Command Palette
Search for a command to run...
MultiHashFormer : Modèles de langage génératifs basés sur le hachage
MultiHashFormer : Modèles de langage génératifs basés sur le hachage
Huiyin Xue Atsuki Yamaguchi Nikolaos Aletras
Résumé
Les modèles de langage (LMs) représentent les jetons à l’aide de matrices d’incorporation dont la taille croît linéairement avec celle du vocabulaire. Pour limiter l’empreinte paramétrique, des travaux antérieurs proposent de hacher de nombreux jetons en un seul vecteur dans des modèles uniquement encodeurs. Bien que cela offre une efficacité paramétrique, les collisions plusieurs-vers-un empêchent son utilisation dans les LMs causaux. Dans cet article, nous proposons MULTIHASHFORMER, un nouveau cadre permettant l’autorégression basée sur le hachage. Chaque jeton est représenté par une signature de hachage unique, une courte séquence d’identifiants de hachage discrets, générée par plusieurs fonctions de hachage indépendantes. Un encodeur de hachage compresse cette signature en un vecteur latent unique destiné à être traité par un décodeur Transformer. Ensuite, un décodeur de hachage génère la signature de hachage du jeton suivant, qui est ensuite reconvertie en texte. Nous évaluons notre approche aux échelles de 100M, 1B et 3B paramètres, montrant que MULTIHASHFORMER surpasse systématiquement les LMs Transformer standard sur plusieurs benchmarks. De plus, nous montrons que notre modèle gère l’expansion du vocabulaire multilingue avec une empreinte paramétrique constante et sans aucune modification.
One-sentence Summary
Researchers from the University of Sheffield propose MULTIHASHFORMER, a hash-based autoregressive language model that represents tokens as unique collision-free hash signatures via multiple independent hash functions, and it outperforms standard Transformers at 100M, 1B, and 3B parameter scales across multiple benchmarks while enabling multilingual vocabulary expansion with a constant parameter footprint.
Key Contributions
- The paper introduces the first hash-based framework for causal language modeling that prevents token collisions by generating each token as a unique signature from multiple independent hash IDs, enabling deterministic autoregressive text generation.
- Empirical evaluations at 100M, 1B, and 3B parameter scales show that MULTIHASHFORMER consistently outperforms standard Transformer language models across 10 tasks and yields stronger representations for rare words.
- The approach supports vocabulary expansion without changing the architecture or increasing the parameter count, maintaining performance when growing from 32K to 48K tokens.
Introduction
Language models rely on large embedding matrices that scale linearly with vocabulary size, which limits their ability to adapt to new domains or languages without retraining. Prior work introduced hash-based embeddings to fix the parameter footprint, but these many-to-one mappings cause token collisions that make autoregressive decoding impossible because a decoder cannot uniquely recover a specific token from a shared hash index. The authors propose MULTIHASHFORMER, a generative framework that replaces the single embedding matrix with multiple independent hash functions, giving each token a unique multi-ID signature. This collision-free design supports causal language modeling with sub-linear parameter growth, outperforms standard Transformers at multiple scales, and enables vocabulary expansion without adding parameters.
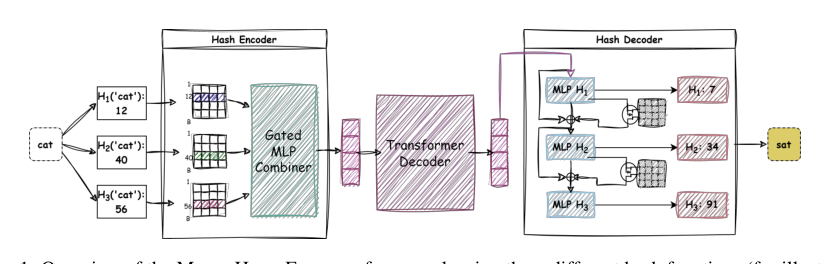
Method
The authors propose MultiHashFormer, a framework designed to bypass the vocabulary bottleneck for decoder-based language models. The architecture comprises three primary modules: a Hash Encoder, a Sequence Processing Backbone, and a Hash Decoder.
The Hash Encoder maps discrete input tokens into distributed multi-ID signatures and compresses them into dense embeddings. For multi-hash indexing, the authors use H independent hash functions, specifically the MurmurHash3 algorithm, to compute the signature coordinates. To ensure collision-free mapping for every token in the vocabulary, an iterative rehashing strategy is employed. If a new token's signature conflicts with an existing entry, the seed of the final hash function is incrementally modified until an unused signature is found. To resolve ambiguity from globally shared hash buckets, the authors introduce a Gated Compositional Embedding. Each hash coordinate passes through a feed-forward bottleneck network with a compression dimension dz≪d, followed by softmax normalization to determine the contribution of each bucket. A linear adapter matrix Ws then projects the combined representation into the latent space of the sequence processing backbone:
e=(∑i=1Hα~iE[Hi(w),:](i))Ws
where the gating weights α~i are computed via a bottleneck projection.
The Sequence Processing Backbone converts these embeddings into contextualized representations. The sequence of hash embeddings X=[e1,e2,…,en]⊤ passes through a standard stack of L Transformer layers. At each time-step t, the final layer emits a contextualized latent vector ht, which is subsequently fed to the Hash Decoder.
The Hash Decoder auto-regressively reconstructs the multi-ID signature of the next token using an auto-regressive Cascaded Predictor. This module iteratively refines index predictions, functioning as a structured error-correcting system. The prediction loop is initialized with the final hidden state of the backbone at the current timestep t, setting the root state c(1)=ht. For each sequential hash head i∈{1,…,H}, the decoder projects the current latent hash state c(i) to compute a logit distribution o(i) over the physical bucket allocations using dedicated weight matrices Wo(i), where the input and output embedding weights are tied. For non-terminal heads, the decoder computes a soft bucket embedding e(i) as the expected value of the shared embedding matrix weighted by the logit probabilities, preserving differentiability. To propagate the contextualized trajectory to the next signature head, a recursive cascade mixer updates the internal hash state by concatenating the existing state with the retrieved soft embedding and routing it through a bottleneck layer with a structural residual connection:
c(i+1)=c(i)+Wup(i)⊤σ(Wdn(i)⊤[c(i)e(i)])
Finally, the authors detail the probability modeling for both training and inference. During training, the model optimizes the product of independent coordinate probabilities over a virtual vocabulary space, allowing predictions over coordinate combinations that might not map to actual vocabulary entries to simplify the optimization objective. During inference, to prevent the generation of invalid signatures, the probability distribution is explicitly re-normalized strictly over the true token vocabulary by accumulating the log-probabilities of individual hash IDs and applying a standard softmax normalization over the valid token space.
Experiment
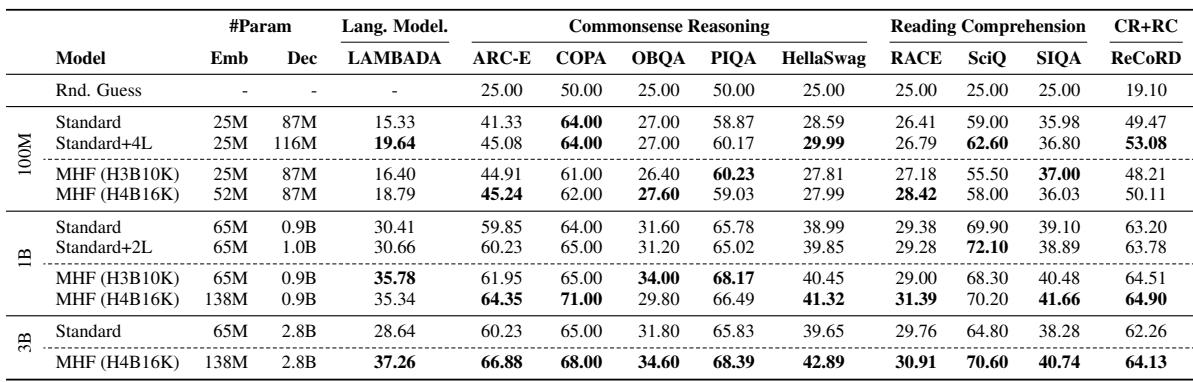
The evaluation compares MULTIHASHFORMER models with token embeddings built via multi-hash signatures against standard and depth-augmented decoder-only Transformers at 100M, 1B, and 3B parameters, testing language modeling, commonsense reasoning, reading comprehension, rare-word similarity, and zero-parameter multilingual vocabulary expansion. At 1B and 3B scales, MULTIHASHFORMER consistently outperforms parameter-matched baselines, particularly on context-sensitive prediction tasks like LAMBADA, while also yielding better semantic representations of rare words and maintaining English performance after adding 15K new language tokens without extra parameters. Multi-hash signatures prove essential to avoid representation collisions, and the H4B16K configuration offers the best balance of embedding capacity and accuracy, with randomized hashing proving sufficient and locality-sensitive hashing offering no consistent gain.
MultiHashFormer decouples vocabulary allocation from model depth, consistently outperforming standard baselines on language modeling and commonsense reasoning across scales. The H4B16K configuration achieves the best balance, with gains becoming more pronounced as parameter count grows from 100M to 3B, while strict parameter-matching shows hash-based variants are more effective than adding layers. At the 1B scale, MultiHashFormer variants surpass standard counterparts on 8 out of 10 tasks, with MHF (H4B16K) reaching 64.90 on ReCoRD versus 63.78 for the Standard+2L baseline. Increasing model capacity from 1B to 3B, MHF (H4B16K) yields a large LAMBADA improvement of 8.62% over the standard model, demonstrating scaling efficacy.
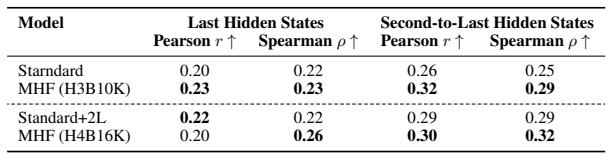
On the Card-660 dataset, MULTIHASHFORMER models achieve higher correlations with human semantic similarity judgments than Standard models at equivalent parameter counts. The improvement is most pronounced in the second-to-last decoder hidden states, where representations are less biased toward training tasks, confirming that Multi-ID hashing better captures rare word semantics. MULTIHASHFORMER variants consistently surpass Standard and Standard+2L models on both Pearson and Spearman correlation metrics. The performance gap between MULTIHASHFORMER and Standard models is larger when measured from the second-to-last hidden states than from the last hidden states. The MHF (H4B16K) configuration yields the highest Spearman correlation (0.32) at the second-to-last layer, indicating stronger alignment with human similarity ratings.
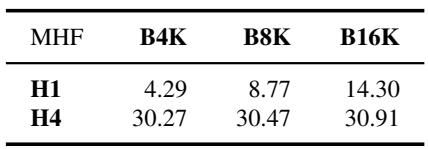
Switching from Single-ID to Multi-ID signatures dramatically improves LAMBADA accuracy, with Multi-ID (H4) achieving around 30% across all bucket sizes while Single-ID (H1) peaks at only 14.30%. The benefit is especially stark at the smallest bucket size, where Multi-ID raises accuracy from 4.29% to 30.27%, indicating that preventing hash collisions is far more effective than simply increasing bucket capacity. Multi-ID signatures consistently achieve near 30% LAMBADA accuracy, whereas Single-ID signatures fail to exceed 15% even with 16K buckets. The gap between Multi-ID and Single-ID is largest at the smallest bucket size, where Multi-ID boosts accuracy from 4.29% to 30.27% at B4K, illustrating that collision avoidance is more impactful than scaling bucket count.
Replacing standard random hash functions with locality-sensitive hashing in the multi-hash embedding model does not lead to consistent gains on LAMBADA accuracy. Performance hovers around 31% across all ratios, with no clear advantage for LSH even when used exclusively. This suggests that the morphological bias from LSH is unnecessary given the data-driven flexibility of the base hashing scheme. LAMBADA accuracy remains near 31% when shifting from all-MMH3 (30.91) to all-LSH (31.36), with intermediate mixes showing no monotonic trend. The highest accuracy (31.40) occurs with three LSH and one MMH3 function, but the improvement over the all-MMH3 baseline is marginal. The standard deterministic hashing (MMH3) already provides sufficient representational freedom, making the explicit morphological prior of LSH redundant for subword learning.

MultiHashFormer decouples vocabulary allocation from model depth and employs multi-ID hashing to mitigate collisions, with evaluations spanning language modeling, commonsense reasoning, and semantic similarity tasks. The approach consistently outperforms standard transformers, and the H4B16K configuration scales effectively, yielding larger gains as model size increases from 100M to 3B parameters. Multi-ID hashing dramatically improves accuracy over single-ID by avoiding collisions rather than merely expanding capacity, and the model's representations align more closely with human semantic judgments, especially in intermediate layers, while locality-sensitive hashing offers no benefit over standard random hashing.