Command Palette
Search for a command to run...
La translation comme action de pontage : Transfert de compétences de manipulation des humains vers les robots
La translation comme action de pontage : Transfert de compétences de manipulation des humains vers les robots
Sijin Chen Kaixuan Jiang Haixin Shi Yanhui Wang Weiheng Zhong Haosheng Li Bo Jiang Yuxiao Liu Xihui Liu
Résumé
Nous étudions s'il est possible d'apprendre de nouvelles compétences de manipulation à partir d'actions humaines pour un robot bi-manuel doté de pinces parallèles. Les données d'actions humaines sont peu coûteuses, abondantes et diverses, ce qui en fait l'une des ressources les plus prometteuses pour le passage à l'échelle de l'apprentissage robotique. Pourtant, le transfert de compétences des humains vers les robots reste difficile : la plupart des travaux antérieurs considèrent les humains comme un simple autre agent bi-manuel à 6 degrés de liberté (6DoF), avec des estimations de poses de main bruitées et des motifs de contact des doigts humains fondamentalement différents de ceux d'une pince parallèle. Nous soutenons donc qu'apprendre des signaux d'action incluant la rotation à partir de données humaines est sous-optimal, et proposons à la place une représentation d'action de pontage : la translation relative du poignet dans le repère initial de la caméra portée sur la tête, un espace d'action partagé par les humains et les robots. Pour gérer l'absence potentielle de certaines composantes d'action dans différentes morphologies, nous construisons un modèle vision-langage-action de type π0 avec des jetons d'action entrelacés et un masquage d'attention. Sur une série de nouvelles tâches de manipulation bi-manuelles, notre action de pontage transfère la connaissance de manipulation humaine aux robots de manière bien plus efficace que les actions humaines bruitées à 6DoF et s'améliore avec la quantité de données humaines.
One-sentence Summary
To transfer human manipulation skills to bi-manual robots with parallel grippers, researchers from HKU-MMLab and ByteDance Seed propose a bridging action representation—relative wrist translation in the initial head-camera frame—and a π0-like vision-language-action model with interleaved action tokens and attention masking that outperforms noisy 6DoF human actions and scales with human data.
Key Contributions
- A translation-based bridging action representation uses relative wrist translation in the initial head-camera frame, shared by humans and robots, to avoid unreliable wrist rotations and enable effective cross-embodiment skill transfer.
- A vision-language-action model with interleaved action tokens and attention masking handles missing action components across data sources, allowing seamless co-training of human and robot actions.
- Experiments on novel bi-manual manipulation tasks show that the bridging action transfers human manipulation knowledge to robots far more effectively than noisy 6DoF human actions and scales positively with the amount of human data.
Introduction
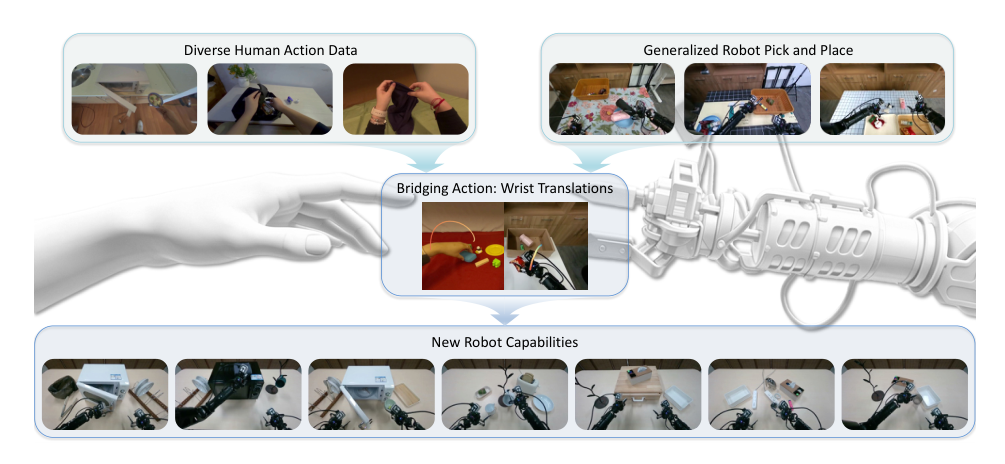
Human manipulation data collected in everyday settings offers a scalable and cost-effective way to train robot policies, but learning from this data is complicated by noisy hand-pose estimates and the mismatch between human hand rotations and parallel gripper mechanics. Prior work typically uses wrist poses or latent actions, yet incorporating rotation signals often proves unreliable and suboptimal. The authors address these challenges by discarding wrist rotations and instead learning a shared bridging representation that uses only wrist translations under the head-camera frame. They couple this with an interleaved action token design that can mask missing action components, enabling a unified model to transfer manipulation knowledge from large-scale human data to bi-manual robots without needing rotation-inclusive supervision.
Method
The authors propose a framework that transfers manipulation skills from human demonstrations to a bi-manual robot by introducing a shared, embodiment-agnostic action representation and a vision-language-action model trained through a multi-stage curriculum.
Motion Bridging Action Representation Rather than directly adopting 6DoF wrist poses from hand-pose estimators, which suffer from noisy rotation estimates and a mismatch between finger-based and parallel-gripper contact patterns, the method defines a bridging signal based purely on wrist translation. The key insight is that both humans and robots act upon what they perceive; therefore, the relative wrist translation observed from a head-mounted camera serves as a common action. Concretely, the wrist pose at time t in the world frame, Wwt∈SE(3), is mapped into the head-camera frame ct using the inverse camera pose Tw←ct, giving Wctt+i=(Tw←ct)−1Wwt+i. The translation component over a future window of k steps defines the bridging action:
at+i3D-wrist=ΔW3D=t(Wctt+i)−t(Wctt),i=1,…,k,where t(⋅) extracts the 3×1 translation vector. For bi-manual settings, wrist translations of both arms are concatenated, yielding at3D-wrist∈Rk×6. This translation-only signal is physically meaningful under a shared observation perspective, robust to noisy rotations, and embodiment-agnostic.
Alongside the bridging action, the robot-specific 6DoF end-effector action is defined as the relative pose between two SE(3) wrist frames:
at+i6D-eef=ΔW6D=(Wwt)−1Wwt+i,which, after conversion to Cartesian coordinates and Euler angles, gives at6D-eef∈Rk×12 for both arms. The gripper action is a binary chunk atgripper∈Rk×2 indicating open or close for each gripper; for in-lab human data, hand closure is annotated as a proxy.
All action components are unified into a single action vector at=(at3D-wrist,at6D-eef,atgripper). Different data sources provide different subsets: human data yields only the bridging signal, while robot data additionally supplies the 6DoF and gripper actions. During training, only the reliably available components are supervised.
VLA Model with Interleaved Action Sequence The architecture is an end-to-end vision-language-action (VLA) model similar to π0, denoted πθ(l,ot), which generates an action chunk at:t+k conditioned on a language instruction l and visual observations ot from a head camera and two wrist cameras. For human data where wrist views are missing, blank images are padded.
The model separates vision-language processing from action generation to balance different objectives. A pre-trained vision-language model processes the vision and language tokens (ot,l) and produces a key-value cache. This cache then serves as context for an Action Transformer that generates the action chunk via flow matching. Both modules share self-attention layers but use distinct parameter sets.
A central design is the interleaved ordering of action tokens: a3D-wrist→a6D-eef→agripper. This order encodes two structural priors: first, the shared bridging signal should be attended to by the 6DoF action tokens, enabling explicit transfer of manipulation knowledge from human to robot within the attention pattern; second, gripper actuation typically follows the end-effector’s arrival at a target. When a data source lacks a particular action component, the corresponding tokens are masked in the attention layers and excluded from the loss computation, for example, the 6DoF end-effector action for human data.
Action generation is trained with flow matching. Given a time step τ∈(0,1) and Gaussian noise ϵ∼N(0,I), the model receives the noisy action chunk atτ=τϵ+(1−τ)at together with observation ot and language l, and predicts a velocity field v^(atτ,ot,l,τ) that points from noise toward the clean action. The ground-truth velocity is v∗=ϵ−at, and the flow matching loss is:
LFM=∥v^(atτ,ot,l,τ)−v∗∥22.The loss is applied only to the action components present in each training sample. During inference, the model generates only the robot-executable components a6D-eef and agripper by integrating the velocity from τ=0 to τ=1 using the Euler method with step size Δτ=0.2.
To prevent overfitting to action data, the VLA model is co-trained with a collection of vision-language data using a standard next-token prediction objective LNTP. Each training batch contains either action trajectories (using LFM) or vision-language examples (using LNTP), balancing perception and action capabilities.
Training Strategies The model is trained in three stages to gradually introduce embodiment-specific grounding while preserving the skills learned from human data.
Stage I: Pre-training on human actions. Human demonstrations provide rich skill and scene diversity at scale. Approximately 600 hours of human action data (including ego-centric manipulation clips and in-lab recordings) are used to train the bridging signal exclusively through LFM3D-wrist. No robot-specific components are involved, so the model learns a generalizable motion prior.
Stage II: Human-robot co-training. To ground the bridging representation in executable robot commands, the model is exposed to real robot trajectories alongside a smaller set of task-specific in-lab human actions. The robot data consists of generalized pick-and-place episodes covering many objects, while in-lab operators mimic the robot gripper with their hand to provide gripper annotations. All three losses (LFM3D-wrist, LFM6D-eef, LFMgripper) are active on robot data. Crucially, during training on robot trajectories, the target is either the bridging action itself or the 6DoF action substituted in its place; this binding strategy explicitly aligns the shared latent motion with the robot-specific action space and proves essential for transfer.
Stage III: Few-shot robot post-training. To study data efficiency, only 10 teleoperated demonstrations per task are used for fine-tuning. This final stage co-trains on the few-shot robot trajectories, further adapting the model to the target task with minimal supervision.
Implementation-wise, the VLA model uses a Mixture-of-Transformer architecture with approximately 4B parameters and is initialized from a pre-trained VLM. Stage I trains all parameters with a batch size of 1024 for 400k iterations; Stage II continues co-training on both robot and human data with batch size 256 for 120k iterations; Stage III fine-tunes with the same batch size for 25k iterations. To accelerate convergence, the Action Transformer’s effective batch size is increased fourfold by repeating the VLM’s key-value cache within each training batch.
Experiment
The evaluation covers 15 diverse manipulation tasks using a bi-manual robot and in-lab human action data, with performance measured by success rate and fine-grained progress. The experiments demonstrate that a translation-only bridging action representation transfers skills beyond pick-and-place, scales effectively with large-scale human-only pre-training, and surpasses 6DoF human actions by yielding more stable robot behaviors. Human-only pre-training aligns with the executable robot action space, improves few-shot post-training data efficiency, and training the bridging objective on robot data is essential; the approach shows promise for multi-embodiment learning but precision in contact-rich tasks remains a limitation where rotation cues would help.
The table defines which action components are supervised for each data source: in-the-wild human clips provide only the translation-only wrist action from a head-camera view, in-lab human adds gripper supervision, and robot teleoperation adds the full 6D end-effector action. Learning this bridging wrist translation from human-only data transfers to the robot’s executable action space, lowering training loss for 6D end-effector and gripper actions and improving downstream task performance. The alignment between the bridging action and the full 6D action is empirically verified, and the representation’s effectiveness grows as the visual and action-noise gap between embodiments shrinks. In-the-wild human data can supervise only the translation component of wrist motion, not gripper or full 6DoF actions. Human-only pretraining on the bridging wrist translation lowers the co-training loss for both 6D end-effector and gripper actions. Predicted bridging translations align closely with predicted 6D end-effector actions when projected into the same head-camera frame. When task-specific robot demonstrations are converted to the bridging translation, performance rises substantially, confirming the representation is effective and benefits from reduced observation and noise gaps. Contact-rich failures correlate with the decision to discard wrist rotation supervision from human data, suggesting that injecting limited reliable rotation cues could help.

Co-training with translation-only bridging actions yields substantially higher overall task progress and success rates compared to using 6DoF human wrist actions, as the simpler representation leads to more stable learned behaviors and aligns closely with the robot's executable action space. This alignment allows the bridging signal to serve as a reliable alternative for robot actions, though performance remains limited in tasks that critically depend on precise rotational control. Overall progress improves from 34.67% with 6DoF human actions to 44.58% with the translation-only bridging action, and success rates nearly double (12.50% vs. 22.50%). The bridging action closely matches the 6DoF robot action across diverse tasks, explaining why translation-only pre-training transfers effectively, while discarding rotation cues causes failures in contact-rich tasks like straw insertion and drawer opening.

Human-only pre-training with non-executable wrist-translation actions substantially improves few-shot robot post-training data efficiency, raising overall progress from 53.8% to 71.2% and success rate from 35.8% to 55.0%. Gains were largest on mug/cup and other tasks, while drawer tasks declined, revealing task-dependent transfer. The bridging action aligns closely with the robot's full 6DoF end-effector action, explaining why supervision on these non-executable signals transfers to executable skills. Overall progress and success rates rose markedly with human-only pre-training, despite the model never seeing executable actions during that stage. Mug/cup tasks benefited the most: success rate jumped from 6.3% to 46.9%, while drawer tasks saw a drop in both progress and success after pre-training. The bridging action projections closely match the 6DoF end-effector actions in camera views, indicating a shared representation that aids transfer across embodiments.

Supervising the bridging action on robot data during co-training is essential for effective manipulation skill transfer. Removing this objective causes the overall success rate to drop from 38.33% to 12.50%, with consistent performance declines across all task groups, including microwave, drawer, mug, and other tasks. The results confirm that the bridging signal aligns the robot's learning with the transferable knowledge from human demonstrations. Overall success rate roughly triples when the bridging objective is included. Mug and cup tasks completely fail (0% success) without bridging supervision. Progress scores also decline universally, indicating weaker task intent understanding without the bridging signal.

When the embodiment gap is removed by using robot data with no observation mismatch and low action noise, the bridging objective achieves substantially higher skill transfer than co-training with human data. Gains are especially large for mug/cup and drawer tasks, where success rates more than double, demonstrating that the bridging representation becomes increasingly effective as visual and action discrepancies diminish. The upper-bound variant improves overall progress from about 60% to nearly 74% and overall success from 38% to 56% compared to the default human co-training approach. Mug/cup tasks see the largest relative improvement, with success rising from 15.6% to 53.1% and progress from 52.5% to 81.3%. All task groups benefit, confirming that the bridging representation itself provides an effective medium for skill transfer and scales with cleaner action and perception.

The evaluation setup uses in-the-wild human video and robot teleoperation data to train policies with a bridging wrist-translation action that omits rotation. Pre-training or co-training with this translation-only signal improves downstream task performance and few-shot data efficiency, as the bridging representation aligns closely with the robot’s full 6D end-effector action, especially when the visual and action-noise gaps between embodiments are minimized. The benefit is lost if bridging supervision is removed during robot co-training, and contact-rich tasks that require rotation still suffer, indicating that the translation-only bridging provides a stable, transferable scaffold while limited rotation cues could address its remaining weaknesses.