Command Palette
Search for a command to run...
HarnessX : Une fonderie d'agents de type Harness composable, adaptatif et évolutif
HarnessX : Une fonderie d'agents de type Harness composable, adaptatif et évolutif
Darwin Agent Team
Résumé
La performance des agents d’IA dépend de manière critique du « runtime harness » (environnement d’exécution), qui englobe les prompts, les tools, la mémoire et le control flow servant d’intermédiaires pour la manière dont un modèle observe, raisonne et agit. Pourtant, les harnesses actuels restent en grande partie conçus à la main et statiques : chaque nouveau modèle ou tâche nécessite toujours un échafaudage spécifique, et les traces riches produites lors de l’exécution sont rarement exploitées pour en tirer des améliorations systématiques.Nous présentons HarnessX, une plateforme de fabrication permettant la création de harnesses d’agents composable, adaptatif et évolutif. HarnessX assemble des primitives de harness typées via une algèbre de substitution, les adapte grâce à AEGIS, un moteur d’évolution multi-agents piloté par les traces, fondé sur un miroir opérationnel entre l’adaptation symbolique et l’apprentissage par renforcement, et referme la boucle harness-modèle en transformant les trajectoires à la fois en mises à jour du harness et en signaux d’entraînement du modèle.Sur cinq jeux de données (benchmarks) – ALFWorld, GAIA, WebShop, τ3-Bench et SWE-bench Verified – HarnessX génère une amélioration moyenne de +14,5 % (jusqu’à +44,0 %), les gains étant plus marqués lorsque les performances des solutions de référence (baselines) sont les plus faibles. Ces résultats suggèrent que les progrès des agents n’ont pas besoin de provener uniquement de l’augmentation de la taille des modèles : composer et faire évoluer les interfaces d’exécution à partir des retours d’exécution constitue un levier d’action et complémentaire. L’intégralité du code source sera mise en accès libre dans une version future.
One-sentence Summary
The Darwin Agent Team introduces HarnessX, a foundry for composable, adaptive, and evolvable agent harnesses that assembles typed primitives via a substitution algebra and adapts them through AEGIS, a trace-driven multi-agent evolution engine, to close the harness-model loop by turning trajectories into harness updates and model training signal, yielding an average gain of +14.5% across five benchmarks (ALFWorld, GAIA, WebShop, τ3-Bench, and SWE-bench Verified) and demonstrating that evolving runtime interfaces complements model scaling.
Key Contributions
- This work introduces HarnessX, a foundry for constructing composable and evolvable agent harnesses that overcome the limitations of static, hand-crafted scaffolding.
- The system assembles typed harness primitives via a substitution algebra and adapts them through AEGIS, a trace-driven evolution engine that closes the loop by converting execution trajectories into harness updates and model training signals.
- Evaluation across five benchmarks demonstrates an average performance gain of +14.5% with peaks up to +44.0%, indicating that evolving runtime interfaces complements model scaling.
Introduction
AI agent performance critically depends on the runtime harness that mediates model behavior through prompts, tools, and control flow. Despite this importance, existing harnesses remain hand-crafted and static, requiring bespoke modifications for new tasks while discarding valuable execution traces. The authors address these gaps with HarnessX, a foundry that treats the harness as a composable first-class object using typed primitives and a substitution algebra. Their system employs AEGIS, a trace-driven evolution engine that adapts harness components and closes the loop with model training to achieve significant performance gains across five benchmarks without relying solely on model scaling.
Dataset
The authors utilize a comprehensive evaluation suite to assess agent performance across various failure modes.
-
Dataset Composition and Sources
- The evaluation spans five benchmarks: GAIA, ALFWorld, WebShop, τ3-Bench, and SWE-bench Verified.
- These sources cover tasks ranging from short-horizon embodied planning to long-horizon software engineering.
-
Key Details for Each Subset
- GAIA: Consists of 103 tasks distributed across three difficulty levels to evaluate exact match against reference answers.
- ALFWorld: Uses the valid-unseen split containing 134 tasks across six types including pick-and-place and cool-and-place.
- WebShop: Samples 100 instances with a fixed seed to simulate independent online shopping sessions.
- τ3-Bench: Focuses on three domains (Retail, Airline, and Telecom) to test dialogue-policy adherence.
- SWE-bench Verified: Selects a 55-task subset to measure patch resolution on real GitHub issues.
-
Data Usage and Processing
- Fixed evaluation sets are re-scored at every evolution round to measure round-over-round changes on stable task sets.
- Each run generates a self-describing directory layout with artifacts like INDEX.md, journal.md, and audit.jsonl.
- Metadata construction includes cross-round ledgers stored in data/ship_outcomes.json and per-task analysis in digests folders.
- Raw rollouts and candidate manifests are saved as jsonl files to support decision reconstruction.
Method
The authors propose HarnessX, a framework designed to close the optimization loop between agent scaffolding and model capability. The system operates through a continuous cycle where the execution harness is composed, adapted based on runtime traces, and evolved alongside the underlying foundation model. Refer to the framework diagram for the high-level interaction between composition, adaptation, and evolution.
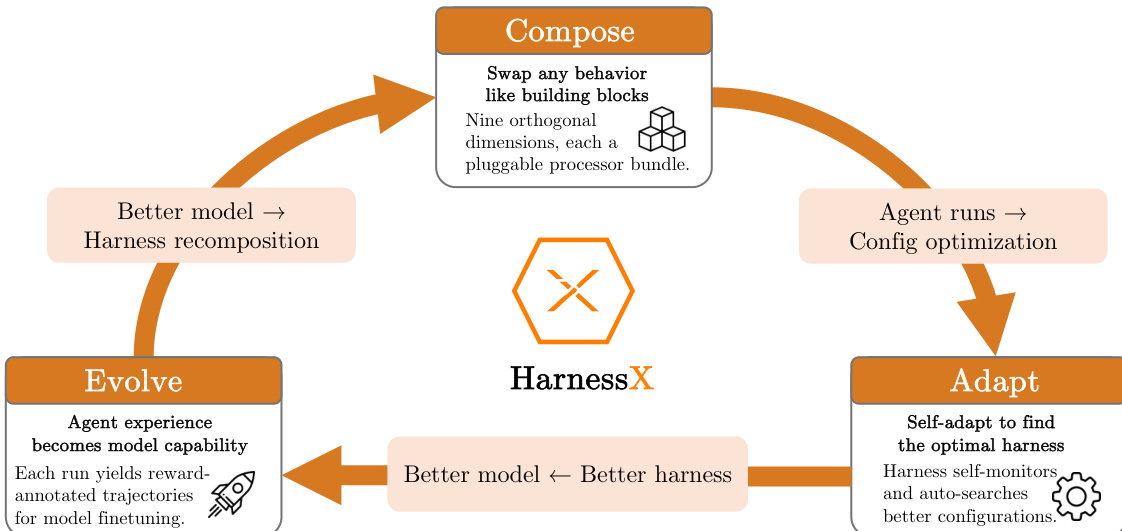
Harness Composition and AEGIS Architecture
The foundational layer of the system is the harness, formalized as a first-class, typed object. A harness H consists of a model configuration M and a harness configuration C. The configuration C is composed of processors attached to specific lifecycle hooks, enabling behavioral changes to be inserted, removed, or swapped without breaking type safety. The authors organize the behavioral space into nine orthogonal dimensions, covering aspects such as model selection, context assembly, memory management, and tool ecosystems.
To automate the improvement of these configurations, the authors introduce AEGIS, a trace-driven evolution engine. As shown in the figure below:
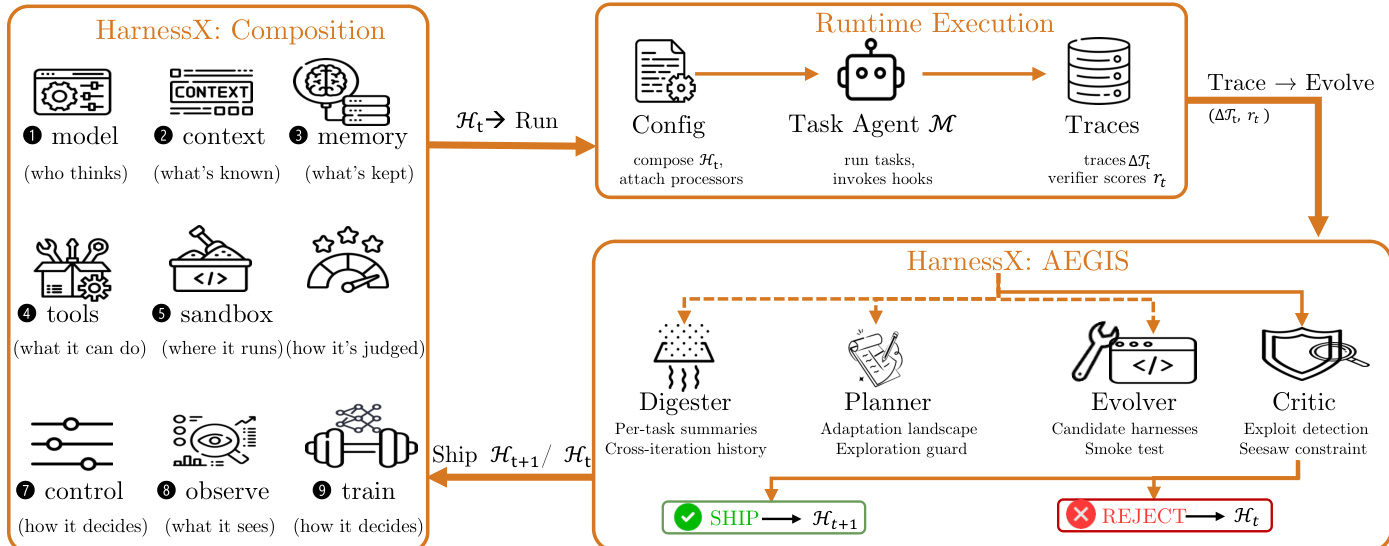
AEGIS maps harness adaptation onto standard reinforcement learning constructs, treating harness configurations as states and typed code edits as actions. To address common RL pathologies like reward hacking and catastrophic forgetting, the engine employs a four-stage pipeline driven by a meta-agent:
- Digester: Compresses raw execution traces into structured per-task summaries, identifying failure categories and implicated components.
- Planner: Constructs an adaptation landscape by analyzing the digested evidence and historical edits, determining which structural or incremental changes are viable.
- Evolver: Generates candidate harness edits based on the adaptation landscape, ensuring type safety through a builder algebra.
- Critic: Validates candidates against trace evidence and regression constraints.
A deterministic gating layer follows the Critic, enforcing a "seesaw constraint" where a candidate edit is only shipped if it does not regress performance on previously solved tasks. This ensures that evolution proceeds safely even when the meta-agent proposes aggressive changes.
Harness-Model Co-Evolution
While evolving the harness alone yields significant gains, the authors identify a "scaffolding ceiling" where the fixed model's reasoning capacity eventually limits performance. Conversely, training the model under a fixed harness hits a "training-signal ceiling." To break these limits, HarnessX interleaves harness evolution with model reinforcement learning over a shared replay buffer.
The co-evolution mechanism is illustrated in the figure below:
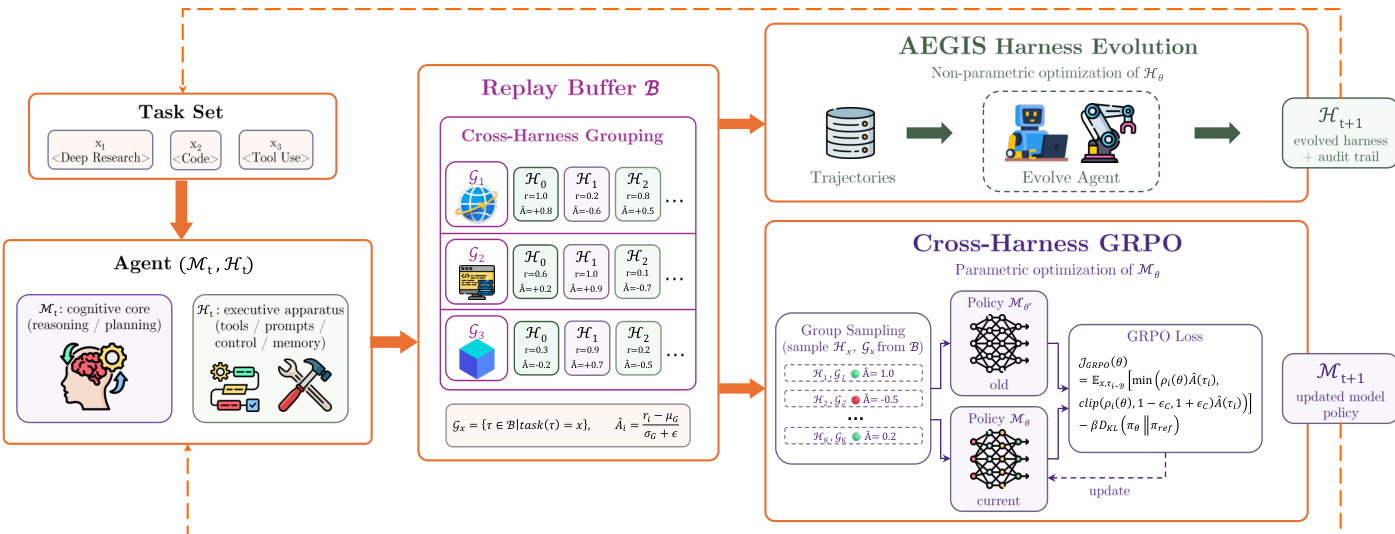
The system maintains a shared replay buffer B that stores trajectories (τ,r) from multiple iterations, each tagged with the specific model and harness version that generated it. This buffer drives two parallel optimization processes:
- AEGIS Harness Evolution: The meta-agent reads the buffered traces to propose non-parametric structural edits to the harness Ht, resulting in Ht+1.
- Cross-Harness GRPO: The model Mt is updated via Group Relative Policy Optimization. Trajectories are grouped by task identity across different harness versions, allowing the model to compute advantages based on inter-strategy reward contrasts rather than stochastic sampling noise alone.
The group-relative advantage A^(τi) for a trajectory τi is calculated as:
A^(τi)=σ(Gx)+ϵri−μ(Gx)where Gx represents the set of all trajectories for task x in the buffer, regardless of the harness version used. This approach allows the model to internalize successful strategies from successive harness versions, effectively learning to exploit the evolving scaffold. By sharing the replay buffer, the system achieves joint optimization at no additional rollout cost, as the same traces serve as both diagnostic evidence for the harness and training signals for the model.
Experiment
HarnessX is evaluated across five diverse benchmarks and three model families to validate the effectiveness of trace-driven harness evolution against static baselines. Experiments demonstrate that evolutionary gains are most pronounced for weaker models and that variant isolation strategies are critical for maintaining stability on heterogeneous task sets where global evolution causes catastrophic forgetting. Further analysis indicates that infrastructure efficiency matters more than evolver architecture for accuracy, while joint co-evolution with model training successfully breaks performance ceilings and validates that predicted failure modes are detectable.
The experiment compares a Global evolution strategy against a variant isolation ablation on the GAIA benchmark, alongside results for ALFWorld. While the Global strategy failed to improve performance on GAIA, the variant isolation approach successfully generated positive gains and did so more efficiently. In contrast, the Global strategy achieved improvements on the ALFWorld benchmark. Variant isolation resolved the performance stagnation observed with the Global strategy on the GAIA benchmark. The variant isolation method achieved better results with lower token consumption compared to the Global strategy. The ALFWorld benchmark demonstrated successful performance gains under the Global strategy configuration.

The authors compare a variant-isolation strategy against a single-harness global strategy to address stability issues in harness evolution. Results indicate that maintaining multiple harness variants prevents the performance degradation seen in the global approach, resulting in a higher final accuracy and a stable trajectory. The variant strategy also achieves these improvements with greater token efficiency compared to the global baseline. The ensemble strategy sustains its peak performance through the final round, while the global strategy suffers a substantial drop in accuracy. Variant isolation avoids the catastrophic forgetting that causes the single-harness method to stagnate or regress. The multi-variant approach consumes fewer tokens than the single-harness baseline while delivering superior results.

The authors evaluate the four-stage AEGIS evolver against a single-agent baseline to determine the value of the architectural decomposition. Results demonstrate that both approaches yield comparable accuracy, with the multi-stage pipeline achieving a negligible improvement. The primary advantage of the four-stage pipeline lies in its efficiency, consuming notably fewer tokens to achieve similar performance outcomes. The multi-stage evolver achieves accuracy comparable to the single-agent baseline. Token consumption is significantly lower for the four-stage architecture. Performance gains appear driven by the shared infrastructure rather than the evolver's internal structure.

The authors evaluate the effectiveness of their evolution framework across multiple benchmarks and model families. Results show that the evolved harnesses generally lead to performance improvements over the initial static configuration. The data suggests an inverse relationship between baseline capability and improvement magnitude, where weaker models benefit most from the evolution process. Evolution improved performance in nearly all tested model and benchmark combinations. Models with lower initial baseline scores consistently demonstrated the largest performance gains. Performance stagnation occurred in a specific heterogeneous task setting, indicating limits for single-harness strategies.
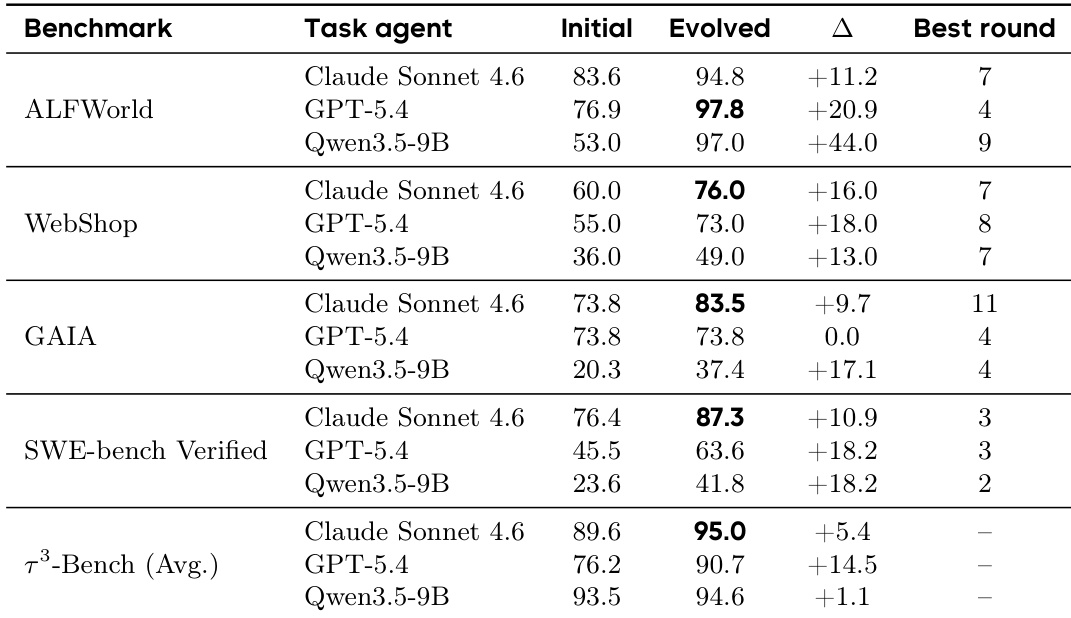
The experiments evaluate global and variant isolation strategies alongside a four-stage evolver across GAIA, ALFWorld, and various model families. Variant isolation prevents the performance stagnation and catastrophic forgetting observed in global approaches while improving token efficiency. The four-stage pipeline matches single-agent accuracy with lower token consumption, and evolution yields the largest gains for models with weaker baseline capabilities.