Command Palette
Search for a command to run...
Modèle d'interaction audio
Modèle d'interaction audio
Résumé
L'audio constitue une modalité intrinsèquement interactive ; pourtant, les grands modèles de langage audio (LALM) actuels fonctionnent hors ligne, et les modèles audio en streaming ne traitent chacun qu'une tâche unique, telle que la reconnaissance automatique de la parole en streaming (ASR) ou le chat vocal. Il est temps de les unifier au sein d'un unique LALM en ligne : un modèle qui, via une boucle « percevoir-décider-répondre » toujours active, écoute les sons, l'environnement et les instructions en temps réel et réagit à la volée. Nous formalisons ce paradigme sous le nom de Modèle d'Interaction Audio et le concrétisons avec Audio-Interaction, un modèle de streaming unifié qui préserve l'exécution de tâches hors ligne tout en intégrant le suivi d'instructions audio générales en ligne, allant du dialogue au chat vocal complet, en décidant du moment de répondre à partir de la sémantique du flux. Pour y parvenir, nous proposons SoundFlow, un cadre qui instancie la boucle « percevoir-décider-répondre » de bout en bout, depuis la constitution des données jusqu'à l'entraînement et le déploiement, grâce à une construction de données native au streaming, un entraînement conscient de la compréhension, et une inférence asynchrone à faible latence permettant une interaction en temps réel stable. Nous construisons par ailleurs StreamAudio-2M, un corpus de streaming de 2,6 millions d'éléments couvrant sept capacités fondamentales et vingt-huit sous-tâches, ainsi que Proactive-Sound-Bench, dédié à l'évaluation de l'intervention audio proactive. Sur huit jeux de référence, Audio-Interaction conserve des performances compétitives sur les tâches audio standard tout en débloquant des capacités inaccessibles aux LALM hors ligne, notamment la reconnaissance automatique de la parole en temps réel, le suivi d'instructions audio en streaming et l'assistance proactive.
One-sentence Summary
The authors introduce the AUDIO INTERACTION MODEL, instantiated as AUDIO-INTERACTION, which unifies offline and single-task streaming audio systems into a real-time perceive-decide-respond loop via the SOUNDFLOW framework, trained on the STREAMAUDIO-2M corpus and evaluated with PROACTIVE-SOUND-BENCH to enable low-latency, proactive audio intervention and unified voice interaction.
Key Contributions
- AUDIO-INTERACTION formalizes the Audio Interaction Model regime by executing traditional offline tasks alongside real-time online instruction following and voice chatting, dynamically deciding when to respond based on the semantics of the incoming audio stream.
- SOUNDFLOW implements an always-on perceive-decide-respond loop through streaming-native data construction, comprehension-aware training, and asynchronous low-latency inference to enable stable real-time deployment.
- STREAMAUDIO-2M provides a 2.6M-item streaming corpus spanning seven fundamental abilities and 28 sub-tasks, complemented by PROACTIVE-SOUND-BENCH for evaluating proactive audio intervention. Experiments across eight benchmarks demonstrate competitive performance on standard tasks while enabling long-stream interaction and proactive assistance.
Introduction
Audio is fundamentally a continuous, real-time modality, yet current Large Audio Language Models operate in an offline batch-processing mode that waits for complete recordings before generating responses. This architectural mismatch limits their deployment in always-on applications where systems must simultaneously monitor environments, follow dynamic instructions, and interact naturally with users. Prior streaming approaches attempt to bridge this gap but remain confined to narrow, task-specific pipelines that cannot jointly process acoustic context, environmental sounds, and user prompts while dynamically deciding when to intervene. The authors address these limitations by introducing the Audio Interaction Model, a unified streaming architecture that processes audio in fixed chunks through a continuous perceive, decide, and respond loop. By implementing the SOUNDFLOW framework for streaming-native data construction, comprehension-aware training, and asynchronous low-latency inference, they enable a single model to execute traditional audio tasks alongside real-time instruction following and proactive assistance without sacrificing benchmark performance.
Dataset
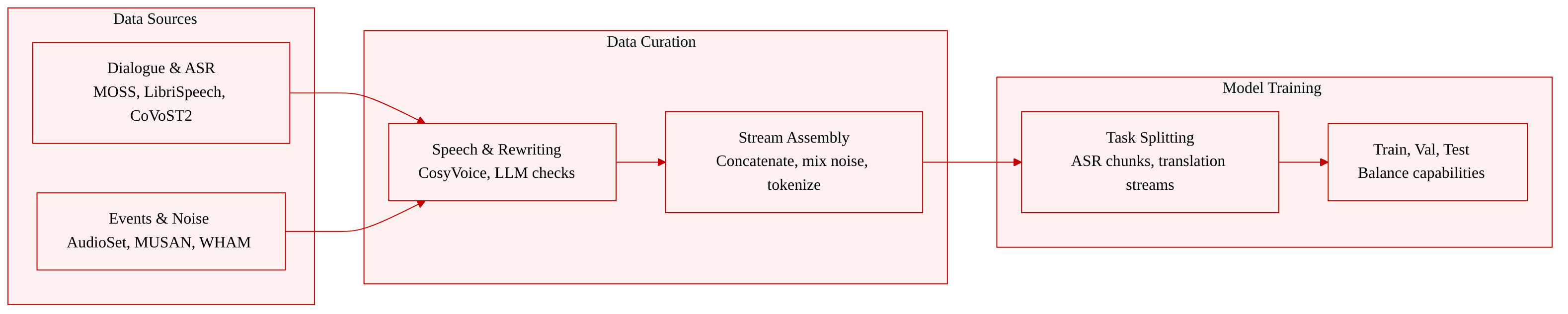
-
Dataset Composition and Sources
- The authors introduce StreamAudio-2M, a large-scale streaming-native corpus designed for continuous audio interaction. It spans seven core capability categories and twenty-eight sub-tasks, totaling approximately 2.6 million items and 302,000 hours of audio. Each sample represents a three to fifteen turn heterogeneous interaction featuring interleaved events and sparse, context-dependent response cues.
-
Subset Details and Sizing
- Dialogue and Language: MOSS supplies the largest block, converting 392,000 text instances into roughly 4,900 hours of multi-voice speech.
- ASR and Translation: LibriSpeech, CommonVoice, and GigaSpeech provide recognition data, while CoVoST2 and AISHELL contribute bidirectional English-Chinese translation pairs.
- Acoustic Events: The authors combine real AudioSet recordings with synthetic clips from AudioX and ElevenLabs to cover rare safety-critical sounds, yielding approximately 171,000 event clips.
- Background Noise: MUSAN, WHAM!, and DNS-Challenge contribute roughly 620 hours of environmental audio used exclusively for acoustic conditioning.
-
Data Processing and Construction
- Textual sources are rendered into speech using a multi-voice CosyVoice model, followed by LLM-based rewriting and ASR verification to ensure natural spoken phrasing.
- A strict spoken-style rewriter normalizes text by stripping markdown, expanding numerals and abbreviations, and replacing symbols while preserving original meaning and tone.
- Validated sequences are concatenated into multi-turn streaming formats with dual-track background noise mixed at a controlled signal-to-noise ratio.
- The final corpus is tokenized into standard input and label pairs for model training.
-
Usage, Cropping, and Metadata Strategy
- The authors partition the dataset across capability families with specific task proportions to balance streaming interaction, proactive response, and continuous understanding during training.
- For ASR supervision, LibriSpeech is re-segmented into 400 millisecond chunks to deliver recognition targets during the listening phase rather than at utterance boundaries.
- Translation data is utilized in both native offline formats and stitched continuous streams to train simultaneous interpretation capabilities.
- Reference answers for question-answering tasks are strictly constrained to appear at least three turns prior, must not be inferable from recent context, and are phrased as natural, entity-grounded user queries without scaffolding cues.
Method
The authors leverage a unified streaming architecture to bridge the gap between conventional offline audio-language models and real-time interactive settings. The framework, termed AUDIO-INTERACTION, operates on a continuous stream of audio chunks, enabling autonomous decision-making on whether to remain silent or generate a response. At each time step t, the model consumes the current audio chunk at and predicts a streaming intervention decision dt and a response rt based on the history a<t,d<t,r<t. This perceive–decide–respond loop forms the core of the system, allowing the model to perform a variety of real-time tasks such as speech translation, simultaneous interpretation, dialogue, and proactive assistance. As shown in the figure below, the architecture integrates an audio encoder, an adapter, and a language model, with the adapter facilitating the transformation of chunk-wise acoustic representations into the language model's latent space. The model's decision to respond is governed by a special token, <response>, which triggers autoregressive response generation, while <silent> indicates continued listening. This formulation enables the model to jointly learn when to respond and what to generate in real-time spoken interaction.
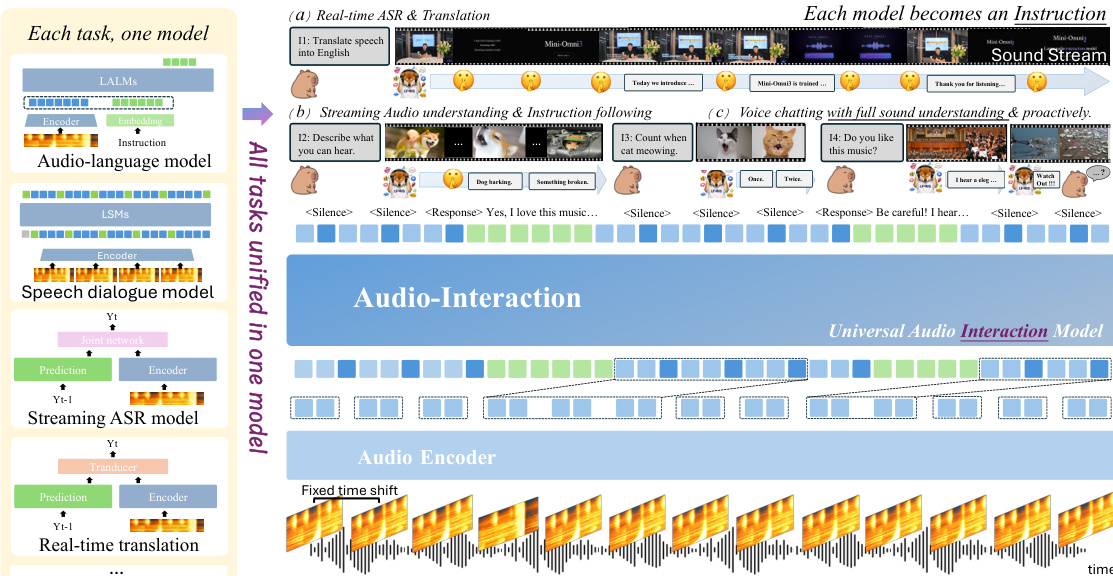
The training process is designed to support this streaming paradigm through a multi-stage pipeline. The model is initialized from Qwen2.5-Omni-3B, a compact and efficient language model, and is optimized with a dual-loss objective that combines standard language modeling with a dedicated streaming control token prediction. The overall loss is defined as L=N1∑j=1N(−logPθ(tj∣Hj)+λ(−logPθ(sj∣Hj))), where the first term supervises the generation of text tokens and the second term, weighted by λ, targets the prediction of the streaming control token sj. This dual objective ensures the model learns both the content of the response and the timing of its generation. The training pipeline consists of four stages: format training to teach the model the sequence format and the use of the <Spe_token>, adapter training to map acoustic features to the language model space, large-scale streaming supervised training on core capabilities like audio understanding and dialogue, and instruction-following fine-tuning on complex behaviors involving continuous assistance and proactive response. This staged approach allows the model to progressively build the necessary skills for real-time interaction.
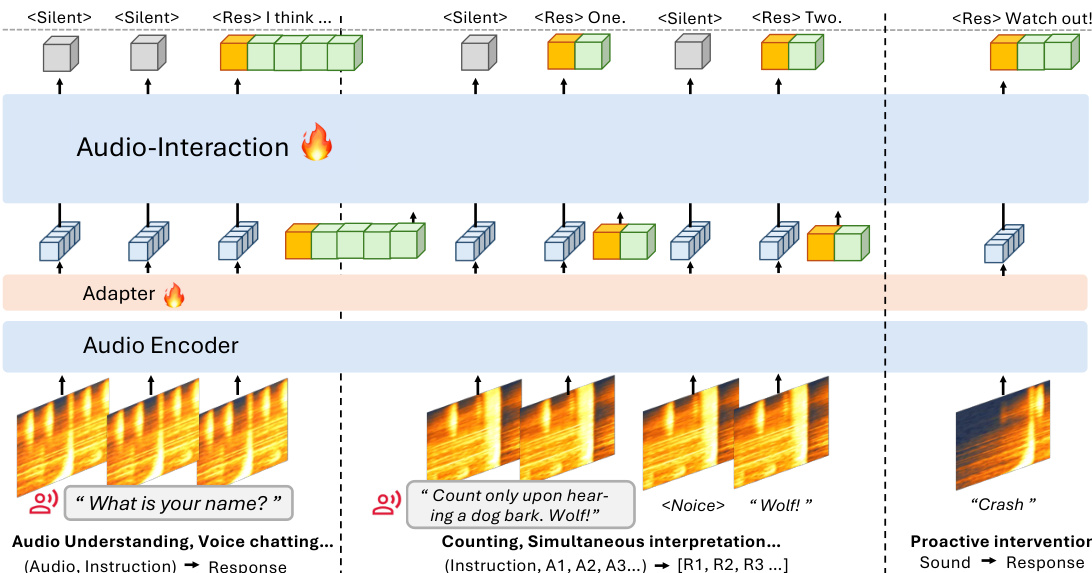
To ensure the model's robustness in real-world scenarios, the training data is carefully constructed to address two critical failure modes: insufficient context retention and false triggering. The framework employs a hierarchical event curation pipeline to create long-form, coherent streaming audio data. This process begins with scenario planning, where a large language model generates a high-level narrative from randomly matched audio annotations, ensuring semantic consistency across events. Each topic is then refined into concrete audio events, and clips are obtained through retrieval or generation, verified for plausibility and coherence. The data is further processed through a time-frequency joint preprocessing (TFJP) module, which smooths audio segments by iteratively removing silence, estimating and subtracting background noise, and refining the boundaries of informative content. This preprocessing ensures that the audio is well-aligned and suitable for downstream streaming tasks. The resulting dataset, StreamAudio-2M, is designed to cover seven core capabilities across 28 sub-tasks, providing a comprehensive foundation for training the model.

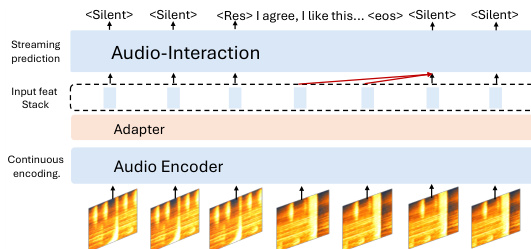
The deployment of the model is managed through an asynchronous inference scheme with FIFO scheduling to mitigate waiting conflicts and ensure low-latency performance. As illustrated in the figure below, the audio encoder continuously processes incoming chunks and appends their acoustic representations to a temporally ordered queue. The decoder, operating independently, is conditionally triggered based on the last generated token. When the model emits a or token, it drains the entire queue, ensuring that the decoder's context is aligned with the most recent audio input. This approach eliminates inference stalling and reduces the first-frame latency for resuming listening after a response. The system's ability to maintain a stable and responsive interaction is further enhanced by the use of a large amount of silent audio verified by agents in PROACTIVESOUND-BENCH, which helps the model learn to remain silent unless intervention is truly warranted. This combination of a robust training framework and efficient inference scheduling enables the model to perform complex real-time audio interactions effectively.
Experiment
The evaluation framework assesses the model across comprehensive audio understanding, spoken dialogue, and speech processing benchmarks, alongside specialized tests for proactive streaming responses and real-world acoustic environments. These experiments collectively validate that native streaming training preserves offline comprehension capabilities while enabling low-latency, context-aware interventions that remain robust against acoustic noise and extended audio concatenation. Ablation studies further confirm that architectural decisions such as asynchronous inference scheduling and balanced dual-loss optimization are essential for maintaining stable decision boundaries and achieving an optimal accuracy-latency trade-off. Ultimately, the model demonstrates strong generalization to unfiltered deployment scenarios, proving that its streaming behaviors reflect genuine acoustic comprehension rather than synthetic training artifacts.
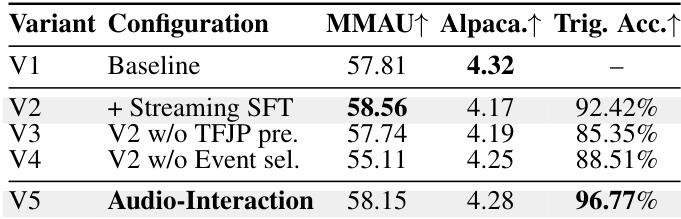
The authors evaluate AUDIO-INTERACTION against a range of specialized, omni, and streaming audio language models on spoken dialogue and voice benchmark tasks. Results show that AUDIO-INTERACTION achieves competitive performance on key metrics, particularly in the Web Questions and SD-QA categories, while operating at a smaller model size compared to many baselines. AUDIO-INTERACTION achieves competitive performance on Web Questions and SD-QA benchmarks despite its smaller size compared to larger models. Among specialized models, Freeze-Omni and Moshi show strong results on spoken dialogue tasks, with Freeze-Omni leading in several categories. The model AUDIO-INTERACTION demonstrates balanced performance across both spoken dialogue and voice benchmarks, indicating its effectiveness in multi-task audio interaction scenarios.
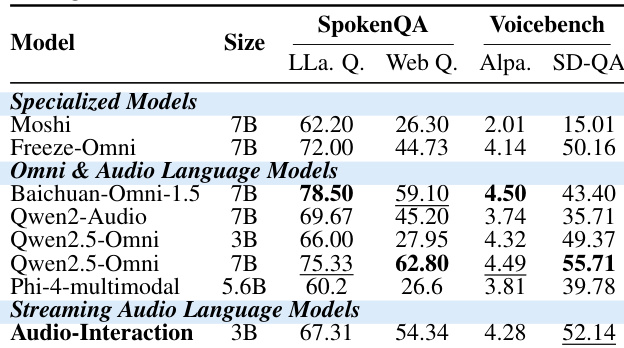
The authors analyze the importance of different model components across layers and heads for various tasks, including ASR, S2TT, audio understanding, and dialogue. The heatmaps show that certain heads and layers contribute more significantly to specific tasks, with distinct patterns emerging for each task type. The results suggest that task-specific attention mechanisms are distributed across different parts of the model architecture. Different tasks exhibit distinct patterns of importance across model layers and heads. Certain heads and layers are more critical for specific tasks like ASR, S2TT, audio understanding, and dialogue. The importance distribution varies significantly between tasks, indicating specialized attention mechanisms.
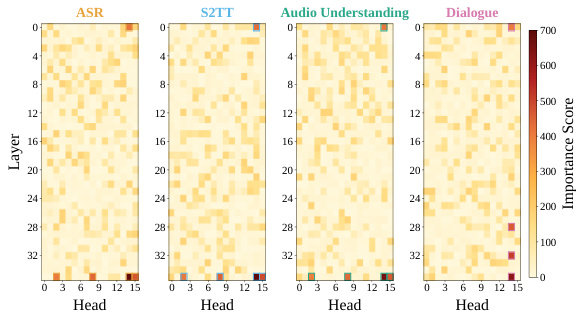
The authors evaluate the performance of various audio language models on a proactive sound benchmark, comparing Omni and Audio Language Models with Streaming Audio Language Models. Results show that the proposed Audio-Interaction model achieves higher average accuracy across both single and multiple event tiers, particularly in the Daily and Traffic categories, outperforming other models in the Streaming Audio Language Models category. Audio-Interaction achieves the highest average accuracy among all models in the Streaming Audio Language Models category. Audio-Interaction shows significant improvements in the Daily and Traffic categories compared to other models. The model maintains high performance in both single and multiple event tiers, indicating robust proactive response capabilities.
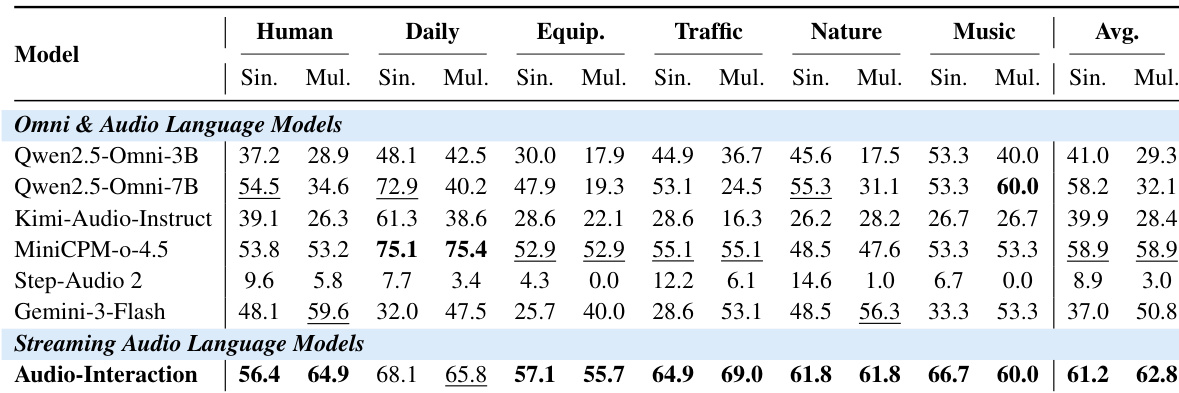
The authors conduct an ablation study to evaluate the impact of different training components on model performance. Results show that adding streaming supervised fine-tuning improves audio understanding and proactive response accuracy compared to the baseline. Removing specific preprocessing or event selection methods reduces accuracy, while the full Audio-Interaction configuration achieves the highest proactive trigger accuracy. Adding streaming supervised fine-tuning improves both audio understanding and proactive response accuracy compared to the baseline. Removing TFJP preprocessing or event selection reduces proactive trigger accuracy, indicating their importance. The full Audio-Interaction configuration achieves the highest proactive trigger accuracy among all variants.
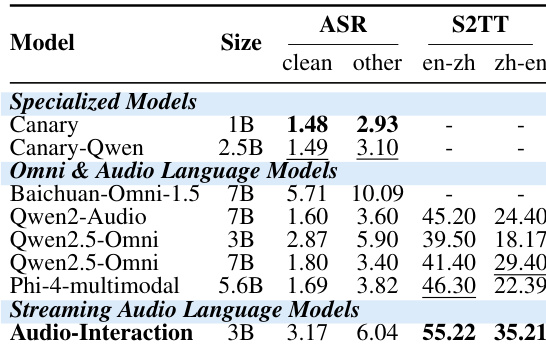
The authors evaluate AUDIO-INTERACTION, a streaming audio language model, against specialized, omni, and audio language models across speech and speech-to-text translation tasks. Results show that AUDIO-INTERACTION achieves competitive performance on core speech tasks, particularly in speech-to-text translation, while maintaining a smaller model size compared to other multimodal models. AUDIO-INTERACTION achieves strong performance on speech-to-text translation tasks, outperforming other models in both en-zh and zh-en directions. The model maintains a smaller parameter size compared to other multimodal models while still achieving competitive results. AUDIO-INTERACTION shows improved performance on speech recognition tasks, particularly in the other category, compared to specialized models like Canary and Canary-Qwen.
The evaluation benchmarks AUDIO-INTERACTION against specialized, omni, and streaming audio language models across spoken dialogue, proactive sound, speech recognition, and translation tasks, while also analyzing internal attention distributions and training component contributions. Qualitative results indicate that the model delivers balanced performance across diverse audio interaction scenarios despite its compact parameter size. Internal analysis reveals that distinct layers and heads specialize in different tasks, highlighting effective task-specific attention mechanisms. Furthermore, ablation studies confirm that streaming supervised fine-tuning combined with targeted preprocessing and event selection strategies is essential for maximizing proactive response and audio understanding capabilities.