Command Palette
Search for a command to run...
Optimisation rétrospective du contrôle : Amélioration des Agents LLM via l'auto-préférence sur les déroulés de trajectoire
Optimisation rétrospective du contrôle : Amélioration des Agents LLM via l'auto-préférence sur les déroulés de trajectoire
Wenbo Pan Shujie Liu Chin-Yew Lin Jingying Zeng Xianfeng Tang Xiangyang Zhou Yan Lu Xiaohua Jia
Résumé
Les agents IA s'appuient sur un harnais de compétences, d'outils et de flux de travail pour résoudre des problèmes complexes. L'amélioration continue de ce harnais est essentielle pour s'adapter à de nouvelles tâches. Cependant, les méthodes d'optimisation existantes nécessitent généralement des ensembles de validation de vérité terrain, or de telles données étiquetées sont difficiles à acquérir dans des contextes de déploiement pratiques. Pour résoudre ce problème, nous présentons Retrospective Harness Optimization (RHO), une méthode auto-supervisée qui optimise le harnais de l'agent en utilisant uniquement des trajectoires passées. Plus précisément, RHO sélectionne un noyau diversifié de tâches difficiles à partir des trajectoires passées et les résout à nouveau en parallèle. L'agent analyse ces exécutions à l'aide d'une auto-validation et d'une auto-consistance, puis génère des mises à jour candidates du harnais et sélectionne la plus efficace selon sa propre auto-préférence par paires. Nous évaluons RHO sur trois domaines variés, couvrant le génie logiciel, le travail technique et le travail intellectuel. Notamment, un seul tour d'optimisation améliore le taux de réussite sur SWE-Bench Pro, passant de 59 % à 78 %, sans aucune notation externe. De plus, notre analyse démontre que RHO cible efficacement les modes de défaillance antérieurs. En conséquence, le harnais optimisé modifie les schémas comportementaux de l'agent et maintient une précision plus élevée lors de sessions de longue durée.
One-sentence Summary
Retrospective Harness Optimization (RHO) is a self-supervised framework that enhances LLM agent harnesses using only past trajectory rollouts by leveraging self-validation, self-consistency, and pairwise self-preference to autonomously select updates, raising the SWE-Bench Pro pass rate from 59% to 78% without external grading while sustaining higher accuracy across software engineering, technical work, and knowledge work during long-horizon sessions.
Key Contributions
- The paper introduces Retrospective Harness Optimization (RHO), a self-supervised framework that enhances agent prompts, tools, and workflows using only unlabeled past execution trajectories without requiring ground-truth validation datasets.
- RHO selects a diverse coreset of challenging historical tasks, re-solves them in parallel, and extracts improvement signals through self-validation, self-consistency, and pairwise self-preference to automatically generate and select optimal harness modifications.
- Evaluations across software engineering, technical work, and knowledge work domains demonstrate that a single optimization round increases the SWE-Bench Pro pass rate from 59% to 78% without external grading while consistently outperforming baseline experience accumulation and validation-driven evolution approaches.
Introduction
AI agents rely on a configurable harness of skills, tools, and workflows to execute complex tasks, making continuous post-deployment optimization essential for adapting to new challenges and sustaining long-horizon accuracy. Prior optimization methods typically depend on labeled validation sets to guide these improvements, yet acquiring ground-truth data that accurately reflects real-world task distributions remains a major practical bottleneck. To address this gap, the authors introduce Retrospective Harness Optimization (RHO), a self-supervised framework that evolves the entire harness exclusively from unlabeled past trajectories. The authors leverage a diverse coreset of historically difficult tasks, re-solve them in parallel, and extract internal self-validation and self-consistency signals to generate candidate updates. By ranking these candidates through the agent's own pairwise self-preference, the method identifies the most effective harness modifications without any external grading, consistently boosting performance across software engineering, technical, and knowledge work domains.
Dataset
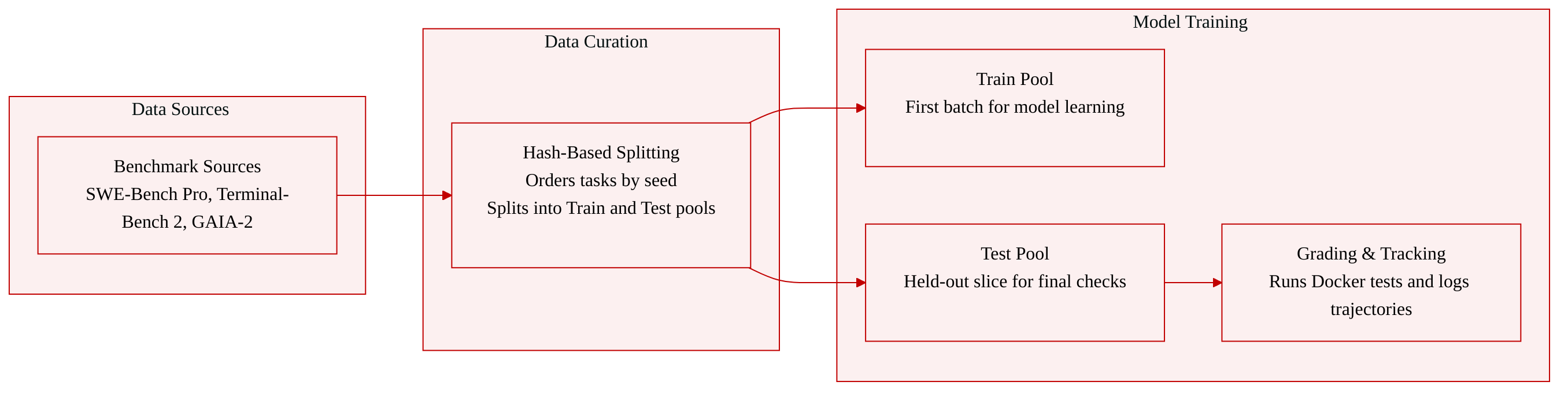
-
Dataset Composition and Sources
- The authors evaluate their framework using three benchmarks sourced from pinned upstream commits to ensure reproducibility.
- SWE-Bench Pro: Sourced from the test split on Hugging Face, this long-horizon software engineering benchmark requires multi-file patches that pass upstream tests.
- Terminal-Bench 2: Drawn from the upstream repository, this dataset contains 89 executable command-line tasks focused on reward-based success rather than build conventions.
- GAIA-2: Loaded from the Hugging Face validation split in mini configuration, this benchmark features 200 scenarios with asynchronous event streams and independent environment evolution.
-
Subset Details and Splits
- The authors apply a consistent deterministic splitting strategy across all benchmarks. Tasks are ordered by the SHA-256 hash of a fixed seed and instance ID, then partitioned into training and held-out test pools.
- SWE-Bench Pro: The split yields 100 training instances and 100 held-out test instances, with remaining rows discarded. Results are reported on the held-out pool.
- Terminal-Bench 2: The split allocates 30 instances to the training pool and 59 to the held-out pool. No difficulty filtering is applied, preserving the full upstream difficulty mix.
- GAIA-2: The split divides 200 scenarios into 100 training and 100 held-out instances. The authors report metrics on the held-out slice.
-
Processing and Evaluation Protocols
- SWE-Bench Pro: Grading extracts patches by re-applying workspace edits to a fresh repository checkout and computing
git diff -binary. The pipeline strips binary hunks and auto-generated paths before applying the patch in official Docker images. A one-hour wall-clock budget limits execution per task. - Terminal-Bench 2: Agents author shell scripts on the host machine and execute them within isolated containers. The grading process runs the upstream test suite inside the container, where a verifier writes a binary reward. A wall-clock watchdog enforces task-specific timeouts.
- GAIA-2: The environment interacts with the agent via a sidecar process that advances simulated time and replays events. The authors increased the message cap from one to four per turn to prevent penalizing verbose agents. Judge-relaxation switches for event filtering and UI judging remain disabled.
- SWE-Bench Pro: Grading extracts patches by re-applying workspace edits to a fresh repository checkout and computing
-
Metadata Construction and Persistence
- The authors implement a comprehensive persistence layer that records prompts, completions, trajectories, diagnoses, candidate harnesses, diffs, scores, and run metadata for every execution.
- Each stored trajectory includes the full event stream, final message, workspace diff, and wall-clock time, enabling downstream audit, re-grading, and ablation studies without re-running the agent.
- Trajectory inspection involves analyzing
events.jsonlandfinal_message.txtto determine success flags and document evidence, tool usage, and reasoning steps. - The system also persists input harness identifiers and per-candidate pairwise scores to support the optimization and ranking operators.
Method
The proposed Retrospective Harness Optimization (RHO) framework operates as a self-supervised pipeline that iteratively improves an agent's harness by analyzing past execution trajectories. The overall architecture is structured into three sequential stages: coreset selection, group rollout, and best-of-N harness proposal. This process is designed to be entirely data-driven, leveraging the agent's own historical performance to generate and refine optimization signals without requiring ground-truth labels or external supervision.
The first stage, coreset selection, aims to identify a representative subset of past trajectories that are most critical for guiding harness optimization. Given a large dataset of trajectories D, the framework selects a coreset Dcore that captures both challenging and diverse scenarios, ensuring the optimization process addresses a wide range of failure modes. This is achieved by employing a Determinantal Point Process (DPP) kernel, which balances difficulty and diversity. The difficulty of each trajectory is first assessed by a language model judge, which produces a score ri and an abstract structural fingerprint detailing the problem's shape. This fingerprint is used to compute a similarity matrix S based on cosine similarity between embeddings. The kernel matrix K=diag(r)Sdiag(r) is then constructed, where ri is a scaled difficulty score determined by a parameter θ. The DPP selects a subset of k trajectories into Dcore with a probability proportional to the kernel determinant, effectively prioritizing difficult and diverse tasks. 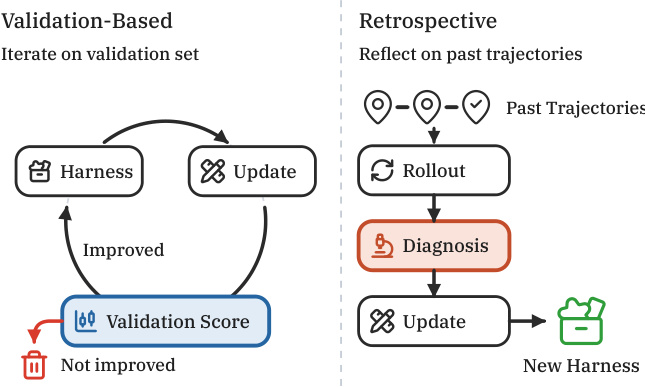
The second stage, group rollout, generates a set of parallel trajectories for each task in the coreset to extract harness improvement signals. For each task t in Dcore, the agent runs G parallel solves using the current harness h0. This group of trajectories is then subjected to a self-preference analysis along two dimensions. Self-validation (rankval) examines the correctness of the agent within each trajectory, flagging issues such as incorrect tool invocations, false assumptions, and premature stopping. Self-consistency (rankcon) analyzes whether the agent's behavior remains consistent across different trajectories, identifying consequential disagreements in plans, tool sequences, or final answers. The structured evaluations from these two analyses are combined into a single improvement instruction It for each task. The union of all It across the coreset forms the final harness improvement instructions. 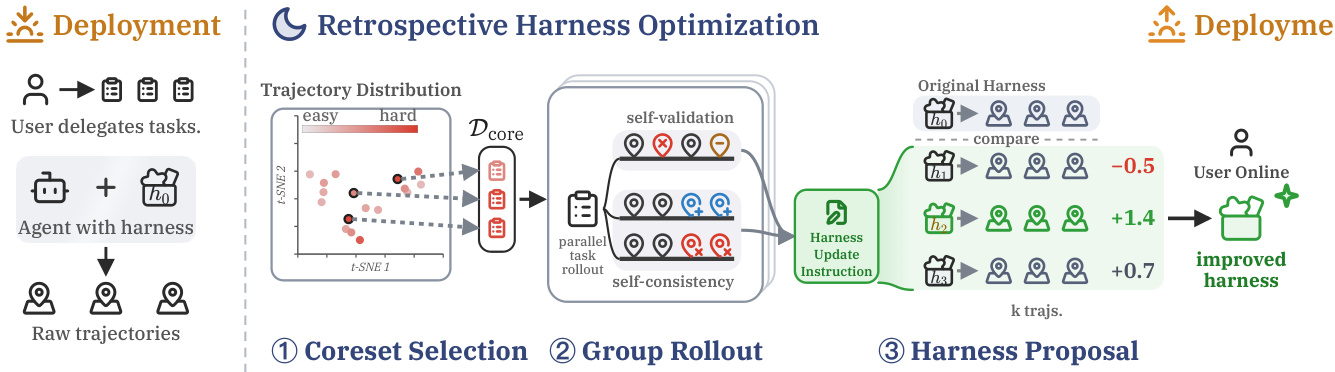
The third stage, best-of-N harness proposal, generates and selects the most promising candidate harnesses. To mitigate the stochastic nature of harness optimization, the framework samples N candidate harnesses in parallel by providing the improvement instructions I to the agent. Each candidate harness hj is then used to generate a new set of trajectories on the k coreset tasks. The relative advantage of each candidate is computed by averaging the agent's self-preference scores over the coreset, where the score Sj is calculated as the mean of pairwise rankings between the new trajectory τt(j) and the original baseline trajectory τt(0) for each task t. The candidate with the maximum relative advantage score Sj∗ is selected. The update is accepted only if this score is strictly greater than zero, ensuring that only improvements are adopted. 
Experiment
The evaluation employs a configurable Codex agent harness across software engineering, technical, and knowledge-work benchmarks to assess retrospective optimization against both feedback-free memory methods and iterative validation-based optimizers. Experiments validate that RHO consistently enhances performance by generating targeted tools and procedural skills that address recurrent failure modes, while behavioral analysis reveals improved long-horizon task success through increased verification and active tool application. Additional ablation studies confirm that balancing task difficulty and diversity during coreset selection is essential for effective optimization, and that explicit self-validation and self-consistency signals reliably drive improvements without requiring ground-truth labels or excessive computational overhead. Collectively, these findings demonstrate that offline retrospective analysis can effectively evolve agent capabilities while maintaining a streamlined optimization budget.
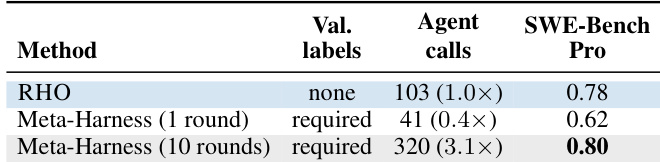
The authors compare their method, RHO, with Meta-Harness, a validation-feedback optimizer, on SWE-Bench Pro. RHO achieves a higher pass rate than Meta-Harness at both single-round and multi-round settings. The comparison shows that RHO performs better with fewer agent calls and without requiring validation labels, while Meta-Harness requires labels and more compute to reach a similar or lower performance level. RHO achieves a higher pass rate than Meta-Harness on SWE-Bench Pro without using validation labels. Meta-Harness requires validation labels and more agent calls to achieve a performance level similar to or lower than RHO. RHO outperforms Meta-Harness at a single round and even when Meta-Harness is scaled to ten rounds, requiring significantly more optimization-phase compute.
The authors compare RHO against several feedback-free baselines and a validation-feedback optimizer, demonstrating that RHO consistently improves performance across multiple benchmarks without relying on validation feedback. RHO achieves higher pass rates than all baselines and outperforms a validation-feedback method under matched compute, while also enabling the agent to develop new tools and skills that address specific failure modes. The optimization process leads to changes in agent behavior, such as increased verification on long-horizon tasks and more effective use of newly developed tools. RHO achieves consistent improvements across all benchmarks without using validation feedback, outperforming feedback-free baselines and a validation-feedback optimizer under matched compute. RHO generates new tools and skills that address specific failure modes, such as non-standard toolchain locations and cache directory issues, which were missed by the original harness. The optimized agent shifts its behavior, relying more on verification for long-horizon tasks and actively using new tools, leading to higher success rates on complex tasks.
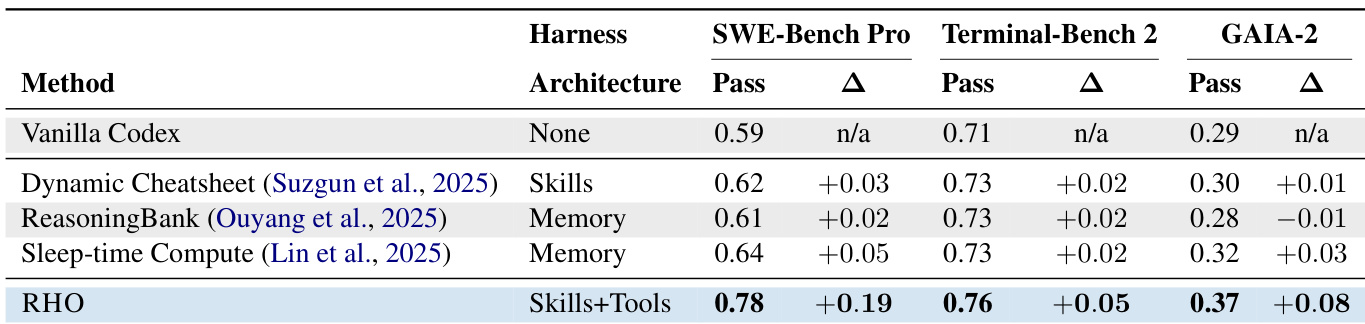
The the the table compares the computational cost of different methods in terms of agent invocations across various stages of the optimization process. RHO incurs the highest total number of invocations due to its more complex workflow involving diagnosis, optimization, and ranking, while other methods like ReasoningBank and Dynamic Cheatsheet have simpler processes with fewer steps. Vanilla Codex serves as a baseline with no optimization steps and only test invocations. RHO requires the most agent invocations due to its multi-step optimization process including diagnosis, optimization, and ranking. ReasoningBank and Dynamic Cheatsheet have simpler workflows with fewer steps and lower total invocations compared to RHO. Vanilla Codex has the lowest computational cost as it only performs test invocations without any optimization steps.

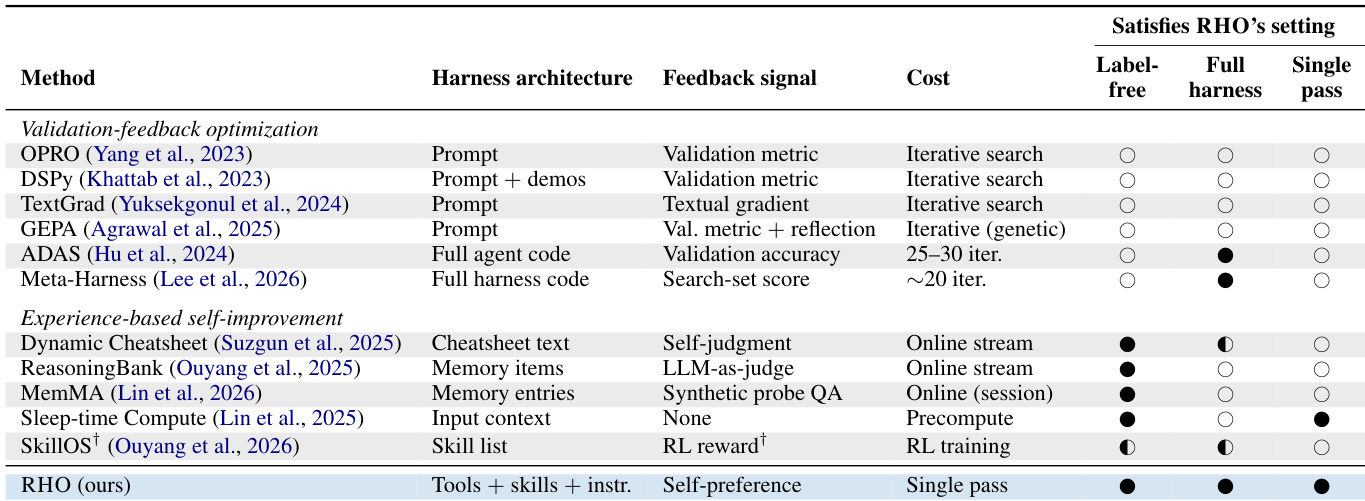
{"summary": "The authors compare their method, RHO, against existing optimization techniques across multiple benchmarks, demonstrating consistent improvements without relying on validation feedback. RHO achieves superior performance by enabling flexible harness optimization through the creation of new tools, skills, and instructions, while maintaining a single offline pass and operating label-free. The comparison highlights that RHO uniquely satisfies all three criteria of label-free optimization, full harness editing, and single-pass execution, distinguishing it from prior approaches.", "highlights": ["RHO achieves consistent improvements across benchmarks without using validation feedback, outperforming baselines that rely on feedback or memory systems.", "RHO enables full harness optimization by creating new tools, skills, and instructions, unlike methods that only modify memory or context.", "RHO is the only method that satisfies all three criteria of being label-free, editing the full harness, and operating as a single offline pass."]
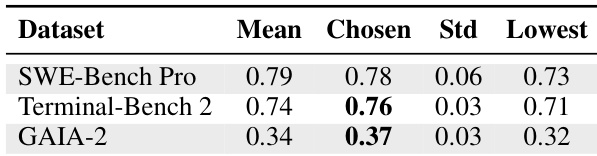
The authors evaluate the performance of RHO on three benchmarks, comparing the mean, chosen, standard deviation, and lowest pass rates of the optimized harnesses. Results show that the chosen harness consistently outperforms the mean across all datasets, with the lowest pass rate always below the mean, indicating that the best-of-N selection effectively avoids poor-performing candidates. The performance gap between the chosen and mean values is most pronounced on SWE-Bench Pro, suggesting greater variability in optimization outcomes for this benchmark. The chosen harness consistently achieves higher performance than the mean across all benchmarks. The lowest-performing harness is always below the mean, indicating that the optimization process reliably improves performance. The performance gap between the chosen and mean values is largest on SWE-Bench Pro, suggesting higher variability in optimization outcomes for this benchmark.
The evaluation compares RHO against multiple feedback-free and validation-feedback baselines across software engineering benchmarks to validate its efficiency, label-free operation, and adaptive optimization capabilities. Comparative experiments demonstrate that RHO consistently outperforms existing methods by autonomously developing new tools and instructions that target specific failure modes, while simultaneously shifting agent behavior toward more rigorous verification on complex tasks. Computational comparisons show that while RHO employs a more complex multi-step workflow, it requires significantly fewer agent calls than label-dependent optimizers to reach comparable or superior performance levels. Finally, selection experiments confirm that best-of-N sampling reliably isolates high-performing harnesses, proving that flexible, label-free harness editing effectively enhances agent performance across diverse benchmarks.