Command Palette
Search for a command to run...
Orchestra-o1: Omnimodal Agent Orchestration
Orchestra-o1: Omnimodal Agent Orchestration
Résumé
Le récent succès des essaims d'agents a fait évoluer le paradigme des agents basés sur des modèles de langage de grande taille (LLM) des workflows single-agent vers des systèmes multi-agents, soulignant l'importance de l'orchestration des agents pour la décomposition des tâches et la collaboration. Toutefois, les frameworks d'orchestration existants se limitent à un ensemble restreint de modalités et peinent à se généraliser à des contextes plus complexes où des modalités hétérogènes coexistent et interagissent. Cette limitation se révèle particulièrement marquée dans les scénarios omnimodaux, où les tâches exigent une compréhension et une coordination unifiées d'entrées variées telles que le texte, l'image, l'audio et la vidéo. Dans ce travail, nous proposons Orchestra-o1, un framework d'orchestration d'agents omnimodal conçu pour faciliter une collaboration efficace des agents sur plusieurs modalités. Orchestra-o1 introduit un mécanisme d'orchestration unifié permettant une décomposition des tâches sensible aux modalités, une spécialisation en ligne des sous-agents et l'exécution parallèle des sous-tâches. Cette architecture évolutive permet aux systèmes d'agents de traiter efficacement des tâches complexes du monde réel impliquant des sources d'information hétérogènes, dépassant la deuxième meilleure approche de 10,3 % en précision sur le benchmark OmniGAIA. Par ailleurs, nous introduisons l'optimisation de politique relative de groupe alignée sur la décision (DA-GRPO), une approche efficace d'apprentissage par renforcement agentique pour l'entraînement de Orchestra-o1-8B, qui atteint également des performances de pointe face à l'ensemble des agents omnimodaux open-source existants.
One-sentence Summary
Orchestra-o1 is an omnimodal agent orchestration framework that employs a unified mechanism for modality-aware task decomposition, online sub-agent specialization, and parallel sub-task execution, and its DA-GRPO-trained Orchestra-o1-8B variant achieves state-of-the-art performance against existing open-source omnimodal agents, surpassing the second-best approach by 10.3% accuracy on the OmniGAIA benchmark.
Key Contributions
- This work introduces Orchestra-o1, an omnimodal agent orchestration framework that unifies the coordination of text, image, audio, and video inputs. The system implements a modular architecture featuring modality-aware task decomposition, online sub-agent specialization, and parallel sub-task execution to manage complex heterogeneous information sources.
- The paper presents decision-aligned group relative policy optimization (DA-GRPO), a reinforcement learning algorithm designed for efficient agentic training. This method aligns decision-level orchestration to train the Orchestra-o1-8B variant while maintaining fixed sub-agent backends during the optimization process.
- Evaluations on the OmniGAIA benchmark demonstrate that the framework surpasses the second-best approach by 10.3% accuracy while delivering faster inference and improved cost-effectiveness. The trained model also achieves state-of-the-art performance against all existing open-source omnimodal agents.
Introduction
The shift from single-agent systems to multi-agent swarms has made orchestration critical for decomposing and coordinating complex tasks, particularly as real-world applications demand unified processing across text, image, audio, and video. However, current frameworks remain constrained to narrow modalities, rely on rigid linear workflows, and struggle to effectively coordinate heterogeneous inputs or leverage comprehensive toolsets. The authors address these gaps by introducing Orchestra-01, an omnimodal orchestration framework that decouples high-level reasoning from specialized perception and action. Their design enables modality-aware task decomposition, dynamic sub-agent specialization, and parallel execution within a unified tool ecosystem. To further enhance open-source capabilities, the authors also develop DA-GRPO, a reinforcement learning algorithm that aligns step-level orchestration decisions with high-quality reference trajectories, enabling efficient training of scalable omnimodal agent systems.
Dataset

-
Dataset Composition and Sources: The authors use public multimodal benchmarks, specifically FineVideo, LongVideoBench, and COCO 2017, as the foundation for the dataset. Each initial seed consists of a question, a multimodal input (image, audio, or video), a ground truth answer, and a required tool set.
-
Subset Sizes and Filtering Rules: Starting with 300 seed examples, the pipeline generates approximately 1,500 candidate rewrites using five transformation strategies distributed across easy, medium, and hard difficulty tiers. Candidates undergo a five-step verification process that enforces anchor fact coverage, limits lexical similarity to 0.85, performs a modal bypass test, validates numerical answers in a Python sandbox, and applies an LLM judge for factual consistency and duplication. This yields a final curated set of roughly 1,200 verified examples.
-
Data Usage and Training Integration: The authors use this dataset for post-training Orchestra-o1-8B, which is derived from Qwen3-8B. Rather than treating the data as static pairs, they decompose full orchestration trajectories into decision-level samples. Each sample reconstructs the main agent state before an expert decision and pairs it with the reference orchestration action, providing dense supervision for delegation, tool routing, backend selection, and parallel scheduling.
-
Processing and Metadata Construction: The authors keep the original modality files unchanged throughout the pipeline to preserve perceptual grounding. They extract modality-specific anchor facts that serve as non-bypassable constraints during rewriting. All language model components, including the anchor extractor, question rewriter, and verification judge, are implemented using Claude-Opus-4.6 to ensure consistent quality and factual alignment.
Method
The authors formulate omnimodal agent orchestration as a multi-round decision-making problem over heterogeneous inputs. Given a task instance x=(q,M), where q denotes the natural-language question and M represents a set of auxiliary modality inputs such as images, audios, and videos, the objective is to produce a concise final answer that maximizes the task reward. Traditional approaches typically rely on a single native omnimodal agent that processes all inputs internally.
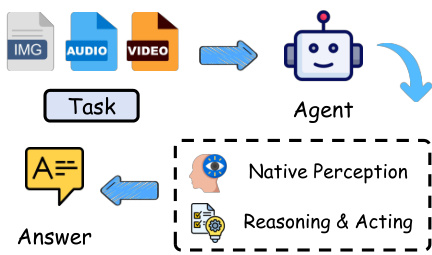
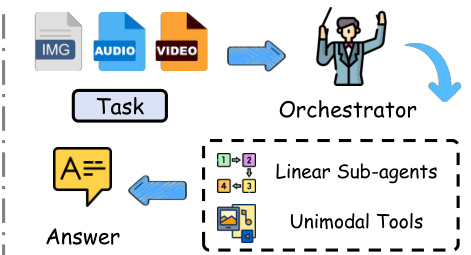
As illustrated in the diagram above, this native design compresses diverse modalities into a single internal representation, which often leads to information bottlenecks and high computational costs. To address these limitations, the authors explore alternative orchestration paradigms. A linear orchestrator decomposes tasks into sequential sub-tasks handled by unimodal tools, which fails to exploit concurrency.
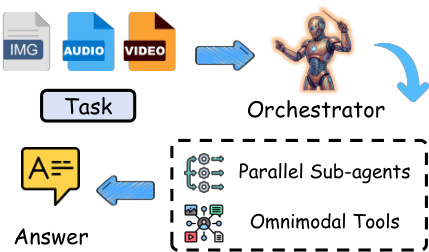
Conversely, a parallel orchestrator attempts to execute multiple sub-tasks simultaneously using omnimodal tools, but lacks the sophisticated dependency tracking required for complex reasoning.
Refer to the framework diagram below for the complete architecture of the proposed Orchestra-o1 system. The framework implements a hierarchical policy that factorizes complex problem solving into high-level orchestration and low-level specialized execution. The main agent acts as an orchestrator rather than directly operating on every modality. At each orchestration round t, it observes a state defined by the question, modality inputs, accumulated context, structured sub-task history, available sub-agent models, and the tool ecosystem. The system state is formulated as:
st=(q,M,ct,Ht,B,T),where ct is the accumulated context, Ht is the structured sub-task history, B is the set of available sub-agent models, and T is the set of tools available to sub-agents. The main agent outputs a structured decision yt from two action types: delegate or complete. If the complete action is selected, the main agent terminates the trajectory and returns the final answer. If the delegate action is selected, it generates a batch of sub-tasks.
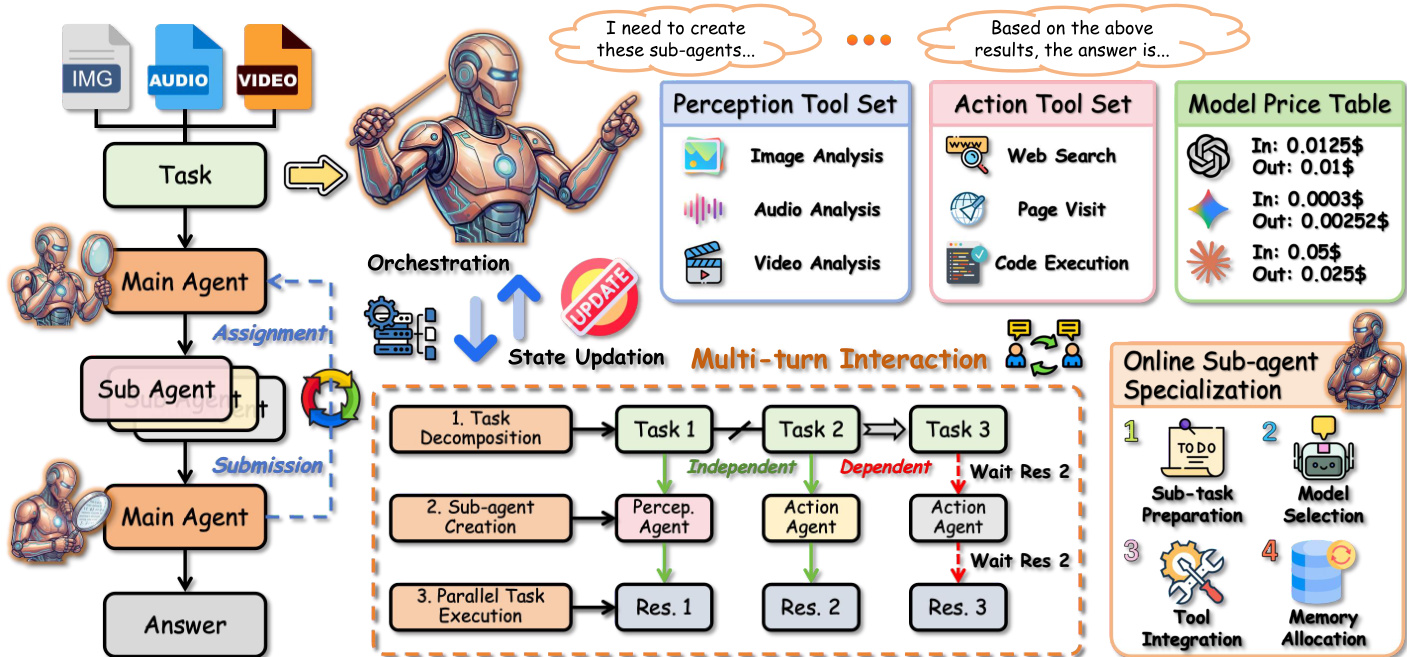
The framework incorporates flexible agentic backends and a unified omnimodal tool ecosystem. Each backend is represented by a skill vector and a cost-latency profile. The main agent predicts a requirement vector for each candidate sub-task and selects the optimal backend by maximizing a cost-aware matching score. Similarly, tool assignment is formulated as a requirement matching problem, where the system selects a subset of tools that maximizes sparse coverage while minimizing redundancy. The perception tool set includes image, audio, and video analysis capabilities, while the action tool set contains web search, page visit, and code execution utilities.
At each round, the main agent induces a latent dependency graph over unsolved sub-goals. Each node is associated with a modality mask and a tool mask. A sub-goal becomes executable only after all its predecessors are completed. The main agent selects a parallel batch from the ready set under dependency and budget constraints. For each selected node, the system materializes a concrete sub-task by assigning a specific backend and tool subset. Each delegated sub-task is then executed by an independent ReAct-style sub-agent. Since the sub-tasks in the parallel batch are conditionally independent given the current state and do not share mutable environment states, their execution factorizes, yielding a formal latency advantage over sequential execution.
After each delegation round, the system updates a structured memory that stores the evidence returned by all sub-agents. To keep the main-agent context within the token budget, Orchestra-o1 constructs a compressed context by solving an information relevance optimization problem. The main agent terminates the process when its evidence sufficiency score exceeds a predefined threshold. Otherwise, it refines the dependency graph according to new evidence and continues delegation. This closed-loop decision process separates high-level planning from specialized perception and action execution, ensuring modularity and scalability.
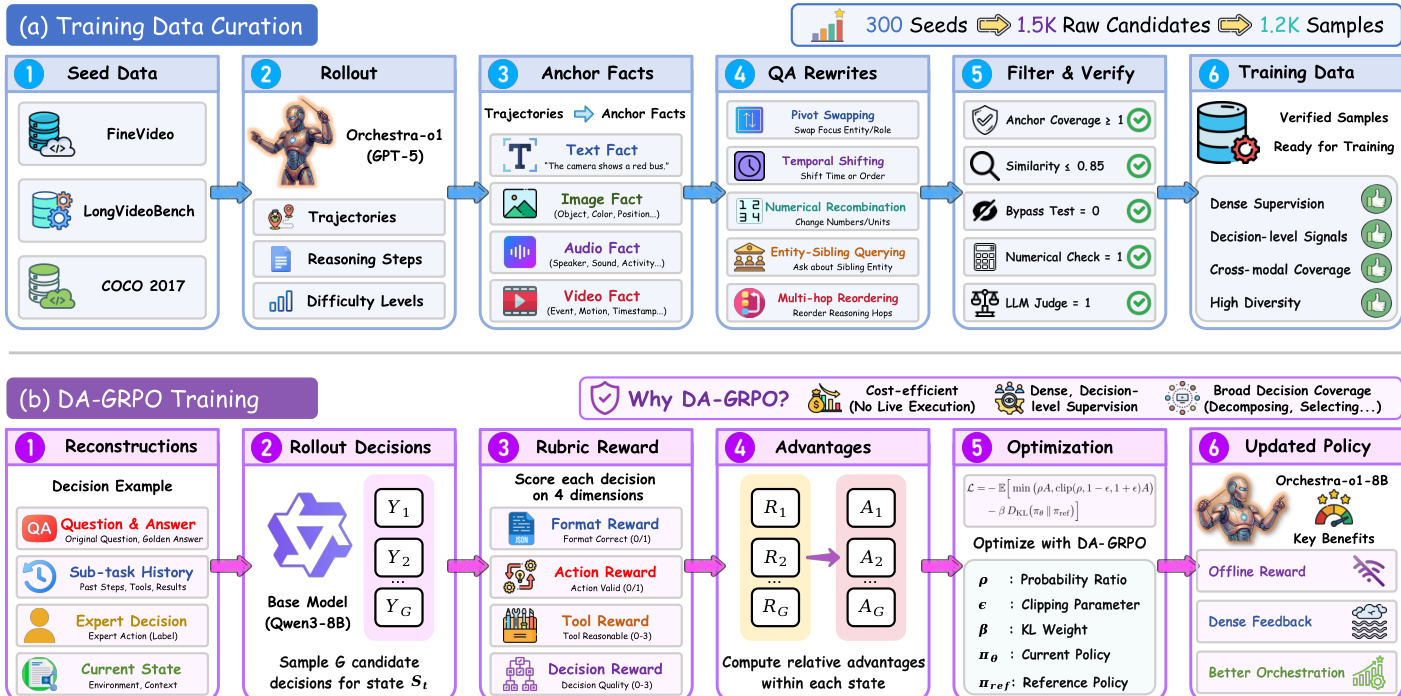
To derive an open-source main agent capable of effective orchestration, the authors propose a training recipe centered on decision-aligned group relative policy optimization (DA-GRPO). Standard group relative policy optimization suffers from sparse and expensive final-answer rewards in multi-agent systems. DA-GRPO instead evaluates each sampled main-agent decision directly at the current orchestration state using a rubric reward that measures format correctness, action validity, tool reasonableness, and overall decision quality.
For each prompt, the policy samples a group of candidate decisions. Each decision is scored by a multi-dimensional reward function that combines binary format and action rewards with graded tool and decision rewards. A lightweight reward model evaluates these dimensions in a single call, using expert trajectories as references while rewarding alternative but reasonable decompositions. Given the group rewards, DA-GRPO computes the relative advantage of each sampled decision by normalizing within the group. The policy is then optimized using a clipped policy-gradient objective and a KL regularizer to the reference model. This approach avoids repeatedly executing expensive sub-agent trajectories during training while providing dense feedback on the main agent core responsibilities. The resulting open-source model, Orchestra-o1-8B, demonstrates substantial improvements over strong open-source omnimodal baselines by learning to coordinate specialized agents, tools, and evidence sources in a principled and efficient manner.
Experiment
Evaluated on the OmniGAIA benchmark, the experiments compare Orchestra-o1 against native, proprietary, and orchestration-based baselines across diverse multimodal categories and difficulty levels. The main results validate that explicit orchestration significantly enhances multi-step reasoning and cross-domain accuracy while improving cost-efficiency through parallel task execution. Ablation studies further confirm that these gains originate from the structured decomposition framework and targeted training pipeline rather than the underlying model capacity alone. Ultimately, the findings demonstrate that strategic orchestration combined with specialized reinforcement learning enables both compact and advanced models to achieve robust, efficient performance on complex omnimodal tasks.
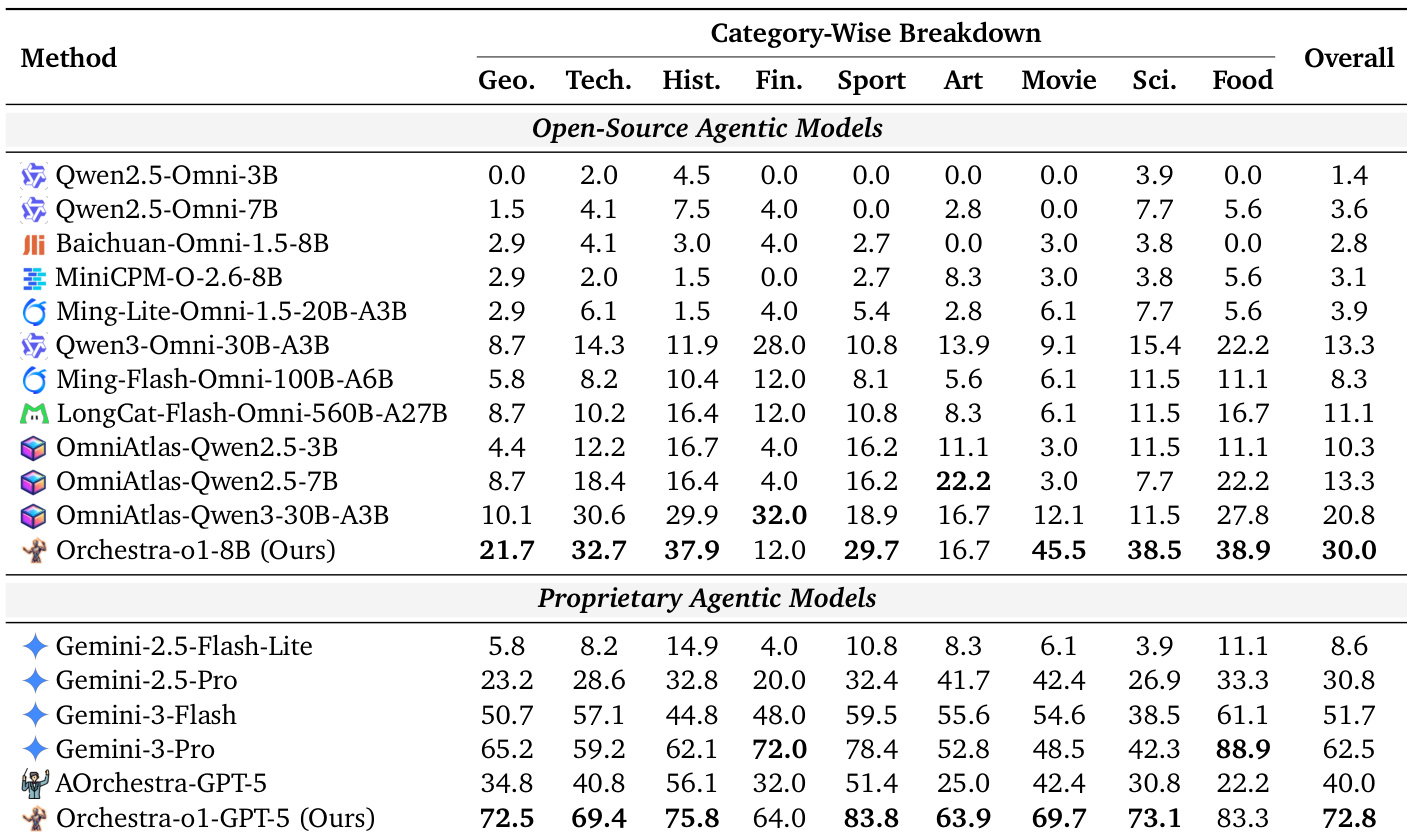
The authors evaluate their proposed Orchestra-o1 framework against a range of open-source and proprietary agentic models on the OmniGAIA benchmark. The results indicate that both the open-source and proprietary variants of Orchestra-o1 achieve the highest overall accuracy within their respective groups, consistently outperforming strong baselines like Gemini-3-Pro and OmniAtlas across diverse topic categories. Orchestra-o1-GPT-5 achieves the highest overall accuracy among proprietary models, surpassing Gemini-3-Pro. The open-source Orchestra-o1-8B model leads the open-source group, outperforming OmniAtlas-Qwen-3-30B-A3B. The method shows consistent improvements across nearly all category-wise breakdowns, indicating broad utility.
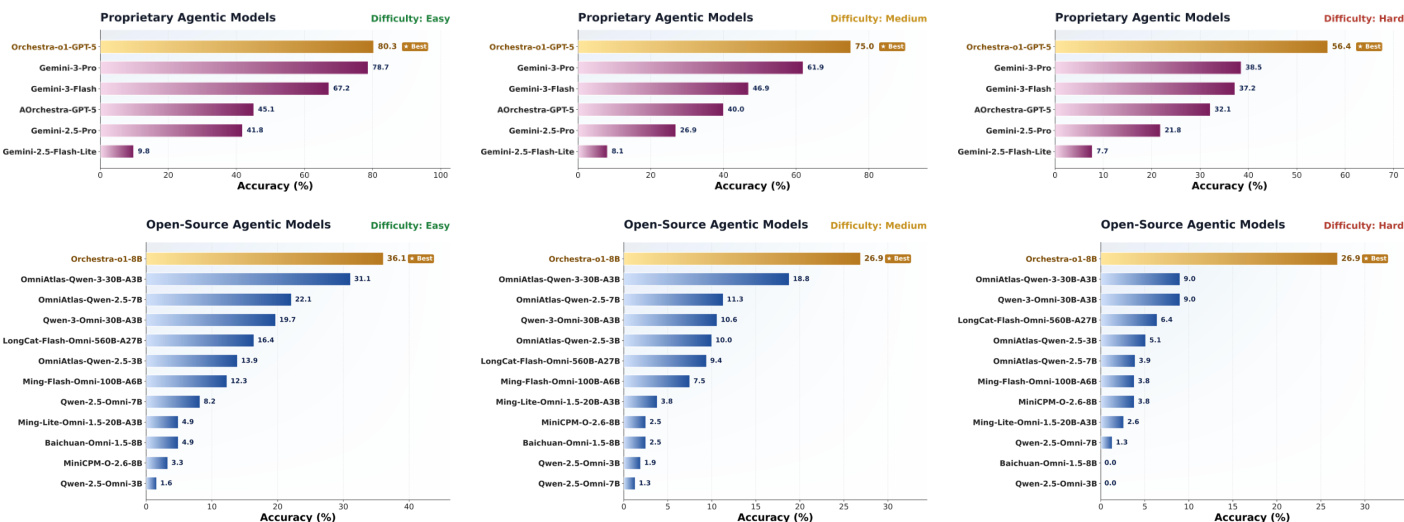
The authors evaluate agentic models on the OmniGAIA benchmark, comparing their proposed Orchestra-o1 framework against proprietary and open-source baselines. The results demonstrate that Orchestra-o1 consistently achieves the highest accuracy across easy, medium, and hard difficulty levels in both model categories. Orchestra-o1-GPT-5 achieves the best performance among proprietary models, significantly outperforming Gemini-3-Pro and AOrchestra-GPT-5. The open-source Orchestra-o1-8B variant leads the open-source category, surpassing the strongest baseline OmniAtlas-Qwen-3-30B-A3B across all difficulty levels. Although performance drops for all models as difficulty increases, Orchestra-o1 maintains a substantial lead, with the performance gap over competitors becoming more pronounced on harder tasks.
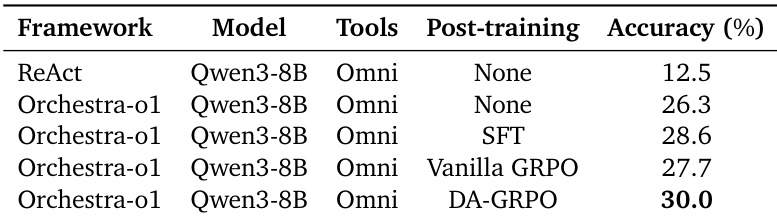
The authors evaluate the Qwen3-8B model on the OmniGAIA benchmark to assess the impact of the Orchestra-o1 framework and various post-training techniques. The results demonstrate that the orchestration framework provides a significant performance boost over standard baselines, and specific post-training methods further enhance these capabilities, with DA-GRPO yielding the best results. The Orchestra-o1 framework significantly improves accuracy compared to the standard ReAct baseline without any post-training. Supervised fine-tuning (SFT) yields better results than vanilla GRPO when applied to the orchestration framework. The DA-GRPO method achieves the highest accuracy, demonstrating superior performance compared to other post-training strategies.
Evaluated on the OmniGAIA benchmark, the Orchestra-o1 framework consistently outperforms leading proprietary and open-source agentic models across diverse topics and difficulty levels. The initial comparisons validate the framework's superior general reasoning capabilities, while difficulty-based testing confirms that its performance advantage scales with task complexity. Component analysis further demonstrates that the core orchestration architecture provides significant accuracy improvements over standard baselines, with specialized post-training methods delivering optimal results. Collectively, these findings establish Orchestra-o1 as a highly effective and broadly applicable solution for complex agentic workflows.