attention architecture combining Compressed Sparse Attention and Heavily Compressed Attention, Manifold-Constrained Hyper-Connections, and the Muon optimizer, with DeepSeek-V4-Pro-Max redefining the state-of-the-art for open models and DeepSeek-V4-Pro requiring only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek-V3.2.
Key Contributions
- The DeepSeek-V4 series introduces two Mixture-of-Experts language models supporting a context length of one million tokens. DeepSeek-V4-Pro features 1.6T parameters with 49B activated, while DeepSeek-V4-Flash features 284B parameters with 13B activated.
- Architectural upgrades include a hybrid attention architecture combining Compressed Sparse Attention and Heavily Compressed Attention to improve long-context efficiency. The series also incorporates Manifold-Constrained Hyper-Connections to enhance residual connections and the Muon optimizer for faster convergence and greater training stability.
- DeepSeek-V4-Pro-Max redefines the state-of-the-art for open models by outperforming predecessors in core tasks. In one-million-token context settings, DeepSeek-V4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek-V3.2.
Introduction
Processing ultra-long contexts is essential for enabling test-time scaling and complex agentic tasks in next-generation large language models. However, existing solutions struggle with efficiency barriers that prevent open-source models from matching the reasoning capabilities of proprietary systems. To address this, the authors introduce the DeepSeek-V4 series which combines a hybrid attention architecture with extensive infrastructure optimization. This approach enables efficient native support for million-token contexts and establishes a new standard for open models regarding reasoning performance and cost efficiency.
Dataset
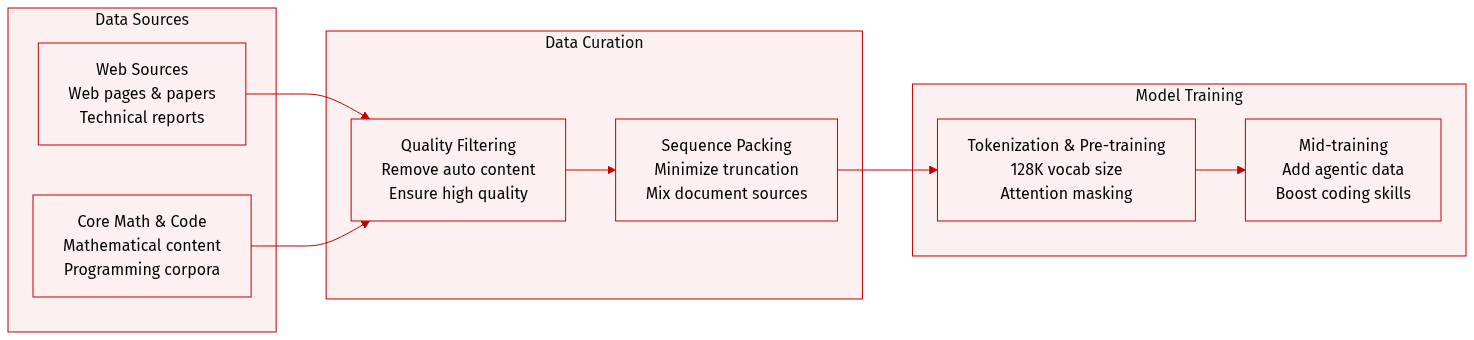
-
Dataset Composition and Sources
- The authors build on the pre-training data of DeepSeek-V3 to create a diverse corpus exceeding 32T tokens.
- Primary sources include web pages, mathematical content, code, multilingual text, and long documents such as scientific papers and technical reports.
-
Subset Details and Filtering Rules
- Web-sourced data is filtered to remove batched auto-generated and templated content to mitigate model collapse risks.
- Mathematical and programming corpora serve as core components, with agentic data added during the mid-training phase for coding enhancement.
- The multilingual corpus is expanded to improve the capture of long-tail knowledge across various cultures.
- Long-document data curation prioritizes materials reflecting unique academic values for the DeepSeek-V4 series.
-
Training Usage and Processing
- Pre-processing largely follows DeepSeek-V3 strategies with a fixed vocabulary size of 128K.
- The tokenizer introduces special tokens for context construction while retaining token-splitting and Fill-in-Middle (FIM) strategies.
- Documents from different sources are packed into appropriate sequences to minimize sample truncation.
- Sample-level attention masking is employed during pre-training, marking a departure from the previous version.
Method
Model Architecture and Training Methodology
The DeepSeek-V4 series retains the Transformer architecture and Multi-Token Prediction (MTP) strategy while introducing key upgrades to enhance long-context efficiency and training stability. The overall framework incorporates a hybrid attention mechanism and Manifold-Constrained Hyper-Connections (mHC) alongside the DeepSeekMoE structure. The complete architecture, illustrating the flow from input tokens through embedding, Transformer blocks, and prediction heads, is presented in the diagram below.
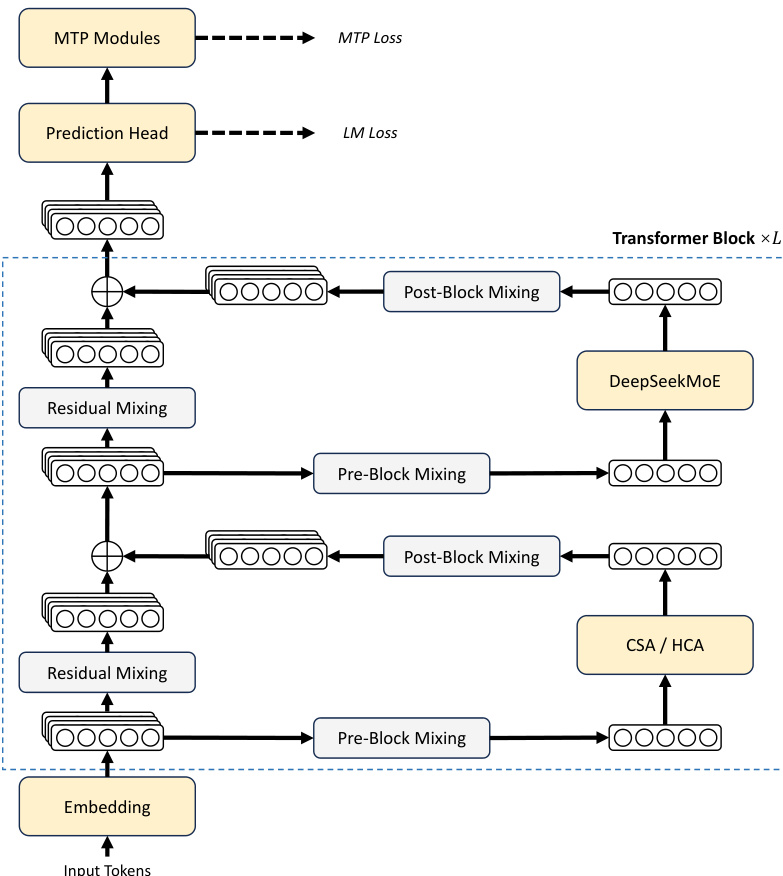
To strengthen signal propagation across layers, the authors incorporate Manifold-Constrained Hyper-Connections (mHC) to upgrade conventional residual connections. The core idea involves constraining the residual mapping matrix to the manifold of doubly stochastic matrices. This ensures the spectral norm of the mapping matrix is bounded by 1, which increases numerical stability during both the forward pass and backpropagation without influencing the design of inner layers.
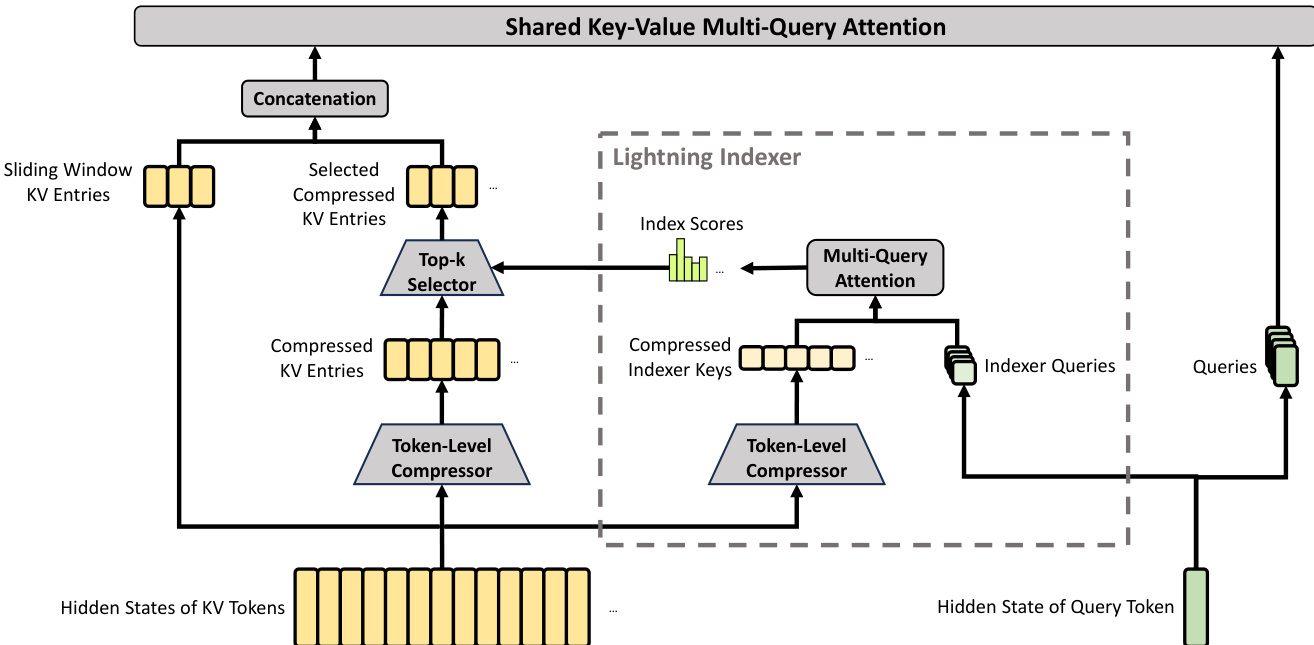
A critical component for handling ultra-long contexts is the hybrid attention architecture, which combines Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). CSA first compresses the Key-Value (KV) cache of every m tokens into one entry and then applies a sparse selection strategy. A Lightning Indexer computes index scores to select top-k compressed KV entries for the core attention mechanism. The detailed architecture of CSA, including the token-level compressor and selection process, is shown below.
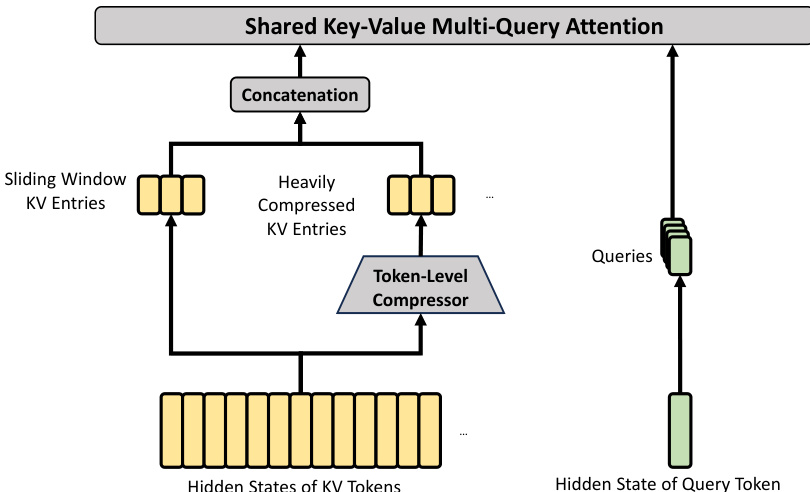
HCA aims for extreme compression by consolidating the KV cache of every m′ tokens into a single entry, where m′ is significantly larger than m. Unlike CSA, HCA does not employ sparse attention but performs dense attention over the heavily compressed representation. This design further reduces the computational cost and KV cache size. The core architecture of HCA, which utilizes a token-level compressor without an indexer, is depicted below.
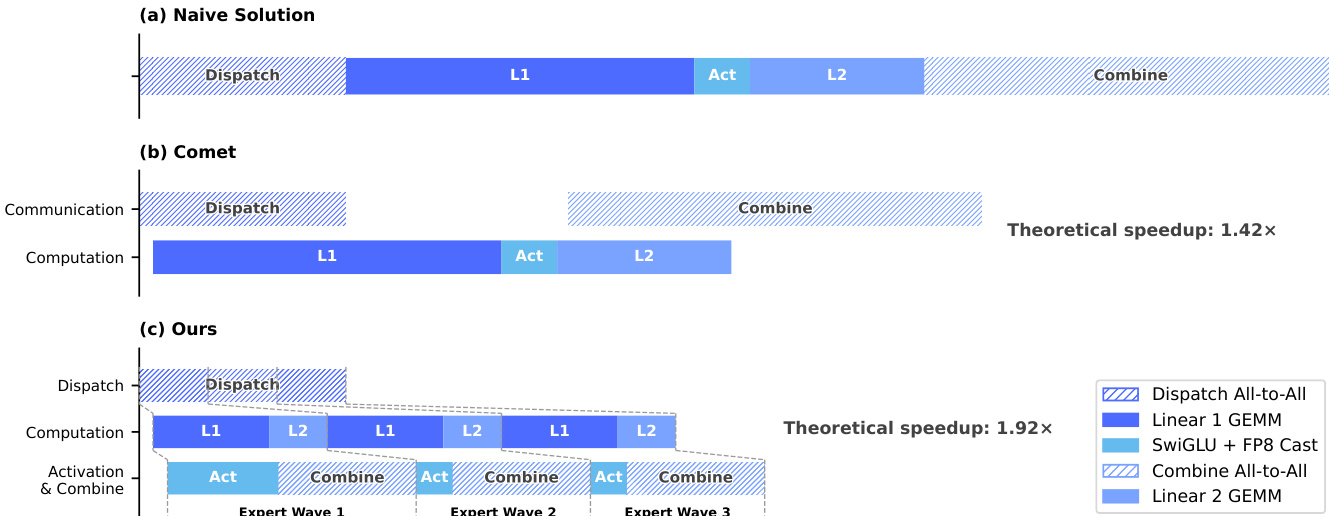
For optimization, the models employ the Muon optimizer to achieve faster convergence and greater training stability. To support efficient training and inference of the Mixture-of-Experts (MoE) components, the system implements a fine-grained Expert Parallelism scheme. This approach fuses communication and computation into a single pipelined kernel by splitting experts into waves. As illustrated in the timing diagram below, this allows computation for one wave to proceed while communication for the next occurs, effectively hiding communication latency.
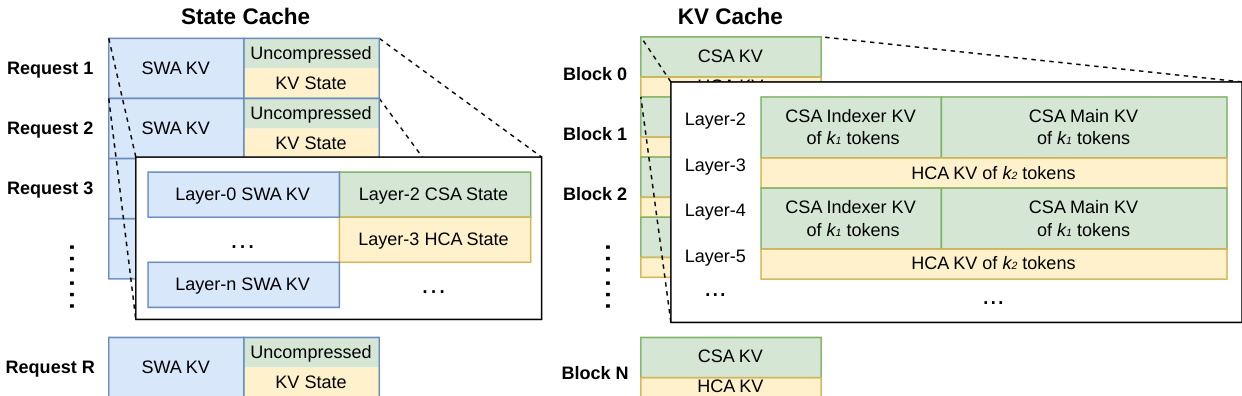
The hybrid attention mechanism necessitates a heterogeneous KV cache structure to manage different compression ratios and attention policies. The system maintains a State Cache for sliding window attention and uncompressed tail tokens, alongside a classical KV Cache for compressed entries. This layout, visualized below, organizes cache blocks to accommodate the varying requirements of CSA and HCA layers across different requests.
Following pre-training, the models undergo a post-training pipeline involving specialist training and On-Policy Distillation. The training supports multiple reasoning effort modes, allowing the model to adapt its computational depth to task complexity. The comparison of these reasoning modes, including their context windows and length penalties, is presented in the table below.
For maximum reasoning effort, specific instructions are injected into the system prompt to guide the model's behavior during the "Think Max" mode. The instruction template used for this mode is shown below.
Experiment
The evaluation framework assesses DeepSeek-V4 variants against leading open and proprietary models across knowledge, reasoning, coding, and long-context benchmarks, supplemented by internal metrics for real-world applications. DeepSeek-V4-Pro-Max establishes a new leading standard for open-source models, significantly narrowing the performance gap with frontier closed systems while demonstrating robust capabilities in 1 million token context retention and agentic search. While the efficient Flash variant outperforms previous generations, the Pro series excels in complex enterprise tasks and coding, though it still trails top competitors slightly in formatting precision and instruction following.
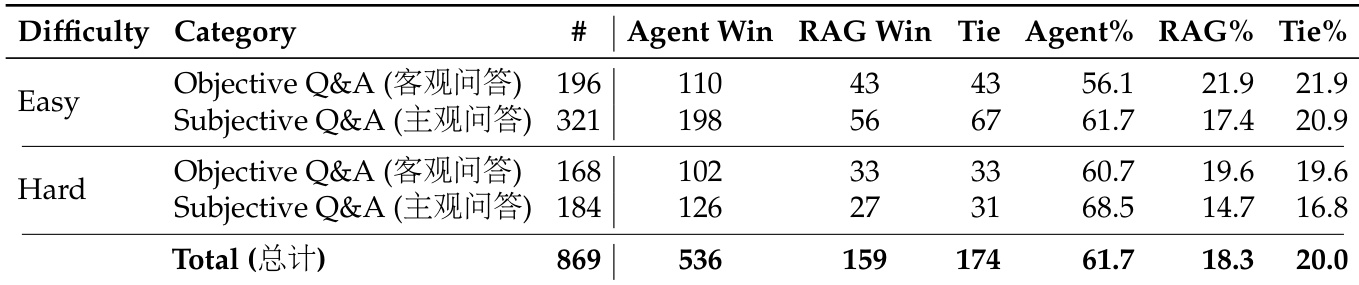
The the the table presents a pairwise comparison between Agentic Search and Retrieval-Augmented Search (RAG) across varying difficulty levels and question categories. The results demonstrate that Agentic Search consistently outperforms RAG, achieving a substantially higher win rate in both easy and hard scenarios. This performance advantage is observed across both objective and subjective question types, confirming the efficacy of the agentic approach. Agentic Search achieves a dominant win rate over RAG across all evaluated categories. The performance gap remains consistent for both easy and hard difficulty levels. Agentic Search shows particular strength in hard subjective questions compared to RAG.
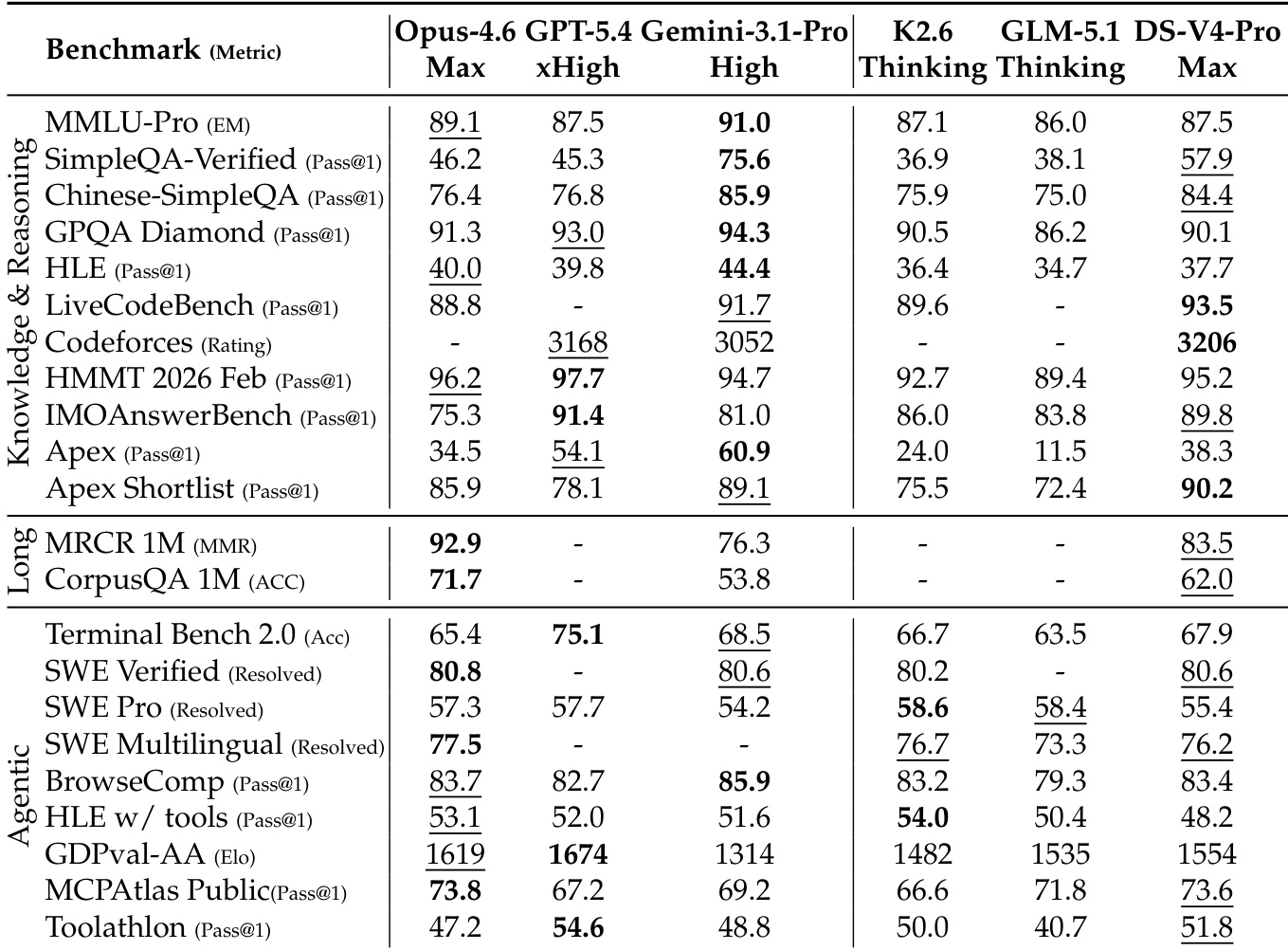
The provided data compares DeepSeek-V4-Pro against leading proprietary and open-source models across knowledge, reasoning, long-context, and agentic benchmarks. DeepSeek-V4-Pro consistently outperforms other open-source models, often ranking second or third overall behind top-tier closed models like Opus-4.6 and GPT-5.4. While it demonstrates significant strength in long-context retrieval and specific coding evaluations, it still trails the strongest proprietary models in complex mathematical reasoning and certain agentic tasks. DeepSeek-V4-Pro significantly outperforms open-source competitors on knowledge benchmarks like SimpleQA but remains behind proprietary leaders such as Gemini-3.1-Pro. The model achieves superior long-context retrieval performance compared to Gemini-3.1-Pro, though Opus-4.6 maintains the lead. In agentic and coding evaluations, DeepSeek-V4-Pro matches or exceeds other open models but generally lags behind the highest-performing closed models.
The authors present a comparison of DeepSeek-V4-Pro-Max against several Claude model variants on a benchmark measuring pass rates. The data shows that DeepSeek-V4-Pro-Max significantly outperforms the Sonnet 4.5 model and performs at a level comparable to the base Opus 4.5 model. Despite this strong performance, the DeepSeek model falls short of the specialized Thinking variants of the Opus series, which achieve the highest success rates in this evaluation. DeepSeek-V4-Pro-Max shows a clear advantage over the Sonnet 4.5 model in this benchmark. Performance is competitive with the standard Opus 4.5 configuration but lower than Opus variants with Thinking enabled. Opus 4.6 Thinking achieves the highest pass rate, surpassing both the DeepSeek model and other Claude variants.

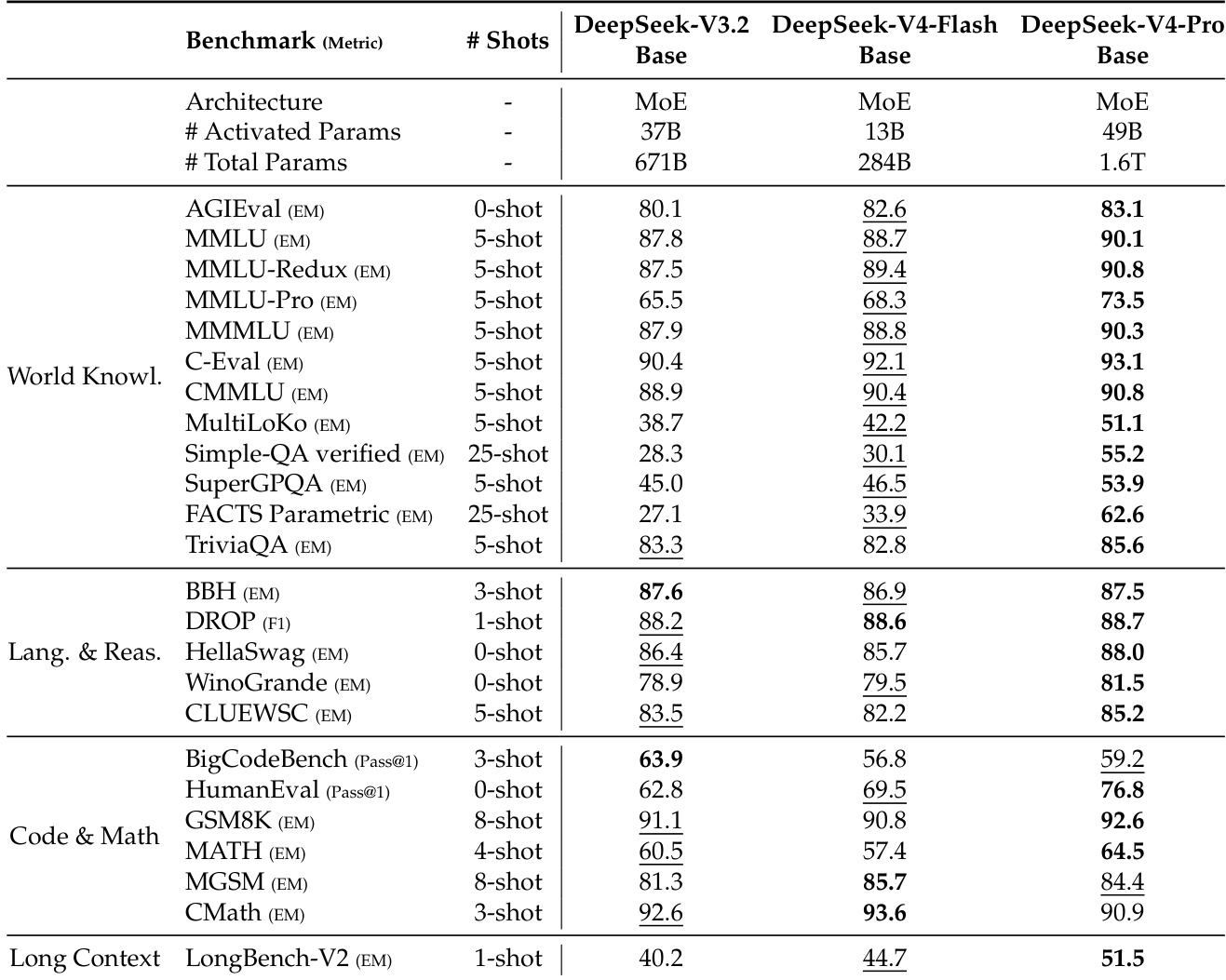
The the the table compares the performance of DeepSeek-V3.2, DeepSeek-V4-Flash, and DeepSeek-V4-Pro base models across knowledge, reasoning, coding, and long-context benchmarks. DeepSeek-V4-Pro-Base demonstrates a decisive leap in capability, achieving the highest scores in most categories and establishing itself as the strongest foundation model in the series. Meanwhile, DeepSeek-V4-Flash-Base showcases significant efficiency gains, outperforming the larger DeepSeek-V3.2-Base in many evaluations despite having fewer activated parameters. DeepSeek-V4-Pro-Base achieves top performance across nearly all evaluated dimensions, showing decisive improvements in world knowledge and long-context processing. DeepSeek-V4-Flash-Base proves highly efficient by surpassing the larger DeepSeek-V3.2-Base on a wide array of benchmarks with significantly fewer parameters. While the Pro variant leads overall, specific coding and math tasks reveal instances where the V3.2 and Flash models maintain competitive or superior scores.
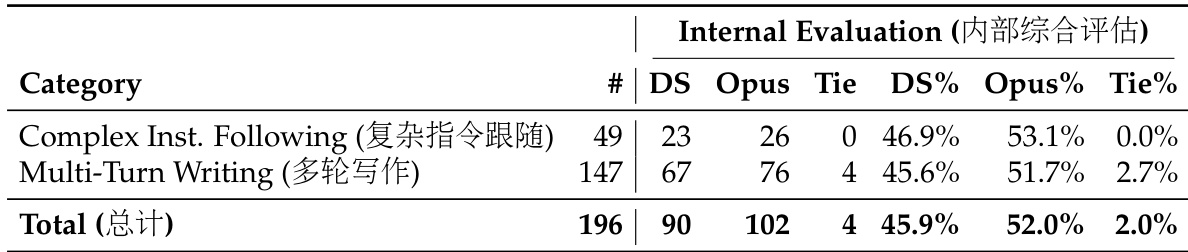
The authors conduct an internal evaluation comparing DeepSeek-V4-Pro against Claude Opus 4.5 on tasks involving complex instruction following and multi-turn writing. The results indicate that while DeepSeek-V4-Pro performs competitively, Opus 4.5 maintains a consistent performance advantage across these specific challenging categories. This suggests that despite strong general capabilities, the model still trails the leading proprietary counterpart in handling high-complexity constraints and extended interactions. Opus 4.5 achieves a higher win rate than DeepSeek-V4-Pro in both complex instruction following and multi-turn writing benchmarks. DeepSeek-V4-Pro demonstrates strong competitiveness by securing wins in nearly half of the evaluated instances against the leading model. The evaluation highlights a specific performance gap where DeepSeek-V4-Pro lags behind Opus 4.5 in high-complexity and multi-turn scenarios.
The evaluations compare Agentic Search against Retrieval-Augmented Search and benchmark DeepSeek model variants against leading proprietary and open-source competitors across knowledge, reasoning, and coding tasks. Results indicate that Agentic Search consistently outperforms RAG, while DeepSeek-V4-Pro variants demonstrate superior efficiency and long-context capabilities compared to open-source peers but generally trail top-tier closed models in complex mathematical reasoning and multi-turn writing. Within the DeepSeek series, the Pro-Base variant establishes the strongest foundation, though specialized Thinking models from competitors maintain an advantage in complex instruction following.