Command Palette
Search for a command to run...
Du chatbot au collègue numérique : le changement de paradigme vers une IA autonome persistante
Du chatbot au collègue numérique : le changement de paradigme vers une IA autonome persistante
Résumé
Les Modèles de Langage de Grande Taille (LLM) subissent une transformation fondamentale, passant de générateurs conversationnels à des systèmes d'IA intégrés capables de raisonnement, d'action, de mémoire et d'auto-amélioration. Nous conceptualisons cette transition comme un passage du Chatbot au Collègue Numérique : d'une réponse conversationnelle à un travail persistant. Nous organisons cette transition selon deux dimensions étroitement couplées. Premièrement, au niveau du noyau cognitif, les LLM évoluent des systèmes de « pensée rapide » de l'ère Chatbot, pilotés par la prédiction du prochain token, vers des Thinking LLMs qui exploitent le calcul au moment de l'inférence, le raisonnement Chain-of-Thought, la réflexion, la supervision de processus et l'apprentissage par renforcement pour soutenir une cognition plus délibérée et fiable. Deuxièmement, au niveau de l'exécution des tâches augmentée par des outils, les LLM progressent des agents appelant des outils qui invoquent des ressources externes de manière ad hoc vers des systèmes de poste de travail de style OpenClaw (OpenClaw) équipés d'espaces de travail persistants, de compétences, de boucles de vérification et de gouvernance. Le paradigme « Espace de travail + Compétence » rend l'utilisation épisodique des outils semblable à celle d'un collègue grâce à la persistance de l'état, à la réutilisation de procédures, à la clôture des tâches et à la réutilisation de l'expérience. Nous examinons les évolutions de la construction des données, passant des paires instruction-réponse aux trajectoires État-Action-Observation, ainsi que les changements d'évaluation, passant des benchmarks statiques à des écosystèmes d'IA sandboxés, auditables et auto-évolutifs.
One-sentence Summary
The authors propose a framework mapping the transition of large language models from conversational chatbots to persistent digital colleagues by integrating Thinking LLMs that leverage inference-time computation and reinforcement learning with OpenClaw-style workstations that replace ad hoc tool calling with persistent Workspaces and Skills for stateful, self-verifying execution, all supported by State-Action-Observation trajectory data and evaluation within sandboxed, auditable, self-evolving ecosystems.
Key Contributions
- The paper introduces the "Workspace + Skill" paradigm to reframe the evolution of large language models from conversational chatbots into persistent digital colleagues, enabling state persistence, reusable procedures, and reliable task closure.
- It proposes a workspace-centered architectural perspective that unifies fragmented agent capabilities, demonstrating how durable environments containing files, terminals, and permissions dictate system perception and recovery while elevating safety governance to a core design requirement.
- The work establishes a data and evaluation framework that transitions training from instruction-response pairs to State-Action-Observation trajectories, utilizing sandboxed, auditable ecosystems to measure environmental state changes and task completion.
Introduction
Large language models are transitioning from passive conversational interfaces into autonomous systems capable of deliberate reasoning, environmental interaction, and sustained task execution. This shift matters because it redefines AI from a text-generation tool into a reliable digital colleague that can handle complex, multi-step professional workflows. Prior architectures, however, remain bottlenecked by fast-response generation that lacks deep verification, while early agent frameworks suffer from fragmented tool calls, transient state management, and brittle long-horizon execution. The authors leverage a two-dimensional framework to chart this evolution, tracking the cognitive move from probabilistic next-token prediction to inference-time reasoning alongside the executional shift toward persistent workstation environments. Their primary contribution centers on the Workspace + Skill paradigm, which replaces ephemeral interactions with durable state persistence, reusable procedural knowledge, and verifiable task closure. By aligning this architectural leap with corresponding shifts in training data and evaluation metrics, they establish a technical roadmap for building safe, auditable, and self-evolving AI ecosystems.
Dataset

-
Dataset Composition and Sources: The authors describe a multi-stage data ecosystem that evolves alongside model capabilities. The collection draws from static knowledge corpora, human-annotated dialogue pairs, crowdsourced instruction sets, self-generated reasoning traces, and interactive workspace execution logs. Sources range from web text, books, and code repositories to simulated productivity services, real operating systems, and high-fidelity mock environments designed for reproducible agent testing.
-
Key Details for Each Subset:
- Chatbot and SFT data consists of human-labeled instruction-response pairs, preference comparisons, and self-instructed dialogues focused on instruction following and safety alignment.
- Reasoning data contains chain-of-thought traces, intermediate calculation steps, mathematical proofs, and code generation paths. These subsets include step-level correctness annotations and verifiable trajectories distilled from stronger models or filtered through self-consistency methods.
- Agent and workspace trajectory data features state-action-observation sequences that log tool calls, terminal outputs, file system changes, UI screenshots, and DOM states. This subset integrates reusable skill packages, permission boundaries, and task history to support long-horizon workflows.
-
Training Usage and Processing: The authors use a progressive pipeline that shifts from answer imitation to reward-guided exploration. Early subsets support supervised fine-tuning and direct preference optimization. Reasoning subsets undergo distillation, revision, and step-wise filtering to enable process reward modeling. Agent trajectories are structured to train models for dynamic environment navigation, with reinforcement learning applied to verifiable task completion signals. The training mixture prioritizes trajectory continuity and final-state verification, ensuring the model learns to recover from errors and adapt to changing conditions.
-
Metadata Construction and Structural Handling: Data is organized into verifiable sequences rather than isolated prompts. The authors emphasize constructing structured skill assets that include versioning, dependency declarations, trigger conditions, and safety permissions. Trajectories are captured with explicit state snapshots, execution logs, and final-state diffs to enable reproducibility. The processing pipeline filters out invalid steps, aligns tool outputs with environmental feedback, and embeds safety guardrails directly into the metadata. This approach replaces simple text overlap metrics with comprehensive verification stacks that track task closure, execution reliability, and trajectory-level safety.
Method
The authors outline a progressive architectural framework for AI systems, describing an evolution from simple response generation to autonomous, task-oriented digital colleagues. This framework is defined by five distinct milestones, each introducing new modules and capabilities to address the limitations of the previous stage. The overall trajectory of this evolution is visualized in the roadmap below:
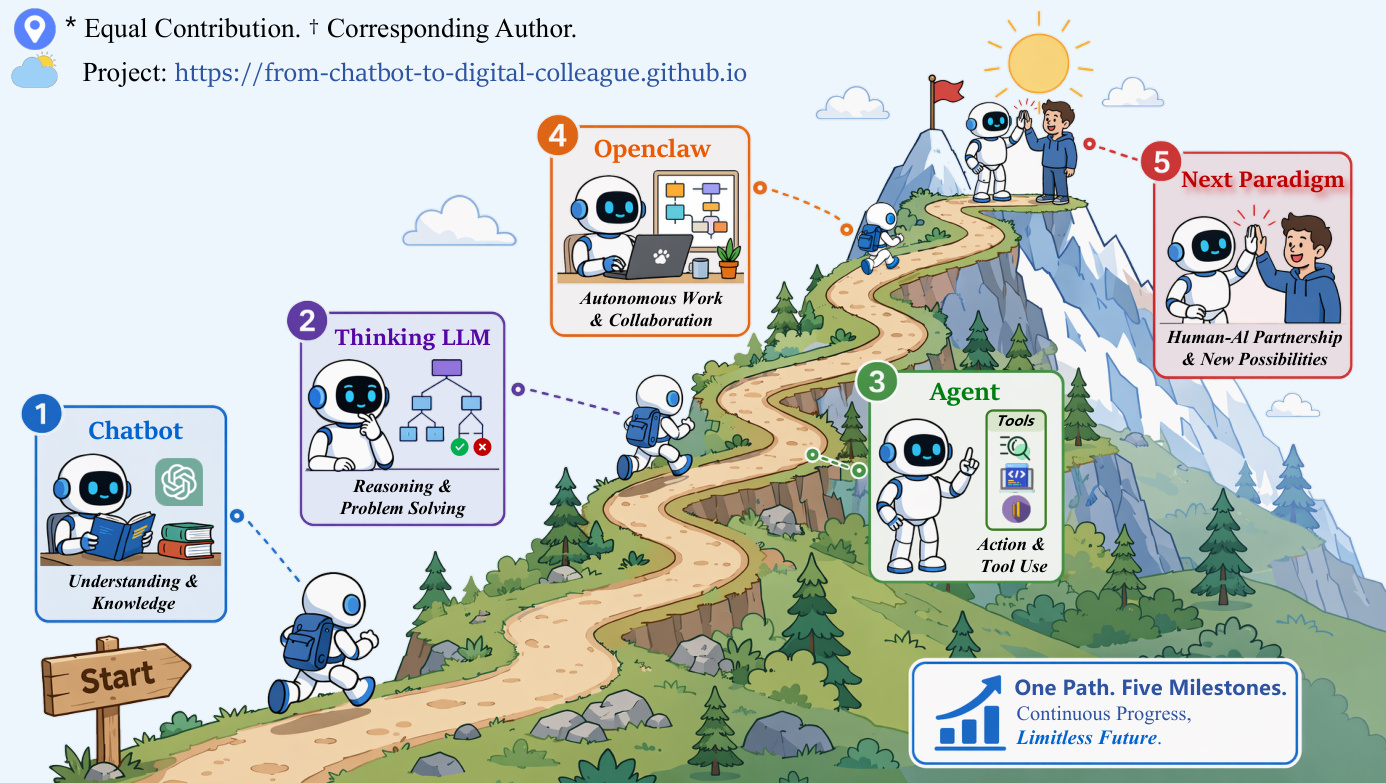
The foundation of this progression is the Chatbot LLM architecture. In this paradigm, the model operates as a stateless function that processes user inputs and generates responses token by token in a single forward pass. While this approach offers high scalability and low latency, it lacks the ability to retain memory across interactions or perform multi-step reasoning beyond the immediate context window. The system relies entirely on compressed world knowledge encoded within the model weights to produce coherent text. As shown in the figure below:
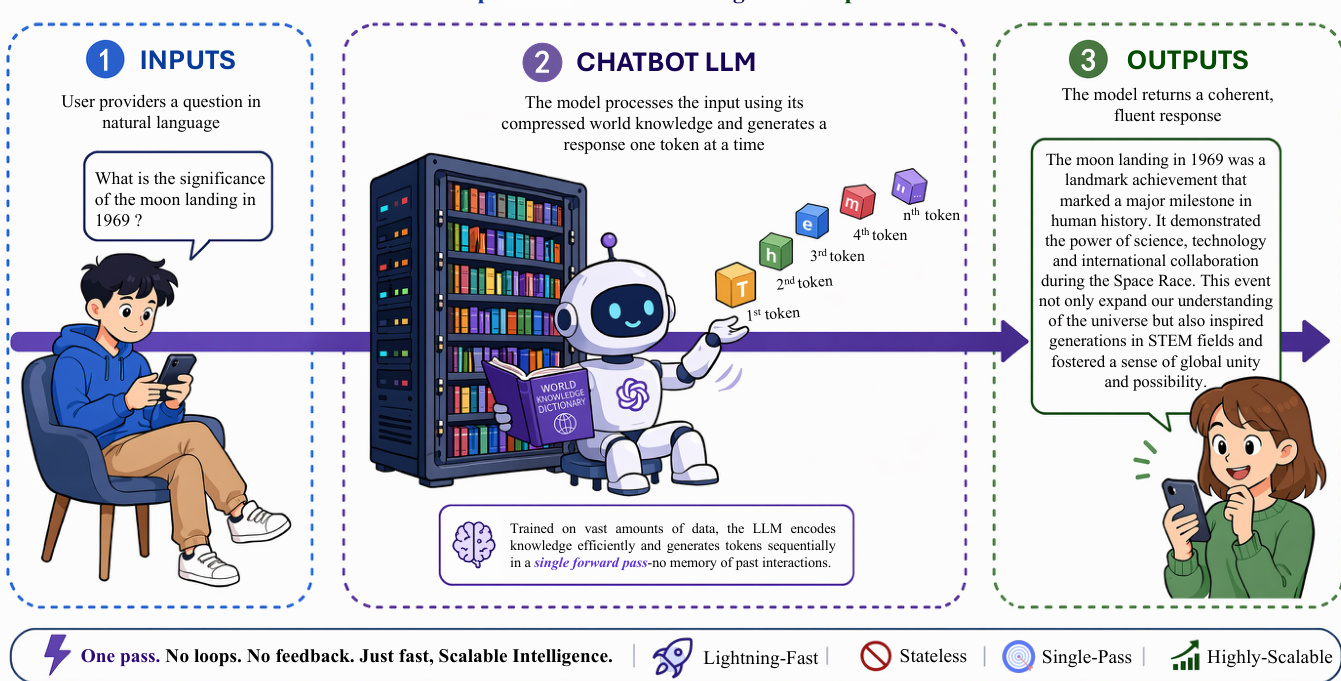
To address the limitations of single-pass generation, the authors introduce the Thinking LLM architecture, which enhances the model with deliberate reasoning capabilities. This module enables the system to handle complex problems by exploring multiple reasoning paths, detecting errors, and self-correcting. The core mechanism involves generating a reasoning tree, such as a Chain-of-Thought or Tree of Thoughts, where the model iteratively refines its approach. It can backtrack from failed steps, verify intermediate results, and synthesize insights until a verified final answer is derived. This architecture transforms the model from a passive responder into an active problem solver capable of structured, verifiable reasoning. The internal workflow of this reasoning core is depicted in the diagram below:
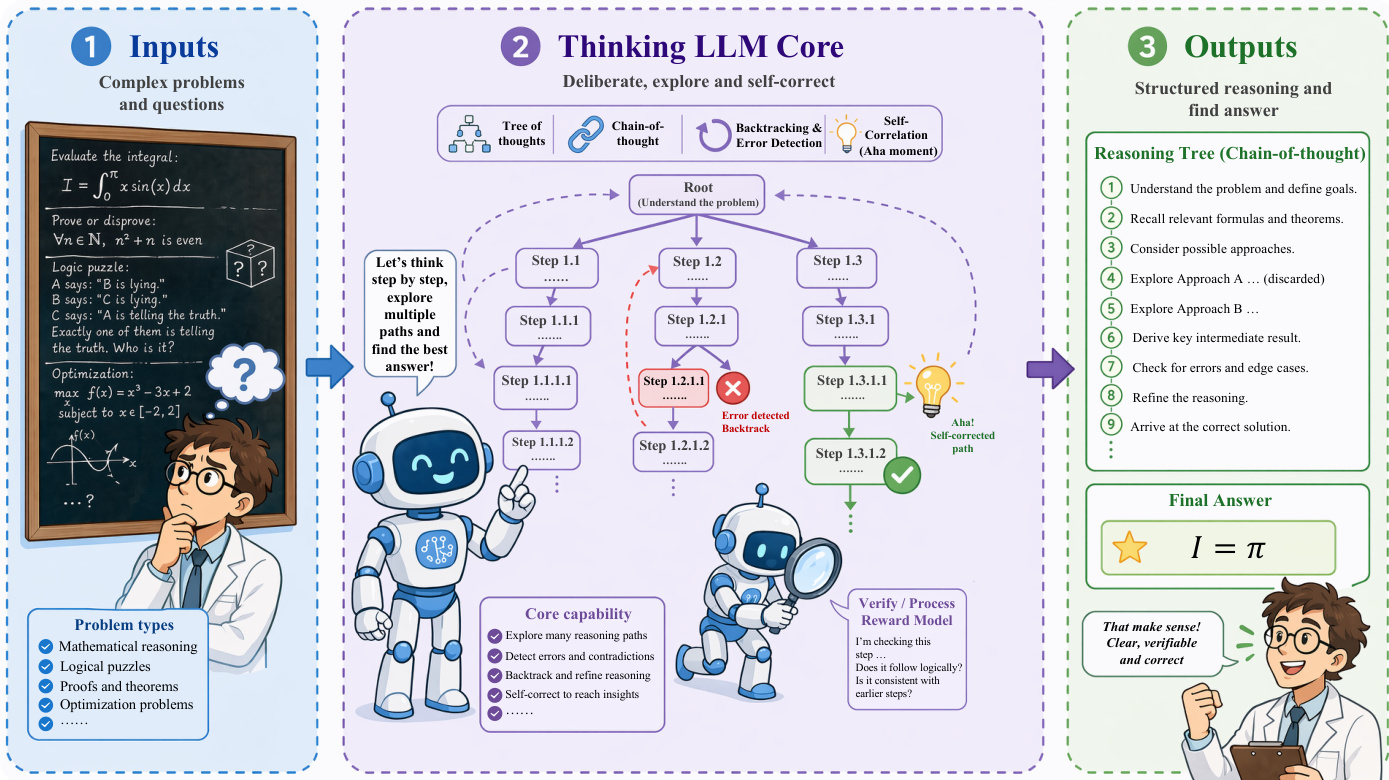
The next architectural leap is the Agent era, which extends the model's cognition into the external world through a closed-loop interaction framework. This system is organized around an observe-think-act cycle, where the agent perceives its environment, plans actions, and invokes tools to effect change. The architecture is typically decomposed into four essential modules: Perception, which interprets textual or visual inputs; Planning, which decomposes goals into actionable steps using search or decomposition strategies; Memory, which maintains context and accumulates experience over long horizons; and Tool Use, which allows the model to invoke external APIs and execute code. This loop allows the agent to recover from failures and adapt to dynamic environments, moving beyond isolated responses to sustained interaction. The agent architecture operates within a closed loop as shown in the diagram below:
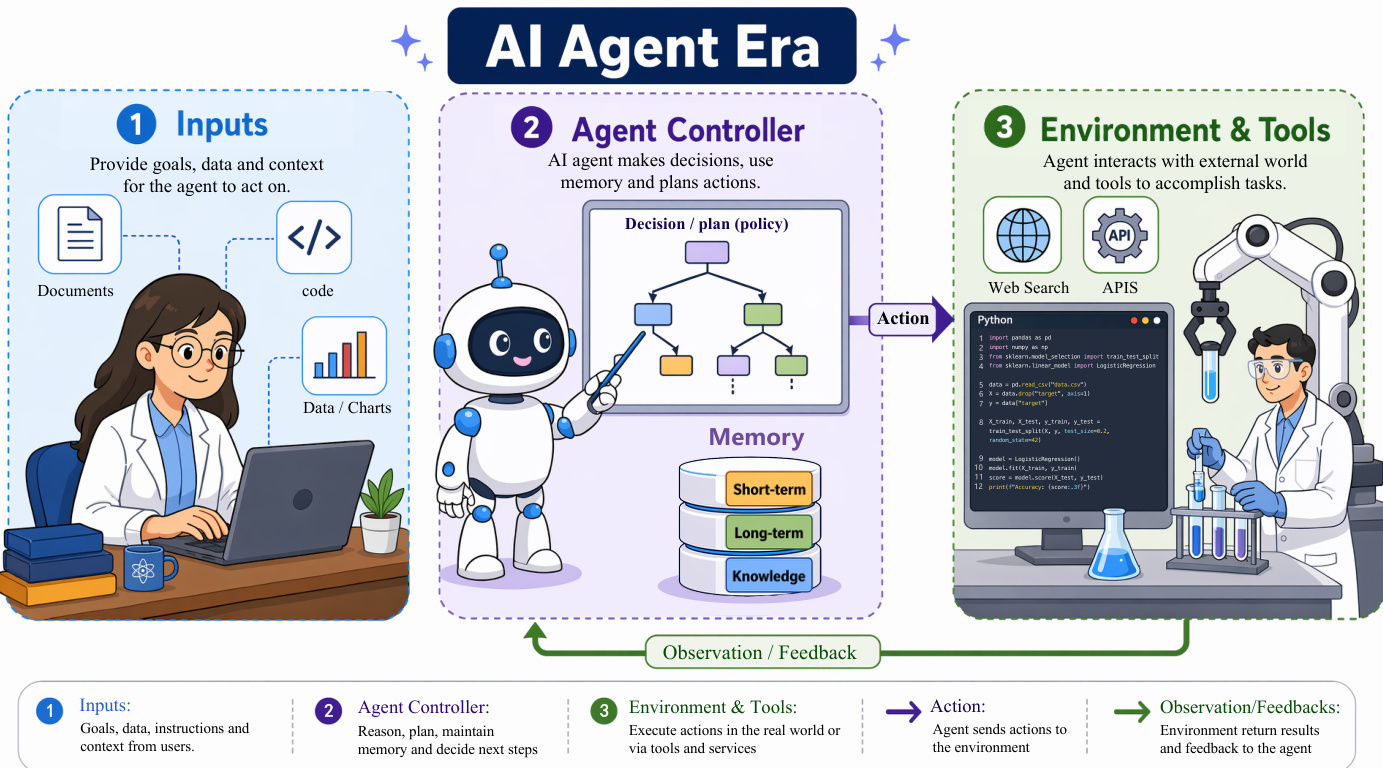
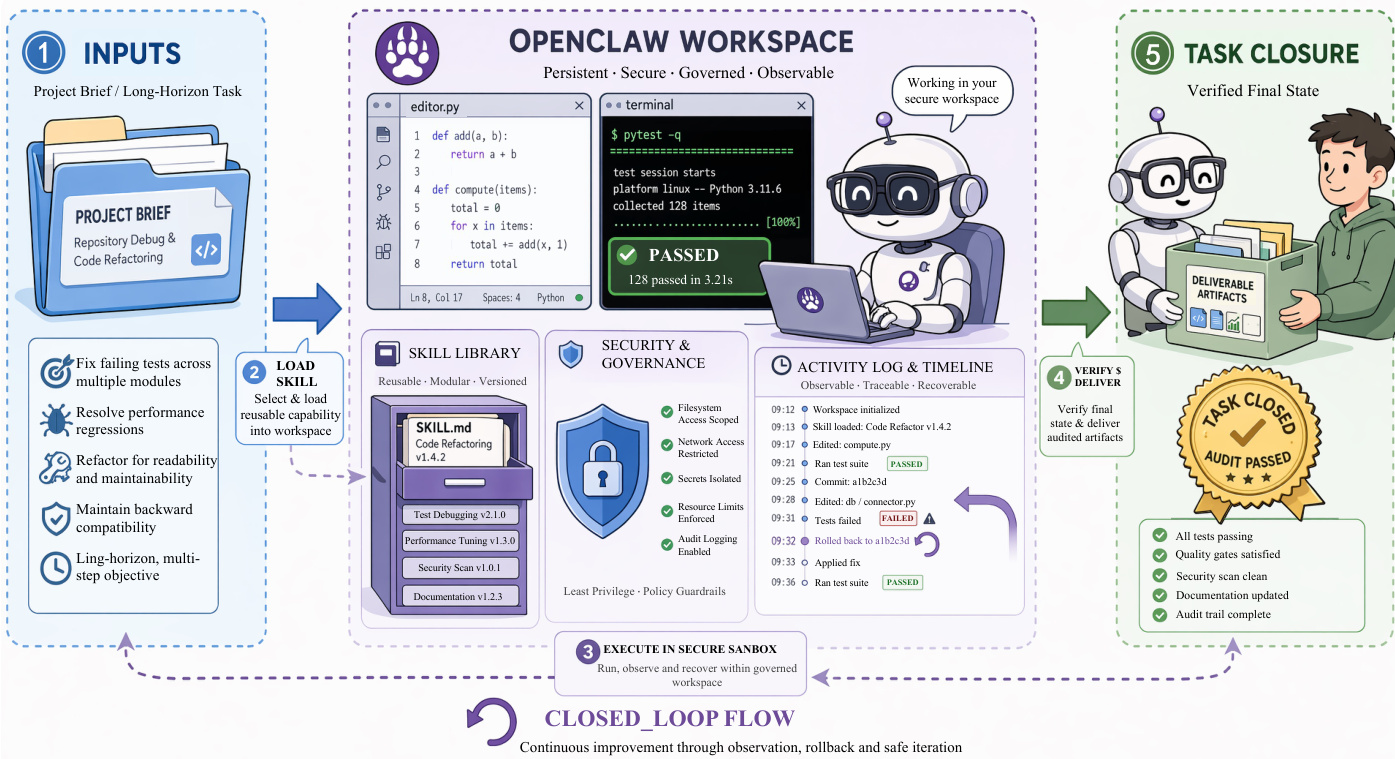
Finally, the authors present the OpenClaw paradigm, which shifts the focus from isolated tool calls to persistent, governed work execution within a digital workspace. This architecture integrates a persistent environment with modular, reusable skills to ensure task closure and reliability. The workspace serves as a durable substrate where files, logs, and execution states persist across trajectories, allowing the agent to inspect, validate, and recover from errors. Skills are implemented as modular packages, often centered around a configuration file, that provide procedural guidance, safety constraints, and verification logic. The system operates within a secure sandbox, executing actions and continuously verifying the final state against task objectives. This design enables the agent to deliver auditable, verifiable outcomes rather than merely transient responses. The OpenClaw system integrates these components into a persistent workspace, as detailed in the workflow below:
Experiment
The evaluation framework has progressed through three stages that validate increasingly complex AI behaviors, moving from early approaches that validated static tasks via final-output correctness to subsequent methods that assess the coherence and faithfulness of multi-step reasoning. Finally, modern validation focuses on task closure for agentic systems, verifying that tool usage and environmental modifications successfully achieve the intended real-world outcomes. This evolution highlights a fundamental transition from superficial answer matching to comprehensive assessment of reasoning validity and functional autonomy.
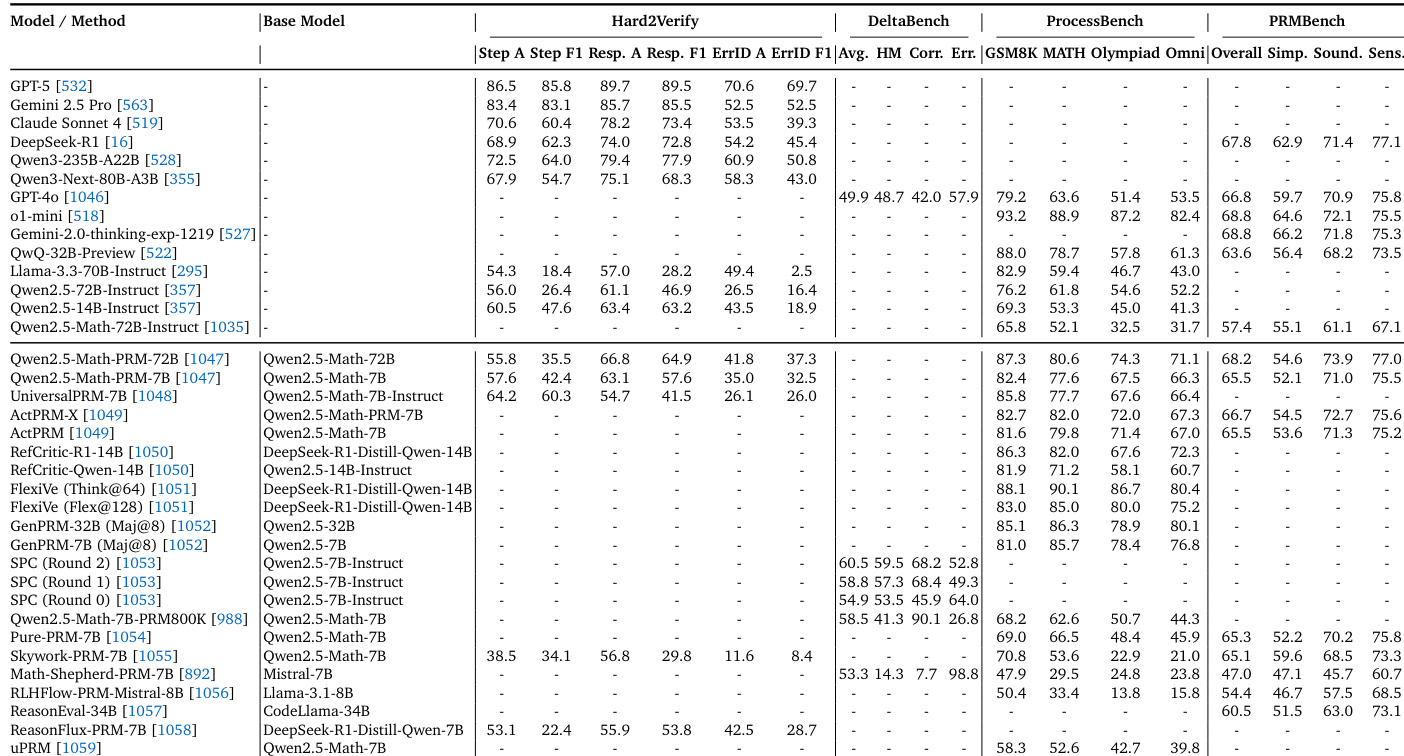
The the the table presents a comprehensive evaluation of various models and methods focused on Stage II process-level reasoning and verification. It compares general large language models against specialized Process Reward Models (PRMs) and verification techniques across multiple benchmarks including Hard2Verify, DeltaBench, ProcessBench, and PRMBench. The results highlight the performance differences between standard reasoning models and those specifically designed for step-level verification and process quality assessment. General-purpose models such as GPT-5 and o1-mini demonstrate high capabilities in step-level verification and standard mathematical reasoning tasks, often achieving superior performance on Hard2Verify and ProcessBench compared to specialized PRM baselines. Specialized Process Reward Models (PRMs) like Qwen2.5-Math-PRM and ActPRM are evaluated on PRMBench, providing specific metrics for process quality aspects such as simplicity, soundness, and sensitivity that are not reported for general models. The evaluation framework encompasses a broad range of process-level metrics, including step-level accuracy, harmonic mean of correct and error recall, and comprehensive process quality scores, illustrating the complexity of process reasoning evaluation.
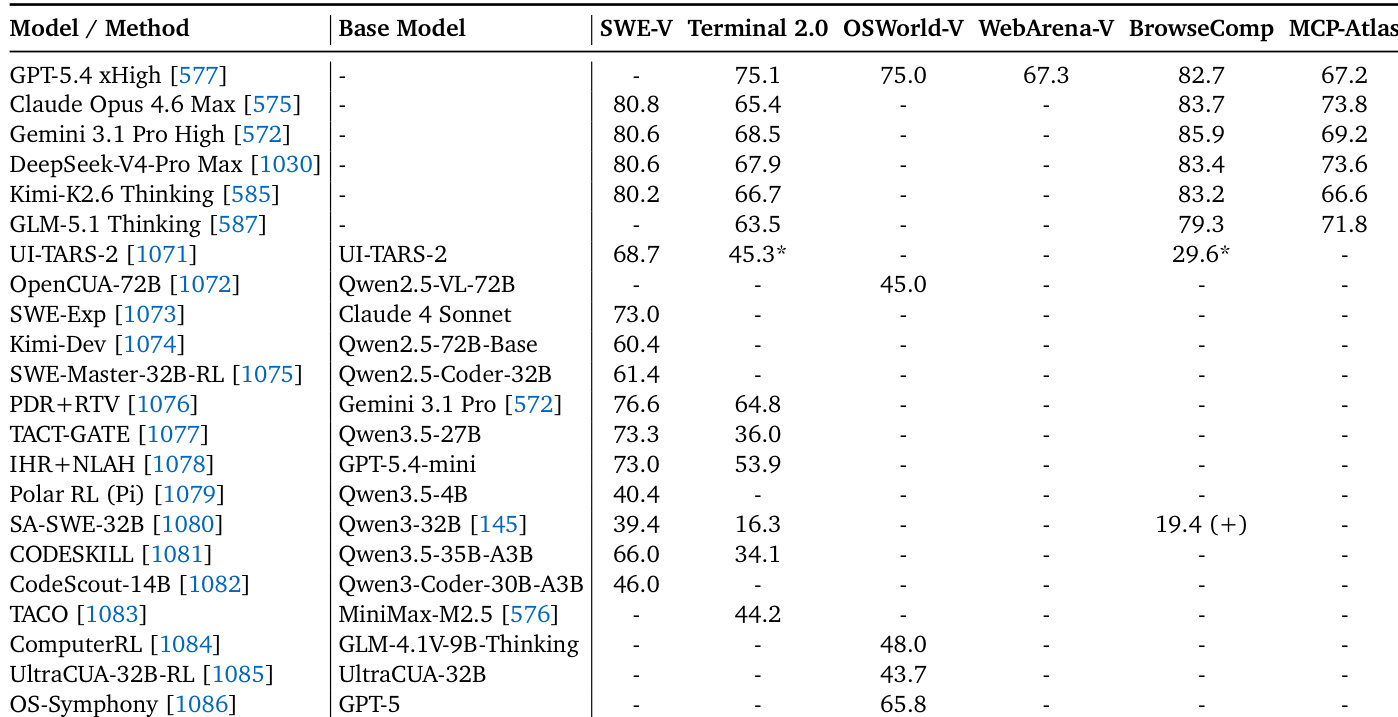
The authors present a comparative analysis of agentic models evaluated on task-closure benchmarks, reflecting the shift from final-answer accuracy to environment interaction. The the the table lists general-purpose models alongside specialized methods, assessing their performance on software engineering, terminal, OS, and web navigation tasks. Top-tier general models like GPT-5.4, Claude Opus, and Gemini demonstrate broad competence across multiple agentic benchmarks including SWE-V, Terminal 2.0, and WebArena-V. Specialized models and methods often target specific domains, with some focusing on UI tasks (UI-TARS-2), software engineering (SWE-Exp), or operating system interactions (OpenCUA-72B). The results show that specialized approaches, particularly those leveraging specific base models like Qwen2.5 variants, can achieve competitive performance on benchmarks such as SWE-V and OSWorld-V.
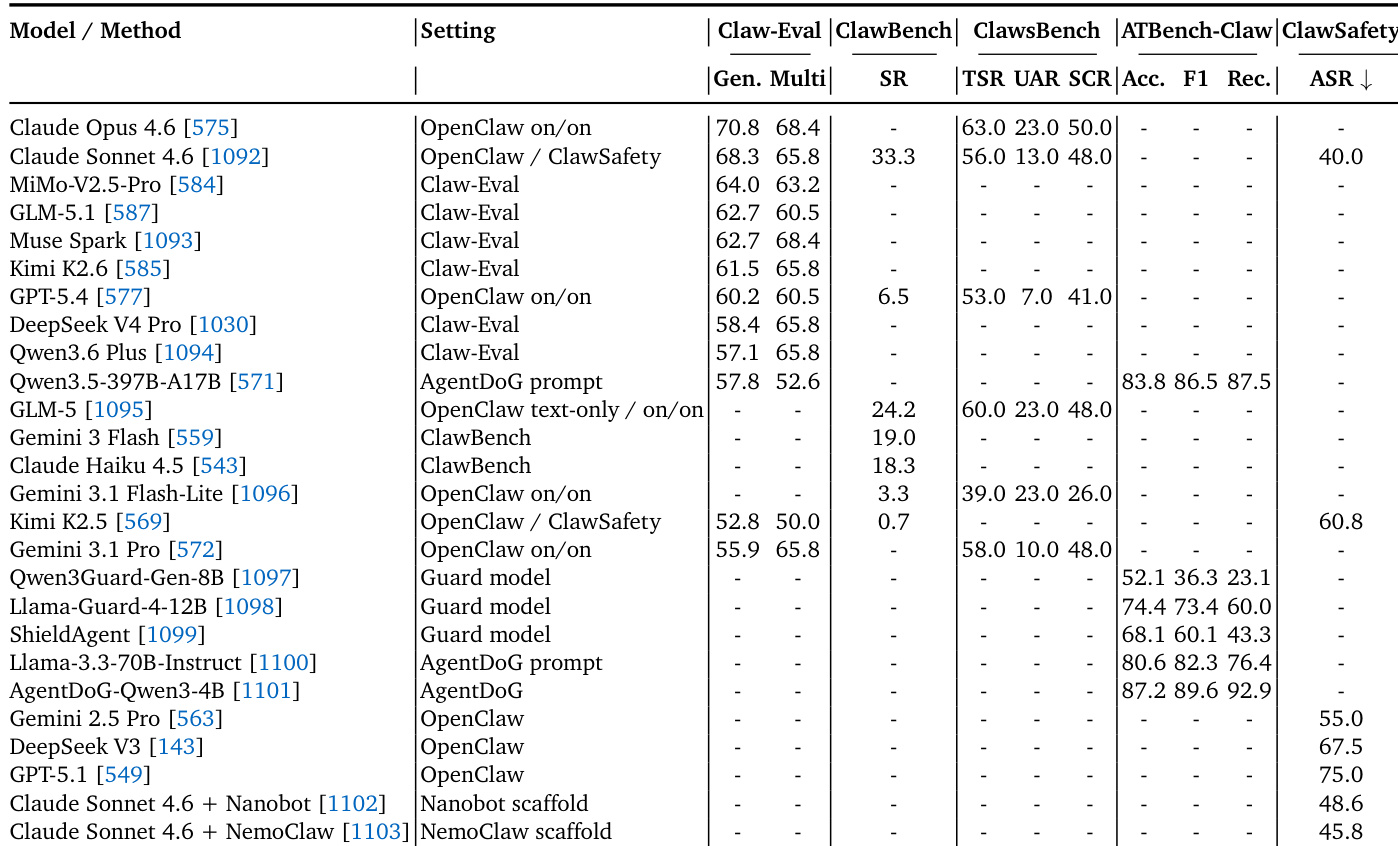
The the the table evaluates a range of large language models and specialized methods across benchmarks designed to assess agentic capabilities, including task completion, safety reasoning, and attack resistance. Claude Opus 4.6 and Claude Sonnet 4.6 generally lead in task success metrics and demonstrate the strongest safety resilience compared to other models. Specialized guard models and scaffolds show mixed results, with some excelling in reasoning tasks but others failing to improve safety metrics over base models. Claude Opus 4.6 achieves the highest performance in general and multi-turn task completion benchmarks, outperforming other leading models. Claude Sonnet 4.6 exhibits the strongest safety profile with the lowest attack success rate, significantly outperforming models such as GPT-5.1. Specialized agent methods using prompt strategies achieve high proficiency in trajectory safety reasoning, whereas dedicated guard models show lower performance in these metrics.
The the the table compares various language models on benchmarks for general knowledge, mathematical reasoning, and coding. Top-tier commercial models demonstrate superior performance across most general and coding benchmarks. Specialized models often focus on specific domains, showing strong results in mathematical reasoning tasks while sometimes lacking scores in general knowledge evaluations. Top commercial models lead in general knowledge and coding benchmarks. Specialized models excel in mathematical reasoning tasks. Models focusing on specific reasoning techniques often show high scores in math benchmarks but lack comprehensive evaluation across all categories.
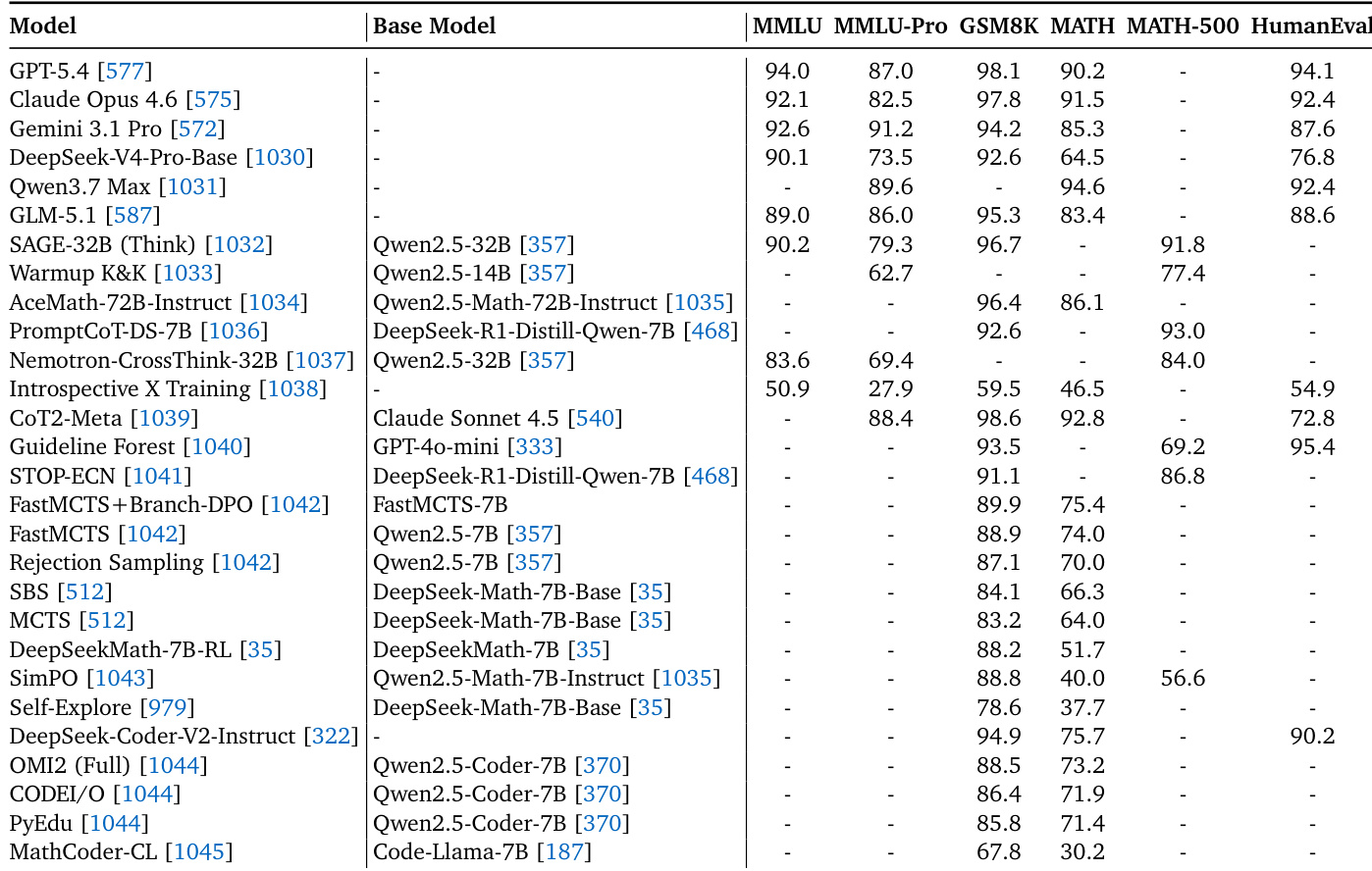
The experiments evaluate a spectrum of general-purpose and specialized large language models across benchmarks targeting process-level reasoning, agentic task closure, safety resilience, and core domain competencies. Results consistently indicate that leading commercial models demonstrate broad versatility and strong performance in general knowledge, coding, and multi-turn agentic tasks. In contrast, specialized models and verification techniques show targeted strengths, particularly in step-level mathematical reasoning and domain-specific interactions, though they often lack comprehensive cross-domain coverage. Overall, the findings highlight a clear trade-off between the wide-ranging adaptability of general models and the focused efficacy of specialized approaches.