Command Palette
Search for a command to run...
Apprendre de ses propres erreurs : Construire des trajectoires micro-réflexives apprenables pour l'auto-distillation
Apprendre de ses propres erreurs : Construire des trajectoires micro-réflexives apprenables pour l'auto-distillation
Zhilin Huang Hang Gao Ziqiang Dong Yuan Chen Yifeng Luo Chujun Qin Jingyi Wang Yang Yang Guanjun Jiang
Résumé
L'auto-distillation améliore le raisonnement des grands modèles de langage en utilisant les propres rollouts du modèle comme signal d'entraînement, généralement par le biais d'un alignement implicite au niveau des logits qui minimise la divergence KL vers une distribution cible privilégiée. Cependant, cette supervision étant générée par un échantillonnage non contrôlé, elle n'apporte aucune information diagnostique sur les erreurs spécifiques du modèle ni de guides correctifs pour ses schémas d'échec individuels. Par conséquent, le modèle apprend à imiter une distribution privilégiée plutôt que de recevoir des corrections fines qui indiquent précisément où et pourquoi son raisonnement échoue. Dans cet article, nous proposons l'Optimisation de Politique Augmentée par Trajectoire (TAPO), qui fait évoluer l'auto-distillation d'un alignement distributionnel implicite vers une construction explicite de trajectoires. Lors de l'entraînement par renforcement (RL), le modèle génère à la fois des rollouts corrects et incorrects pour une même requête, et le TAPO exploite cette structure contrastive pour élaborer des corrections micro-réflexives, constituées de nouvelles trajectoires d'entraînement qui conservent le raisonnement erroné du modèle jusqu'au point d'échec, avant d'y insérer un diagnostic en langage naturel et un raisonnement corrigé, le tout guidé par une référence correcte issue du même groupe d'échantillonnage. Étant donné que chaque trajectoire s'ancre dans le préfixe et les solutions propres à l'apprenant, le signal correctif préserve la distribution on-policy du modèle dans une bien plus grande mesure que l'alignement position par position imposé par les méthodes fondées sur la divergence KL. Pour intégrer ces trajectoires, le TAPO introduit une sélection de candidats sensible à la difficulté au niveau de la frontière de capacité du modèle, ainsi qu'une estimation découplée de l'avantage afin de prévenir la contamination des gradients. Les expériences sur AIME 2024, AIME 2025 et HMMT 2025 montrent que le TAPO obtient des améliorations constantes par rapport au GRPO pour un nombre identique d'étapes d'entraînement. Des analyses complémentaires démontrent que le TAPO renforce à la fois le raisonnement en un seul passage et l'efficacité de la correction des erreurs.
One-sentence Summary
Trajectory-Augmented Policy Optimization (TAPO) advances self-distillation beyond implicit logit alignment by contrasting correct and incorrect rollouts to construct micro-reflective trajectories that preserve pre-failure reasoning, insert natural-language diagnoses, and append corrected steps, thereby enabling models to learn targeted error corrections rather than generic distributional imitation.
Key Contributions
- This paper introduces Trajectory-Augmented Policy Optimization (TAPO), a self-distillation framework that replaces implicit logit alignment with explicit trajectory construction. TAPO anchors training sequences to the model's erroneous reasoning prefixes and appends natural-language diagnoses alongside corrected steps derived from within-group correct solutions.
- The framework addresses integration challenges in advantage-based reinforcement learning through three targeted mechanisms. Difficulty-aware Candidate Selection establishes an emergent curriculum by targeting problems within the model's capability boundary, Decoupled Advantage Estimation prevents gradient contamination from inflated group rewards, and OOD Token Suppression stabilizes optimization when processing out-of-distribution corrective tokens.
- Evaluations across the AIME 2024, AIME 2025, and HMMT 2025 benchmarks demonstrate consistent performance gains over GRPO and distributional alignment baselines under identical training steps. Direct Solution Rate and Effective Reflection Rate analyses confirm that the micro-reflective training signal enhances both first-pass reasoning accuracy and autonomous error correction without requiring explicit reflection prompts at inference.
Introduction
Large language models have advanced significantly in complex reasoning through reinforcement learning with verifiable rewards, where self-distillation methods use dense token-level supervision to align model outputs with verified solutions. Prior approaches, however, rely on implicit distributional alignment that treats reasoning targets as uncontrolled probability distributions and suppresses errors instead of teaching recovery pathways. To overcome these limitations, the authors leverage the model's own incorrect rollouts to construct explicit micro-reflective trajectories that diagnose mistakes and demonstrate natural-language corrections. By integrating these targeted signals into a standard advantage-based reinforcement learning framework, they enable models to internalize autonomous error correction while preserving exploratory diversity and maintaining training stability.
Dataset

- Dataset composition and sources: The authors build a 45,000 example cold-start dataset drawn from approximately 40,000 queries in the DeepScaleR collection.
- Key details for each subset: The data splits into 30,000 supervised fine-tuning examples and 15,000 instruction-following fine-tuning examples. All initial responses are sampled from the Qwen3-8B-Instruct base model.
- Processing and filtering rules: The authors partition sampled responses into correct and incorrect groups. They only generate micro-reflective corrective trajectories from incorrect responses, enforcing a strict limit of one trajectory per query. The pipeline structures outputs to reliably produce specific XML-style tags for the analysis and reconstruction phases.
- Usage in the model: The authors jointly train the two example formats during a cold-start phase to initialize the model before reinforcement learning. This combined mixture equips the policy with both instruction-following reliability and foundational self-error analysis capabilities, preventing severe out-of-distribution tokens and stabilizing corrective signal propagation during subsequent training.
Experiment
The evaluation assesses TAPO on challenging mathematical reasoning benchmarks using both direct and cold-start initialization settings to compare against standard reinforcement learning baselines. Main results and capability internalization analyses validate that TAPO genuinely internalizes error-correction capabilities, significantly improving both first-pass reasoning strength and reflective recovery rates rather than merely augmenting training data. Ablation and training dynamics experiments confirm that preserving valid reasoning prefixes, employing contrastive advantage estimation with negative samples, and suppressing out-of-distribution tokens are essential for stable optimization and distributional alignment. Collectively, these findings demonstrate that cold-start pre-alignment and carefully structured corrective trajectories enable robust policy learning that substantially outperforms conventional methods, particularly on complex mathematical tasks.
The authors evaluate the capability internalization of TAPO versus GRPO by measuring Direct Solution Rate and Effective Reflection Rate. The data indicates that TAPO consistently outperforms the baseline across all benchmarks, demonstrating enhanced first-pass reasoning and more effective error correction. TAPO achieves higher Direct Solution Rate than the baseline method across all benchmarks. The Effective Reflection Rate is superior for TAPO compared to GRPO. Improvements in both reasoning and correction metrics are consistent across different datasets.

The authors evaluate TAPO against baselines like GRPO and OPSD on mathematical reasoning benchmarks using both direct training and cold-start initialization settings. Results indicate that TAPO with cold-start initialization consistently achieves the highest Pass@1 scores across all benchmarks, demonstrating superior first-pass reasoning. In contrast, direct training yields mixed results, where TAPO excels on AIME 2024 but underperforms GRPO on more challenging benchmarks without the pre-alignment provided by the cold-start phase. TAPO with cold-start initialization outperforms GRPO and OPSD across all benchmarks, achieving the best Pass@1 scores. The cold-start phase is critical for TAPO, as direct training leads to performance drops on harder benchmarks compared to GRPO. TAPO sustains its performance gains across varying Pass@k values, indicating robust capability enhancement rather than variance reduction.
The authors evaluate the TAPO method against a cold-start baseline and various ablation variants across three mathematical reasoning benchmarks. The results demonstrate that the full TAPO configuration consistently outperforms the baseline and all partial configurations. The inclusion of all integration components yields the highest performance metrics across all Pass@k settings. The full TAPO configuration consistently achieves the highest scores across all benchmarks and Pass@k metrics. Ablation studies reveal that removing components such as OOD token suppression or negative samples results in lower performance compared to the full method. The cold-start baseline exhibits the lowest accuracy, serving as the foundation for incremental improvements as components are added.

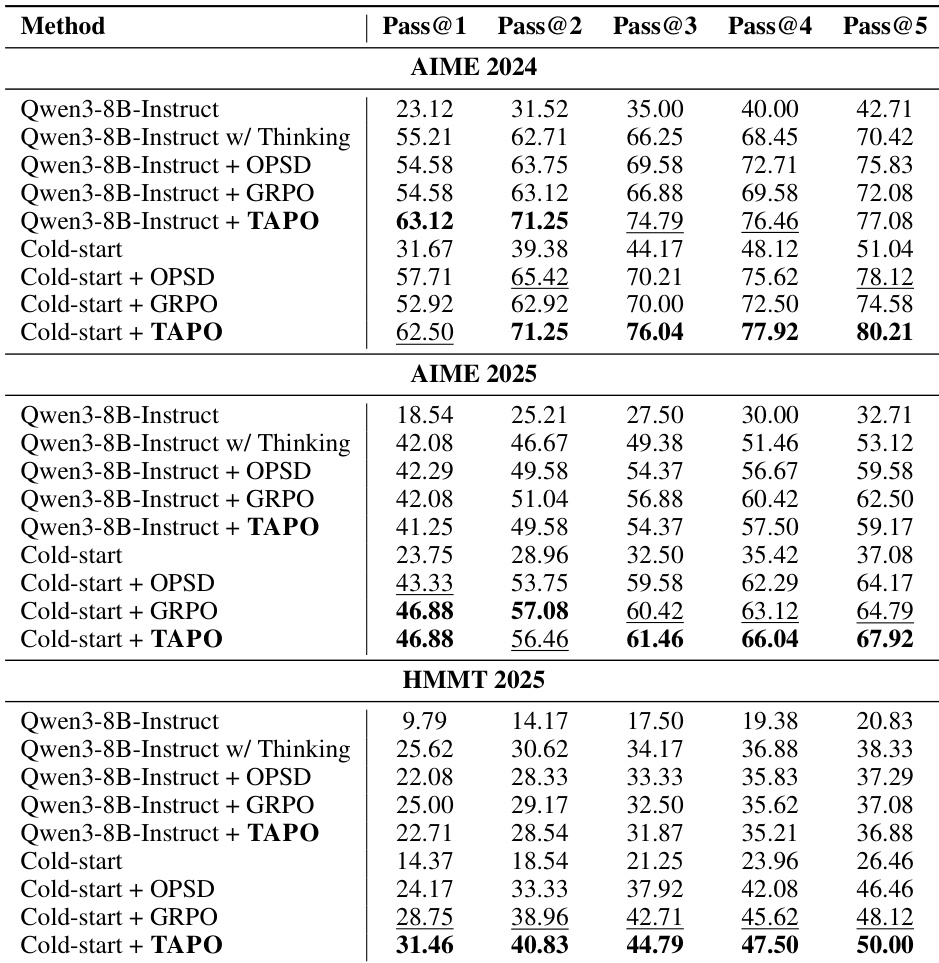
The authors evaluate the TAPO method against baselines like Cold-start, GRPO, and SFT across three mathematical reasoning benchmarks. Results indicate that TAPO with micro-reflective trajectory construction consistently achieves the highest performance, surpassing both standard reinforcement learning and supervised fine-tuning approaches. The ablation studies highlight that preserving partial reasoning paths during correction is more effective than full reconstruction, demonstrating the value of incremental error correction. TAPO with micro-reflective construction consistently outperforms GRPO and SFT baselines across all tested benchmarks. Preserving valid reasoning prefixes during correction yields better results than regenerating full solutions from scratch. The method demonstrates robust improvements on challenging benchmarks, particularly showing significant gains on the hardest dataset.
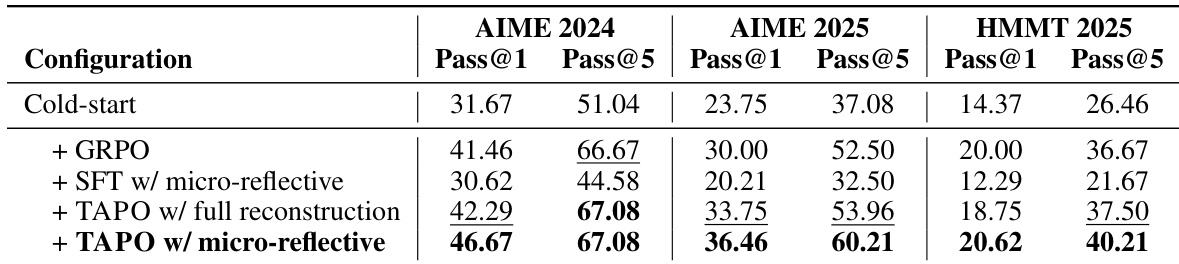
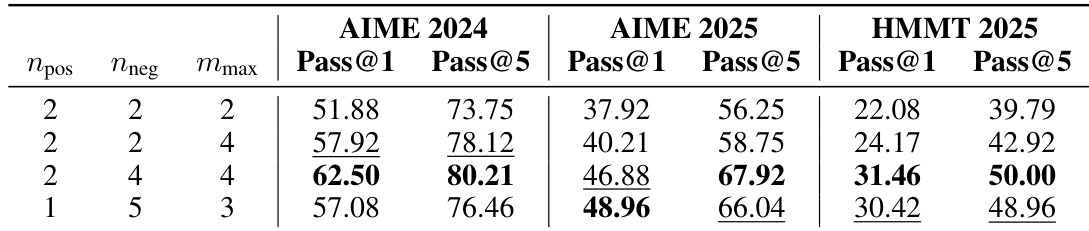
The authors investigate the impact of the ZPD threshold parameters and maximum construction count on model performance. The default configuration demonstrates robust effectiveness, securing the top Pass@1 performance on AIME 2024 and HMMT 2025, along with the best Pass@5 results across all benchmarks. The default parameter configuration achieves the highest Pass@1 scores on AIME 2024 and HMMT 2025. A stricter threshold setting proves most effective for the AIME 2025 benchmark. Reducing the maximum construction count leads to a noticeable decline in performance, highlighting the importance of construction volume.
The authors evaluate TAPO against multiple reinforcement learning and supervised baselines across mathematical reasoning benchmarks, employing direct training, cold-start initialization, ablation studies, and hyperparameter tuning to validate its core design principles. Results demonstrate that TAPO consistently outperforms competing methods in both initial reasoning accuracy and subsequent error correction, with cold-start initialization proving critical for sustaining performance on complex tasks. Component analysis confirms that preserving partial reasoning paths during refinement and integrating all architectural elements yields the most robust improvements compared to full reconstruction or partial configurations. Ultimately, the experiments establish that TAPO delivers reliable capability enhancement through its structured initialization and incremental correction mechanisms.