Command Palette
Search for a command to run...
InterleaveThinker : Renforcement de la Génération Entrelacée Agentique
InterleaveThinker : Renforcement de la Génération Entrelacée Agentique
Dian Zheng Harry Lee Manyuan Zhang Kaituo Feng Zoey Guo Ray Zhang Hongsheng Li
Résumé
Les générateurs d'images récents ont fait preuve d'un photoréalisme remarquable et de capacités de suivi des instructions pour la génération et la modification d'images uniques. Cependant, limités par leurs architectures, ils ne peuvent pas réaliser de génération entrelacée (séquence texte-image), qui présente des applications cruciales dans les récits visuels, le guidage et la manipulation incarnée. Même les derniers modèles multimodaux unifiés open-source (UMMs) affichent des performances limitées à cet égard. Dans cet article, nous présentons InterleaveThinker, le premier pipeline multi-agent conçu pour doter n'importe quel générateur d'images existant de capacités de génération entrelacée. Plus précisément, nous employons un planner agent afin d'organiser la séquence d'entrée image-texte, en instruisant le générateur d'images sur l'exécution requise à chaque étape. Par la suite, nous introduisons un critic agent pour évaluer les sorties du générateur, identifier les échantillons qui s'écartent des instructions planifiées et affiner les instructions pour une régénération. Pour implémenter ce pipeline, nous construisons Interleave-Planner-SFT-80k et Interleave-Critic-SFT-112k afin de procéder à un amorçage à froid du format. Nous développons ensuite Interleave-Critic-RL-13k pour renforcer la capacité de correction des instructions étape par étape au sein d'une trajectoire de génération à l'aide de GRPO. Étant donné qu'une seule trajectoire de génération entrelacée peut impliquer plus de 25 appels au générateur, l'optimisation de la trajectoire entière est computationnellement impraticable. Par conséquent, nous proposons une récompense de précision et une récompense étape par étape, permettant au RL en une seule étape de guider efficacement l'ensemble de la trajectoire de génération. Les résultats montrent qu'InterleaveThinker améliore les performances de divers générateurs d'images. Sur les benchmarks de génération entrelacée, il atteint des performances comparables à celles de Nano Banana et GPT-5. De manière surprenante, il améliore également significativement le modèle de base sur les benchmarks de raisonnement ; par exemple, sur 4-step FLUX.2-klein, nous observons des gains substantiels sur WISE et RISE.
One-sentence Summary
InterleaveThinker is a multi-agent pipeline that equips existing image generators with interleaved text-image sequence generation by coordinating a planner agent to structure stepwise instructions and a critic agent to evaluate outputs and refine subsequent prompts, with stepwise instruction correction within generation trajectories reinforced through GRPO to address the architectural constraints of prior unified multimodal models in visual narratives and embodied manipulation.
Key Contributions
- The paper introduces InterleaveThinker, a multi-agent pipeline that retrofits frozen image generators with interleaved text-image sequence generation without modifying their base architectures. A planner agent structures the execution steps while a critic agent evaluates outputs, identifies deviations, and refines prompts to ensure strict trajectory adherence.
- Training is enabled through three curated datasets, Interleave-Planner-SFT-80k and Interleave-Critic-SFT-112k for format cold-starting, and Interleave-Critic-RL-13k for reinforcement learning. A GRPO-based optimization with a dual-reward strategy comprising accuracy and step-wise rewards efficiently aligns long-horizon generation trajectories at reduced computational cost.
- Evaluated on off-the-shelf generators such as FLUX.2-klein, the framework surpasses open-source unified multimodal models on interleaved generation benchmarks and matches proprietary systems like Nano Banana and GPT-5. The approach also substantially improves reasoning performance on the WISE benchmark (0.47 to 0.73) and the RISE benchmark (13.3 to 28.9).
Introduction
Modern image generation models excel at single-image synthesis, yet practical applications like visual storytelling and embodied manipulation demand interleaved generation that seamlessly alternates text and image outputs. While Unified Multimodal Models attempt to support this workflow, they frequently exhibit visual over-reliance on intermediate states and suffer from compounding step-by-step errors during extended sequences. To address these limitations, the authors propose InterleaveThinker, a multi-agent framework that retrofits frozen image generators with robust sequential capabilities. The system utilizes a Planner agent to forecast complete instruction trajectories upfront, effectively bypassing premature visual dependency, while a Critic agent evaluates outputs and refines prompts to prevent error accumulation. By combining this architecture with a curated training dataset and a dual-reward reinforcement learning strategy, the authors achieve trajectory-level alignment that matches proprietary models and significantly enhances base model reasoning.
Dataset
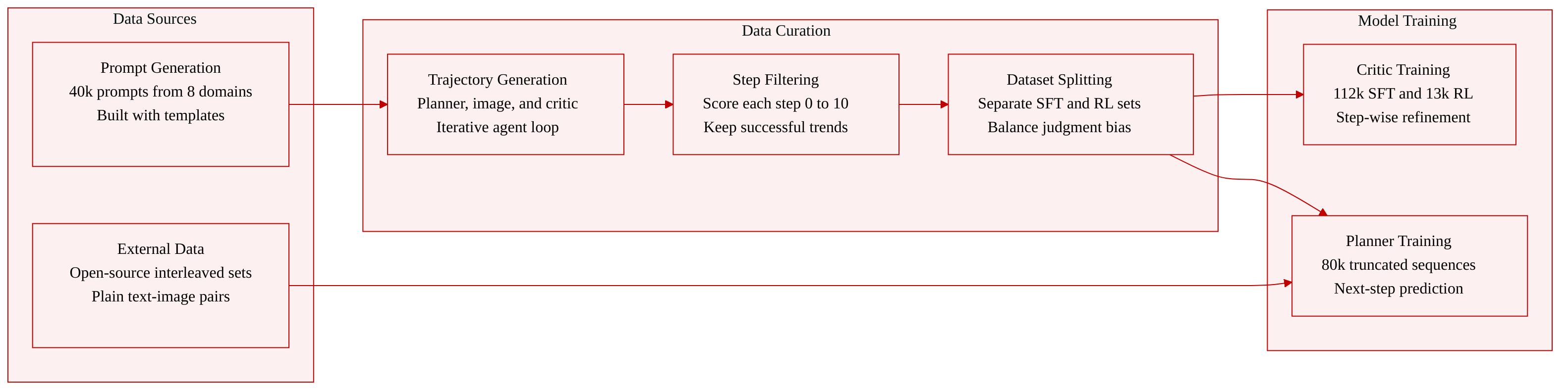
- Dataset Composition and Sources: The authors generate roughly 40,000 text prompts through a top-down pipeline that starts with 8 broad domains, expands to 75 fine-grained subcategories, and leverages Gemini 2.5 Pro to build domain-specific vocabulary banks and instructional templates. Multi-agent trajectory generation combines Gemini 2.5 Pro and Nano Banana Pro, with FLUX.2-klein-9B added to balance visual quality and prevent critic bias. The final corpus also integrates existing open-source interleaved datasets to supplement planner training.
- Subset Details and Filtering: Interleave-Critic-SFT-112k contains 112,000 samples filtered for successful refinement trends, stable high scores, and low iteration score variance. Interleave-Critic-RL-13k holds 13,000 samples selected for high score variance to capture dynamic refinement processes, maintaining a strict 2:1 ratio with the SFT subset. Interleave-Planner-SFT-80k comprises 80,000 samples that bypass critic filtering entirely, preserving the original unfiltered trajectories for planner training.
- Training Splits and Processing: The pipeline decomposes full trajectories into independent step-wise segments to enable stable single-iteration optimization instead of computationally prohibitive end-to-end reinforcement learning. Each refinement step is scored from 0 to 10 for semantic alignment and visual quality using Gemini 2.5 Pro adapted from VIEScore. The authors apply targeted resampling to balance the binary judgment distribution for the critic, ensuring unbiased training across iteration-wise predictions.
- Metadata and Structural Processing: Planner training pairs are constructed by randomly truncating interleaved text-image sequences, where the preceding context serves as input and the subsequent text plan acts as the target output. Metadata explicitly tracks original user instructions, rewritten refinement prompts, and paired original versus generated images to support step-wise evaluation. The filtering pipeline discards steps exhibiting negative refinement trends or persistent low quality, retaining only those that demonstrate successful iterative improvement.
Experiment
The evaluation employs a multi-agent InterleaveThinker framework to validate performance across interleaved generation and reasoning-based editing benchmarks using both in-domain and generalization image models. Results demonstrate that the approach significantly outperforms existing open-source methods by effectively mitigating visual over-reliance and step-wise error accumulation while preserving textual fidelity and image quality. Ablation studies confirm that the dedicated planner-critic architecture, fine-tuned training stages, and closed-loop refinement process are essential for robust performance, as single-model or unfiltered alternatives consistently degrade results. Although the framework encounters limitations with out-of-domain concepts unknown to the base generator, it remains a highly generalizable and model-agnostic solution for complex multimodal tasks.