Command Palette
Search for a command to run...
SearchSwarm : Vers l'Intelligence de Délégation dans les LLMs agents pour la Recherche Approfondie à Long Terme
SearchSwarm : Vers l'Intelligence de Délégation dans les LLMs agents pour la Recherche Approfondie à Long Terme
Pu Ning Quan Chen Kun Tao Xinyu Tang Tianshu Wang Qianggang Cao Xinyu Kong Zujie Wen Zhiqiang Zhang Jun Zhou
Résumé
Les grands modèles de langage sont de plus en plus appelés à prendre en charge des tâches réelles complexes et à long terme dont les besoins contextuels peuvent croître sans borne, alors que les fenêtres contextuelles des modèles demeurent intrinsèquement finies. Des travaux récents explorent un paradigme dans lequel un agent principal décompose les tâches et transmet des sous-tâches à des sous-agents, qui les exécutent et ne retournent que des résultats résumés, préservant ainsi le budget contextuel de l'agent principal. Toutefois, une exécution efficace de ce processus requiert une intelligence de délégation : la capacité de décomposer des tâches complexes, de déterminer quand et quoi déléguer, et d'intégrer les résultats retournés au flux de travail en cours. Les données d'entraînement nécessaires à cette capacité sont rares dans les textes naturels, et à notre connaissance, les méthodes permettant de synthétiser de telles données et d'entraîner des modèles afin qu'ils acquièrent cette capacité restent largement inexplorées au sein de la communauté open-source. Afin de combler cette lacune, nous présentons une exploration préliminaire axée sur la recherche approfondie, une tâche représentative d'agent à long terme. Plus précisément, nous concevons un harness qui guide le modèle vers une décomposition et une délégation de tâches de haute qualité, tout en contraignant les sous-agents à restituer correctement les résultats afin de soutenir le flux de travail de l'agent principal. Les trajectoires guidées par le harness encodent naturellement des décisions de délégation correctes, que nous utilisons comme données pour le fine-tuning supervisé afin d'internaliser l'intelligence de délégation dans les poids du modèle. Notre modèle final, SearchSwarm-30B-A3B, obtient un score de 68,1 sur BrowseComp et de 73,3 sur BrowseComp-ZH, constituant les meilleurs résultats parmi l'ensemble des modèles de taille comparable. Nous mettrons à disposition notre harness, les poids du modèle ainsi que les données d'entraînement afin de faciliter les recherches futures.
One-sentence Summary
SearchSwarm-30B-A3B is a model trained via supervised fine-tuning on harness-generated trajectories to internalize delegation intelligence for long-horizon deep research, achieving 68.1 on BrowseComp and 73.3 on BrowseComp-ZH, the best results among models of comparable scale.
Key Contributions
- A specialized execution harness structures multi-agent workflows by guiding task decomposition, subagent briefing, and citation-grounded result integration while constraining subagents to return only summarized outputs. This architecture shields the main agent from raw tool responses, effectively preserving finite context capacity for iterative exploration.
- Harness-generated trajectories are extracted and formatted into supervised fine-tuning data to internalize delegation intelligence directly into model weights. This data synthesis pipeline addresses the scarcity of naturally occurring delegation examples in open-source training corpora.
- The resulting SearchSwarm-30B-A3B model achieves state-of-the-art performance among comparable-scale models on BrowseComp and BrowseComp-ZH. Evaluation results further demonstrate that the trained delegation patterns generalize effectively to single-agent settings and open-ended research tasks.
Introduction
Large language models are increasingly deployed as autonomous agents for complex, long-horizon tasks like deep research, where information demands quickly outpace finite context windows. This bottleneck makes efficient context management essential for maintaining model performance and scalability. While active delegation architectures offer a promising alternative to passive summarization techniques, the open-source community lacks a complete training recipe, and naturally occurring text rarely contains the explicit multi-agent coordination data required to teach delegation intelligence. To bridge this gap, the authors leverage a custom inference harness to guide a main agent through structured task decomposition and detailed subagent briefing, then convert these successful trajectories into supervised fine-tuning data. This process internalizes delegation intelligence directly into model weights, producing SearchSwarm-30B-A3B, which achieves state-of-the-art results among similarly sized models while fully open-sourcing the harness, training data, and weights for future research.
Dataset

- Dataset Composition and Sources: The authors construct the training corpus by executing deep research tasks on queries sourced from the open-source RedSearcher and OpenSeeker datasets. They record complete execution trajectories that capture chain-of-thought reasoning, tool invocations, and environment feedback.
- Subset Details and Filtering Rules: Data collection follows two configurations. The first runs a single model as both main and subagent, preserving paths from both roles. The second pairs a stronger main agent with a weaker subagent, retaining only the main agent trajectories to encourage tighter task decomposition and verification. Filtering keeps main agent paths only when they yield correct final answers and retains subagent paths exclusively when paired with a correct main trajectory. The authors also downsample overly short subagent clips and discard samples featuring repeated tool calls, hallucinated citations, or tool misuse like web scraping through Python interpreters.
- Training Usage and Processing: Trajectories from both configurations are mixed into a single training set. The authors fine-tune the base model using next-token prediction with strict environment masking. The loss function is computed solely over the model's generated outputs, while all environment returns are masked to prevent the model from memorizing external feedback.
- Context Management and Cropping Strategy: The main agent context window is capped at 128K tokens and the subagent window at 64K tokens. When a trajectory nears these limits, the system prompts the model to generate a final answer immediately. Rather than dropping these sequences, the authors preserve them so the model learns to perform well under forced-answer conditions during inference. Additionally, subagent dispatches are carefully crafted to include only established context, ensuring they focus on specific sub-questions without repeating settled ground.
Method
The SearchSwarm framework operates under a main-distributes, sub-executes paradigm, where a central main agent orchestrates complex research tasks by delegating subtasks to independent subagents. This architecture is designed to manage context efficiently and enable high-quality reasoning through structured delegation. The main agent, equipped with a comprehensive tool set including search, visit, Python interpreter, and Google Scholar, interacts with the environment through a sequence of thoughts, actions, and observations, following the ReAct framework. At each step, the agent reasons about the current state, selects an action, and processes the resulting observation. When a subtask is identified, the main agent invokes the call_sub_agent tool, which dispatches a brief to a subagent. The brief contains a subtask description along with contextual information such as the task's relevance, prior findings, and unresolved questions, ensuring the subagent operates with sufficient background to contribute effectively.
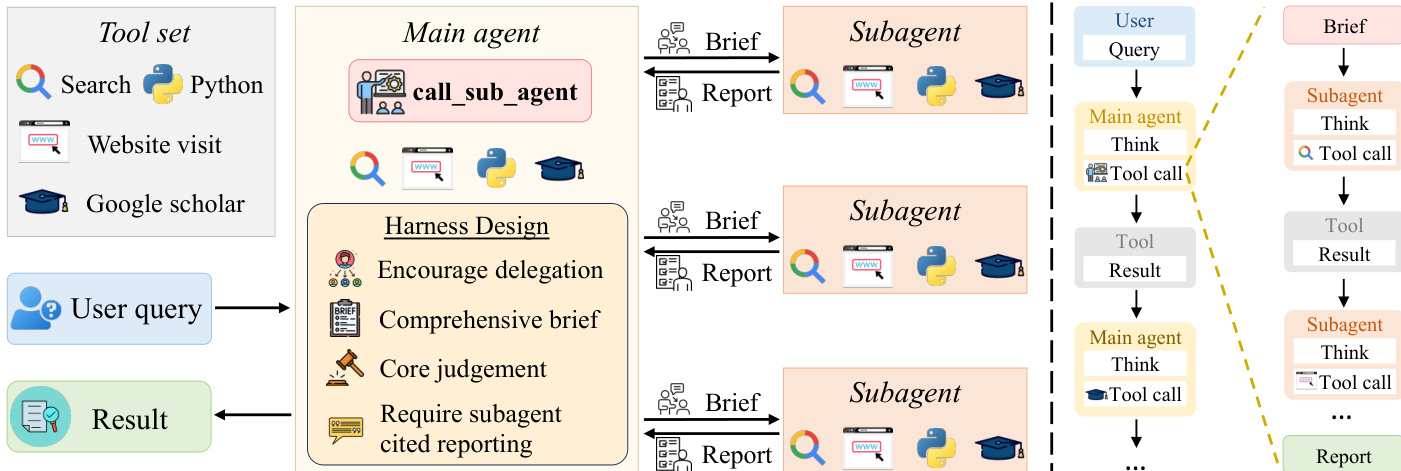
As shown in the figure above, the main agent and subagents operate in separate contexts, with the subagent receiving only the brief and returning a condensed report. This separation ensures that the main agent’s context remains uncluttered, preserving its capacity for high-level coordination and judgment. The subagent, equipped with the same set of tools as the main agent, conducts its own multi-turn interactions to gather evidence and produce a report. The report is required to include inline citations for every significant claim, allowing the main agent to verify the reliability of the findings without access to the subagent’s intermediate steps. The main agent then integrates the report into its reasoning process, continuing the iterative cycle of thought and action until a final answer is generated. This approach enables the system to handle long-horizon tasks by effectively compressing subtask execution into a single report, thereby managing context growth while maintaining traceability and coherence.
Experiment
The experiments evaluate a two-agent delegation framework across multiple long-horizon and open-ended research benchmarks, comparing it against leading closed-source, open-source, and lightweight models. Results demonstrate that the proposed harness and training data substantially enhance delegation intelligence, enabling a compact model to match or exceed much larger frontier systems. Ablation studies and cross-architecture tests confirm that the framework effectively elicits structured information gathering and synthesis while proving the high quality of the underlying training data. Furthermore, the acquired capabilities generalize robustly to single-agent configurations and open-ended research tasks, highlighting the method's versatility and the model's internalized problem-decomposition skills.
The authors present a model that achieves state-of-the-art performance among lightweight models on long-horizon research tasks, demonstrating strong competitiveness against larger models. The model's delegation mechanism enables effective context management, leading to improved results across multiple benchmarks, and the training data and harness design contribute to generalization beyond the delegation setting. SearchSwarm outperforms other models of similar scale and achieves results competitive with larger models across multiple benchmarks. The model's delegation mechanism enables efficient context management, with the main agent primarily orchestrating subagent calls for information gathering. The training data and harness design lead to generalization benefits, improving performance even in settings without delegation tools.
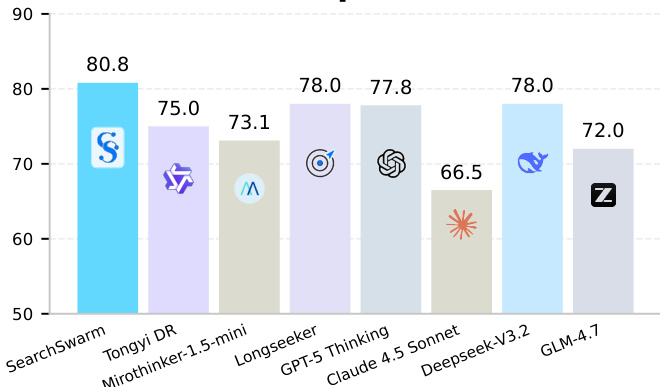
The authors compare their model, SearchSwarm, against a range of closed-source, open-source, and lightweight open-source models across multiple benchmarks. Results show that SearchSwarm achieves state-of-the-art performance among models of its scale and demonstrates strong competitiveness against larger models, particularly on long-horizon research tasks. The model also generalizes well to open-ended deep research settings, outperforming its base model and achieving high results without explicit training on such tasks. SearchSwarm achieves top performance among lightweight models and surpasses several larger models on key benchmarks. The model demonstrates strong generalization to open-ended research tasks, improving significantly over its base model. The main agent relies heavily on delegation, using the subagent tool for information gathering while handling verification and computation directly.
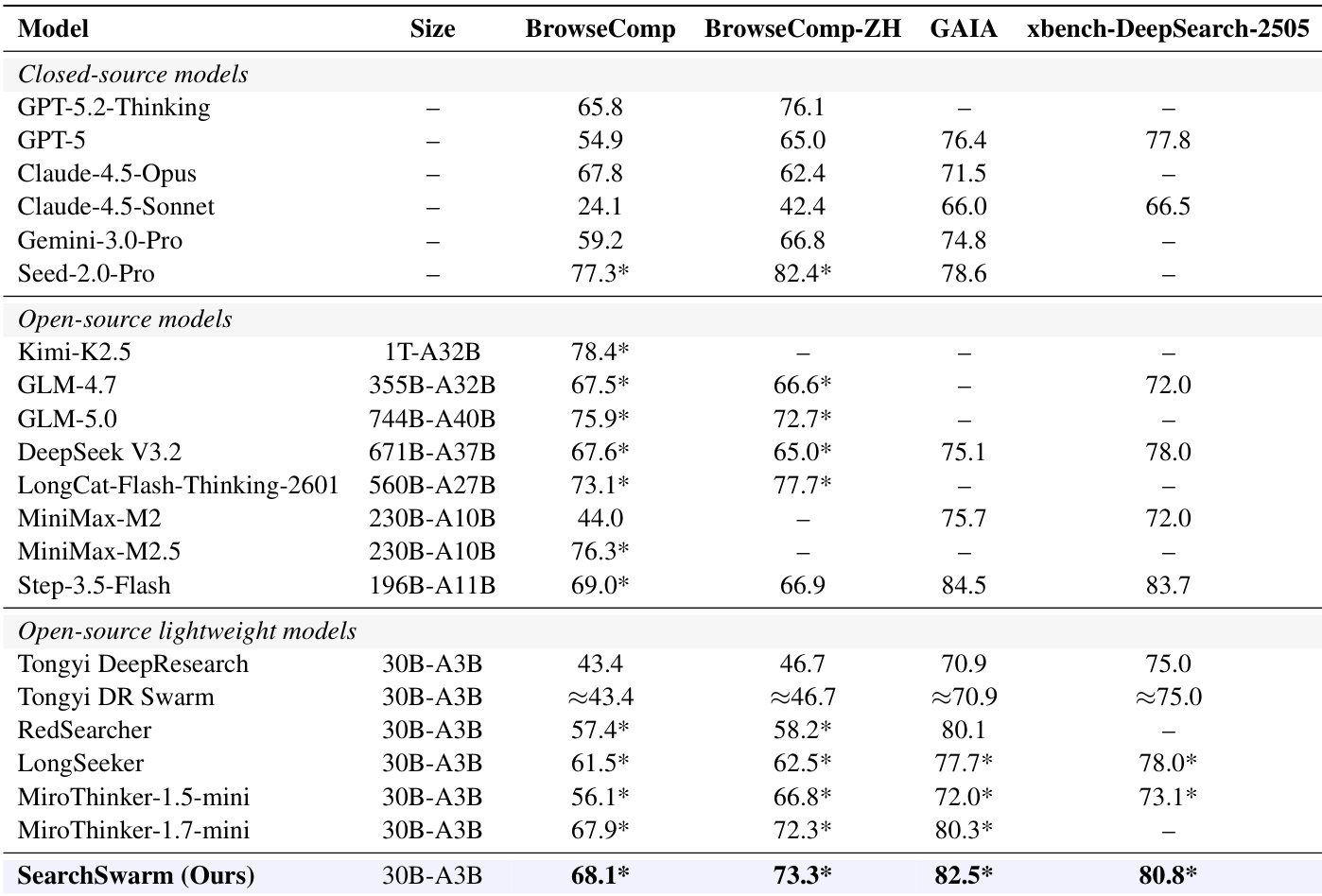
The authors evaluate their model, SearchSwarm, on open-ended deep research benchmarks and compare its performance against both closed-source and open-source systems. Results show that SearchSwarm achieves competitive performance, particularly excelling on ResearchQA and ScholarQA-v2, and ranks second among open-source models in average performance. The model outperforms its base model across all benchmarks, demonstrating strong generalization to long-form synthesis tasks. SearchSwarm achieves the second-highest average performance among open-source models on open-ended deep research benchmarks. SearchSwarm significantly outperforms its base model across all evaluated benchmarks, showing strong generalization to long-form synthesis tasks. SearchSwarm achieves top performance on ResearchQA and ScholarQA-v2, outperforming several strong open-source models.
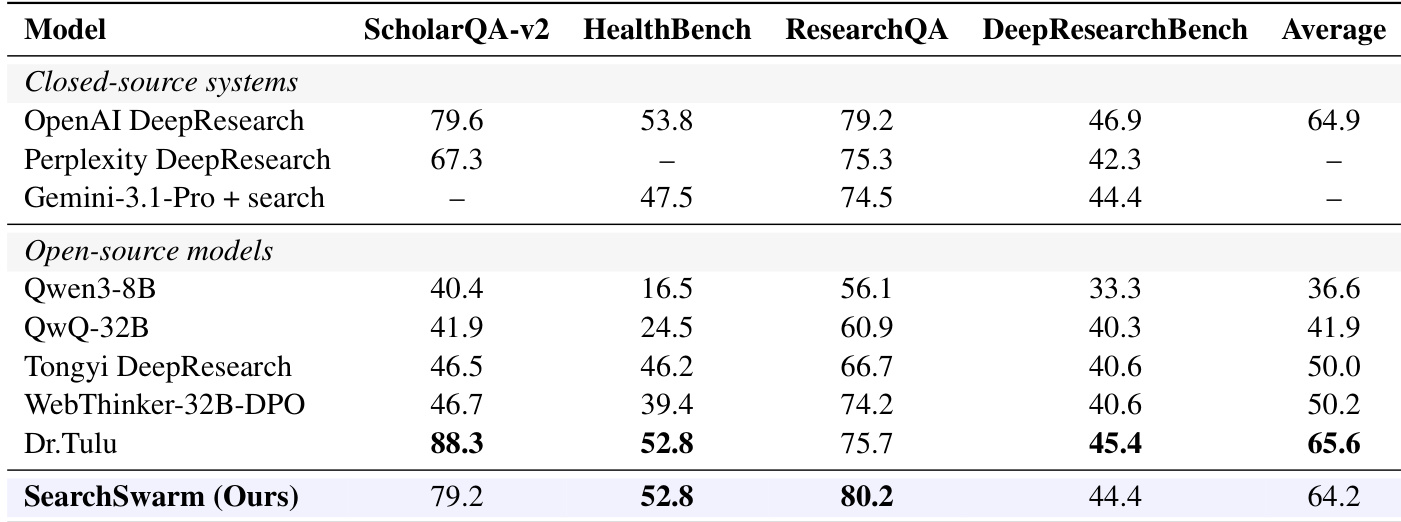
The authors evaluate their model, SearchSwarm, on multiple benchmarks and compare it to various open-source and closed-source models. Results show that SearchSwarm achieves top performance among models at the 30B-A3B scale and competes with much larger models, indicating that effective delegation intelligence enables strong performance in long-horizon research tasks. The model's training data and harness design are effective in promoting intelligent delegation and generalizing capabilities to both single-agent and open-ended research settings. SearchSwarm achieves state-of-the-art performance among 30B-A3B scale models across all benchmarks. SearchSwarm competes with significantly larger models, demonstrating that delegation intelligence enables strong performance despite model size. The training data and harness design promote effective delegation and generalize to single-agent and open-ended research settings.
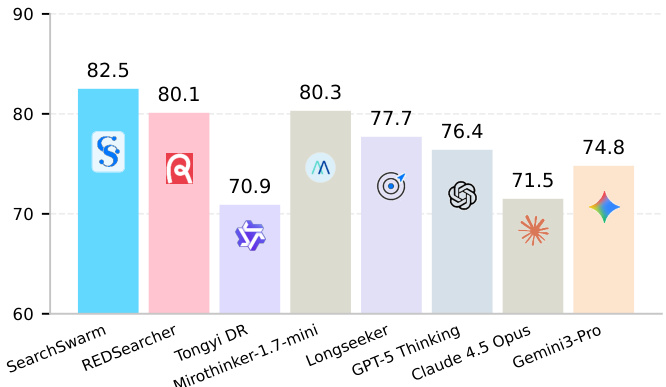
The authors evaluate SearchSwarm across multiple long-horizon and open-ended research benchmarks, comparing it against closed-source, open-source, and similarly sized models to validate its competitive efficiency and generalization capabilities. Results indicate that the model achieves state-of-the-art performance within its parameter scale while remaining highly competitive with significantly larger systems, demonstrating that effective delegation intelligence can offset size limitations. The experiments further validate that the delegation mechanism successfully manages context by orchestrating subagent information retrieval, which consistently drives improvements over the base architecture. Additionally, the tailored training data and harness design prove effective at promoting intelligent delegation, enabling robust generalization to both single-agent and open-ended research settings without explicit task-specific training.