Command Palette
Search for a command to run...
DeepCrack : Une architecture d’apprentissage hiérarchique de caractéristiques profondes pour la segmentation des fissures
DeepCrack : Une architecture d’apprentissage hiérarchique de caractéristiques profondes pour la segmentation des fissures
Yahui Liu Lian Yao Xiaohu Lu Renping Xie Li Li
Résumé
La détection automatique de fissures à partir d’images de scènes variées constitue une tâche à la fois utile et complexe en pratique. Dans cet article, nous proposons un réseau de neurones convolutif profond et hiérarchique, appelé DeepCrack, capable de prédire une segmentation des fissures à l’échelle du pixel, dans une approche de bout en bout. DeepCrack est composé de Fully Convolutional Networks (FCN) étendus et de Deeply-Supervised Nets (DSN). Lors de l’entraînement, le modèle, conçu de manière rigoureuse, apprend et agrège des caractéristiques multi-échelles et multi-niveaux, depuis les couches convolutives basiques jusqu’aux couches convolutives de haut niveau. Cette approche se distingue des méthodes standards qui ne tirent parti que de la dernière couche convolutives. Les DSN fournissent une supervision directe intégrée pour les caractéristiques de chaque étape convolutive. Nous appliquons à la fois le filtrage guidé et les Conditional Random Fields (CRFs) afin d’affiner les résultats de prédiction finaux. Un jeu de données de référence, composé de 537 images accompagnées de cartes d’annotation manuelles, a été construit pour valider l’efficacité de la méthode proposée. Notre méthode a obtenu des performances de pointe sur le jeu de données proposé (score moyen IoU de 85 %.
One-sentence Summary
The authors propose DeepCrack, a deep hierarchical convolutional neural network combining extended Fully Convolutional Networks and Deeply-Supervised Nets for end-to-end pixel-wise crack segmentation that aggregates multi-scale features across all convolutional stages with direct supervision and refines final prediction results using guided filtering and Conditional Random Fields, achieving state-of-the-art performance on a benchmark dataset of 537 manually annotated images.
Key Contributions
- DeepCrack, a deep hierarchical convolutional neural network, aggregates multi-scale and multi-level features from low to high convolutional layers for end-to-end pixel-wise segmentation.
- Integrated direct supervision is provided by Deeply-Supervised Nets, while guided filtering and Conditional Random Fields refine the final prediction results.
- A public benchmark dataset consisting of 537 manually annotated images was established to evaluate the system, where the method achieved state-of-the-art performance with a mean I/U of 85.
Introduction
Automatic crack detection is critical for ensuring the safety and durability of infrastructure, yet traditional computer vision methods often fail to generalize across varying scenes and noise conditions. Existing deep learning approaches frequently lack the pixel-wise precision required for accurate segmentation or rely on separated mechanisms that propagate errors. To address these challenges, the authors introduce DeepCrack, a deep hierarchical convolutional neural network designed to learn and aggregate multi-scale features from all convolutional layers rather than just the final output. This architecture employs Deeply-Supervised Nets for integrated direct supervision and refines results using guided filtering and Conditional Random Fields. Furthermore, the researchers created an open benchmark dataset with manual annotations to enable rigorous evaluation of crack detection systems.
Dataset
-
Dataset Composition and Sources
- The authors established a new open benchmark database consisting of 537 RGB color images with manual annotations.
- An additional public benchmark [48] is referenced for evaluating thin crack detection capabilities.
-
Subset Details
- The main database divides images into 300 for training and 237 for testing.
- All images in the main database share a fixed size of 544 by 384 pixels.
- The external benchmark contains fewer than 40 annotated images focused on cracks 2 to 5 pixels wide.
-
Annotation and Processing
- Ground truth is provided as pixel-wise segmentation masks that precisely cover crack regions.
- Annotators generated masks by viewing binary images to ensure segmentation accuracy.
- The dataset covers diverse textures including bare, rough, and dirty surfaces across asphalt and concrete scenes.
- Crack widths vary significantly from 1 to 180 pixels to challenge segmentation models.
-
Usage in Model Development
- The primary dataset serves as the basis for training and testing the proposed deep learning methods.
- The external dataset evaluates performance on thin cracks where traditional post-processing is usually required.
Method
The authors formulate crack segmentation as a binary image labeling problem, where the network assigns a label of "0" for non-crack and "1" for crack pixels. To address the requirement for both high-level semantic features and low-level spatial cues, the proposed architecture aggregates hierarchical features from multiple layers. The overall framework is illustrated in the diagram below, which depicts the flow from the input RGB image through the convolutional backbone to the final segmentation output.
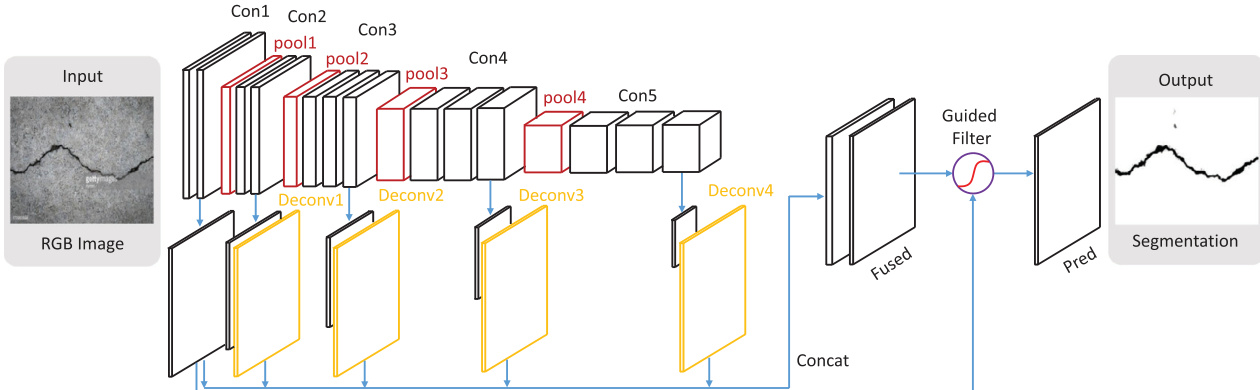
The core of the network utilizes the first 13 convolutional layers of the VGG-16 architecture, designed for object classification. However, the fully connected layers and the fifth pooling layer are discarded. This design choice is made to preserve spatial resolution for meaningful side-outputs and to reduce computational intensity. Each convolutional layer consists of a convolution operation, batch normalization to reduce internal covariate shift, and a Rectified Linear Unit (ReLU) activation function. Spatial pooling is performed using four max-pooling layers with a 2×2 filter and stride of 2, following specific convolutional stages to achieve translation invariance and reduce parameter size.
A detailed view of the layer configurations and operations is provided in the following figure, highlighting the specific kernel sizes, strides, and the integration of batch normalization.
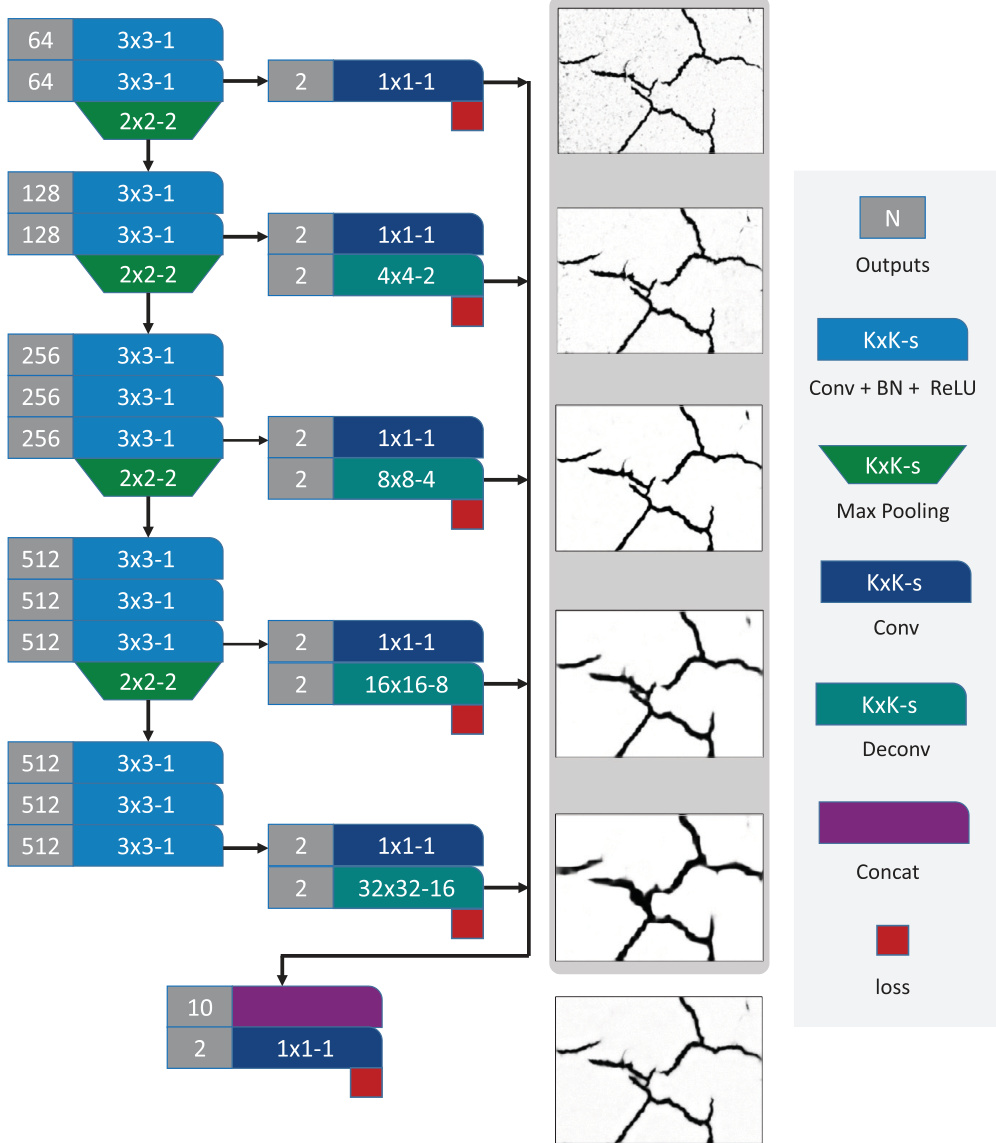
To leverage features at different scales, the authors employ a deep supervision strategy by inserting side-output layers. These layers are 1x1 convolutional layers that produce prediction maps at various depths of the network. Except for the first side-output layer, the subsequent side-outputs are followed by deconvolutional layers to upsample the feature maps to the size of the input image. These upsampled feature maps are then concatenated to form the final fused features. The process of generating these side-outputs and their subsequent fusion is visualized below.
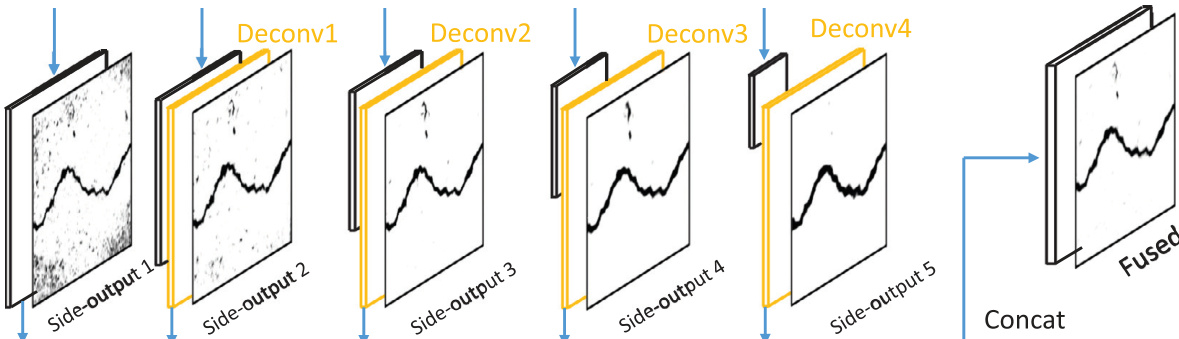
The final fused prediction is refined using a Guided Filtering module. This technique addresses the trade-off between boundary preservation and noise resistance found in different convolutional stages. Lower stages preserve boundaries well but are sensitive to noise, while deeper stages are robust to noise but lack boundary detail. The guided filter uses the first side-output as a guidance map to refine the fused prediction, effectively removing noise while preserving crack regions. This method is noted to be faster and more efficient than Conditional Random Field (CRF) based methods.
Regarding the training process, the model is trained in an end-to-end manner using a weighted cross-entropy loss function. Deep supervision is applied to each side-output layer to learn meaningful features. The total loss function L is composed of the side-output loss Lside and the fused loss Lfuse. Given the class imbalance where non-crack pixels significantly outnumber crack pixels, class balancing weights w0 and w1 are applied. Specifically, w0 is set to 1.0 for negative pixels, and w1 is set to the ratio of negative to positive pixels in the training set to prevent training saturation. The overall loss is formulated as:
L=Lside(I,G,W,w)+Lfuse(I,G,W)
where I represents the input image, G is the ground truth, and W denotes the network parameters. This formulation ensures that the network minimizes the differences between the final prediction and the ground truth across all supervision levels.
Experiment
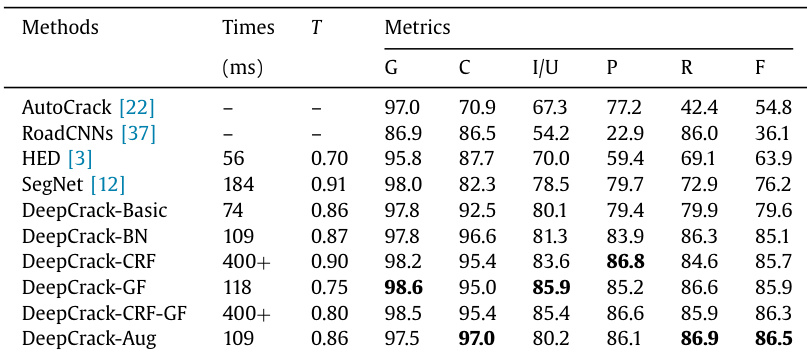
The evaluation compares six DeepCrack network strategies against four baseline methods using a custom benchmark to assess crack segmentation effectiveness. Results indicate that the proposed architecture significantly outperforms traditional and edge-based detectors by effectively capturing both thin and wide cracks without relying on pre-trained models. Qualitative findings reveal that batch normalization reduces overfitting while guided filtering provides a more efficient refinement than conditional random fields, ultimately yielding sharper boundaries and robust generalization on external datasets.
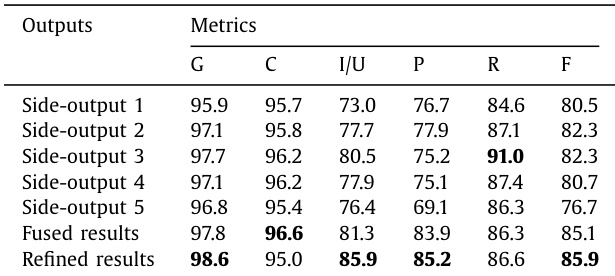
The the the table compares performance metrics across individual side-outputs, fused results, and refined results for the DeepCrack-GF model. Performance trends indicate that middle-level layers generally yield better results than lower or higher-level layers, while fusion and refinement strategies significantly enhance overall accuracy and F-score. Middle-level side-outputs outperform lower and higher-level layers in most metrics. Fusing hierarchical features leads to better performance than individual side-outputs. Refined results achieve the highest global accuracy and F-score.
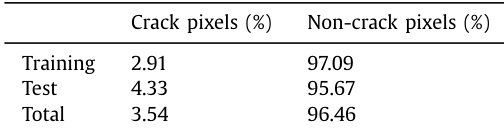
The provided the the table details the distribution of crack and non-crack pixels within the training, test, and total datasets. It demonstrates a significant class imbalance where non-crack pixels vastly outnumber crack pixels across all categories. Non-crack pixels constitute the overwhelming majority of the data. The test set contains a relatively higher proportion of crack pixels compared to the training set. The overall dataset maintains a consistent imbalance favoring non-crack regions.
The authors evaluate their proposed DeepCrack network variants against several baseline methods using a custom benchmark database. Results show that adding batch normalization and data augmentation significantly boosts performance, with the augmented model achieving the highest F-score and recall. While post-processing techniques like CRF and Guided Filtering improve precision, the Guided Filtering variant offers a more efficient trade-off between accuracy and inference time compared to the computationally heavier CRF approaches. The DeepCrack-Aug variant outperforms all other methods in terms of F-score and recall, highlighting the benefit of data augmentation. DeepCrack-GF achieves the highest global accuracy and intersection over union, providing sharper boundaries with faster inference than CRF-based methods. Traditional methods and edge detection networks like AutoCrack and HED exhibit lower performance, particularly in handling wider cracks or producing rough segmentations.
The study evaluates the DeepCrack network on a custom benchmark database characterized by significant class imbalance between crack and non-crack pixels. Experiments demonstrate that middle-level layers outperform other hierarchical levels, while feature fusion and refinement strategies significantly enhance segmentation accuracy. Furthermore, variants using data augmentation and guided filtering achieve superior efficiency and boundary sharpness compared to baseline methods and traditional edge detection networks.