Command Palette
Search for a command to run...
Votre matrice d'UnEmbedding est secrètement une lentille de fonctionnalités pour les embeddings de texte
Votre matrice d'UnEmbedding est secrètement une lentille de fonctionnalités pour les embeddings de texte
Songhao Wu Zhongxin Chen Yuxuan Liu Heng Cui Cong Li Rui Yan
Résumé
Les grands modèles de langage démontrent des capacités zero-shot impressionnantes sur un large éventail de tâches en aval. Cependant, ils éprouvent des difficultés à fonctionner en tant que modèles d'incorporation prêts à l'emploi, ce qui se traduit par des performances sous-optimales sur des benchmarks d'incorporation de texte à grande échelle. Dans cet article, nous identifions une cause potentielle sous-jacente à cette lacune. Notre motivation découle d'une observation inattendue : les incorporations de texte ont tendance à s'aligner sur des tokens fréquents mais peu informatifs lorsqu'elles sont projetées dans l'espace du vocabulaire. Nous avançons que cette surexpression de tokens à haute fréquence altère la capacité du modèle à capturer des nuances sémantiques. Pour remédier à cela, nous présentons EmbedFilter, une transformation linéaire simple conçue pour affiner directement les incorporations de texte dérivées des LLM. Plus précisément, nous mettons en évidence que la matrice d'unincorporation au sein des LLM encode un espace latent qui projette activement ces tokens fréquents dans l'espace d'incorporation. En filtrant ce sous-espace, EmbedFilter atténue l'influence des tokens à haute fréquence, améliorant ainsi les représentations sémantiques. Comme sous-produit remarquable, cette approche permet une réduction de dimensionnalité inhérente, diminuant l'espace de stockage des index et accélérant la récupération, tout en préservant intégralement la qualité des incorporations affinées. Nos expériences menées sur plusieurs backbones de LLM démontrent que les LLM équipés d'EmbedFilter obtiennent des performances zero-shot en aval supérieures, même avec des dimensions d'incorporation considérablement réduites. Nous espérons que nos résultats apportent un éclairage plus approfondi sur les mécanismes des représentations basées sur les LLM et inspirent des conceptions plus rigoureuses afin d'améliorer l'entraînement des incorporations de texte. Notre code est disponible à l'adresse https://github.com/CentreChen/EmbFilter.
One-sentence Summary
EmbedFilter refines large language model text embeddings through a linear transformation that leverages the unembedding matrix as a feature lens to filter out a high-frequency token subspace, suppressing uninformative tokens and enhancing semantic representations while enabling inherent dimensionality reduction that lowers index storage and speeds up retrieval without compromising embedding quality.
Key Contributions
- This work identifies a latent subspace within the LLM unembedding matrix that encodes high-frequency tokens and drives semantic anisotropy. EmbedFilter is introduced as a training-free linear transformation that projects out this subspace to directly refine raw model embeddings.
- Extensive evaluations across multiple LLM backbones demonstrate that EmbedFilter achieves up to a 14.1% improvement on the MTEB benchmark for zero-shot text embedding tasks. This lightweight post-processing technique enhances representation quality without requiring additional training.
- The transformation operates as a distance-preserving operation that implicitly reduces the effective dimensionality of the embeddings. This inherent compression lowers index storage overhead and accelerates retrieval speed while fully preserving the refined embedding quality.
Introduction
Large language models have transformed zero-shot learning, yet they consistently underperform as off-the-shelf text embedding models for critical applications like semantic search and large-scale retrieval. Previous efforts to fix this rely on prompt engineering and heuristic adjustments, which are highly sensitive to setup, computationally expensive, and ultimately fail to address the fundamental bottleneck limiting semantic capture. The authors leverage mechanistic interpretability to reveal that the LLM unembedding matrix encodes a latent subspace that forces embeddings to align with high-frequency but semantically empty tokens, creating anisotropic representations. To resolve this, they introduce EmbedFilter, a training-free linear transformation that isolates and removes this problematic subspace. This approach significantly boosts zero-shot embedding quality, naturally compresses the vector space without distorting distances, and accelerates retrieval while reducing storage overhead.
Dataset
- Dataset composition and sources: The authors draw on a corpus focused on zero-shot text embedding and large language model research, though the provided text does not specify external repositories or raw data origins.
- Key details for each subset: No information is provided regarding subset sizes, source breakdowns, or filtering criteria applied to the materials.
- How the paper uses the data: The authors do not outline training splits, mixture ratios, or how the data is allocated across mechanistic interpretation tasks.
- Additional processing details: The input lacks any description of cropping strategies, metadata construction, or preprocessing pipelines used to prepare the dataset.
Method
The authors leverage the unembedding matrix of a large language model (LLM) to develop a method for enhancing text embeddings by filtering out the edge spectrum subspace, which is found to encode dominant, semantically uninformative tokens. The standard process of extracting text embeddings from an LLM involves passing an input sentence X=[x1,x2,…,xL] through the model backbone and applying a pooling strategy P to produce a dense vector h∈Rd. This embedding is derived from the final layer outputs of the LLM, and the unembedding matrix, which maps hidden states back to the vocabulary space, is central to the model's decoding mechanism. The authors argue that this matrix has been underutilized in the context of embedding quality and can be exploited to refine embeddings.
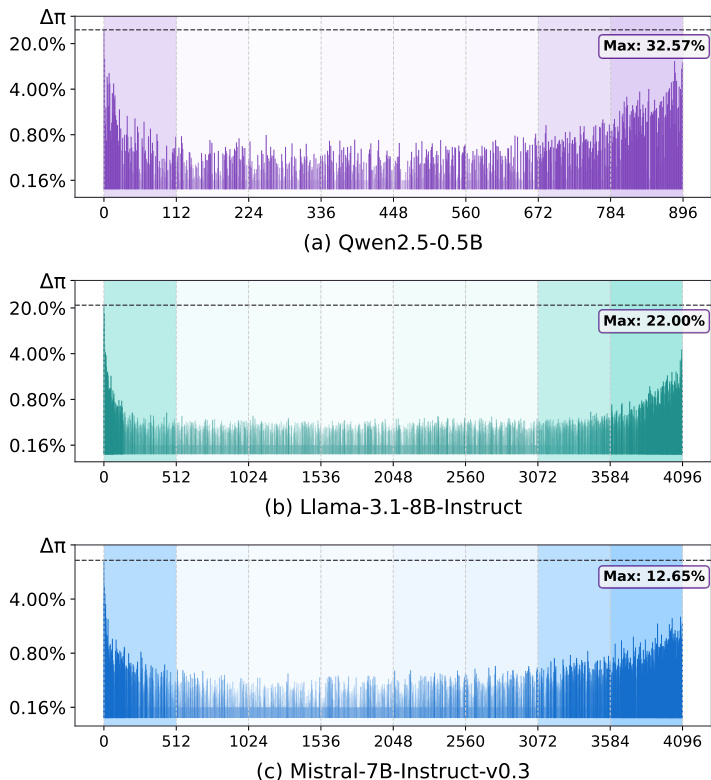
To identify the subspace responsible for encoding high-frequency, non-semantic tokens, the authors employ mechanistic interpretability tools such as Logit Lens and Logit Spectroscopy. Logit Lens projects intermediate representations into the vocabulary space to analyze how activations influence token predictions. Building on this, Logit Spectroscopy uses the singular value decomposition (SVD) of the unembedding matrix WU=UΣV⊤, where WU∈R∣V∣×d, to isolate the contribution of individual spectral components. For each dimension i, a filter Ψi=I−V[i]V[i]⊤ removes the projection of a representation onto the i-th right singular vector of V, enabling spectral analysis of the hidden states.
The authors reverse-engineer the "average" token representation by leveraging word frequencies from the training corpus and the unembedding matrix. Using the Moore–Penrose pseudo-inverse of WU⊤, they compute the average embedding h^=log(p^)WU+, where p^ is the empirical frequency distribution of tokens. Applying Logit Spectroscopy to this average token, they quantify the influence of each spectral subspace on high-frequency tokens through the cumulative logit difference Δπ(i), which measures the sensitivity of the logit predictions to filtering out the i-th subspace. The results reveal that the edge spectrum—corresponding to the largest and smallest singular values—has a dominant effect on frequent tokens, indicating that this region encodes generic, non-semantic information.
Based on these insights, the authors propose EmbedFilter, a linear transformation to filter out the edge spectrum subspace from raw LLM-derived text embeddings. The Bulk Spectrum Transformation Φτ is defined as Φτ=V[lτ:rτ]V[lτ:rτ]⊤, where lτ and rτ are the indices of the mid-range singular components, excluding those associated with extreme singular values. This transformation is applied post-processing to refine embeddings ei into ei=eiΦτ⊤, effectively suppressing the influence of the edge spectrum while preserving the bulk spectrum that captures core semantics. 
As shown in the figure below, the refined embeddings exhibit reduced overrepresentation of frequent, uninformative tokens and enhanced semantic richness, as demonstrated by the Logit Lens analysis. The authors further observe that EmbedFilter enables dimensionality reduction at no cost to performance. Since the transformation matrix V[lτ:rτ] is orthogonal, it preserves pairwise distances, allowing the embeddings to be projected into a lower-dimensional space without theoretical degradation in similarity measurements. This reduction decreases memory overhead and accelerates retrieval, offering both efficiency and effectiveness improvements.
Experiment
Evaluated across the MTEB benchmark on three mainstream LLM backbones, the experiments validate EmbedFilter’s capacity to enhance embedding quality through lightweight dimensionality reduction and targeted subspace filtering. The method consistently improves performance across semantic similarity, classification, clustering, and retrieval tasks while maintaining robustness across varying filtering ratios and significantly lowering computational overhead. Ablation studies confirm that these gains originate from strategically filtering intermediate singular subspaces rather than simple dimension truncation, enabling the framework to approach theoretical performance limits without task-specific calibration. Additionally, the approach outperforms traditional calibration baselines without requiring supervised data, establishing it as an efficient and generalizable enhancement for deploying large language models as embedding generators.
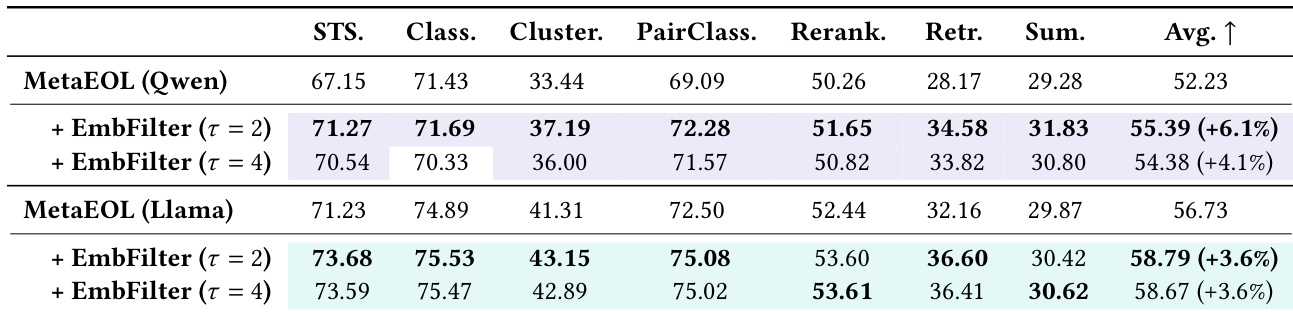
The authors evaluate EmbedFilter on the MTEB benchmark across multiple tasks and backbone models, demonstrating consistent performance improvements over baseline methods. Results show that EmbedFilter maintains strong effectiveness even when reducing embedding dimensions significantly, with minimal computational overhead. The method outperforms various ablation configurations and calibration baselines, highlighting its robustness and efficiency. EmbedFilter achieves consistent performance improvements across all evaluated tasks and models, even with significant dimensionality reduction. The method maintains strong downstream performance with minimal computational overhead, outperforming complex prompt-engineering frameworks. EmbedFilter surpasses ablation configurations and calibration baselines, demonstrating its effectiveness without requiring task-specific tuning.
The authors evaluate EmbedFilter on the MTEB benchmark across multiple tasks and backbone models, demonstrating consistent performance improvements over baseline methods. Results show that EmbedFilter maintains strong effectiveness even with significant dimensionality reduction, and it outperforms both prompt-engineering approaches and calibration baselines without requiring task-specific calibration data. EmbedFilter achieves consistent performance gains across different models and tasks, with improvements maintained even at high dimensionality reduction ratios. EmbedFilter outperforms prompt-engineering methods and calibration baselines like whitening, without relying on supervision or complex calibration data. The effectiveness of EmbedFilter is not due to simple dimensionality reduction, as alternative filtering strategies show inferior results.
The authors evaluate EmbedFilter on the MTEB benchmark across multiple tasks and backbone models, demonstrating consistent performance improvements over baseline methods. Results show that EmbedFilter maintains strong effectiveness even with significant dimensionality reduction, achieving higher overall performance while introducing minimal computational overhead. The method outperforms alternative filtering strategies and calibration baselines, highlighting its robustness and efficiency. EmbedFilter achieves consistent performance improvements across all evaluated tasks and models, even with significant dimensionality reduction. The method maintains superior overall performance compared to baseline approaches, with minimal computational overhead. EmbedFilter outperforms alternative filtering strategies and embedding calibration baselines without requiring task-specific calibration data.
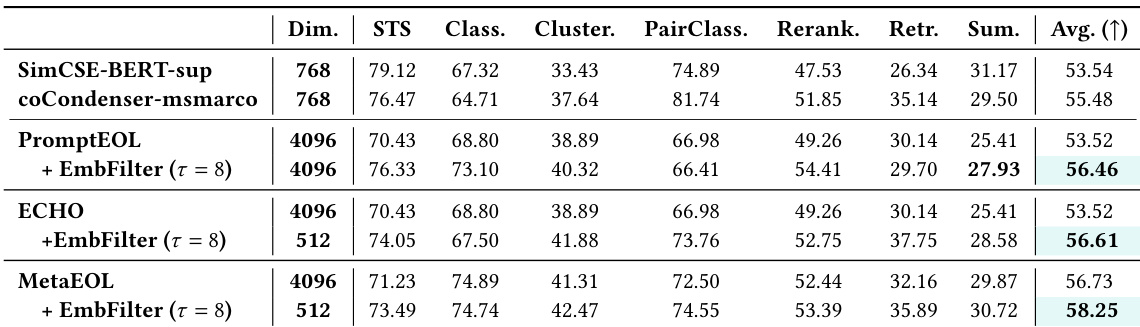
The authors evaluate EmbedFilter on the MTEB benchmark across multiple tasks and backbone models, demonstrating consistent improvements over baseline methods. Results show that EmbedFilter enhances performance across various tasks while reducing embedding dimensionality, with gains maintained even at high filtering ratios. The method achieves superior results compared to both prompt-engineering baselines and calibration techniques like whitening, without requiring additional supervision. EmbedFilter consistently improves performance across MTEB tasks, achieving higher overall scores than baseline methods. The method maintains strong performance even when reducing embedding dimensionality, showing effectiveness at high filtering ratios. EmbedFilter outperforms calibration-based approaches like whitening without relying on supervised calibration data.

The authors evaluate EmbedFilter on the MTEB benchmark across multiple LLMs and configurations, demonstrating consistent improvements over baseline methods across various tasks and dimensionality reduction ratios. Results show that EmbedFilter maintains strong performance even with significant dimensionality reduction, and its effectiveness is robust across different model architectures and prompting strategies. The method achieves these gains with minimal computational overhead, making it suitable for efficient deployment in low-resource scenarios. EmbedFilter consistently improves performance across all evaluated models and tasks, even when reducing embedding dimensions significantly. The method achieves strong results with minimal computational overhead, outperforming more complex frameworks that require iterative LLM calls. EmbedFilter's effectiveness is not due to simple dimensionality reduction, as random or truncated subspace methods perform worse than the proposed filtering strategy.
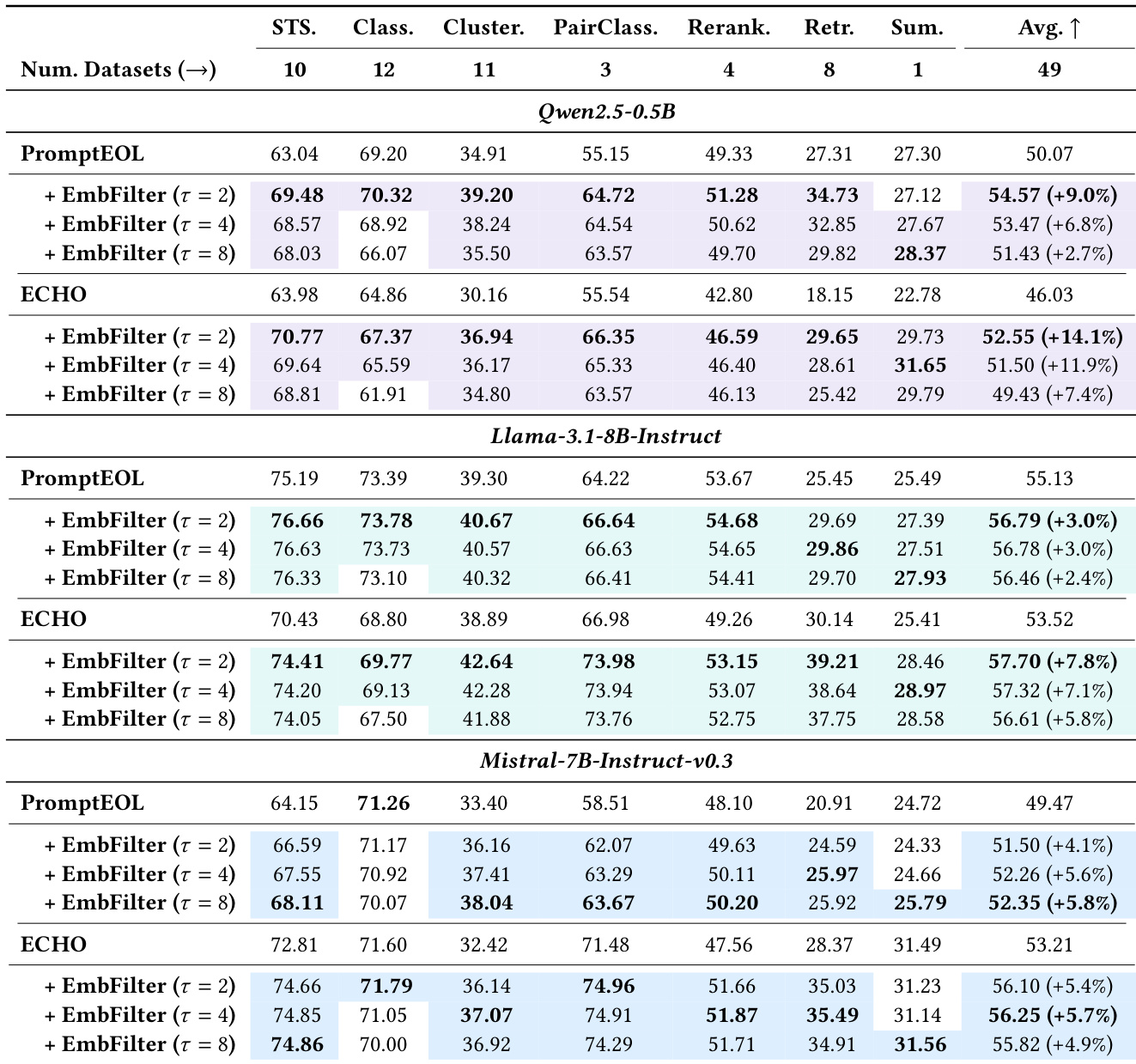
Evaluated across the MTEB benchmark with multiple backbone models and tasks, the experiments validate EmbedFilter's capacity to consistently enhance downstream performance while significantly reducing embedding dimensions. The method demonstrates robust effectiveness across diverse architectures and high filtering ratios, maintaining strong results with minimal computational overhead. Furthermore, it outperforms both calibration baselines and complex prompt-engineering frameworks without requiring task-specific or supervised data, confirming that its improvements stem from targeted filtering rather than simple dimensionality reduction.