Command Palette
Search for a command to run...
MemGUI-Agent : Un Agent GUI Mobile de bout en bout à long horizon avec une gestion proactive du contexte
MemGUI-Agent : Un Agent GUI Mobile de bout en bout à long horizon avec une gestion proactive du contexte
Guangyi Liu Gao Wu Congxiao Liu Pengxiang Zhao Liang Liu Mading Li Qi Zhang Mengyan Wang Liang Guo Yong Liu
Résumé
Les agents GUI mobiles basés sur des MLLM ont accompli des progrès substantiels sur les tâches à horizon court, mais demeurent peu fiables sur les tâches à horizon long, qui exigent de conserver des faits intermédiaires sur de nombreuses étapes et transitions entre applications. Nous attribuons cette limitation au prompting de type ReAct, qui accumule passivement les enregistrements étape par étape, ce qui entraîne une explosion du prompt et une dilution des faits critiques inter-applications. Pour pallier ce problème, nous introduisons MemGUI-Agent, un agent GUI mobile à horizon long de bout en bout doté d'une gestion proactive du contexte. MemGUI-Agent repose sur Context-as-Action (ConAct), qui assimile la gestion du contexte à des actions de première classe émises par la même politique qui sélectionne les actions de l'interface utilisateur. Au lieu d'ajouter passivement l'historique, ConAct maintient trois champs de contexte structurés : un historique d'actions condensé, un état de l'interface utilisateur condensé et un enregistrement de l'étape récente, préservant ainsi les faits critiques de l'interface utilisateur tout en maintenant un contexte compact. Afin de rendre la gestion proactive du contexte apprenable à différentes échelles de modèles, nous constituons MemGUI-3K, un jeu de données de 2 956 trajectoires accompagné d'annotations ConAct complètes pour l'entraînement supervisé et l'analyse hors ligne. L'entraînement d'un modèle 8B sur MemGUI-3K donne naissance à MemGUI-8B-SFT, un agent MemGUI-Agent de 8B paramètres qui atteint les meilleures performances parmi les modèles 8B sur données ouvertes au benchmark MemGUI-Bench et généralise au benchmark MobileWorld hors distribution. Le code, les données et les modèles entraînés seront publiés à l'adresse https://memgui-agent.github.io/.
One-sentence Summary
MemGUI-Agent, an end-to-end long-horizon mobile GUI agent that proactively manages context via Context-as-Action (ConAct) by treating context operations as policy actions and maintaining structured fields of folded action history, folded UI state, and recent step records, achieves top open-data 8B performance on MemGUI-Bench and generalizes to MobileWorld after training on the MemGUI-3K dataset.
Key Contributions
- MemGUI-Agent, an end-to-end mobile GUI agent, replaces passive history accumulation with proactive context management via the Context-as-Action (ConAct) formulation, where the policy emits structured actions to maintain three compact fields: folded action history, folded UI state, and recent step record.
- MemGUI-3K provides 2,956 trajectories with full ConAct annotations, enabling supervised training and offline analysis of proactive context management across model scales.
- Fine-tuning an 8B model on MemGUI-3K yields MemGUI-8B-SFT, which achieves the best open-data 8B performance on MemGUI-Bench and generalizes to the out-of-distribution MobileWorld benchmark.
Introduction
Mobile GUI agents powered by multimodal large language models (MLLMs) can handle short tasks reliably, but they falter on long‑horizon workflows that require remembering key facts across many steps and app transitions. Prior end‑to‑end agents typically use passive context mechanisms like ReAct‑style thought‑action traces, which cause the prompt to balloon with every step and dilute important cross‑app UI details, making them error‑prone on extended tasks. The authors address this with MemGUI‑Agent, an end‑to‑end agent that treats context management as a first‑class action. Their Context‑as‑Action (ConAct) policy jointly decides which UI action to take and how to maintain a compact, structured context, keeping folded action history, folded UI state, and a recent step record so that critical UI‑derived facts are preserved verbatim. They also construct MemGUI‑3K, a dataset of 2,956 trajectories annotated for proactive context actions, and use it to train an 8B model that achieves the best open‑data performance on the MemGUI‑Bench benchmark and generalizes to the out‑of‑distribution MobileWorld benchmark.
Dataset
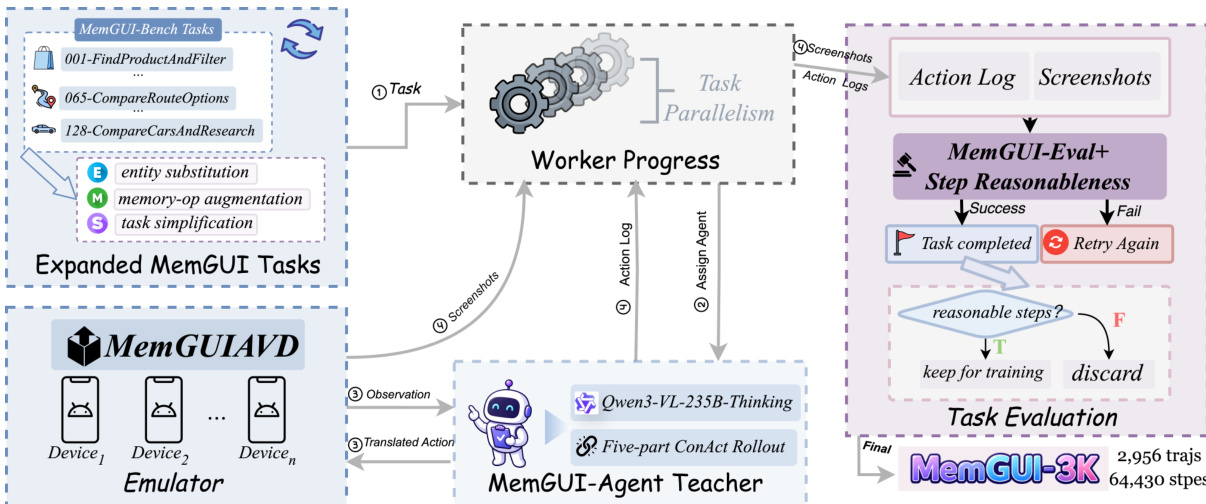
The authors construct the MemGUI-3K dataset from the 128 long-horizon seed tasks of MemGUI-Bench. They expand the seed pool with three strategies: entity substitution preserves task structure while replacing entities; memory-operation augmentation adds tasks requiring update and delete actions; and task simplification breaks complex tasks into shorter single-objective variants. The expansion yields a pool of 7,303 tasks, from which 5,293 are selected for teacher rollouts. All rollouts use a Qwen3-VL-235B-Thinking teacher executing the full 5-part CoNACT protocol in a snapshot-based Android environment, with a step budget of 2.5× the golden-step count plus one.
Key dataset details:
- The final trajectory set contains 2,956 successful trajectories across 26 apps and 7 categories, filtered via MemGUI-Eval’s progressive scrutiny pipeline (trajectory removal includes one abnormal outlier and two low-frequency app trajectories), then split 90/10 at the trajectory level with verified zero overlap against the MemGUI-Bench evaluation tasks.
- Each step is annotated as reasonable or unreasonable. Only reasonable steps (75.7% of steps, averaging 21.8 per trajectory) become supervised fine-tuning samples.
- The resulting step-level SFT set contains 64,430 samples (57,951 train, 6,479 test). Each sample pairs a user message (screenshot in base64 plus structured context: folded action history, folded UI state, recent step record, and query) with the gold assistant response in the 5-part CoNACT format (thinking, folding, tool_call, ui_observation, action_intent).
- Trajectories average 28.8 steps, median 25; memory actions appear in 65.1% of trajectories; 23.8% of folds are span-level summaries averaging 6.25 steps, and 88.7% of trajectories include at least one span-level fold.
How the paper uses the data:
- The authors fine-tune Qwen3-VL-8B-Instruct on the step-level SFT samples using LoRA with the ms-swift framework, producing MemGUI-8B-SFT.
- No dataset blending or mixture ratios are applied; training relies exclusively on the MemGUI-3K SFT samples.
Processing and metadata details:
- Full-resolution screenshots are provided without cropping; the image is embedded in the user message as a base64 string.
- Structured context (folded history, folded UI state, recent step record) is constructed from the teacher’s CoNACT actions during rollout, giving the model rich, long-horizon context supervision.
- The dataset is released in two complementary formats: a trajectory-level format preserving complete rollouts, evaluation metadata, and step-level annotations, and the step-level SFT format compatible with ms-swift.
Method
The authors propose MemGUI-Agent, an end-to-end mobile GUI agent that leverages ConAct (Context as Action) to make context management a first-class part of the action policy. Instead of treating context as a passive log outside the model's control, the agent jointly decides what UI or memory action to execute, what history to fold, and how to describe the current interaction. This turns context maintenance into policy-level behavior.
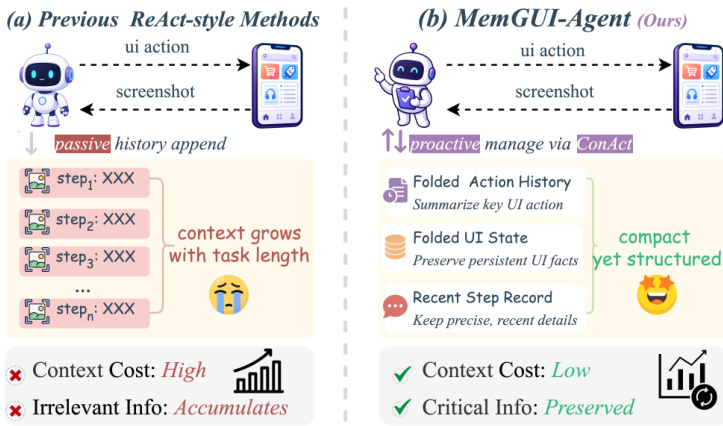
As shown in the figure below, previous ReAct-style methods passively append history, causing context cost to grow with task length and irrelevant info to accumulate. In contrast, MemGUI-Agent proactively manages context via ConAct, maintaining a compact yet structured state with Folded Action History, Folded UI State, and Recent Step Record, keeping context cost low while preserving critical info.
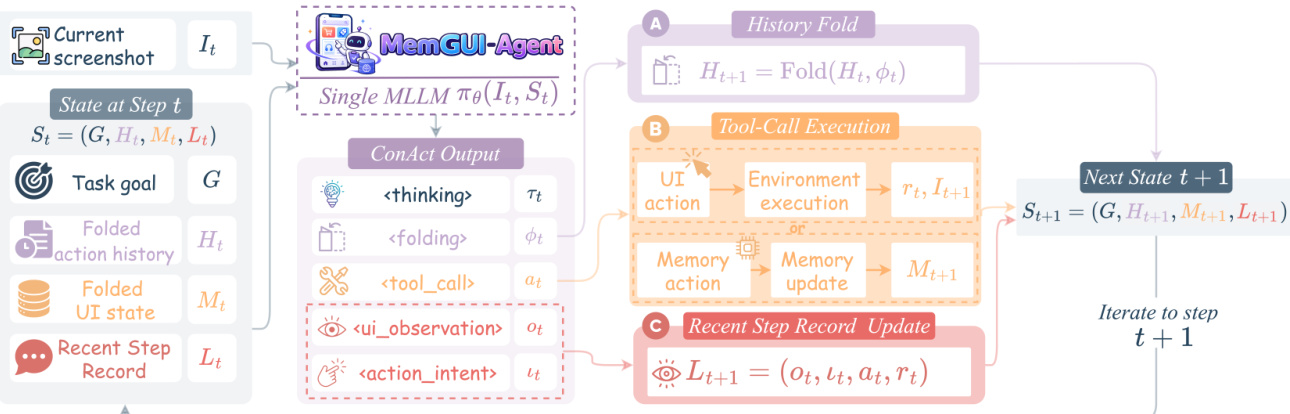
The authors formulate mobile GUI automation as a sequential decision problem with a structured working context. Given a task goal G and screenshot It, the agent observes the state:
St=(G,Ht,Mt,Lt),where Ht, Mt, and Lt denote Folded Action History, Folded UI State, and Recent Step Record, storing compressed trajectory summaries, persistent UI-derived facts, and latest-step details.
At each step, the MLLM policy emits a joint ConAct decision:
yt=(τt,ϕt,at,ot,ιt)∼πθ(⋅∣It,St),where τt is reasoning, ϕt is a folding directive, at is a UI or memory action, ot is the UI observation, and ιt is the action intent. Unlike ReAct-style prompting, which appends a growing task-progress string, ConAct partitions context into three fields and updates them through model-emitted context actions.
Refer to the framework diagram for the single-step execution flow. The model emits a 5-part structured output. The <tool_call> field executes exactly one action per step from the extended action space:
Here, Aui contains UI actions such as clicking, typing, swiping, waiting, and terminating. The memory actions update Mt.
From step 2 onward, the agent emits a mandatory <folding> block. Formally, the folding directive is ϕt=([st,t],zt), where [st,t] is the history span to compress and zt is the generated summary. Step-level distillation corresponds to st=t and keeps the latest step as a compact record, while span-level abstraction uses st<t to summarize a completed sub-task into one reusable record. The folded history is updated as:
which replaces uncontrolled conclusion accumulation with model-controlled folding, pushing context growth from linear accumulation toward sub-linear growth.
Each memory item is a structured triple m=(id,d,c), where id is a unique identifier, d is a short description, and c is the complete content to preserve. Let Amem={a+,a∘,a−} denote memory_add, memory_update, and memory_delete. A memory action induces:
Mt+1=⎩⎨⎧Add(Mt,m),Update(Mt,id,c),Delete(Mt,id),Mt,at=a+,at=a∘,at=a−,at∈Aui.Memory writes store complete task-relevant information rather than references or lossy summaries. This is crucial when prices, codes, contact information, or copied text must survive screen changes, long delays, and app transitions.
The two self-describing fields make each step reusable by future context actions. <ui_observation> provides a grounded screen description with exact visible text, numbers, names, and task-relevant UI facts. <action_intent> states what the current tool call is intended to accomplish. Together with the executed action and tool result, they form:
This record supplies grounded content for memory writes into Mt and future folding into Ht.
At step t, the MLLM πθ takes (It,St) and emits yt=(τt,ϕt,at,ot,ιt). The environment/tool result is:
(rt,It+1)={Env(It,at),(ok,It),at∈Aui,at∈Amem,where UI actions change the screen and memory actions update only the structured context. Combining the equations, the complete state transition is:
St+1=T(St,yt,rt)=(G,Ht+1,Mt+1,Lt+1).The next state St+1 is fed into step t+1. Because folding, memory, and action intent are predicted by the same multimodal policy in one forward pass, compression and memorization inherit the agent's task-level reasoning rather than being delegated to a separate summarizer, retriever, or memory agent.
To train the student model, the authors leverage a teacher model and a specialized evaluation pipeline. As shown in the figure below, the training process begins with expanded MemGUI tasks. A MemGUI-Agent Teacher (Qwen3-VL-235B-Thinking) performs five-part ConAct rollouts on the MemGUI-AVD emulator. The worker progress is monitored, and screenshots and action logs are fed into MemGUI-Eval+ with Step Reasonableness analysis. The evaluator labels each step as reasonable or unreasonable. Only steps labeled as reasonable are converted into SFT samples to form the final MemGUI-3K dataset.
Experiment
The evaluation employs two long-horizon mobile GUI benchmarks, MemGUI-Bench and MobileWorld, to assess task success and memory retention across many-step, cross-app tasks. Zero-shot ConAct with a 235B model sets a new state of the art, surpassing complex agentic frameworks, while the 8B model fine-tuned on the MemGUI-3K dataset achieves the best open-data 8B performance and transfers to out-of-distribution environments, with gains concentrated on the hardest tasks. Ablation studies confirm that ConAct's three components (history folding, UI memory actions, and self-describing step outputs) are complementary and each addresses a distinct failure mode, and error analysis reveals that the full system primarily reduces process and output hallucinations, demonstrating that proactive context management effectively prevents long-horizon information loss rather than relying on stronger reasoning or domain knowledge.
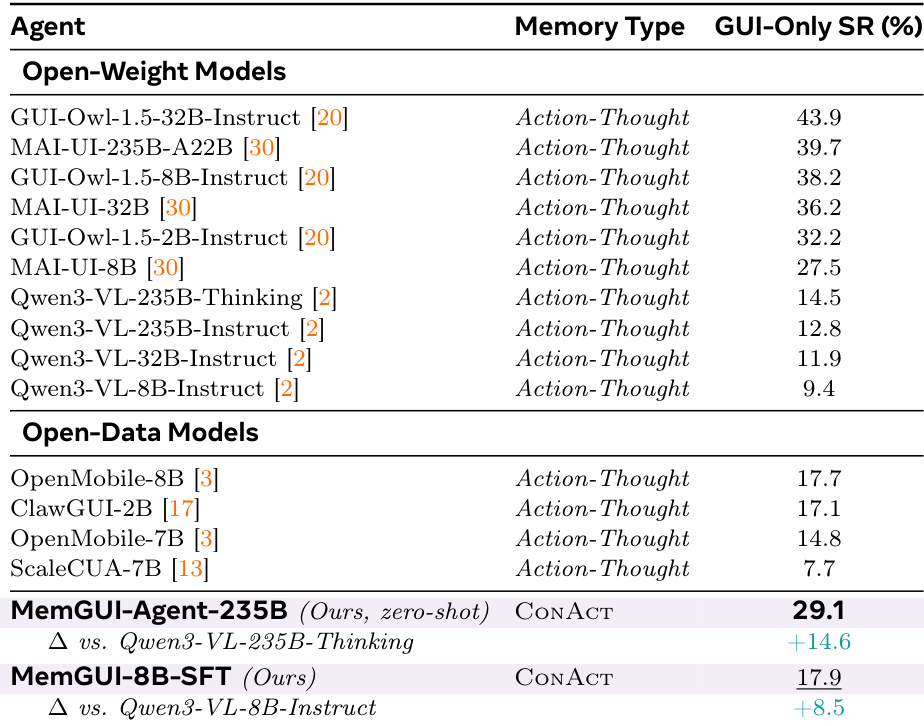
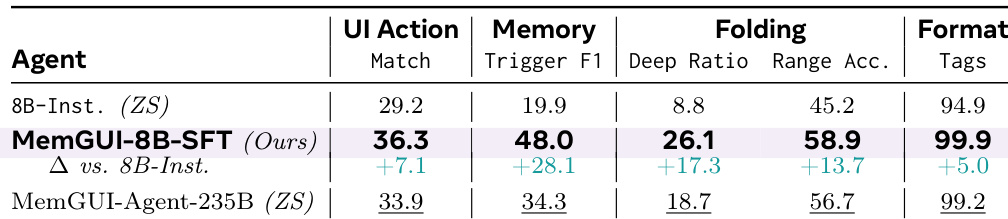
The authors evaluate their MemGUI-Agent models on the MobileWorld GUI-Only benchmark, comparing their ConAct memory type against baselines using Action-Thought. The zero-shot MemGUI-Agent-235B achieves the highest success rate among open-data models, substantially outperforming its Qwen3-VL backbone. Similarly, the fine-tuned MemGUI-8B-SFT model ranks among the top open-data 8B models, demonstrating significant gains over its base model and showing that the learned context-management skills transfer effectively to new environments. MemGUI-Agent-235B with ConAct achieves the top success rate among open-data models, substantially outperforming its Qwen3-VL backbone. MemGUI-8B-SFT ranks among the best open-data 8B models, showing significant gains over its base model. The ConAct memory type consistently improves performance over Action-Thought baselines across different model scales.
The authors evaluate their proposed MemGUI-Agent, which uses a Context-as-Action paradigm, against existing agentic frameworks and end-to-end models on a long-horizon mobile GUI benchmark. Results show that the zero-shot version of their agent achieves state-of-the-art performance, surpassing strong agentic frameworks built on proprietary backbones. Furthermore, fine-tuning a smaller model with their dataset yields substantial improvements, particularly on more difficult tasks, demonstrating effective transfer of context-management skills. The zero-shot MemGUI-Agent outperforms existing agentic frameworks and end-to-end models across all task difficulty levels. Fine-tuning an 8B model significantly boosts its performance, with the largest gains observed on medium and hard tasks compared to the base model. The proposed context management approach consistently improves information retention rates across different task complexities.
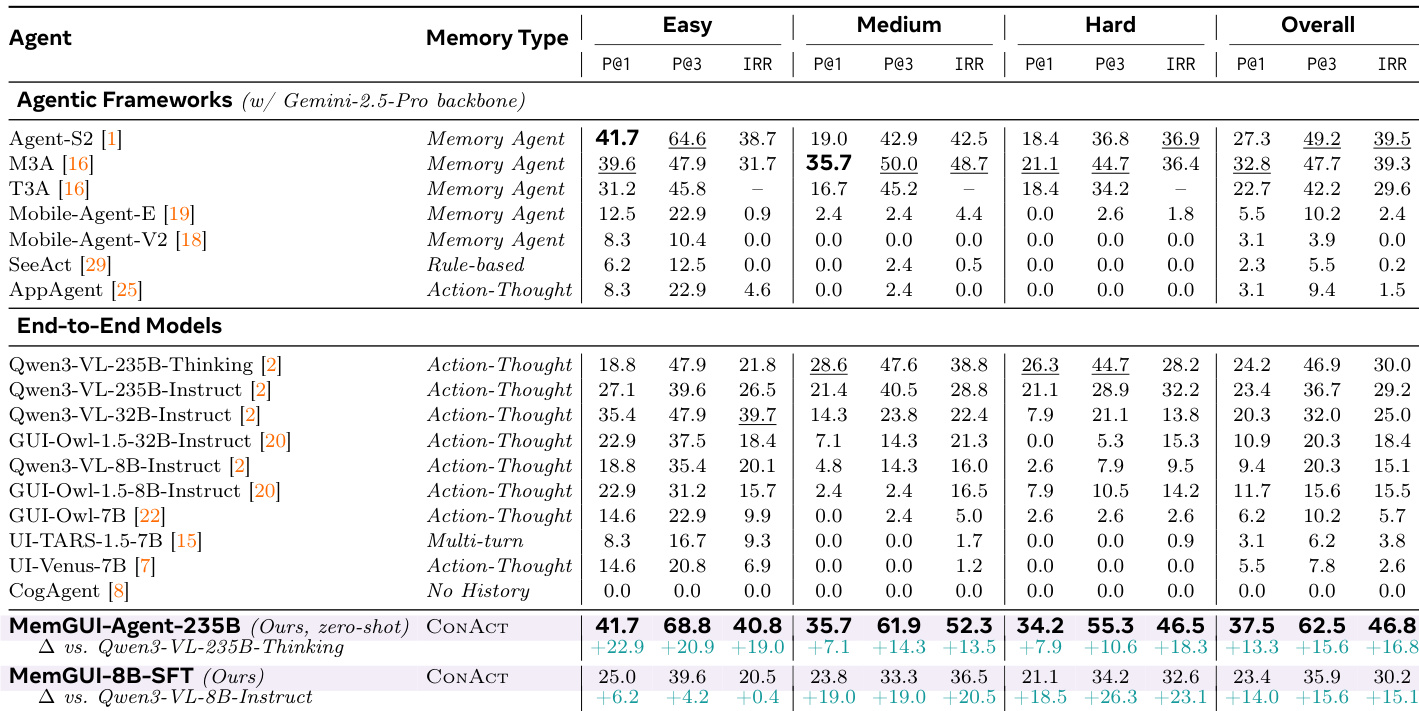
The authors conduct an ablation study to evaluate the individual contributions of three context management components: UI memory actions, history folding, and self-describing step outputs. Results indicate that while each component independently improves upon the baseline, none is sufficient on its own to achieve optimal performance. Combining all three mechanisms yields the highest success and memory retention rates, demonstrating that folding, memory preservation, and grounded self-description are complementary. UI memory actions provide the largest boost to memory-specific metrics compared to the baseline. History folding improves initial success rates but struggles to maintain performance over multiple attempts without memory actions. The full model significantly outperforms all single-component variants across both success rate and memory retention metrics.
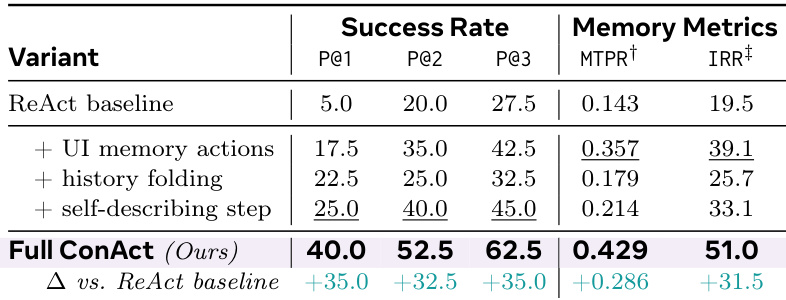
The authors analyze the step distribution within the evaluation trajectories by comparing the statistics for all steps against the subset of reasonable steps. Results show that the reasonable steps subset has lower mean and median values than the full set, indicating that the filtering process effectively reduces the average trajectory length. The reasonable steps subset exhibits lower mean and median values compared to the full set of all steps. Filtering for reasonable steps yields a more compact distribution of trajectory lengths.
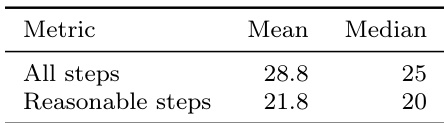
The authors conduct a step-level offline evaluation to isolate subskills such as action execution, memory management, context folding, and formatting. Results show that the fine-tuned 8B model substantially improves memory triggering and deep folding capabilities compared to the base model, while achieving near-perfect format compliance. The fine-tuned 8B agent achieves the highest memory trigger score, surpassing even the larger zero-shot model. Deep folding ratio and range accuracy improve significantly after supervised fine-tuning on the dataset. The model maintains extremely high format compliance, confirming reliable structured generation across all evaluated steps.
The authors evaluate MemGUI-Agent on mobile GUI benchmarks using a Context-as-Action memory paradigm, showing that the ConAct memory type consistently outperforms Action-Thought baselines and that zero-shot and fine-tuned versions achieve leading results among open-data models. Ablation studies confirm that UI memory actions, history folding, and self-describing step outputs are complementary, with their combination delivering the highest success and memory retention. Fine-tuning an 8B model notably boosts memory triggering, deep folding, and format compliance, exceeding even larger zero-shot configurations, while filtering trajectories to reasonable steps reduces average length. The context management skills transfer effectively to new environments and prove especially beneficial on harder long-horizon tasks.