Command Palette
Search for a command to run...
ViQ : Représentations visuelles quantifiées alignées sur le texte à n'importe quelle résolution
ViQ : Représentations visuelles quantifiées alignées sur le texte à n'importe quelle résolution
Xumin Yu Zuyan Liu Zhenyu Yang Yuhao Dong Shengsheng Qian Jiwen Lu Han Hu Yongming Rao
Résumé
Une représentation unifiée du texte et de la vision constitue une quête naturelle, car elle permet une modélisation multimodale plus simple et un entraînement plus efficace. Cependant, représenter les images comme des signaux discrets, de la même manière que le texte, introduit inévitablement une perte d'information sévère. Les travaux existants peinent à équilibrer les détails de bas niveau et la sémantique de haut niveau dans les représentations discrètes : les représentations orientées vers la reconstruction manquent souvent d'informations sémantiques, tandis que les caractéristiques plus riches sur le plan sémantique souffrent généralement d'une perte sévère de détails. Nous présentons ViQ, un cadre de Représentations Visuelles Quantifiées, conçu pour équilibrer sémantique et détails dans les représentations discrètes tout en prenant en charge des entrées à leurs résolutions natives, lui permettant ainsi de servir de représentation discrète unifiée et générale pour des entrées visuelles arbitraires. Notre approche structure l'apprentissage de la quantification en deux étapes : un pré-entraînement aligné sur le texte et une discrétisation des caractéristiques. Grâce au pré-entraînement aligné sur le texte, nous renforçons la supervision riche en sémantique du codeur visuel à partir du modèle de langage pré-entraîné et lui permettons de traiter des entrées visuelles à résolution native. Lors de la discrétisation, nous proposons une stratégie d'apprentissage de représentation proximale pour compacter progressivement l'espace de caractéristiques, ainsi qu'un mécanisme de quantification par tête sensible à la position qui permet un traitement flexible de résolutions arbitraires. De nombreuses expériences sur des tâches multimodales démontrent que ViQ atteint des performances compétitives par rapport aux encodeurs visuels multimodaux de pointe dotés de caractéristiques visuelles continues et de haute dimension, tout en maintenant une grande précision dans la reconstruction de bas niveau. Nous montrons également que l'entraînement multimodal avec des représentations visuelles quantifiées améliore considérablement l'efficacité, offrant une accélération allant jusqu'à 20%-70% selon les LLM de base et les recettes d'entraînement utilisées.
One-sentence Summary
ViQ is a visual quantization framework that balances high-level semantics and low-level details by integrating text-aligned pre-training for native-resolution processing with a proximal representation learning strategy and position-aware head-wise quantization, yielding a unified discrete representation that enables simpler multimodal modeling and more efficient training across arbitrary resolutions.
Key Contributions
- The paper introduces ViQ, a visual quantized representations framework that balances low-level details and high-level semantics in discrete formats while natively supporting arbitrary input resolutions.
- The framework structures quantization learning into text-aligned pre-training and feature discretization phases, employing a proximal representation learning strategy to compact the latent space and a position-aware head-wise quantization mechanism to preserve resolution flexibility.
- Evaluated across nine multimodal benchmarks and reconstruction tasks, the framework outperforms existing quantized models and achieves performance competitive with continuous encoders such as InternViT, AIMv2, and SigLIP2. Training efficiency improves by 20% to 70% across varying sequence lengths, while reconstruction fidelity achieves a PSNR of 22.73 and an rFID score of 0.62.
Introduction
Multimodal large language models benefit from unified representations that align vision and text, enabling simpler modeling and improved training efficiency. However, continuous visual features mismatch the discrete token structure of language and impose heavy computational costs, while existing discrete quantization methods often fail to balance high-level semantics with low-level visual details. The authors introduce ViQ, a framework that produces text-aligned visual quantized representations capable of handling native resolutions. By combining text-aligned pre-training with a proximal representation learning strategy and position-aware head-wise quantization, ViQ achieves competitive multimodal performance and reconstruction fidelity while delivering significant training speedups.
Method
The authors introduce ViQ, a visual quantization framework designed to bridge raw pixels and compact latent representations for multimodal learning. The architecture processes images at any resolution through a specific pipeline that converts continuous features into discrete codes.
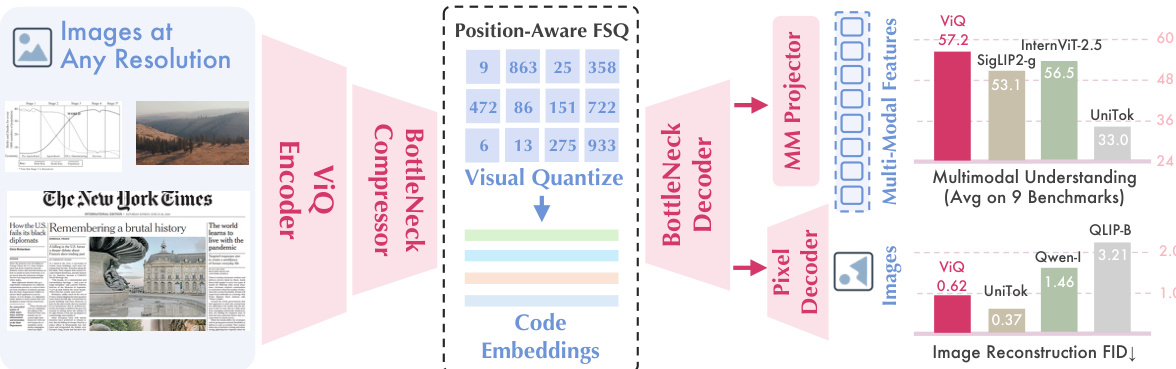
As shown in the framework diagram, input images first pass through a ViQ Encoder to extract high-dimensional features. These features are then compressed by a Bottleneck Compressor. The core module, Position-Aware FSQ, visualizes the quantization process where continuous features are mapped to discrete code embeddings. The BottleNeck Decoder then reconstructs these embeddings. The output branches into two paths: an MM Projector for generating multi-modal features for language models and a Pixel Decoder for image reconstruction tasks.
The training process follows a two-stage approach to ensure robust alignment and effective quantization. In the first stage, text-aligned pre-training aligns the visual encoder with language embeddings. To support native resolution inputs, the model replaces fixed positional embeddings with resized positional embeddings that dynamically adjust dimensions. The optimization combines a text-guided cross-entropy loss and a self-distillation loss. The text loss is defined as:
Ltext=Cross Entropy[LLM(ViQ(I), T), A]The self-distillation loss ensures semantic consistency with a fixed-resolution teacher model using cosine similarity:
Ldistill=1−cos(zsstudent,zsteacher)The second stage involves progressive quantization of the continuous features.
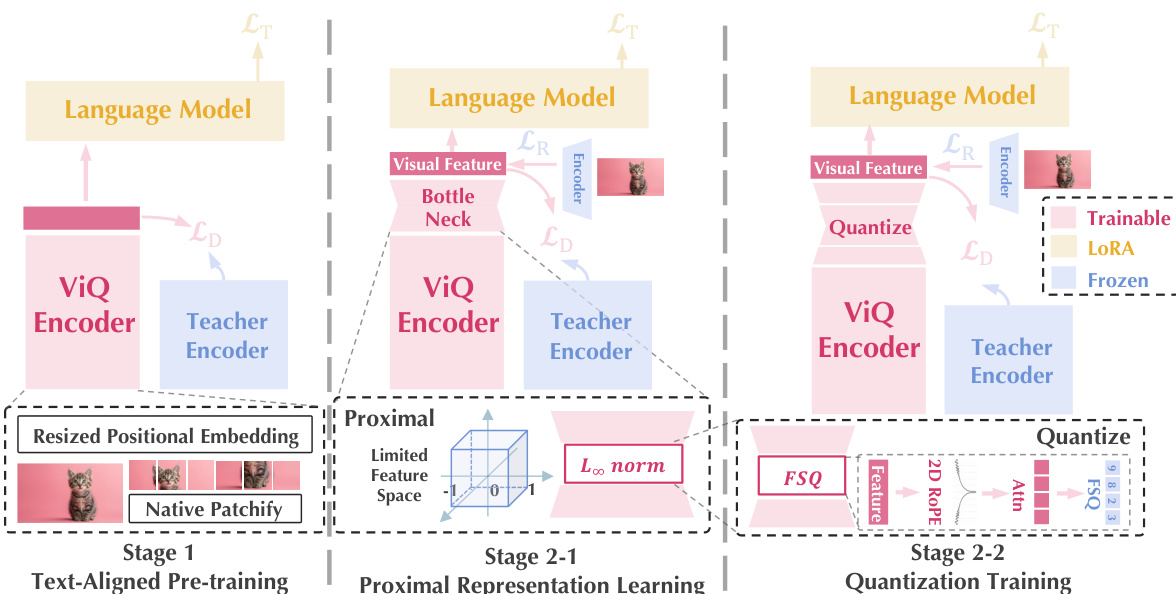
This stage begins with proximal representation learning. High-dimensional features are compressed via a bottleneck layer and constrained to a hypercube surface using the L∞ norm to reduce feature space complexity. The feature transformation is formulated as:
f1=L∞(BN(f)),f^=BN′(f1)Following this, the model employs Multi-Head Finite Scalar Quantization (FSQ). To enhance representational capacity, a multi-head attention mechanism expands each visual patch into a 2×2 grid of codes. Additionally, 2D Rotary Position Embedding (RoPE) is applied to encode spatial resolution information:
f~m=fm⊙ei(hθh+wθw)To preserve low-level details, the training incorporates a reconstruction loss supervised by a pre-trained visual autoencoder. The total objective combines the text loss, distillation loss, and reconstruction loss:
Ltotal=λtextLtext+λdistillLdistill+λreconLreconExperiment
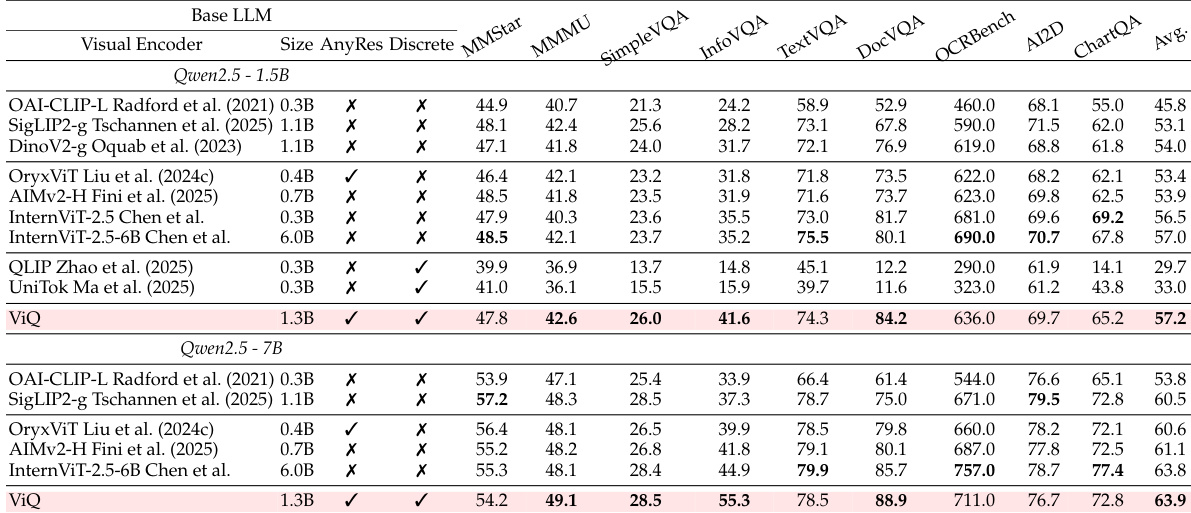
The evaluation integrates ViQ with varying-scale language models and benchmarks it against general, multimodal-specialized, and quantized visual encoders across comprehensive understanding tasks, training efficiency tests, and image reconstruction pipelines. These experiments validate that ViQ achieves compact visual representations that preserve strong perceptual and semantic capabilities, particularly excelling in text- and document-centric tasks while delivering substantial training speed-ups through precomputed discrete codes. Ablation studies further confirm that gradually regularizing the latent space, employing non-learnable codebooks, and combining targeted reconstruction losses effectively balance low-level fidelity with high-level alignment. Overall, the findings establish ViQ as an efficient visual encoder that successfully navigates the trade-off between aggressive compression and robust multimodal understanding.
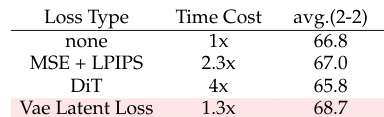
The authors evaluate different reconstruction loss formulations to optimize the training process. The experiments demonstrate that the VAE latent loss yields the best performance while being more computationally efficient than complex alternatives like MSE combined with LPIPS. The VAE latent loss achieves the highest average performance compared to other loss types. It requires less computational time than the MSE and LPIPS combination. It outperforms the baseline configuration with no specific loss.
The authors compare the performance of FSQ and SimVQ quantization methods across varying codebook sizes. The findings show that FSQ consistently outperforms SimVQ, and reducing the codebook size leads to better results for both approaches. FSQ achieves higher average performance than SimVQ. Smaller codebook sizes improve performance for FSQ. SimVQ performance declines as the codebook size increases.

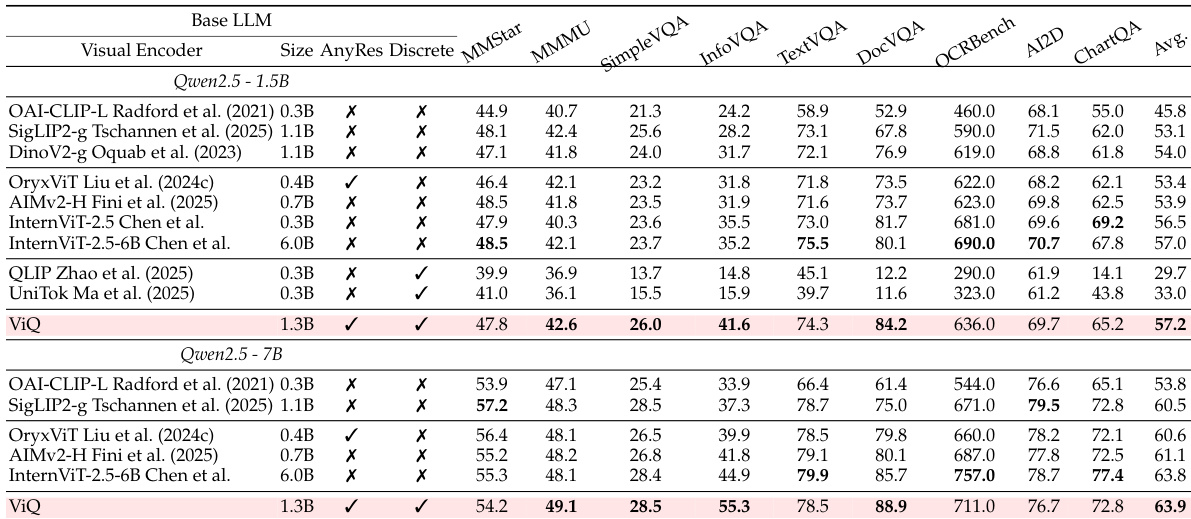
The authors evaluate ViQ against various visual encoders on multimodal understanding benchmarks to assess its effectiveness. The results demonstrate that ViQ achieves competitive overall performance, frequently matching or surpassing continuous encoders while significantly outperforming existing quantized models. It exhibits particular strength in text and document-centric tasks, validating its capability as a compact visual representation. ViQ achieves higher average scores than most continuous visual encoders across different model sizes. The model significantly outperforms previous quantized baselines on multimodal understanding benchmarks. ViQ demonstrates superior performance in text and document recognition tasks compared to other encoders.
The authors investigate the impact of bottleneck width on the model's average performance across multiple benchmarks. The results demonstrate that a significantly reduced bottleneck width can achieve performance levels comparable to the widest configuration. This suggests that the model maintains robustness and quality even with substantial dimensionality reduction. A narrower bottleneck width achieves performance similar to the widest configuration. Reducing the width does not cause significant performance degradation. The model preserves high average scores despite reduced dimensionality.

The evaluation setup systematically tests key training and architectural components, validating that the VAE latent loss optimizes both reconstruction quality and computational efficiency compared to complex alternatives. Quantization analysis reveals that FSQ consistently outperforms SimVQ, with smaller codebook sizes further enhancing results across both methods. When benchmarked against standard visual encoders, the proposed ViQ model matches or exceeds continuous approaches on multimodal tasks while significantly surpassing prior quantized baselines, particularly in text and document understanding. Finally, bottleneck width tests confirm that substantial dimensionality reduction preserves overall performance, validating the framework's robustness and compact design.