Command Palette
Search for a command to run...
Cosmos 3 : Modèles du monde omnimodaux pour l'IA physique
Cosmos 3 : Modèles du monde omnimodaux pour l'IA physique
Résumé
Nous présentons Cosmos 3, une famille de modèles de monde omnimodaux conçus pour traiter et générer conjointement le langage, les images, la vidéo, l'audio et les séquences d'actions au sein d'une architecture unifiée de type mixture-of-transformers. En supportant des configurations entrée-sortie hautement flexibles, Cosmos 3 unifie de manière transparente les modalités essentielles à l'IA physique, intégrant ainsi de facto les modèles vision-langage, les générateurs vidéo, les simulateurs de monde et les modèles monde-action dans un cadre unique. Nos évaluations démontrent que Cosmos 3 établit un nouvel état de l'art sur une gamme diversifiée de tâches de compréhension et de génération, confirmant les modèles de monde omnimodaux comme des architectures de base évolutives et polyvalentes pour les agents. Nos modèles Cosmos 3 post-entraînés ont été classés par Artificial Analysis comme les meilleurs modèles open-source Text-to-Image et Image-to-Video, et par RoboArena comme le meilleur modèle de politique au moment de la rédaction du rapport technique. Afin d'accélérer la recherche ouverte et le déploiement dans le domaine de l'IA physique, nous mettons à disposition notre code, les points de contrôle des modèles, les ensembles de données synthétiques soigneusement sélectionnés et le benchmark d'évaluation sous la licence OpenMDW-1.1 de la Linux Foundation's https://openmdw.ai/license/1-1/ sur https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos et https://huggingface.co/collections/nvidia/cosmos3 . Le site web du projet est disponible à l'adresse https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
One-sentence Summary
Cosmos 3 is a unified omnimodal world model employing a mixture-of-transformers architecture to jointly process and generate language, image, video, audio, and action sequences, unifying vision-language models, video generators, and simulators into a single flexible framework that achieves state-of-the-art performance across diverse understanding and generation tasks while serving as a scalable backbone for Physical AI agents.
Key Contributions
- Cosmos 3 introduces a unified mixture-of-transformers architecture that jointly processes and generates language, image, video, audio, and action sequences. The framework couples an autoregressive reasoning tower with a diffusion-based generation tower to support highly flexible input-output configurations for Physical AI.
- The model unifies multimodal understanding and generation within a single system using modality-specific encoders and structured token arrangements. This architecture enables one system to interpret environments, simulate physical dynamics, infer actions, and predict future observations without relying on separate specialized networks.
- Post-trained Cosmos 3 variants establish state-of-the-art performance across diverse understanding and generation benchmarks, ranking as the best open-source text-to-image, image-to-video, and robotic policy models. The release of source code, pre-trained checkpoints, curated synthetic datasets, and evaluation benchmarks under the OpenMDW-1.1 License accelerates open research in Physical AI.
Introduction
Physical AI agents must continuously perceive, reason about, and act within dynamic environments, yet training them directly in the real world remains prohibitively expensive and unsafe. Prior research has typically addressed these requirements through fragmented pipelines that stitch together isolated vision-language models, video generators, and action predictors. This architectural separation introduces computational inefficiencies and prevents the system from maintaining a coherent representation across perception and simulation. The authors leverage a unified Mixture-of-Transformers architecture to introduce Cosmos 3, an omnimodal world model that jointly processes and generates language, image, video, audio, and action sequences. By natively integrating understanding and generation within a single framework, the model eliminates the need for disjointed task-specific systems and establishes a scalable, state-of-the-art backbone for embodied AI research and deployment.
Dataset
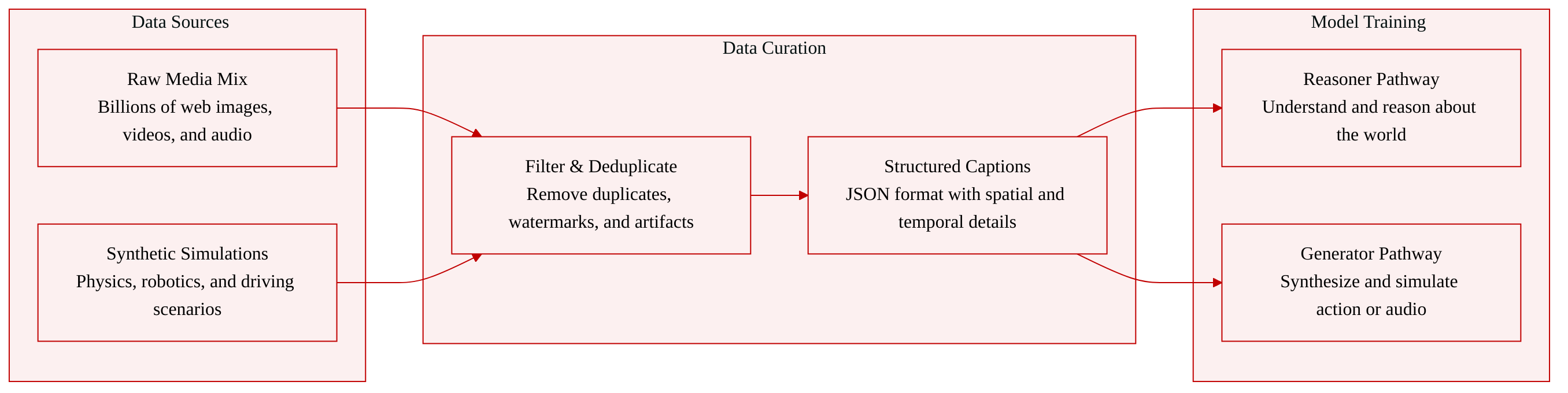
-
Dataset Composition and Sources: The authors build a massive multimodal corpus drawn from tens of billions of raw image and video candidates, split into two complementary pathways. The Reasoner pathway relies on paired vision language data, including web scale image text pairs, video text pairs, and text only conversations. The Generator pathway trains on large scale unannotated multimodal corpora covering images, videos, audio, and actions, supplemented by high fidelity synthetic simulations and control conditioned data.
-
Key Subset Details: The Reasoner contains approximately 24.2 million samples, divided into 22.0 million for pre training and 2.2 million for supervised fine tuning. The pre training stage emphasizes broad visual understanding, while fine tuning shifts to Physical AI domains like autonomous driving, robotics, and smart infrastructure, with video text samples making up half the mixture. Sources include LocateAnything, Nexar dashcam footage, MADS, MimicGen, BEHAVIOR 1K, and various internal logs. The Generator pre training utilizes 767 million images and 347.7 million video clips filtered from billions of raw sources. Mid training introduces a curated mix of 15.6 million images and 74.7 million videos, heavily weighted toward domain specific Physical AI scenarios and synthetic data. Audio is split into 12.8 million non speech clips and 6 million lip synced speech clips. The authors also release five large scale synthetic datasets covering physics interactions, robotics, driving, digital humans, and warehouse safety. Raw media undergoes embedding based deduplication using KMeans clustering, and quality filters remove collages, watermarks, NSFW content, and major artifacts like split screen or static videos. Audio clips are filtered through source separation, lip sync confidence scoring, and speech to music ratio thresholds.
-
Training Usage and Mixture Strategy: The authors employ a multi stage curriculum that evolves over time. The Reasoner starts with general vision language pre training before transitioning to specialized fine tuning. The Generator follows a pre training to mid training pipeline where the model learns general generation, then integrates action trajectories, control signals, and domain specific clips. Mid training tokens are distributed across 256p, 480p, and 720p resolutions within a fixed context window, with action losses scaled higher to balance normalized vector magnitudes. Post training uses a compact, high quality subset to close generation gaps without overfitting.
-
Processing, Cropping, and Metadata Construction: The pipeline begins by segmenting long videos into temporally consistent clips using scene change detection and removing black borders with standard video tools. The authors replace free form captions with a structured JSON annotation format generated by fine tuned vision language models. This structured metadata captures static attributes like lighting and composition, plus temporal fields for camera motion, actions, and state changes. For images, a quadrant scanning strategy ensures complex layouts are fully described. All data is processed through a scalable distributed infrastructure that handles sharding, metadata tracking, and embedding retrieval, ensuring consistent formatting across training stages.
Method
The authors leverage a unified architecture to enable Cosmos 3 to process multimodal inputs and generate multimodal outputs, treating language, vision, audio, and action as core modalities. The model's foundation is a Mixture-of-Transformers (MoT) backbone that processes a unified sequence of tokens from different modalities. This framework is designed to handle diverse tasks by organizing input tokens into a structured format, which is then processed by the MoT architecture. The overall model is composed of a reasoning path for language and visual understanding, and a generation path for producing video, audio, and action outputs.
The model's architecture begins with modality-specific encoders to project different inputs into a unified representation space. For vision, two separate encoders are used: a ViT encoder for understanding, which is jointly trained with the backbone, and a VAE encoder for generation, which is kept frozen. The ViT encoder uses a 16×16 patch size and aggregates visual features via DeepStack, while the VAE encoder compresses video temporally by 4× and spatially by 32×32. For audio, the model uses a frozen audio VAE architecture. For action, the model maps diverse embodiment controls into a unified action interface using a shared latent space, which enables consistent reasoning and generation across domains. This action representation uses a compact vector built from shared geometric components, such as 3D translation and 6D rotation for ego and effector poses, and grasp states for manipulation.
The input token sequence is organized into two distinct subsequences: an autoregressive (AR) subsequence and a diffusion (DM) subsequence. The AR subsequence, which contains language tokens and video/image tokens from the ViT encoder, is processed by a dedicated set of parameters in the transformer decoder layers for reasoning. The diffusion subsequence, which contains video/image tokens from the VAE encoder, as well as audio and action tokens, is processed by a separate parameter set for generation. This separation allows the model to support various tasks, such as language generation, text-to-image, and video-to-video, by arranging the tokens in a consistent format. For example, in text-to-image generation, the AR subsequence contains the language prompt, and the diffusion subsequence contains the noisy target image tokens.

The core of the architecture is the Mixture-of-Transformers (MoT) design, which features a dual-tower layer structure. Each transformer decoder layer contains two independent pathways: a reasoner tower and a generator tower. The reasoner tower processes the AR subsequence using standard causal self-attention, ensuring that each token only attends to preceding tokens in the same sequence. The generator tower processes the DM subsequence using full bidirectional attention, allowing each diffusion token to attend to the entire context, including the AR tokens. These two pathways interact through a dual-stream joint attention mechanism, where the generator tokens attend to the concatenated keys and values from both the AR and DM subsequences, while the AR tokens remain causally self-contained. This allows the model to condition the generation process on the reasoning context without violating the autoregressive property.

To manage the temporal and spatial structure of the multimodal inputs, the model employs a 3D Multimodal RoPE (MRoPE) positional embedding scheme. This scheme aligns video, audio, and action tokens along a shared physical temporal axis. For the AR subsequence, the position indices follow the standard 3D MRoPE design, with language tokens using a monotonically increasing index and ViT tokens varying on all three axes. For the diffusion subsequence, video tokens vary across all three axes (temporal, height, width), while audio and action tokens only carry temporal coordinates. To prevent over-saturation and artifacts, a fixed temporal gap is inserted between the AR and DM subsequences. The model further modulates the effective size of each temporal increment using FPS modulation, which aligns tokens with different temporal resolutions onto a shared physical axis by scaling the temporal step based on the base TPS. The model is trained at three scales—Edge, Nano, and Super—each built upon a dense transformer backbone with specific architectural hyperparameters.
Experiment
The evaluation framework assesses Cosmos 3 across a comprehensive suite of benchmarks spanning multimodal reasoning, image and video generation, spatial transfer, and robotics policy learning to validate its physical plausibility, temporal consistency, and real-world task execution. Experiments demonstrate that its unified omnimodal architecture consistently matches or surpasses specialized baselines, while carefully curated synthetic data effectively broadens domain coverage without compromising perceptual fidelity. Further ablation studies reveal that joint action training establishes a reusable cross-domain prior that significantly accelerates adaptation to new embodiments, and that the integrated reasoning tower substantially enhances the generator's physical-world understanding. Ultimately, the results confirm that a single foundation model can efficiently unify perception, simulation, and control for diverse physical AI applications.
The experiment section describes the evaluation of Cosmos 3 across various modalities and tasks, focusing on its performance in image and video generation, transfer generation, and action generation. The results show that Cosmos 3 achieves state-of-the-art performance in multiple benchmarks, particularly in video generation and action generation tasks, with strong performance in both open-source and closed-source models. The model's ability to handle diverse physical AI scenarios is highlighted, with significant improvements in domain-specific tasks such as robotics and autonomous driving. The evaluation also demonstrates the effectiveness of the unified architecture in enabling cross-domain adaptation and transfer learning. Cosmos 3 achieves state-of-the-art performance in video generation and action generation tasks, outperforming both open-source and closed-source models. The model shows strong domain-specific capabilities in robotics and autonomous driving, demonstrating its effectiveness in physical AI scenarios. Cosmos 3's unified architecture enables effective cross-domain adaptation and transfer learning, with significant improvements in task-specific performance.

The the the table compares the checkpoint save times for two models, Cosmos3-Nano and Cosmos3-Super, showing that Cosmos3-Super has higher mean, minimum, and maximum save times compared to Cosmos3-Nano. Cosmos3-Super also achieves a greater speedup over synchronous training than Cosmos3-Nano. Cosmos3-Super has higher checkpoint save times than Cosmos3-Nano across mean, minimum, and maximum metrics. Cosmos3-Super achieves a greater speedup over synchronous training compared to Cosmos3-Nano. Cosmos3-Nano has lower checkpoint save times and a smaller speedup compared to Cosmos3-Super.

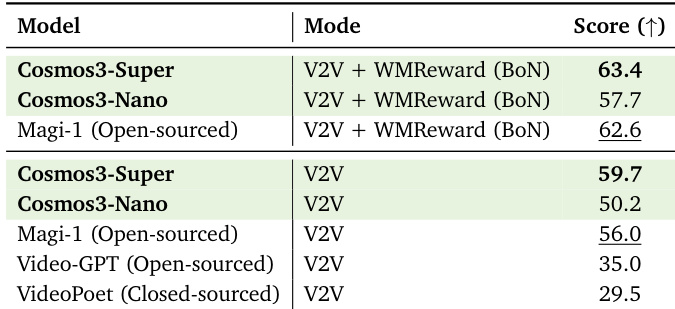
The the the table compares the performance of different models on a video-to-video generation task, with scores indicating their effectiveness. Cosmos3-Super achieves the highest score among the models listed, followed by Cosmos3-Nano, while open-sourced models like Magi-1 and Video-GPT show lower performance. The results suggest that the proposed models outperform existing open-sourced alternatives, with the larger model demonstrating superior capabilities. Cosmos3-Super achieves the highest score on the video-to-video generation task. Cosmos3-Nano outperforms open-sourced models such as Magi-1 and Video-GPT. The proposed models demonstrate superior performance compared to existing open-sourced alternatives.
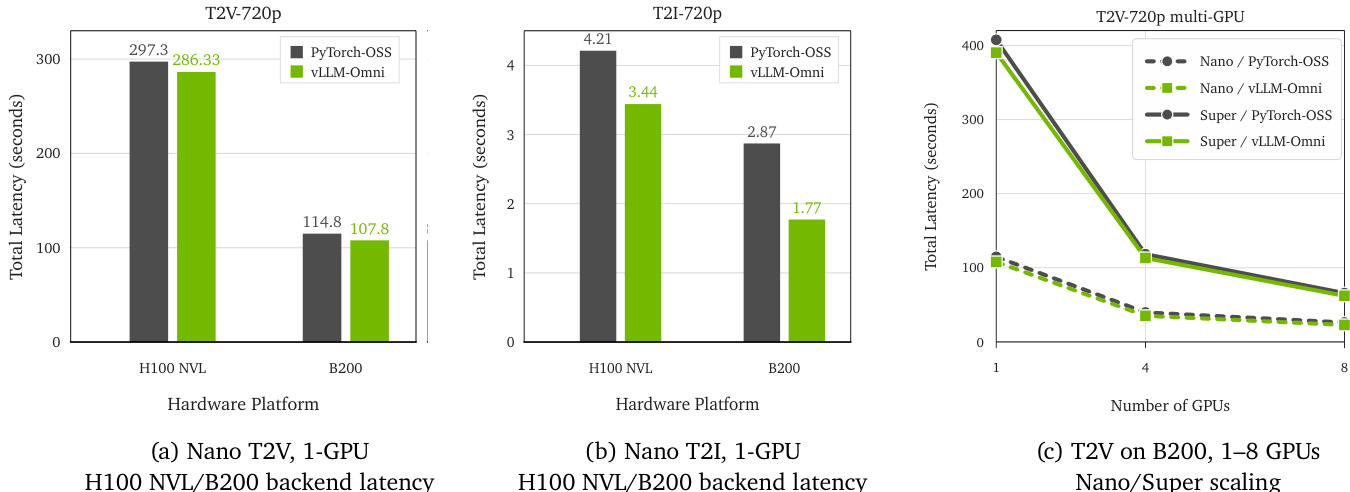
The the the table presents training throughput results for two model variants, Cosmos3-Nano and Cosmos3-Super, across different hardware backends and resolutions. Cosmos3-Super achieves significantly higher throughput compared to Cosmos3-Nano on all hardware configurations, with the most substantial gains observed on H100 80GB for both resolutions. The throughput is generally higher at 256 resolution than at 480 resolution for both models. Cosmos3-Super achieves substantially higher training throughput than Cosmos3-Nano across all hardware backends and resolutions. The throughput difference between the two models is most pronounced on the H100 80GB backend. Training throughput is consistently higher at 256 resolution than at 480 resolution for both model variants.

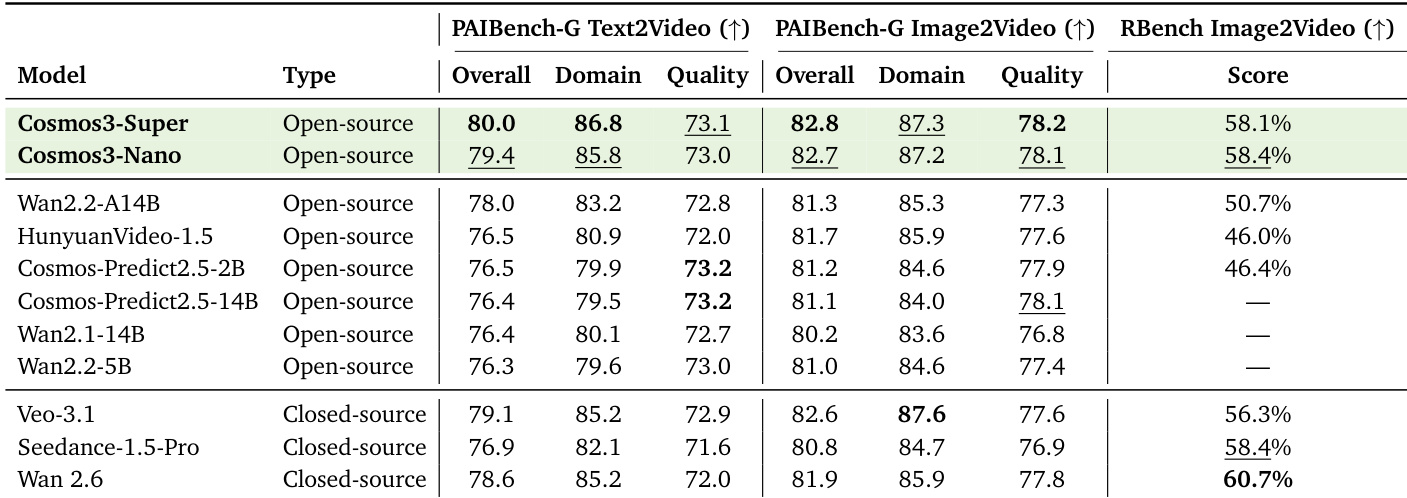
The the the table presents a comparison of video generation models on the PAIBench-G benchmark, evaluating both overall performance and domain-specific capabilities across various Physical AI tasks. Cosmos3-Super achieves the highest overall score and leads in most individual domains, while Cosmos3-Nano performs competitively, particularly in semantic alignment and visual integrity. The results highlight the strong performance of open-sourced models, with Cosmos3-Super outperforming closed-source models like Veo-3.1 and Seedance-1.5 in several key areas. Cosmos3-Super achieves the highest overall score and leads in most domain-specific categories, including semantic alignment and visual integrity. Cosmos3-Nano performs competitively, particularly excelling in semantic alignment and visual integrity, and is the best open-source model in the Human domain. Closed-source models like Veo-3.1 and Seedance-1.5 are outperformed by open-source models in several domains, with Cosmos3-Super achieving state-of-the-art results.
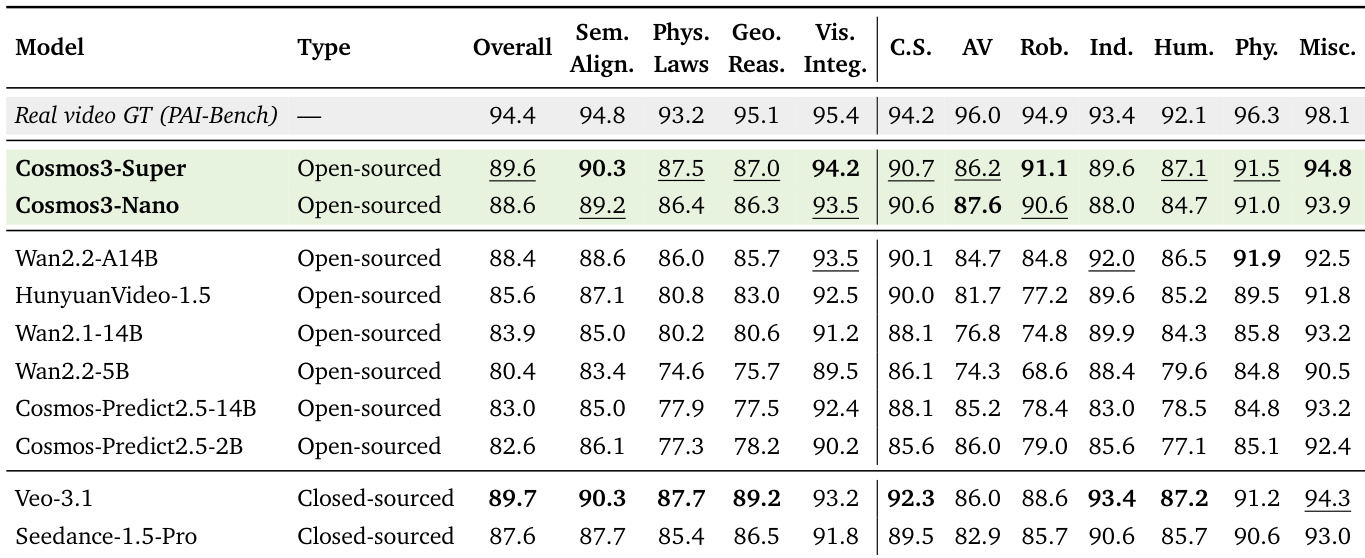
The evaluation examines the Cosmos 3 framework across video generation, action synthesis, and physical AI tasks to validate its cross-domain adaptability and computational efficiency. Results indicate that the unified architecture successfully facilitates transfer learning, with the larger model consistently delivering superior generation quality and training throughput compared to existing alternatives. Ultimately, these experiments demonstrate that the framework achieves state-of-the-art capabilities in complex physical AI scenarios while maintaining reliable scalability across diverse hardware configurations.