Command Palette
Search for a command to run...
Autodata : Un agent scientifique des données pour créer des données synthétiques de haute qualité
Autodata : Un agent scientifique des données pour créer des données synthétiques de haute qualité
Résumé
Nous présentons Autodata, une méthode générale permettant aux agents d’IA d’agir en tant que data scientists capables de concevoir des ensembles de données d’entraînement et d’évaluation de haute qualité. Nous montrons comment former (méta-optimiser) un tel agent « data scientist », afin qu’il apprenne à générer des données encore plus performantes. Nous décrivons la formulation générale ainsi qu’une implémentation pratique spécifique, Agentic Self-Instruct. Nous menons des expériences sur des tâches de recherche en informatique, de raisonnement juridique et de raisonnement avec des objets mathématiques, obtenant des résultats améliorés par rapport aux méthodes classiques de création de jeux de données synthétiques. Par ailleurs, la méta-optimisation de l’agent « data scientist » lui-même engendre un gain de performance encore plus important. La création de données par des agents offre un moyen de convertir l’augmentation du compute d’inférence en une formation de modèles de meilleure qualité. Globalement, nous estimons que cette voie a le potentiel de transformer notre manière de construire les données d’IA.
One-sentence Summary
The authors propose Autodata, an agentic data scientist meta-optimized via Agentic Self-Instruct to generate high-quality synthetic training and evaluation data, outperforming classical methods on computer science, legal, and mathematical reasoning tasks by converting increased inference compute into improved model training.
Key Contributions
- Autodata formulates data creation as an iterative recipe-improvement process where an AI agent acts as a data scientist that builds, analyzes, and curates training and evaluation data.
- Agentic Self-Instruct, a concrete implementation, achieves improved results over classical synthetic dataset creation methods on computer science research, legal reasoning, and mathematical object reasoning tasks.
- Meta-optimizing the data scientist agent itself delivers a further performance uplift beyond the gains of the base agentic data creation.
Introduction
The authors tackle the growing challenge of producing synthetic training and evaluation data that keeps pace with advancing AI models. While manual data collection is slow and static, prior synthetic methods such as Self-Instruct, its grounded or chain-of-thought variants, and self-challenging approaches can generate large volumes of data but lack mechanisms to directly control difficulty and quality, often requiring post-hoc filtering or evolution steps. The authors introduce Autodata, an agentic framework where a data scientist agent iteratively creates, inspects, evaluates, and refines data against explicit success criteria. Crucially, they also meta-optimize this agent so that it learns to produce even stronger data, transforming increased inference compute into higher-quality model training without human intervention.
Dataset
The authors generate a large set of verified QA pairs using an agentic self-instruct pipeline. This dataset is designed to probe multi-step reasoning and to separate strong from weak solvers. The following points summarize its composition, processing, and usage.
Dataset composition and sources
- All questions originate from a single agentic generation process. The raw output is filtered to keep only verified pairs.
- The full dataset is not sized explicitly in the provided material, but a random sample of 1,000 pairs is drawn for detailed annotation.
Key details for the annotated subset
- Annotation pipeline: 1,000 questions are classified via a two-phase LLM-based process (Kimi-K2.6). First, a taxonomy of question types is discovered from 200 items stratified by challenge score; 98 raw proposals are consolidated into 11 non-overlapping types. Then each of the 1,000 items is assigned to exactly one type. After removing parsing failures, 687 items receive valid annotations.
- Question types and distribution: The 11 types fall into three categories.
- Reasoning (roughly half of the sample): multi-step symbolic derivation, combinatorial/structural analysis, probabilistic/dynamical analysis, spectral/optimization analysis, asymptotic/scaling analysis, and proof/formal justification.
- Knowledge (about one-fifth): direct formula/identity application and factual/definitional recall.
- Mixed (about one quarter): physical modeling, algorithmic/procedural computation, and data-driven inference.
- Format rules enforced during generation:
- Each question must be atomic (exactly one thing asked, no multi-parts).
- The correct answer must be expressible in a single sentence.
- Answers must be verifiable; preferred forms are exact symbolic expressions, named entities, or short phrases that allow unambiguous equivalence checking. Bare integers and precision-sensitive real numbers are avoided.
How the paper uses the data
- The annotated sample is used to characterize the reasoning demands of the generated questions. The observed distribution confirms that the agentic pipeline produces questions emphasizing multi-step reasoning over simple recall, aligning with the goal of creating challenging data that differentiates solvers.
- No explicit training split or mixture ratios are detailed in the provided description. The annotation itself serves to validate the data’s properties rather than to define a training/validation split.
Processing and metadata construction
- The generation pipeline enforces the three format requirements (atomic, one-sentence answer, verifiable). Non-conforming outputs are filtered out.
- During annotation, parsing failures are removed, yielding the final set of 687 classified items.
- Metadata includes the assigned question type from the 11-category taxonomy and the original challenge score used for stratified sampling. No further cropping or dataset-specific preprocessing is described.
Method
The authorspropose Autodata, a framework that treats synthetic data creation as an iterative data-science process rather than a fixed prompting pipeline. As shown in the figure below, the high-level design centers on an LLM agent equipped with tools, subagent calls, and memory. This agent grounds its generation on provided source data, such as academic papers or legal documents, to create synthetic training or evaluation data. The core loop consists of two main phases: data creation and data analysis. During data creation, the agent leverages its acquired skills and inference-time compute to generate examples. Subsequently, in the data analysis phase, the agent evaluates the generated data to identify successes and failures, checking for correctness, quality, diversity, and challenge level. These learnings are fed back into the creation process to iteratively refine the dataset until a stopping criterion is met. Furthermore, the framework supports meta-optimization of the data scientist agent itself, where an outer loop optimizes the agent's harness and prompts to improve its data generation capabilities.
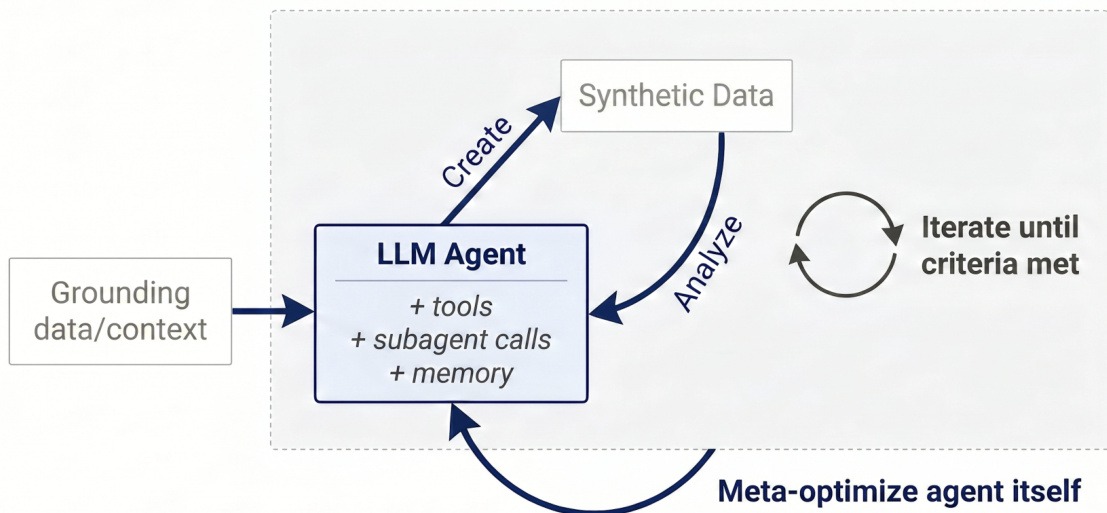
To instantiate this framework, the authors introduce Agentic Self-Instruct, a specific implementation designed to generate high-quality training data by calibrating task difficulty. As illustrated in the figure below, the main orchestrator agent directs four LLM subagents: a Challenger, a Weak Solver, a Strong Solver, and a Verifier/Judge. The Challenger generates training examples based on detailed prompts from the main agent. These examples are then evaluated by the Weak Solver, which is expected to struggle with the tasks, and the Strong Solver, which is expected to succeed. The Verifier/Judge assesses the quality of both the examples and the solver outputs, passing its learnings back to the main agent. The system aims to produce training data where the strong solver succeeds while the weak solver struggles, ensuring the examples are challenging yet solvable. If the criteria are not met, the main agent analyzes the verifier's report and modifies the prompt sent to the Challenger to generate a new example, repeating the cycle until the desired difficulty gap is achieved.
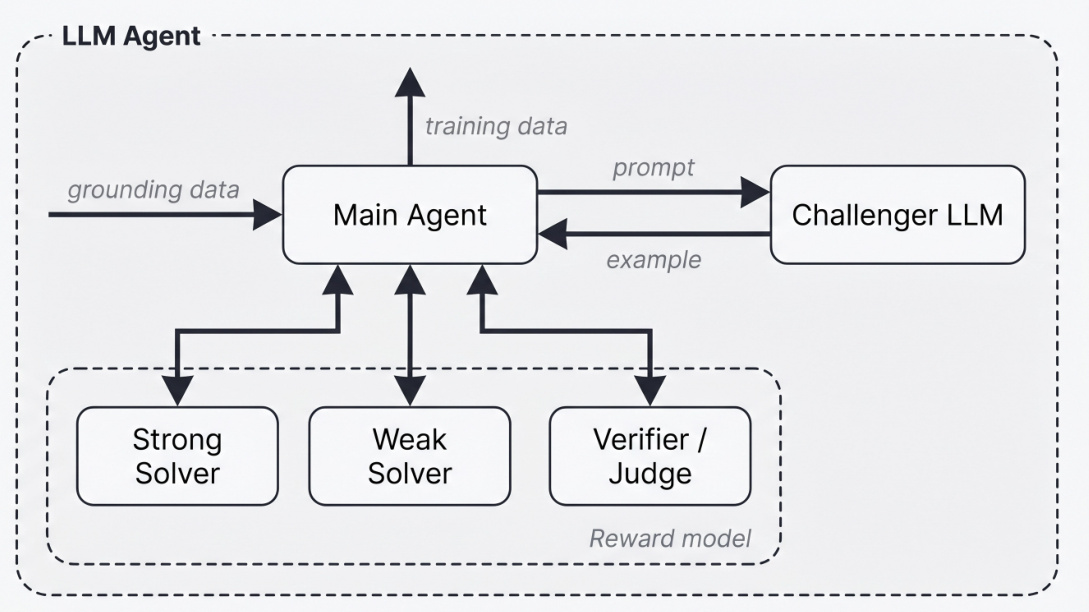
For verifiable tasks, the acceptance criteria often require a majority vote over the strong solver to be correct while the majority vote over the weak solver is wrong. For non-verifiable tasks, such as open-ended CS research questions or legal reasoning, the system relies on a rubric-based evaluation by an LLM judge. In the CS research setting, the authors define specific acceptance thresholds: the strong solver must average ≥0.65, the weak solver <0.5, and the strong-weak gap must be ≥20 percentage points. The main agent orchestrates this by calling the Challenger to generate a context-QA pair with a corresponding rubric. A quality verifier checks for context leakage and rubric coverage before the solvers attempt the task. If the criteria fail, the agent provides targeted feedback to the Challenger, specifying whether previous questions were too easy or failed on the strong solver, prompting the generation of a new question from a different reasoning angle.
The framework also allows for the meta-optimization of the data scientist agent. As depicted in the figure below, this process involves an outer loop where the agent harness itself is optimized. Using an approach similar to autoresearch, multiple workers evaluate the current agent configuration, analyze the trajectories and failure modes, and implement modifications to the main agent's prompt or workflow. The modified agent is then re-evaluated, and the best-performing configuration is selected for the next iteration, effectively automating the improvement of the data generation recipe itself.

Experiment
The evaluation spans three domains—computer science research questions, legal reasoning, and scientific problem solving—where a 4B model is trained via GRPO on data from standard CoT Self-Instruct versus the proposed Agentic Self-Instruct pipeline, which iteratively refines questions using feedback from weak and strong solvers to optimize their score separation. Qualitatively, the agentic loop corrects task-specific failure modes: it increases difficulty for CS papers to reward deeper reasoning, elevates weak-solver scores from near zero in legal tasks to produce a learnable reward signal, and generates harder but transferable scientific problems that improve both in-distribution and out-of-distribution performance while also reducing chain-of-thought truncation. A meta-optimization experiment further automates prompt improvements for the data-scientist agent itself, boosting validation pass rates and showing that the synthetic data generation process can self-improve. Overall, the findings demonstrate that dynamically creating discriminative, "just right" training examples yields stronger reasoning models and more efficient learning than static prompting methods.
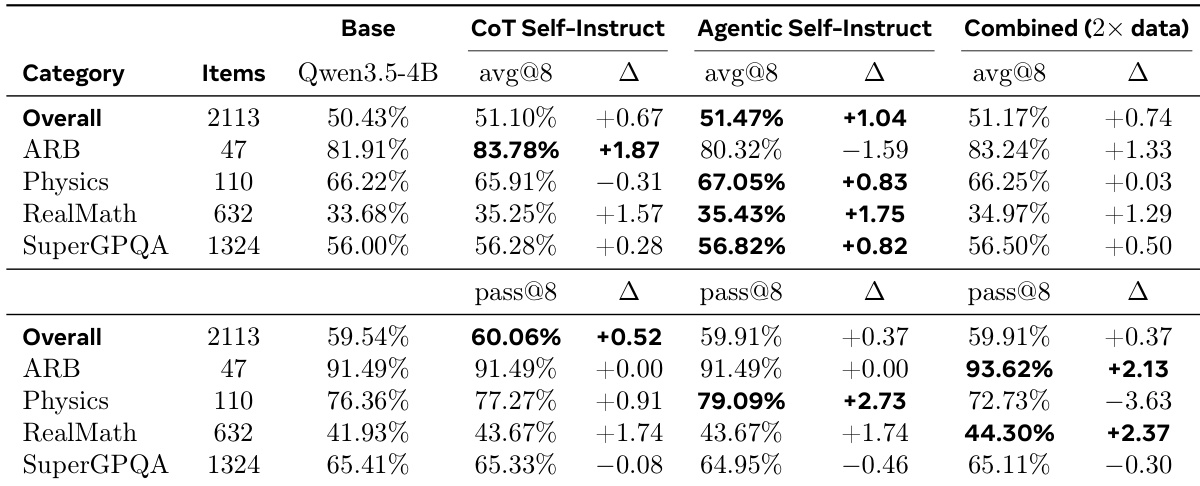
The authors evaluate out-of-distribution performance on a scientific reasoning benchmark, comparing models trained on different synthetic data sources. Results indicate that training on Agentic Self-Instruct data yields the largest overall average improvement across most categories, despite utilizing only half the data volume of the combined dataset. Conversely, the combined dataset demonstrates advantages in pass-at-eight metrics for specific categories, suggesting that increased data diversity helps the model occasionally solve a broader range of problems. Agentic Self-Instruct training consistently improves average performance across most scientific reasoning categories compared to the base model and standard CoT Self-Instruct. The combined dataset achieves the highest pass-at-eight scores in specific categories, indicating that greater data diversity aids in solving a wider variety of problems. Training on agentic data provides a more efficient learning signal, outperforming the larger combined dataset in overall average metrics.
The authors compare the performance of a 4B model trained on CoT Self-Instruct versus Agentic Self-Instruct data using reinforcement learning. Results show that training on Agentic data yields the highest performance on both easier and harder test sets, significantly outperforming the base model and the CoT-trained model. The advantage is particularly pronounced on the harder test set, indicating that the Agentic pipeline produces more discriminative training data that enhances reasoning capabilities. Training on Agentic Self-Instruct data improves performance on both easier and harder test sets compared to CoT Self-Instruct data. The performance gap between Agentic and CoT training is substantially larger on the harder test set. The Agentic-trained model demonstrates strong transferability, achieving the best scores across all evaluation metrics.

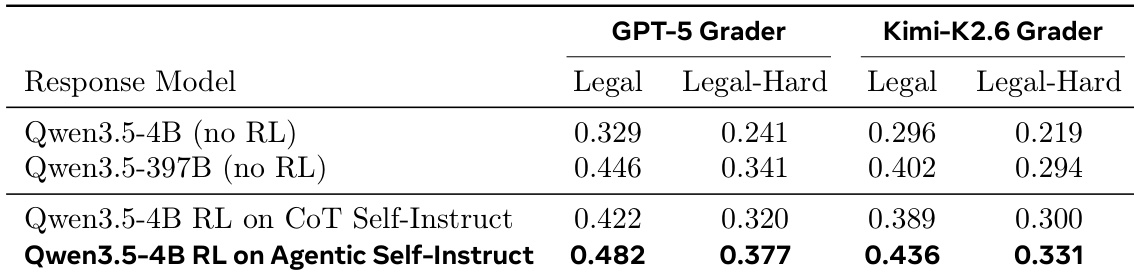
The authors evaluate reinforcement learning training on legal reasoning tasks using different data generation methods. Results show that a smaller model trained on data from the Agentic Self-Instruct loop outperforms both a similarly sized model trained on standard CoT Self-Instruct data and a much larger baseline model without RL. This advantage holds across different difficulty levels and evaluation graders, demonstrating that the agentic loop produces more discriminative training data. The Agentic Self-Instruct method consistently outperforms the standard CoT Self-Instruct method across both standard and hard legal test sets. Training on agentic data allows a smaller model to surpass the performance of a significantly larger model that did not undergo RL training. The performance gains are robust across different evaluation graders, confirming the quality of the generated training data.
The authors apply a meta-optimization framework to iteratively improve the data scientist agent's prompt for generating CS research questions. Results show that this automated prompt evolution substantially increases the validation pass rate compared to the initial baseline, demonstrating that data quality can be significantly enhanced without manual engineering. The meta-optimizer progressively improves the agent's instructions, leading to a significant increase in the validation pass rate over the baseline. The iterative process automatically identifies and resolves systematic failure modes, such as generic answers and context leakage. The optimized prompt achieves a much higher fraction of successful QA pairs that effectively separate weak and strong solvers.

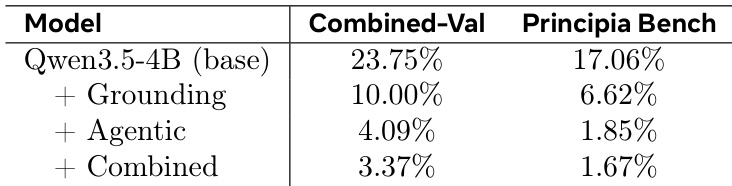
The authors analyze truncation rates to assess how different training configurations affect the token efficiency of a reasoning model. Results show that the base model frequently exceeds the token budget, but training on synthetic data substantially reduces these rates. The combined training setup achieves the lowest truncation rates, indicating that integrating agentic data with grounding data produces the most concise reasoning. The base model exhibits the highest truncation rates across both validation sets, suggesting it struggles to finish reasoning within the limit. Training with agentic self-instruct data drastically cuts truncation rates compared to the grounding baseline. The combined training configuration yields the lowest truncation rates overall, demonstrating superior token efficiency.
The evaluation covers out-of-distribution scientific reasoning, reinforcement learning on logical and legal tasks, automated prompt meta-optimization, and token efficiency analysis. Across these studies, training on Agentic Self-Instruct data consistently provides more discriminative learning signals, leading to stronger average performance, greater gains on harder test sets, and enabling smaller models to surpass much larger counterparts without reinforcement learning. Combining agentic data with grounding sources yields the most concise reasoning with the lowest truncation rates, while meta-optimization shows that automated prompt evolution substantially improves data quality without manual engineering, underscoring the robustness and efficiency of agentic generation pipelines.