Command Palette
Search for a command to run...
Rôle-Agent : Amorçage des Agents LLM via une Évolution à double rôle
Rôle-Agent : Amorçage des Agents LLM via une Évolution à double rôle
Xucong Wang Ziyu Ma Shidong Yang Tongwen Huang Pengkun Wang Yong Wang Xiangxiang Chu
Résumé
Bien que les agents LLM aient démontré des performances solides sur des tâches complexes, leur apprentissage est souvent limité par des retours d'interaction inefficaces et des environnements d'entraînement statiques, ce qui entrave une généralisation plus large. Pour remédier à ces limites, cet article présente Role-Agent, un cadre qui exploite un seul LLM pour fonctionner simultanément en tant qu'agent et en tant qu'environnement, permettant ainsi une co-évolution auto-amorcée. Role-Agent se compose de deux composants synergiques : World-In-Agent (WIA) et Agent-In-World (AIW). Dans WIA, le LLM agit en tant qu'agent et prédit les états futurs après chaque action ; l'alignement entre les états prédits et les états réels est ensuite utilisé comme récompense de processus, encourageant un raisonnement sensible à l'environnement. Dans AIW, le LLM analyse les modes de défaillance issus de trajectoires ayant échoué et récupère des tâches présentant des schémas de défaillance similaires, remodelant ainsi la distribution des données d'entraînement pour un entraînement ciblé. Les expériences sur plusieurs jeux de tests montrent que Role-Agent améliore de manière constante les performances, générant un gain moyen de plus de 4% par rapport à des méthodes de référence solides.
One-sentence Summary
Role-Agent bootstraps large language model agents by leveraging a single model as both agent and environment, utilizing World-In-Agent to generate environment-aware process rewards through state prediction alignment and Agent-In-World to reshape training data via failure pattern analysis, thereby overcoming static training constraints to achieve an average performance gain exceeding 4% over strong baselines across multiple benchmarks.
Key Contributions
- The paper introduces Role-Agent, a framework that deploys a single large language model to concurrently function as both the autonomous agent and the interactive environment, enabling bootstrapped co-evolution without human supervision.
- The method operates through two synergistic modules, World-In-Agent and Agent-In-World, which align predicted and actual states to generate process rewards while dynamically redistributing training data based on sequential failure analysis.
- Extensive evaluations across multiple text-based benchmarks demonstrate that this architecture consistently surpasses strong baselines, yielding an average performance improvement of over 4%.
Introduction
LLM agents drive progress in dynamic domains like coding and embodied navigation by enabling multi-turn reasoning and tool use, with Agentic Reinforcement Learning further enhancing problem-solving through interactive policy optimization. Existing self-evolving methods largely restrict adaptation to the agent side, leaving the environment static and unable to diagnose specific failure modes or generate targeted challenges, while building fully adaptive environments typically requires complex auxiliary models. The authors propose Role-Agent to overcome these barriers by leveraging a single LLM to simultaneously embody both the agent and the environment, enabling seamless co-evolution without human supervision. This dual-role architecture utilizes World-In-Agent to improve decision reliability through future state prediction and Agent-In-World to dynamically redistribute training data based on failure analysis, resulting in superior performance across multiple benchmarks.
Dataset

- Dataset Composition and Sources: The authors assemble a hybrid corpus combining a simulated e-commerce environment with multiple open-domain question answering and retrieval benchmarks. Sources include real-world product catalogs, crowd-sourced instructions, Google search logs, Wikipedia, news archives, and established QA datasets like SQuAD and TriviaQA.
- Subset Details: WebShop provides over 1.18 million real-world products paired with 12,087 natural language instructions, where agents interact via search and click actions. Natural Questions pairs Google queries with Wikipedia answers for single-hop retrieval. TriviaQA offers question-answer-evidence triples from Wikipedia and news using distant supervision. PopQA targets long-tail knowledge with over 14,000 questions about obscure entities. HotpotQA and 2WikiMultihopQA evaluate multi-hop reasoning, with the latter using rule-based templates to enforce predefined logical paths. MuSiQue is programmatically composed from single-hop datasets to ensure strict reasoning connectivity and includes unanswerable distractors. Bamboogle requires sequential multi-document retrieval and is specifically designed to be unsolvable by parametric memory alone.
- Usage and Processing: The authors leverage these datasets to train grounded language agents that balance internal knowledge with external search. The WebShop environment employs an automatically computable reward function based on product attributes to measure task completion and sim-to-real transfer potential. The training mixture emphasizes retrieval-augmented reasoning, requiring agents to decompose complex queries, filter irrelevant information, and synthesize facts across unstructured sources without relying on fixed mixture ratios or traditional cropping strategies.
- Metadata Construction and Analysis: The authors implement a structured metadata framework for systematic failure analysis. Each agent interaction is annotated with a dominant failure type, detailed step breakdowns, critical action points, core lessons, and targeted retrieval queries. This structured logging replaces manual cropping approaches and enables precise error tracking to guide iterative improvements in the agent's reasoning pipeline.
Method
The authors leverage a single large language model (LLM) to function as both the agent and the environment, enabling a bootstrapped co-evolutionary process through two synergistic components: World-In-Agent (WIA) and Agent-In-World (AIW). The overall framework operates in a closed loop where the LLM dynamically switches roles, allowing for both enhanced agent perception and adaptive environmental feedback. Refer to the framework diagram 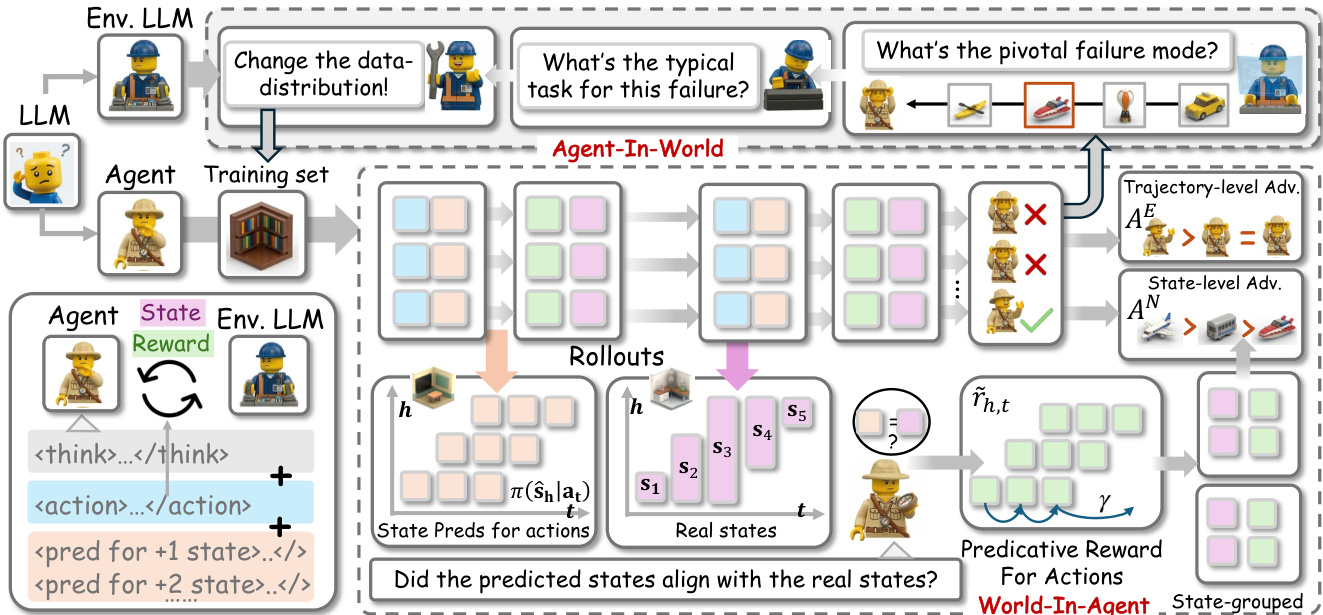 .
.
In the World-In-Agent (WIA) module, the LLM assumes the role of the agent and is tasked with predicting future states following each action. During each interaction step t, after generating an action at, the agent is prompted to predict the state at future time steps t+h for a horizon H, yielding a prediction set Epre,t. These predictions are compared to the actual ground-truth states st+h using the Longest Matching Subsequence (LMS) metric, resulting in a predictive reward matrix r~. This predictive reward is combined with the task reward to form a reliability-aware modulated reward Rt=Rtask(at)(1+Rpre(at)), which serves to amplify the credit for actions that are both effective and reliably predicted, while diminishing credit for actions that succeed by chance. The framework then computes state-level advantages by grouping state-action pairs that occur under identical states, which allows for more precise reward attribution independent of temporal order. These state-level advantages are integrated with trajectory-level advantages to compute the final advantage used in policy optimization.
As shown in the figure below, the Agent-In-World (AIW) component enables the environment to adapt based on the agent's performance.  The LLM, acting as the environment, analyzes the agent's failed trajectories to identify the underlying failure mode. This analysis involves identifying the primary failure type, the critical step where the failure became irreversible, and a generalizable core lesson. The identified failure mode, along with a retrieval query, is stored in a database. When the agent encounters a new task, the environment LLM retrieves past tasks with similar failure patterns, thereby reshaping the training data distribution to include targeted practice on the agent's specific weaknesses. This process is illustrated in the figure below, which shows a failed trajectory, the analysis of its failure mode, and the subsequent retrieval of analogous tasks for retraining.
The LLM, acting as the environment, analyzes the agent's failed trajectories to identify the underlying failure mode. This analysis involves identifying the primary failure type, the critical step where the failure became irreversible, and a generalizable core lesson. The identified failure mode, along with a retrieval query, is stored in a database. When the agent encounters a new task, the environment LLM retrieves past tasks with similar failure patterns, thereby reshaping the training data distribution to include targeted practice on the agent's specific weaknesses. This process is illustrated in the figure below, which shows a failed trajectory, the analysis of its failure mode, and the subsequent retrieval of analogous tasks for retraining. 
Experiment
The evaluation spans household navigation, simulated e-commerce, and search-augmented question answering tasks, benchmarking the proposed method against closed-source models, prompt engineering techniques, and reinforcement learning baselines. Experimental results demonstrate consistent superiority across all domains, with performance gains becoming particularly pronounced in complex multi-step reasoning and multi-hop retrieval scenarios. Ablation studies and training dynamics confirm that targeted environment feedback and predictive rewards are crucial for capturing systematic failure modes, leading to faster convergence, reduced train-inference mismatch, and enhanced generalization. Ultimately, the agent-environment co-evolution framework proves highly effective at building robust reasoning capabilities while maintaining minimal computational overhead.
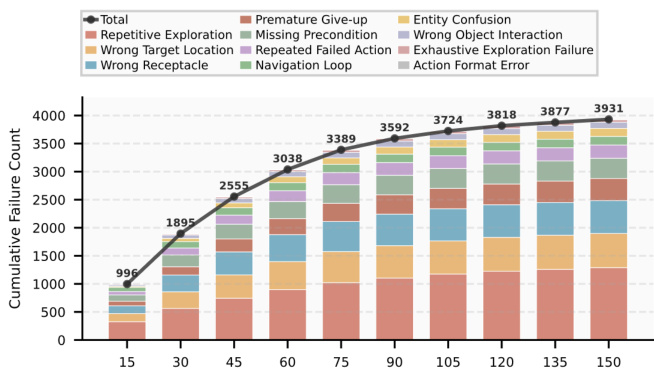
The authors analyze the accumulation of failure modes during training, showing that the total number of recorded failures increases rapidly in the early stages and then stabilizes. The chart illustrates that repetitive exploration and wrong target location are the most frequent failure types, with other categories contributing to a diverse set of errors, indicating that the environment provides targeted tasks to address various weaknesses. Failure modes accumulate rapidly at first and then stabilize over training steps. Repetitive exploration and wrong target location are the most common failure types. The diversity of failure modes suggests the environment provides targeted tasks to address various weaknesses.
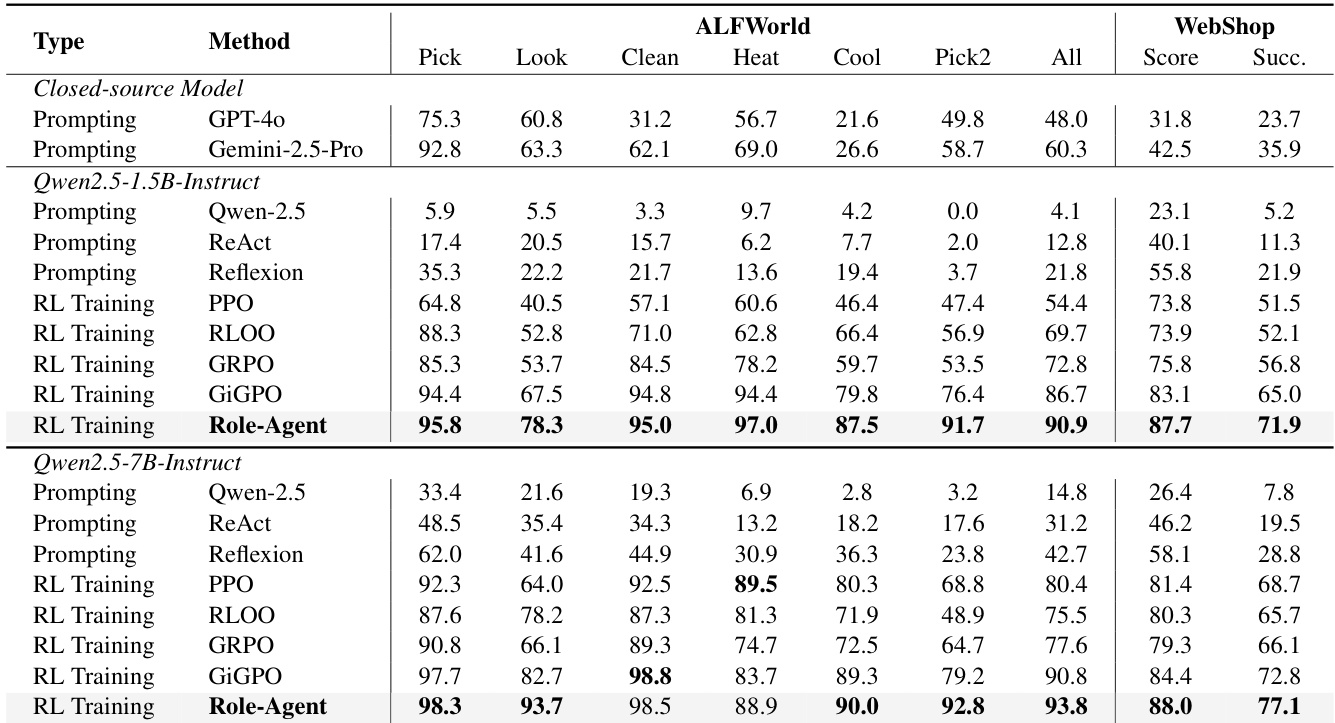
The authors evaluate their method, Role-Agent, across multiple benchmarks including ALFWorld, WebShop, and search-augmented QA tasks, comparing it against various baselines such as closed-source models, prompt engineering methods, and reinforcement learning approaches. Results show that Role-Agent consistently outperforms existing methods, particularly in complex multi-step tasks, and demonstrates robustness and generalization capabilities across different model sizes. The method achieves improved performance through co-evolution between the agent and environment, with ablation studies confirming the importance of key components like environment feedback and predictive reasoning. Role-Agent consistently outperforms various baselines across different benchmarks and model sizes, especially in complex multi-step tasks. The co-evolution of the agent and environment enhances generalization, with significant gains observed in tasks requiring stable memory and multi-step planning. Key components such as environment feedback and predictive reasoning are critical for performance, and the method maintains efficiency with minimal computational overhead.
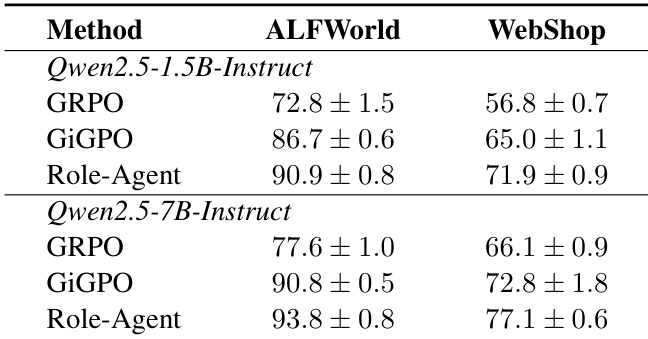
The authors compare their proposed method, Role-Agent, against several baselines on ALFWorld and WebShop tasks using different model sizes. Results show that Role-Agent consistently outperforms other methods across both benchmarks and model scales, achieving higher success rates and demonstrating improved generalization capabilities. The performance gains are particularly notable on complex, multi-step tasks that require stable memory and planning. Role-Agent achieves superior performance compared to all baseline methods on both ALFWorld and WebShop tasks. The method shows consistent improvements across different model sizes, with larger models yielding higher success rates. Role-Agent demonstrates significant gains on complex tasks requiring multi-step planning and stable memory, indicating enhanced generalization capabilities.
The authors compare Role-Agent against various baselines across ALFWorld and WebShop tasks, using Qwen2.5 models as backbones. Results show that Role-Agent consistently outperforms other methods, particularly on complex multi-step tasks, and achieves higher success rates than both prompt-based and reinforcement learning approaches. The method demonstrates strong generalization and stability, with performance improvements across different model sizes and task types. Role-Agent achieves the highest success rates on both ALFWorld and WebShop compared to all baselines. Role-Agent outperforms prompt-based methods and RL training approaches, showing consistent gains across different backbone models. The method shows significant improvements on complex tasks requiring multi-step planning and memory, indicating enhanced generalization capabilities.
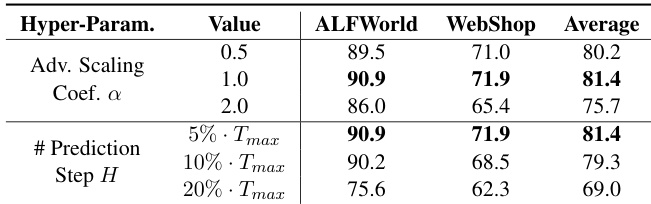
The authors conduct experiments to evaluate the performance of Role-Agent across multiple benchmarks, including ALFWorld, WebShop, and search-augmented QA tasks, comparing it against various baselines. Results show that Role-Agent consistently outperforms other methods, particularly in multi-step and complex tasks, due to its co-evolutionary agent-environment framework. Sensitivity analysis reveals that hyperparameter settings, especially the advantage scaling coefficient and prediction step length, significantly influence performance. The method maintains efficiency with minimal additional computational overhead. Role-Agent achieves consistent performance improvements over various baselines across different tasks and model sizes. Hyperparameter tuning shows that a balanced advantage scaling coefficient and optimal prediction step length are crucial for maximizing performance. The method introduces minimal computational overhead while significantly enhancing training stability and convergence speed.
The authors evaluate their Role-Agent method across multiple benchmarks against diverse baselines using varying model sizes to assess overall performance and generalization. Separate analyses validate the training dynamics by tracking failure mode accumulation, while ablation and sensitivity studies confirm the critical importance of environment feedback, predictive reasoning, and optimal hyperparameter settings. Qualitatively, the co-evolutionary framework consistently outperforms existing approaches, particularly in complex multi-step tasks requiring stable memory and planning. These experiments collectively demonstrate that targeted environmental design effectively addresses diverse behavioral weaknesses while maintaining computational efficiency and robust convergence.