Command Palette
Search for a command to run...
RoboAtlas : SLAM Actif Contextuel
RoboAtlas : SLAM Actif Contextuel
Alexander Schperberg Shivam K. Panda Abraham P. Vinod M. K. Jawed Stefano Di Cairano
Résumé
Nous présentons RoboAtlas, un cadre Active SLAM contextuel qui équilibre de manière adaptative l'exploration géométrique et le raisonnement sémantique en s'appuyant sur un système de cartographie sémantique 3D évolutif, OpenRoboVox. RoboAtlas intègre l'exploration des frontières, le raisonnement sur la carte sémantique globale et le raisonnement égo-centrique fondé sur les VLM au moyen d'un bandit multi-bras contextuel, permettant de passer progressivement de l'exploration à une navigation guidée sémantiquement à mesure que la compréhension de la scène s'affine. Nous évaluons le système en simulation et sur un robot Unitree Go2 dans des environnements réels à grande échelle (supérieurs à 1800 m2) contenant environ 30 000 instances sémantiques cartographiées, atteignant un taux de réussite de tâche de 100 %. Sur le benchmark GOAT-Bench « Val Unseen », RoboAtlas atteint des performances de pointe, enregistrant le taux de réussite (SR) le plus élevé rapporté à ce jour de 90,6 % avec GPT-4o, soit une amélioration de 17,8 points de pourcentage par rapport à la meilleure baseline précédente en termes de SR. Grâce à l'utilisation du modèle nettement plus léger Qwen2.5-VL-7B, le système atteint toujours un SR de 88,8 %, surpassant toutes les baselines utilisant GPT-4o en termes de SR. Ces résultats mettent en évidence l'importance des informations acquises par notre cadre de cartographie sémantique, qui s'avèrent plus déterminantes que le simple remplacement du modèle fondamental sous-jacent. Ces résultats démontrent que l'ancrage des modèles fondamentaux sur des cartes sémantiques 3D à grande échelle permet de réaliser un Active SLAM contextuel à la fois robuste et efficace.
One-sentence Summary
RoboAtlas is a contextual Active SLAM framework that employs a contextual multi-armed bandit to transition from frontier exploration to semantically guided navigation using the OpenRoboVox 3D semantic mapping system, achieving 100% task success on a Unitree Go2 robot across environments exceeding 1800 m² with approximately 30,000 semantic instances and securing state-of-the-art GOAT-Bench "Val Unseen" success rates of 90.6% with GPT-4o and 88.8% with Qwen2.5-VL-7B to demonstrate that large-scale semantic map grounding enables robust autonomous navigation.
Key Contributions
- RoboAtlas is a contextual Active SLAM framework that integrates OpenRoboVox, a re-engineered 3D semantic mapping system designed for scalable real-time deployment on physical robots. OpenRoboVox enhances the original OpenVox architecture through memory-efficient TSDF management, asynchronous semantic processing, and a reduced-order 2D pillar map representation for fast inference.
- The system employs a contextual multi-armed bandit policy to dynamically fuse frontier exploration, global semantic-map reasoning, and egocentric vision-language model cues. This adaptive decision mechanism enables a transition from broad geometric exploration to targeted semantic search as contextual evidence accumulates.
- Evaluations on a Unitree Go2 robot in environments exceeding 1800m2 and on the GOAT-Bench "Val Unseen" benchmark establish state-of-the-art navigation performance. The framework achieves a 90.6% success rate with GPT-4o, improving upon the strongest prior baseline by 17.8 percentage points, while an 88.8% success rate with Qwen2.5-VL-7B demonstrates the critical role of the semantic mapping architecture over foundation model selection alone.
Introduction
Active Simultaneous Localization and Mapping (Active SLAM) enables robots to autonomously navigate unknown environments by optimizing trajectories for information gain. Contextual Active SLAM extends this capability by integrating foundation models to support high-level reasoning tasks such as semantic search and object-goal navigation, addressing the inability of purely geometric approaches to handle complex, language-conditioned directives. Prior work, however, faces notable limitations. Many pipelines rely on low-fidelity geometric representations or heuristic objectives that constrain high-level reasoning, while recent zero-shot vision-language methods often decouple semantic reasoning from metric localization, ignoring platform-specific constraints like map fidelity and planning feasibility. Furthermore, scalable semantic mapping frameworks frequently lack real-time deployment capabilities on physical hardware, often assuming idealized conditions or relying on offline evaluation. To overcome these challenges, the authors present RoboAtlas, a contextual Active SLAM framework that adaptively balances geometric exploration and semantic reasoning via a contextual multi-armed bandit. The system leverages OpenRoboVox, a scalable 3D semantic mapping engine, to fuse frontier exploration, global semantic-map reasoning, and egocentric vision-language cues within a mixture-of-experts architecture. This design enables the robot to transition smoothly from coarse exploration to targeted semantic navigation as contextual evidence accumulates. RoboAtlas achieves state-of-the-art performance on benchmarks, demonstrating that grounding foundation models with large-scale, real-time 3D semantic maps significantly enhances navigation robustness and efficiency.
Method
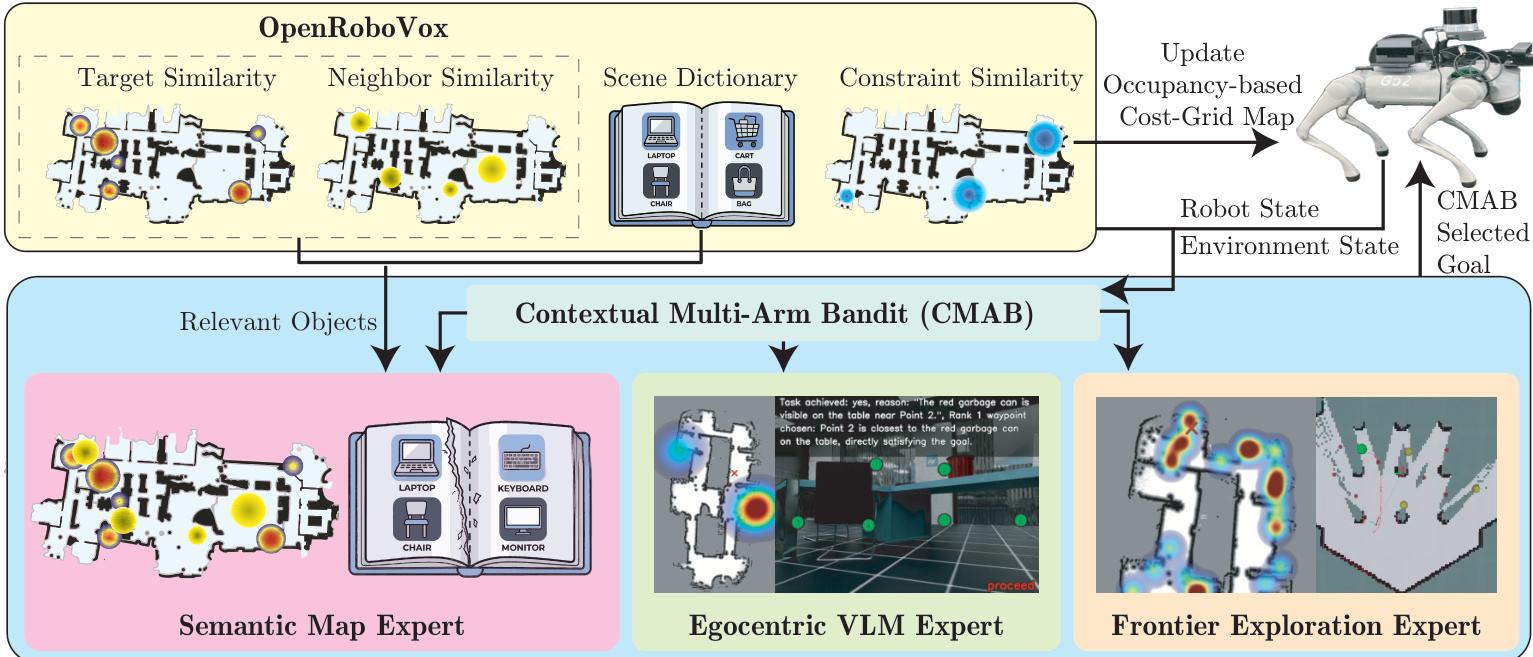
The authors propose RoboAtlas, a contextual Active SLAM framework that integrates real-time semantic mapping with an adaptive goal-selection policy. Refer to the framework diagram for the complete system architecture. The pipeline operates asynchronously, decoupling geometric tracking from semantic reasoning to ensure real-time performance on resource-constrained hardware. At each decision epoch, the system constructs a contextual state vector and employs a Contextual Multi-Armed Bandit (CMAB) to dynamically select among three navigation experts: a frontier-based explorer, a semantic map reasoner, and an egocentric vision-language model (VLM) expert.

OpenRoboVox Semantic Mapping Module To support language-guided navigation, the authors introduce OpenRoboVox, a hardware-efficient, instance-level semantic mapping framework. The perception pipeline ingests RGB and depth streams to perform semantic mask detection and GPU-optimized Truncated Signed Distance Field (TSDF) integration. The system maintains a global instance registry where each voxel preserves a probabilistic representation of object identities. To address memory constraints during large-scale mapping, OpenRoboVox implements a block-based volumetric transfer protocol that bounds peak VRAM usage by transferring disjoint cubic blocks sequentially rather than duplicating the entire tensor. Furthermore, the framework decouples semantic processing from geometric tracking via an asynchronous parallel architecture. A Scene-Dictionary manager operates as a background process, incrementally extracting object centroids, bounding boxes, and occupancy probabilities from the voxel map. This manager employs a priority-based scheduling algorithm that selects a bounded batch of instances for update based on temporal recency, active observation frustums, and rotational consistency. The resulting Scene-Dictionary St provides a compact, queryable representation that bridges raw voxel data with high-level planning.
Contextual Multi-Armed Bandit and Reward Formulation The navigation decision layer formulates goal selection as an adaptive problem using a Contextual Multi-Armed Bandit. The bandit maintains a set of arms corresponding to the expert policies E={EFrontier,ESemanticMap,EEgoVLM}. At each replanning step t, the agent observes a context vector ct summarizing occupancy coverage, semantic similarity metrics, backtracking indicators, and recent displacement. The bandit utilizes a Linear Upper Confidence Bound (LinUCB) strategy to balance exploration and exploitation. Each arm proposes a candidate goal gt(a), and the policy selects the optimal arm at based on an optimistic reward estimate. The reward function is formulated as a weighted combination of map coverage expansion, semantic relevance, VLM confidence, and penalties for backtracking or repeated empty selections:
rt=w1m˙tocc−w2Bt+w3Vtvlm+w4Vtsim+wsuccThis reward structure encourages actions that increase map coverage and improve semantic relevance while discouraging unnecessary revisitation of previously explored regions.
Expert Architectures The frontier expert prioritizes geometric information gain by evaluating candidate goals at the boundary of explored and unexplored space. It optimizes a trade-off between expected sensor footprint coverage and travel cost, subject to energy-feasibility constraints that ensure the robot can safely return to a charging station.
The semantic map expert leverages the Scene-Dictionary St and a large language model (LLM) backend to perform open-vocabulary reasoning. The system serializes the dictionary into a textual context, applying a pre-filtering stage that retains only instances exceeding cosine similarity thresholds relative to the task query. The LLM ranks these filtered candidates based on semantic match and spatial plausibility, outputting a structured confidence score ΦLLM(Oi). The expert selects the navigation goal corresponding to the highest-scoring instance among the top-N candidates.
The egocentric VLM expert operates directly on the robot's current first-person observations. It processes the user directive alongside an annotated RGB image, where spatial annotations are pruned based on interaction range constraints. The VLM outputs discrete action primitives, including proceeding toward a candidate, rotating in place, or executing a 180-degree turn. When a navigation action is selected, the goal is set to the spatial location of the highest-confidence annotated instance. The system rolls out VLM decisions over a finite planning horizon to ensure stable behavior. Additionally, the VLM generates textual scene descriptions that are accumulated into a context dictionary, enriching the semantic map expert's reasoning capabilities.
As illustrated in the processing pipeline below:
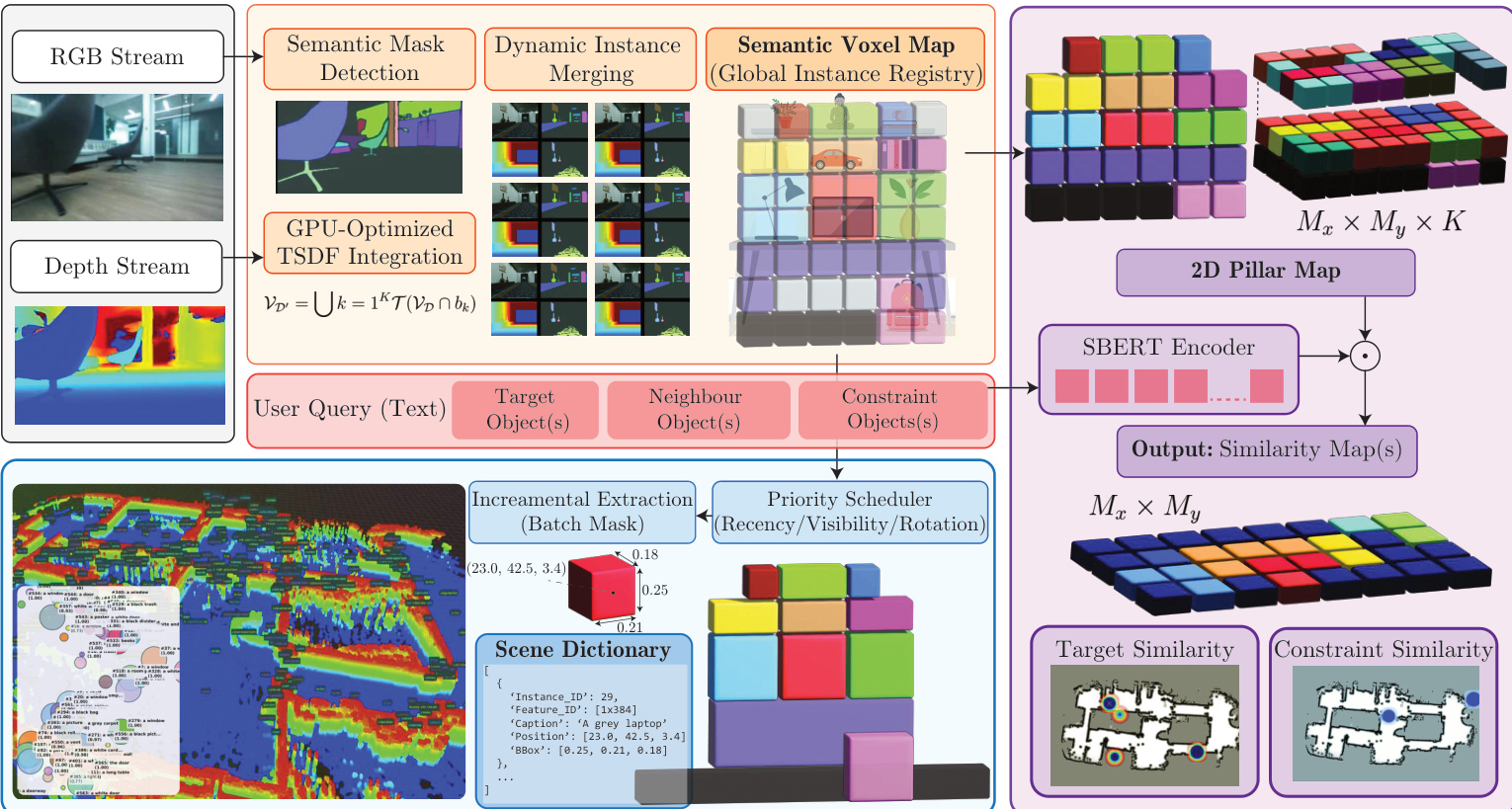
Online Policy Adaptation The bandit policy updates continuously during deployment without requiring offline training. At each replanning epoch, the agent observes per-turn rewards derived from one-step deltas in occupancy coverage, semantic similarity, and new-instance discovery rates. Upon subtask completion, a sparse macro-reward is computed based on agent-perceived evidence of target arrival and confidence. This macro-reward is distributed across the subtask's trajectory using an exponentially decaying credit assignment mechanism, biasing the policy toward arms that are proximally responsible for successful outcomes while still crediting earlier exploratory actions. The accumulated reward signals incrementally update the arm-specific covariance matrices and response vectors, enabling the system to transition naturally from coverage-driven exploration in early stages to targeted, semantics-aware navigation as contextual evidence accumulates.
Refer to the hardware validation setup below:
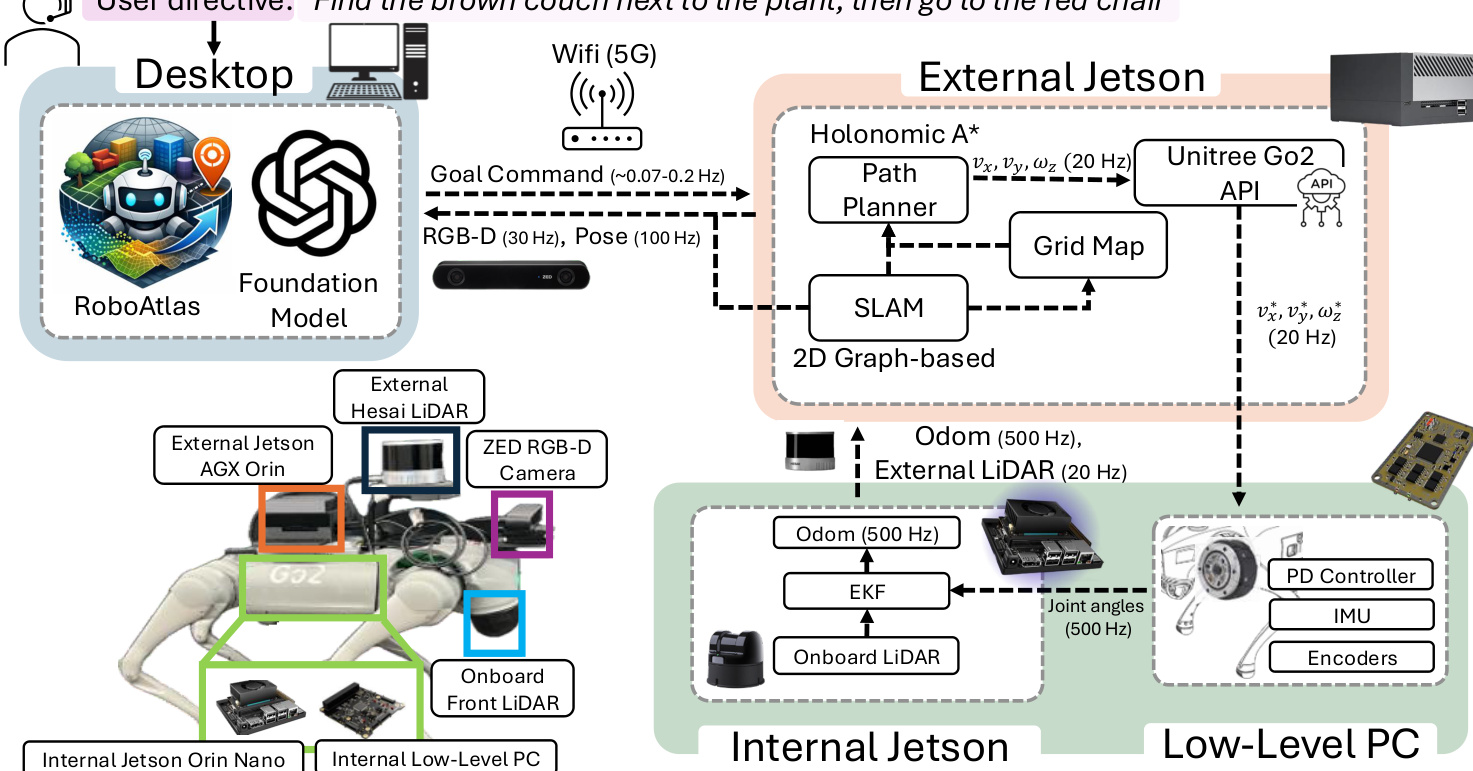
Experiment
Evaluated across real-world hardware, physics-based simulation, and photo-realistic environments, the framework validates its real-time 3D semantic mapping, adaptive decision-making, and long-horizon navigation capabilities. Experiments demonstrate that the contextual bandit policy dynamically transitions from geometric exploration to semantic reasoning as environmental coverage increases, enabling robust target acquisition in both unexplored and pre-mapped settings. Across all platforms and benchmarks, the system consistently achieves high task success rates and outperforms prior methods, even when paired with smaller foundation models. Ultimately, these results confirm that the approach effectively bridges geometric exploration and semantic navigation, though its overall reliability remains contingent on mapping fidelity, inference latency, and reward formulation.
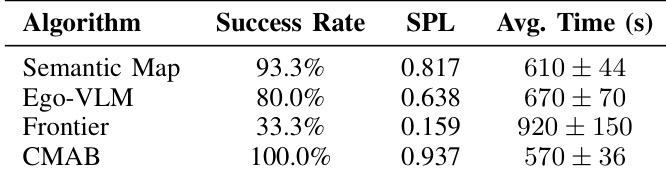
The experiment evaluates four navigation algorithms, demonstrating that the Contextual Multi-Arm Bandit (CMAB) method significantly outperforms fixed-strategy baselines. CMAB achieves the highest success rate and efficiency, completing tasks faster with shorter paths than semantic map, egocentric VLM, or frontier exploration approaches. These results highlight the advantage of dynamically selecting experts based on environmental context rather than relying on a single navigation policy. CMAB demonstrates superior performance by achieving the highest success rate and fastest completion times among all tested algorithms. Frontier exploration proves to be the least efficient strategy, yielding the lowest success rate and longest execution durations. Single-expert methods like semantic mapping and egocentric VLM show moderate performance, falling short of the adaptive CMAB approach in both reliability and speed.
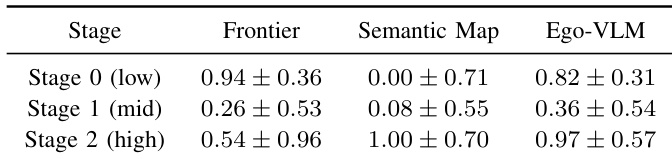
The reward structure analysis decomposes the total reward into constituent components to interpret the bandit's behavior. Semantic signals, specifically cosine similarity and VLM confidence, dominate the reward distribution, significantly outweighing exploratory factors like coverage rate. This indicates that the system shifts its focus toward semantic reasoning and exploitation as the map becomes richer. Cosine similarity is the dominant component, contributing nearly half of the total reward value. VLM confidence is the second largest positive contributor, highlighting the importance of visual reasoning. The backtracking penalty reduces the total reward, while task completion and coverage rate play minor roles compared to semantic terms.
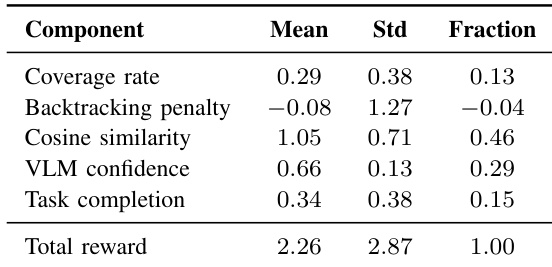
The the the table presents the normalized rewards for three decision experts across low, mid, and high environmental coverage stages. The data indicates a strategic shift where frontier exploration is most rewarding in the early low-coverage stage, ego-centric VLM leads in the mid-coverage stage, and semantic map combined with ego-centric VLM dominate in the high-coverage stage. This progression demonstrates the system's transition from geometric exploration to semantic reasoning as environmental understanding improves. Frontier exploration yields the highest reward in the low-coverage stage, prioritizing rapid geometric map expansion. Ego-centric VLM becomes the most rewarding strategy in the mid-coverage stage, indicating reliance on local semantic cues. Semantic map and ego-centric VLM achieve the highest rewards in the high-coverage stage, reflecting a shift toward semantic exploitation.
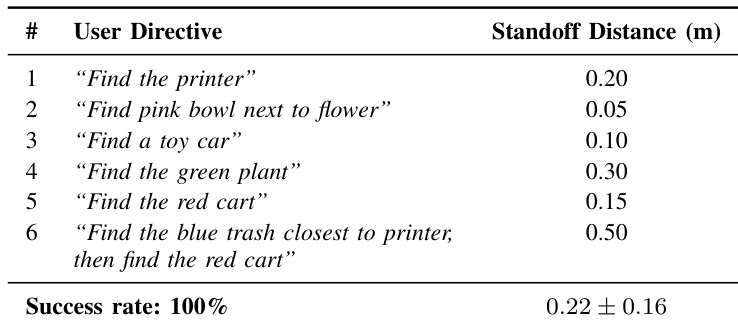
The authors evaluate the RoboAtlas framework on a physical quadruped robot, demonstrating its ability to execute diverse user directives in a real-world setting. The system achieved a perfect success rate across all trials, successfully locating targets ranging from simple objects to complex relational queries. The final standoff distance varied depending on the directive, with the authors attributing these differences to depth estimation inaccuracies and necessary safety margins for obstacle avoidance. The robot achieved a 100% success rate across all tested user directives. Standoff distances varied across tasks, with the robot maintaining a safety margin that influenced the final distance to the target. The observed distance errors were attributed to depth estimation inaccuracies and necessary safety margins enforced by the obstacle avoidance system.
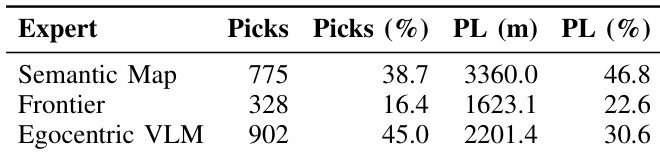
The Contextual Multi-Arm Bandit policy allocates decision-making across three distinct experts during the evaluation. The Semantic Map expert is responsible for the majority of the total path length, indicating its primary role in long-range navigation and exploitation. In contrast, the Egocentric VLM expert is selected most frequently but contributes a smaller share of the distance traveled, suggesting a focus on frequent, short-range adjustments. The Frontier expert is the least frequently chosen yet accounts for a significant portion of the path length, highlighting its specific utility for exploration. The Egocentric VLM expert is selected most frequently but contributes a smaller share of the total path length, indicating its use for frequent, short-range refinements. The Semantic Map expert accounts for the largest share of path length relative to its selection frequency, reflecting its role in long-range semantic exploitation. The Frontier expert is the least frequently chosen yet contributes a disproportionate amount of path length, suggesting it is reserved for preliminary exploration.
The experiments evaluate a Contextual Multi-Arm Bandit navigation framework against fixed-strategy baselines through both simulation and physical quadruped robot trials, validating its adaptive decision-making capabilities. Qualitative analysis demonstrates that the system strategically shifts from frontier-based geometric exploration in early stages to semantic reasoning and exploitation as environmental understanding improves, with visual and semantic signals heavily dominating the reward structure. Expert allocation further reveals a complementary division of labor, where the semantic map handles long-range navigation, the egocentric VLM manages frequent local adjustments, and frontier exploration guides initial mapping. Collectively, these findings confirm that dynamically selecting experts based on contextual cues consistently outperforms single-policy approaches, enabling reliable and efficient task execution across diverse real-world directives.