Command Palette
Search for a command to run...
Distillation affinée par la trajectoire
Distillation affinée par la trajectoire
Li Jiang Haoran Xu Yichuan Ding Amy Zhang
Résumé
La distillation on-policy (OPD) est devenue un outil central de post-entraînement des grands modèles de langage (LLM), fournissant une supervision dense au niveau de chaque token, délivrée par le teacher le long des propres rollouts de l’élève (student). Dans cet article, nous identifions une cause structurelle commune sous-jacente à l’OPD, que nous appelons prefix failure. Dans le cadre du prefix failure, la supervision dense au niveau des tokens induit un mélange bimodal des enseignants et des gradients fragmentés, que la truncation ou la rééquitation (reweighting) des pertes au niveau des tokens ne parviennent pas à corriger. Cette observation nous conduit à dépasser les interventions centrées sur la perte au niveau des tokens pour adopter des corrections de sortie au niveau de la trajectoire. Nous proposons ainsi la Distillation Raffinée au Niveau des Trajectoires (Trajectory-Refined Distillation, TRD), une méthode de correction au niveau des trajectoires qui révise le rollout de l’élève sous la guidance du teacher, tout en restant dans le support on-policy. En corrigeant les prefixes problématiques avant la distillation, la TRD atténue le prefix failure à sa source. De plus, la TRD améliore l’exploration en exposant l’élève à des dérivations valides alternatives sous la guidance du teacher, même lorsque les rollouts initiaux sont déjà corrects. La TRD peut également être appliquée à la distillation auto-on-policy (OPSD), une variante partageant les paramètres, qui utilise le modèle élève conditionné par des informations privilégiées en tant que teacher.
One-sentence Summary
This work proposes Trajectory-Refined Distillation (TRD), a trajectory-level correction method for large language models that mitigates prefix failure by revising student rollouts under teacher guidance to address fragmented gradients and improve exploration beyond token-level interventions, applicable to both on-policy distillation and on-policy self-distillation settings.
Key Contributions
- The work identifies and formalizes prefix failure as a structural cause in on-policy distillation where dense supervision creates bimodal teacher mixtures that token-level loss interventions fail to address. This diagnostic insight establishes the need for trajectory-level corrections over per-token loss reweighting.
- The paper introduces Trajectory-Refined Distillation (TRD), a trajectory-level correction method that revises student rollouts under teacher guidance while retaining on-policy support. TRD mitigates the identified failure mode at its source and enhances exploration by exposing the student to alternative valid derivations during the refinement process.
- Experiments on five competition-math benchmarks and code generation tasks demonstrate that TRD achieves the best average performance against baselines using Qwen3 models. The method shows pronounced gains on the AMOBench dataset, delivering approximately 50% relative Pass@16 improvements for Qwen3-8B under an on-policy self-distillation setup.
Introduction
On-policy distillation serves as a critical post-training mechanism for large language models by delivering dense per-token teacher supervision during student rollouts. Despite its widespread adoption, vanilla approaches often encounter prefix failure where incorrect reasoning paths create fragmented gradients that token-level loss reweighting cannot resolve. The authors propose Trajectory-Refined Distillation (TRD) to address this structural limitation by shifting from per-token adjustments to trajectory-level output corrections. TRD revises the student rollout under teacher guidance to mitigate prefix failure at its source while enhancing exploration across various math and code benchmarks in both standard and self-distillation settings.
Method
Standard on-policy distillation (OPD) and on-policy self-distillation (OPSD) suffer from a structural limitation known as prefix failure. When a student model generates an incorrect reasoning path, the teacher distribution becomes a mixture of modes: one that continues the error for consistency and another that pivots toward the correct solution. This creates a noisy supervisory signal. As shown in the figure below, the choice of KL divergence interacts with this mixture asymmetrically. Forward KL, being mode-covering, dominates the correction region which is out-of-distribution for the student, potentially causing instability. In contrast, Reverse KL, being mode-seeking, focuses on the wrong continuation region where the student already places high probability mass, effectively ignoring the correction signal. Furthermore, standard distillation generates a fragmented gradient because the teacher conditions on the frozen failed prefix at every step rather than the unfolding correction path.
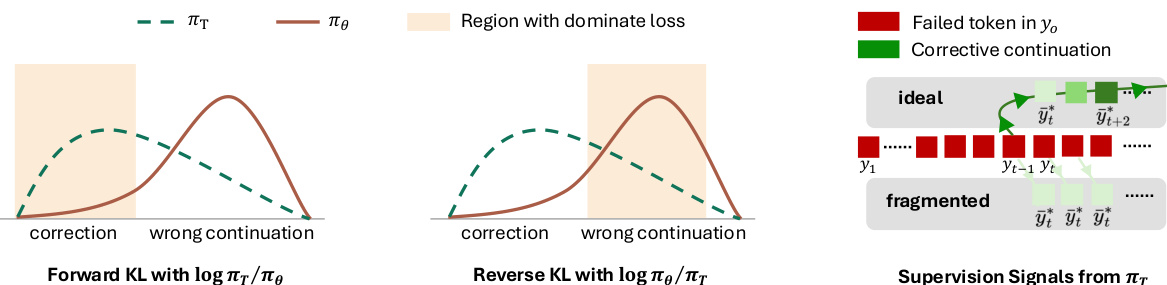
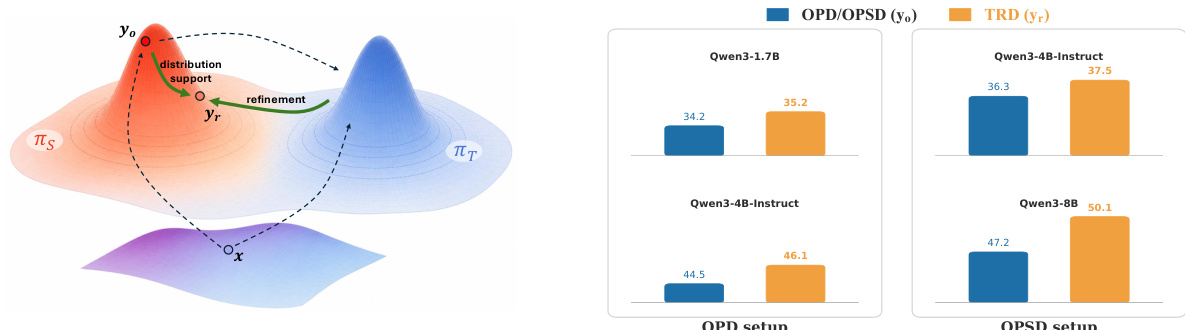
To overcome these issues, the authors introduce Trajectory-Refined Distillation (TRD). This method operates at the trajectory level to optimize the expected verifier pass rate while respecting the on-policy support constraint. Refer to the framework diagram to visualize the refinement process where the teacher constructs a corrected trajectory yr starting from the student's initial rollout yo. The training procedure involves three main steps. First, the student samples a raw rollout yo∼πθ(⋅∣x). Second, the teacher generates a refined trajectory yr∼πT(⋅∣x,yo). In the OPSD setting, the teacher shares the student's parameters but is conditioned on privileged information such as the reference solution y∗. Third, the student is updated to match the distribution of the refined trajectory yr.
The distillation objective uses forward KL divergence with full vocabulary matching to provide stable mode-covering supervision. The loss function is defined as:
L(θ)=Ex∼Dyo∼πθ(⋅∣x)yr∼πT(⋅∣x,yo)∣yr∣1t=1∑∣yr∣D(sg[πT(⋅∣x,yo,yr,<t)]πθ(⋅∣x,yr,<t))By supervising along the refined trajectory yr instead of the raw rollout yo, TRD recovers the ideal gradient structure. The supervision contexts grow along the correction path itself rather than being anchored to the failed prefix. This allows the student to learn the multi-step unfolding of the correction rather than receiving fragmented signals. Additionally, this approach boosts exploration by surfacing alternative valid derivations suggested by the teacher that the student might not sample independently.
Experiment
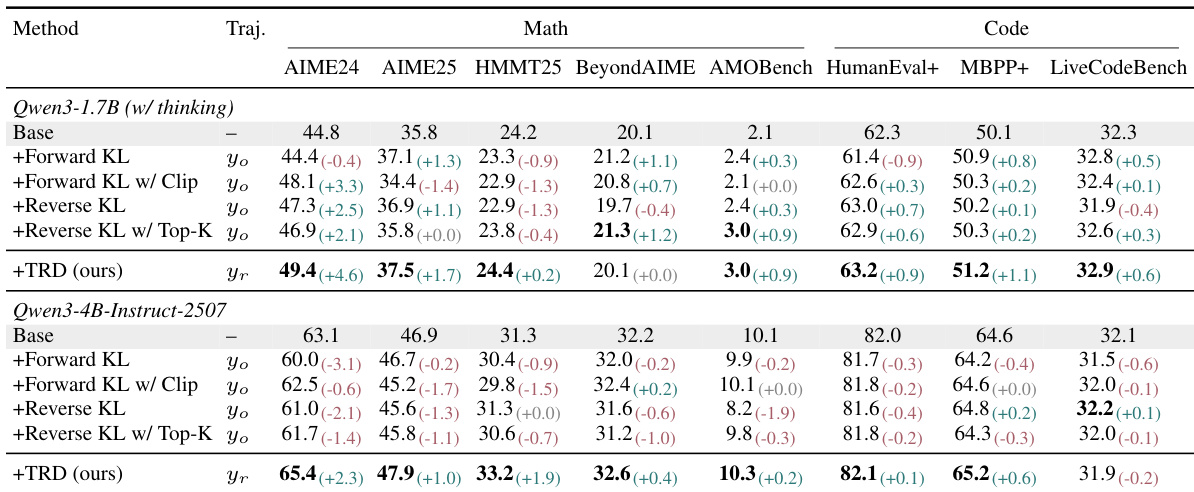
The study evaluates the proposed TRD method against standard dense-KL baselines across math and code benchmarks using Qwen3 models in both OPD and OPSD settings. Experiments validate the prefix failure mechanism by demonstrating that standard KL supervision provides diminishing signals on incorrect rollouts, whereas TRD successfully refines trajectories to correct dead-end prefixes without destabilizing existing capabilities. Qualitative analysis reveals that TRD produces significantly shorter and more accurate reasoning paths, consistently outperforming baselines by expanding the reachable solution space on hard problems while maintaining training stability.
The authors evaluate TRD against four dense-KL baselines using Qwen3 models on math and code benchmarks. Results show that TRD consistently outperforms the base model and other methods across most metrics, whereas standard baselines often degrade performance relative to the base. TRD achieves the top performance on the majority of math and code benchmarks for both model scales. Baseline methods frequently show negative improvements compared to the base model, particularly on math tasks. TRD successfully improves performance on HumanEval+ and MBPP+ code benchmarks where other methods struggle.
The the the table details the hyperparameter configurations for the proposed TRD method and four dense-KL baselines evaluated in the study. The baselines are set up to train on raw student rollouts with vanilla prompts and shorter sequence limits, whereas the proposed method uses refined trajectories with a refinement prompt and longer context windows. This setup supports the experimental findings that the proposed method outperforms the baselines by avoiding prefix failure and providing better supervision signals. Baselines utilize raw on-policy rollouts for training while the proposed method employs refined trajectories. The proposed method is configured with a refinement teacher prompt unlike the vanilla prompts used by baselines. The proposed method supports longer maximum training sequence lengths compared to the baseline configurations.

The the the table compares the performance of OPD and OPSD training settings against a Teacher model across five math benchmarks using Avg@16 and Pass@16 metrics. Results indicate that while the Teacher model generally maintains the highest performance, the OPSD setting tends to achieve higher Pass@16 scores on most benchmarks, whereas OPD shows stronger Avg@16 performance on specific datasets. OPSD achieves higher Pass@16 scores than OPD on the majority of benchmarks. OPD records better Avg@16 results than OPSD on AIME24 and HMMT25. The Teacher model consistently outperforms both student settings across all reported metrics.

The authors evaluate the TRD method under the OPSD setting by comparing the full refined training corpus against ablated subsets filtered by trajectory outcomes. Results show that the complete dataset consistently outperforms restricted subsets and the base model across multiple math benchmarks. This indicates that leveraging the full breadth of refined trajectories is essential for maximizing performance, particularly in Pass@16 metrics. The full TRD method achieves the highest performance across all benchmarks, outperforming both the base model and filtered variants. Restricting the training corpus to specific trajectory outcomes leads to significant performance degradation compared to using the full refined dataset. The experiments confirm that diverse training signals from the complete corpus are more effective than privileged subsets for improving model capabilities.

The authors evaluate TRD against four dense-KL baselines in an OPSD setting using Qwen3 models. Results indicate that TRD consistently matches or exceeds the base model's performance across all math benchmarks, whereas standard KL baselines often degrade performance or show mixed results. Specifically, TRD delivers significant gains on harder benchmarks for the larger model without sacrificing performance on saturated tasks. TRD preserves the base model's performance on saturated benchmarks while achieving consistent improvements on more difficult tasks across both model scales. Standard dense-KL baselines frequently regress below the base model performance, particularly on the smaller student, whereas TRD preserves base capabilities. The larger model with TRD shows notable gains on difficult benchmarks compared to both the base and other refinement methods.
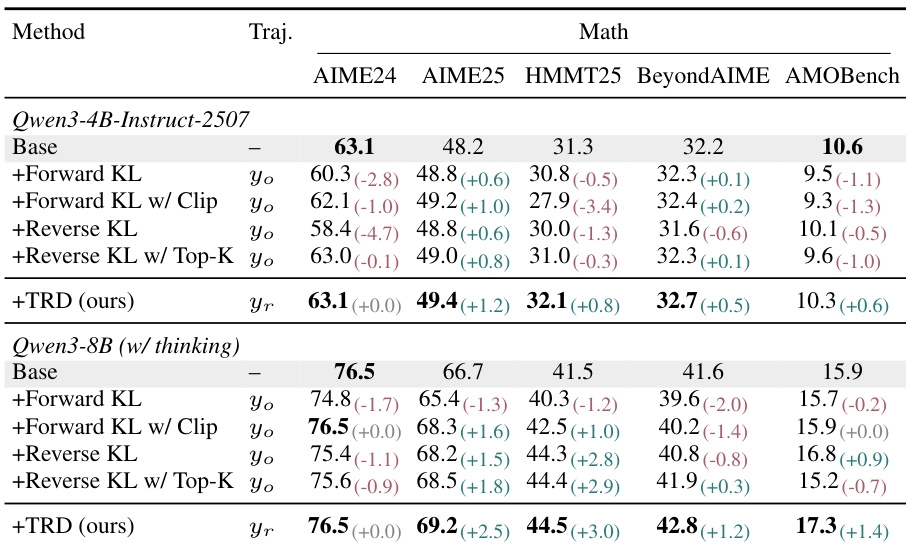
The authors evaluate TRD against dense-KL baselines and a Teacher model using Qwen3 models on math and code benchmarks within an OPSD setting, employing refined trajectories and longer context windows. Results demonstrate that TRD consistently outperforms the base model and other methods, whereas baseline approaches often degrade performance, particularly on math tasks. Additionally, ablation studies validate that the full refined training corpus is essential for maximizing capabilities, allowing TRD to improve on difficult benchmarks without sacrificing performance on saturated tasks.