Command Palette
Search for a command to run...
Les modèles du monde rencontrent les modèles de langage : sur la complémentarité du raisonnement concret et abstrait
Les modèles du monde rencontrent les modèles de langage : sur la complémentarité du raisonnement concret et abstrait
Yucheng Zhou Wei Tao Yiwen Guo Jianbing Shen
Résumé
Les modèles du monde et les modèles de langage large multimodaux (MLLM) offrent des capacités complémentaires pour prédire les résultats futurs à partir d'observations visuelles statiques. Les modèles du monde peuvent générer des déroulements visuels concrets de futurs possibles, tandis que les MLLM peuvent raisonner de manière abstraite sur des questions, des objectifs et des règles. Cependant, les déroulements générés sont stochastiques et peuvent être visuellement plausibles mais incorrects pour la tâche, ce qui rend nécessaire de déterminer quand la simulation visuelle est utile, si un déroulement est crédible et comment il devrait influencer la réponse finale. Nous formulons ce problème comme un raisonnement concret contrôlé, dans lequel un modèle apprend à invoquer, vérifier et intégrer une simulation visuelle du futur aux côtés du raisonnement abstrait. Pour étudier ce cadre, nous construisons deux benchmarks validés par des humains, VRQABench pour l'anticipation spatiale contrôlable et OpenWorldQA pour la prédiction physique en domaine ouvert, et proposons la Distillation auto-entraînement On-Policy à Futur Privilégié (PF-OPSD). Pendant l'entraînement, PF-OPSD utilise les vidéos futures de vérité terrain et les réponses uniquement comme contexte privilégié côté enseignant pour évaluer les trajectoires de raisonnement concret sur politique, tandis que le modèle élève déployable n'observe jamais de vrais futurs au moment du test. Les résultats expérimentaux montrent que PF-OPSD surpasse le modèle de référence de 10,6 % et 10,9 % sur VRQABench et OpenWorldQA, respectivement, tout en augmentant la robustesse face aux déroulements bruités ou conflictuels. Notre code et notre jeu de données sont disponibles à l'adresse https://github.com/yczhou001/PF-OPSD.
One-sentence Summary
The authors propose Privileged-Future On-Policy Self-Distillation (PF-OPSD), a framework that trains multimodal large language models to verify and integrate stochastic world model rollouts with abstract reasoning, achieving 10.6% and 10.9% improvements over baselines on the VRQABench and OpenWorldQA benchmarks while enhancing robustness to noisy simulations through privileged ground-truth future videos during training and strict inference-time restrictions.
Key Contributions
- The paper formulates future prediction as controlled concrete reasoning and introduces two human-verified benchmarks, VRQABench and OpenWorldQA, to evaluate controllable spatial lookahead and open-domain physical prediction from static visual anchors.
- The study proposes Privileged-Future On-Policy Self-Distillation (PF-OPSD), a training framework that utilizes ground-truth future videos and answers exclusively as teacher-side privileged context to evaluate concrete-reasoning trajectories while ensuring the deployed student model never accesses true futures at inference.
- Empirical evaluations show that PF-OPSD surpasses baseline methods by 10.6% on VRQABench and 10.9% on OpenWorldQA, while substantially increasing robustness to noisy or conflicting visual rollouts.
Introduction
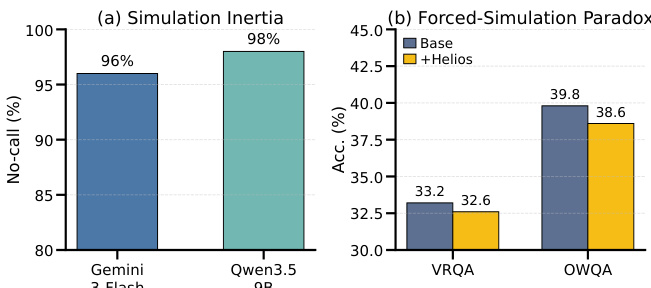
The authors tackle future-oriented visual reasoning by integrating multimodal large language models with video world models to predict outcomes from static observations. This combination matters because static inputs lack temporal dynamics, requiring models to leverage abstract language reasoning for rules while using concrete visual rollouts to simulate physical consequences. Prior work faces significant limitations as world model rollouts are stochastic and often visually plausible yet task-incorrect, leading to failure modes like simulation inertia where models ignore helpful simulations or a forced-simulation paradox where they blindly trust misleading rollouts. To resolve this, the authors formulate controlled concrete reasoning and propose Privileged-Future On-Policy Self-Distillation, a framework that uses ground-truth futures as privileged teacher context during training to distill reliable simulation invocation and verification decisions into a deployable student. Additionally, the authors introduce VRQABench and OpenWorldQA benchmarks to evaluate controllable spatial lookahead and open-domain physical prediction, demonstrating improved accuracy and robustness over baselines.
Dataset
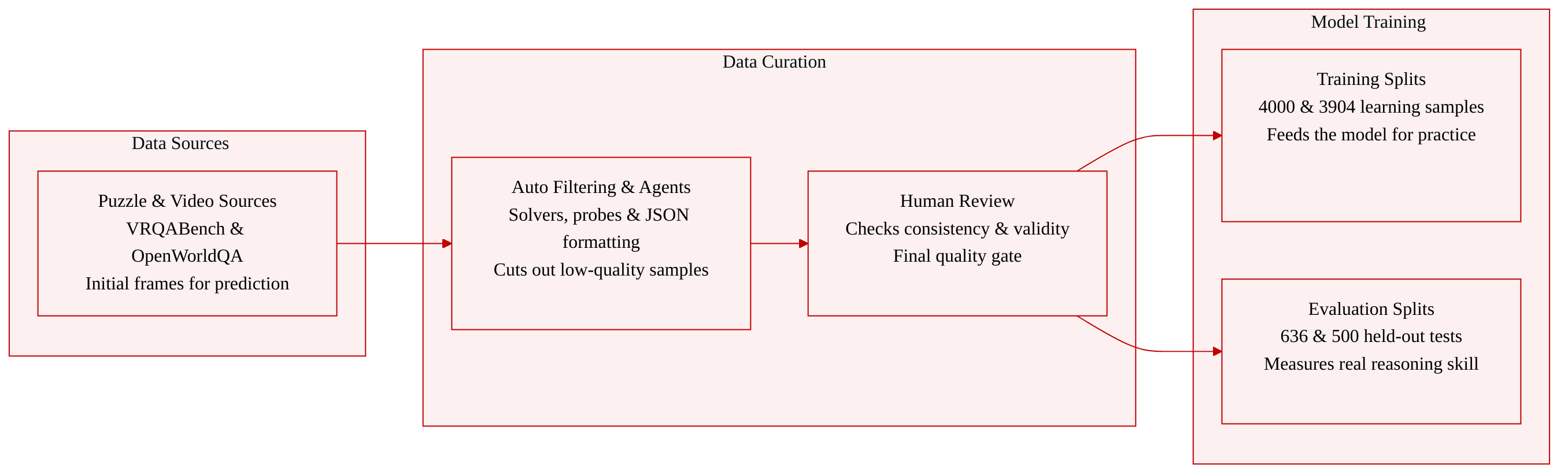
- Dataset Composition and Sources
- The authors introduce two four-choice benchmarks designed to evaluate future prediction from static observations. VRQABench is derived from VR-Bench and focuses on rule-governed spatial lookahead in puzzle environments. OpenWorldQA is constructed from short real-world videos and tests open-domain physical prediction.
- Subset Details (Size, Source, and Filtering)
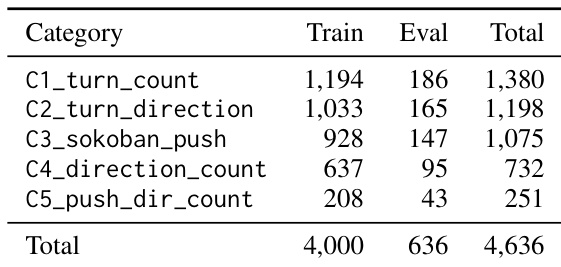
- VRQABench contains 4,636 human-verified questions split into 4,000 training and 636 evaluation samples. It covers five spatial categories and replaces VLM-based solution tracing with deterministic solvers to ensure programmatically grounded labels. Items undergo automatic quality filtering followed by human verification to confirm visual consistency, option plausibility, and answer validity.
- OpenWorldQA comprises 4,404 human-verified questions split into 3,904 training and 500 balanced test samples. It spans twelve physical-reasoning categories and six question forms. The dataset is built through a five-stage agentic pipeline that handles scene analysis, question design, distractor generation, and small-model probing, with a final human review to remove ambiguous or visually inconsistent samples.
- Data Usage and Processing
- The training splits provide the primary learning material, while the evaluation sets measure performance on held-out reasoning tasks. Future video frames are strictly excluded from model inputs. During world-model-assisted experiments, the system can optionally invoke an external rollout generator, but the model must independently decide when to request, trust, or reject the simulated futures. The authors use these benchmarks to diagnose agent limitations like simulation inertia and the forced-simulation paradox, emphasizing dynamic rollout management over naive integration.
- Metadata Construction and Formatting
- Each accepted sample is serialized into a structured JSON file containing the category, question text, four options, correct answer, source identifiers, task type, and file paths for the input image and solution video. The pipeline attaches comprehensive metadata including programmatic solution statistics, human review decisions and scores, and version tracking. ASCII decorative symbols are normalized for compatibility, and all construction prompts are version-controlled to ensure reproducible dataset generation.
Method
The authors leverage a framework for controlled concrete reasoning that integrates a generative world model into a multi-step decision-making process for future prediction tasks. The overall architecture is designed to enable a model to dynamically decide when to engage in simulation-based reasoning, verify the credibility of generated rollouts, and integrate them with abstract reasoning to produce a final answer. The process begins with an input consisting of an observation and a question, from which the model first determines whether abstract reasoning alone is sufficient. If not, the model proceeds to generate a simulation prompt and queries a world model to produce a candidate future rollout. This rollout is then verified for consistency and relevance, and the model decides how much to rely on it, potentially retrying the simulation up to a maximum number of attempts. The final answer is derived by combining the verified rollout with abstract reasoning or by relying solely on abstract reasoning if no simulation was used.
The policy produces a concrete-reasoning trajectory that captures the sequence of decisions made during the reasoning process. Without simulation, the trajectory consists of a simulation decision, a rollout reliance decision, and the final answer. When simulation is invoked, the trajectory includes a bounded sequence of simulation attempts, each comprising a prompt, a generated rollout, and a verification decision. The number of attempts is determined by a stopping condition based on the verification outcome or a maximum cap. The action space exposes five control decisions: simulation decision, simulation query, rollout verification, rollout reliance, and answer prediction. This trajectory makes failure points explicit, allowing the model to underuse useful simulation, accept misleading rollouts, or over-rely on weak rollouts.

The training process, referred to as Privileged-Future On-Policy Self-Distillation (PF-OPSD), separates format learning from utility calibration. In Stage 1, the student policy is initialized with protocol supervision from a Gemini-3.1-Pro + Agent workflow, which generates structured trajectories for each training example. This stage fixes the output protocol and is not used during inference. In Stage 2, the policy is calibrated using a teacher-side evaluator that observes the ground-truth future and answer only during training. The student generates a base trajectory under the student-view context, and at each decision node, a candidate set is built. Discrete nodes use the valid action set, while text nodes use samples from the current policy. Each candidate action is forced at the node, and the remaining trajectory is greedily completed. The privileged evaluator scores the resulting trajectory, and the student policy is updated using an advantage-weighted distillation objective. This on-policy design asks which alternatives would improve the student's own behavior, rather than imitating a fixed privileged trace.
At test time, the model follows a learned simulation-control policy with only the student-view state and a hard per-example retry cap. The first action gates simulation, and if simulation is needed, each attempt samples a prompt, queries the world model, and predicts a verification decision. Rejected or uncertain rollouts trigger another prompt only before the per-example cap is reached. After stopping, the model forms a reliance state and predicts the final answer. This formulation makes inference a closed-loop policy over simulation selection, rollout verification, retry, rollout reliance, and answering. The world model remains a fallible concrete-reasoning source: rejected rollouts are not discarded mechanically, but can be discounted in the reliance state when no accepted rollout is available.
Experiment
The method is evaluated on future-prediction benchmarks using a student model trained via structured self-distillation with an external world model, compared against zero-shot, supervised, and prompted baselines. Main results and ablation studies validate that learned simulation control and utility-calibrated supervision over intermediate reasoning steps are essential, as they consistently outperform static prompting or forced simulation. Qualitative diagnostics further confirm that the model selectively engages the world model for complex queries, reliably filters out misleading or low-quality rollouts, and effectively balances concrete evidence with abstract reasoning to maintain robust performance across varying data scales and rollout conditions.
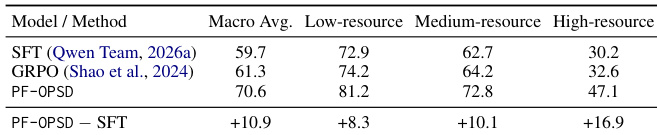
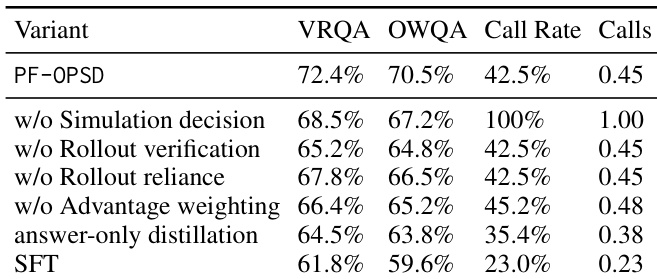
The authors evaluate PF-OPSD on two future-prediction benchmarks and find that it achieves the highest accuracy on both, outperforming various baselines. The results show that removing key components like rollout verification, reliance, or advantage weighting degrades performance, indicating that the gains come from calibrated supervision over intermediate reasoning actions rather than simply using generated rollouts. The model also demonstrates selective simulation usage, calling the world model less frequently than a baseline that simulates everything, while maintaining high accuracy. PF-OPSD achieves the highest accuracy on both benchmarks compared to all evaluated variants. Removing rollout verification, reliance, or advantage weighting significantly reduces performance, showing these components are crucial for the model's success. The model uses simulation selectively, with a lower call rate than a baseline that simulates everything, indicating effective control over when to use world-model rollouts.
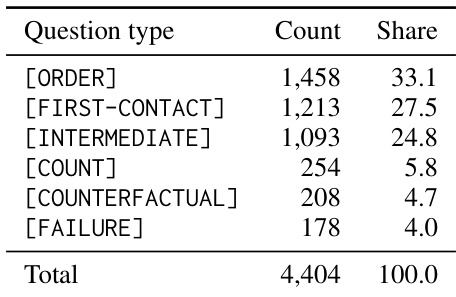
The authors analyze the distribution of question types in their benchmark, highlighting that order-related questions dominate the dataset, followed by first-contact and intermediate types, with smaller proportions of count, counterfactual, and failure cases. This distribution informs the evaluation of model performance across different reasoning demands. Order-related questions constitute the majority of the dataset, followed by first-contact and intermediate types. Count, counterfactual, and failure question types represent smaller portions of the dataset. The dataset includes a total of 4,404 questions across six distinct question types.
The authors evaluate PF-OPSD on two future-prediction benchmarks, demonstrating that it achieves higher accuracy than baseline methods by learning to select and verify simulations effectively. The model selectively invokes the world model, avoiding unnecessary calls while maintaining strong performance, and shows robustness across different world models and resource levels. PF-OPSD achieves higher accuracy than baselines by learning to make selective and reliable simulation decisions. The model reduces unnecessary simulation calls while maintaining strong performance, indicating effective simulation control. PF-OPSD maintains gains across different world models and resource levels, showing robustness and generalization.
The authors present an evaluation framework for future-prediction benchmarks, comparing PF-OPSD against various baselines including supervised fine-tuning and workflow-agent prompting. Results show that PF-OPSD achieves higher accuracy than all baselines on both benchmarks, with consistent improvements across different dataset categories and resource levels. The model demonstrates selective simulation usage, effectively avoiding unnecessary rollouts while maintaining high performance on challenging cases. PF-OPSD achieves higher accuracy than all baselines on both benchmarks, with consistent improvements across different dataset categories. The model selectively invokes the world model, avoiding unnecessary simulations while maintaining high performance on challenging examples. PF-OPSD shows strong performance across resource groups, including low-resource categories with fewer than 100 training examples.
The authors analyze rollout verification behavior under controlled conditions, showing that the model's acceptance rate decreases sharply as rollout quality degrades, while final accuracy remains relatively stable. The model demonstrates a nuanced ability to trust high-quality rollouts, reject misleading or inconsistent ones, and combine rollouts with static cues when they are complementary. This behavior indicates that the policy learns to calibrate reliance on concrete evidence based on its quality and relevance. The model's acceptance rate drops significantly as rollout quality degrades, from high for verified futures to very low for strongly corrupted rollouts. Final accuracy remains stable across different rollout conditions, suggesting the policy can fall back on abstract reasoning when rollouts are unreliable. The model effectively rejects misleading rollouts while still using them when they correct abstract reasoning errors.

Evaluated on two future-prediction benchmarks across diverse question categories and resource constraints, PF-OPSD consistently surpasses baseline methods by learning to selectively verify and integrate world-model simulations. Ablation experiments validate that components like rollout verification and advantage weighting are critical, confirming that accuracy improvements arise from calibrated supervision of intermediate reasoning rather than unverified rollout generation. Complementary analyses demonstrate that the model strategically restricts simulation calls while dynamically adjusting its reliance on rollout quality, effectively discarding inconsistent outputs and falling back on abstract reasoning when simulations degrade. Ultimately, the framework achieves robust generalization and superior predictive performance by mastering the selective and reliable use of simulated futures.