Command Palette
Search for a command to run...
K-BrowseComp : Un benchmark d'Agent de navigation web ancré dans des contextes coréens
K-BrowseComp : Un benchmark d'Agent de navigation web ancré dans des contextes coréens
Résumé
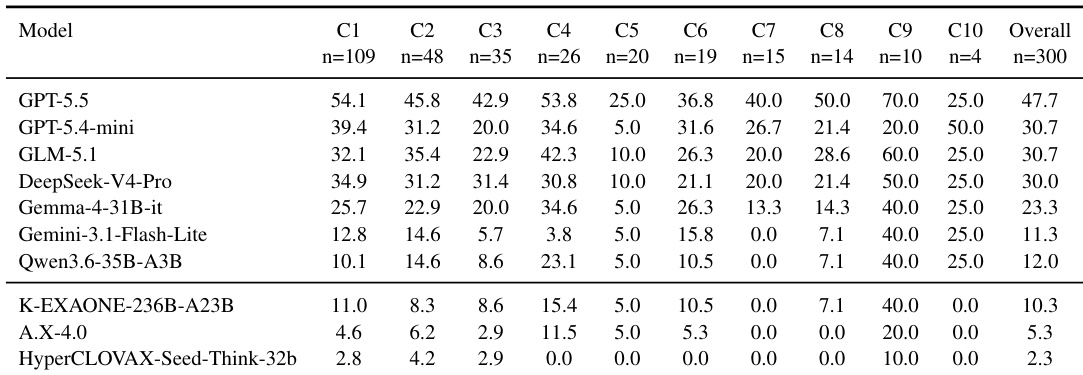
Les évaluations des modèles de pointe évoluent des capacités fondamentales (par exemple, le respect des instructions et le raisonnement) vers des capacités compositionnelles et agentiques, mais les benchmarks agentiques coréens restent rares. Nous présentons K-BrowseComp, un benchmark d'agent de navigation web ancré dans des contextes coréens, composé de 400 problèmes. Le sous-ensemble K-BrowseComp-Verified de 300 problèmes est construit manuellement et validé par des locuteurs natifs coréens. Sur ce sous-ensemble, les LLM de pointe, notamment GPT-5.5, DeepSeek-V4-Pro et GLM-5.1, n'atteignent que 30.00--45.67%, soit une baisse substantielle par rapport à BrowseComp, tandis que les LLM coréens publiés dans le cadre du programme Proprietary AI Foundation Model de la Corée n'obtiennent que 0.00--10.33%. Nous construisons en outre une partition synthétique de 100 problèmes en utilisant des exemples few-shot difficiles et une génération ciblée sur les modes d'échec, afin d'exploiter l'asymétrie entre la résolution et la création de problèmes de navigation web. Sur la partition diagnostique synthétique filtrée de manière adversariale, le modèle le plus performant n'atteint que 26.00%, et nous rapportons cette partition séparément en tant que test de contrainte ciblé. Nous mettons publiquement nos données et notre code à disposition.
One-sentence Summary
the paper introduce K-BROWSECOMP, a Korean-contextualized web-browsing agent benchmark comprising a 300-problem manually verified subset and a 100-problem SYNTHETIC split generated via hard few-shot exemplars and failure-mode-targeted generation, which demonstrates that frontier models including GPT-5.5, DeepSeek-V4-Pro, and GLM-5.1 achieve only 30.00–45.67% on the verified set and 26.00% on the synthetic split, while Korean models score between 0.00% and 10.33%.
Key Contributions
- This work introduces K-BROWSECOMP, a 400-task web-browsing agent benchmark grounded in Korean contexts that incorporates local search conventions, culturally specific clues, and multi-website navigation requirements.
- A synthetic task generation pipeline is developed that identifies recurring failure modes from human-verified questions and leverages hard few-shot exemplars to algorithmically construct adversarial, failure-targeted browsing problems.
- Evaluations on the 300-problem verified subset indicate that frontier models achieve 30.00 to 45.67 percent accuracy and Korean models achieve 0.00 to 10.33 percent accuracy. Performance on the adversarially filtered synthetic diagnostic split further restricts the strongest model to 26.00 percent accuracy.
Introduction
As frontier models shift toward compositional agentic evaluation, the Korean AI community lacks standardized tools to measure browsing capabilities, a gap that threatens local AI sovereignty and limits research on cross-lingual generalization. Prior evaluation frameworks remain anchored to static language tasks or rely on English-centric web benchmarks that overlook Korean search conventions, local entities, and cultural context. To bridge this divide, the authors introduce K-BROWSECOMP, a culturally grounded benchmark that tests how effectively models retrieve and synthesize region-specific information across multiple websites. The authors leverage a novel synthetic generation pipeline that combines human-verified failure modes with few-shot exemplars to produce challenging, verifiable tasks, establishing a robust diagnostic platform for developing Korean-tailored browsing agents.
Dataset
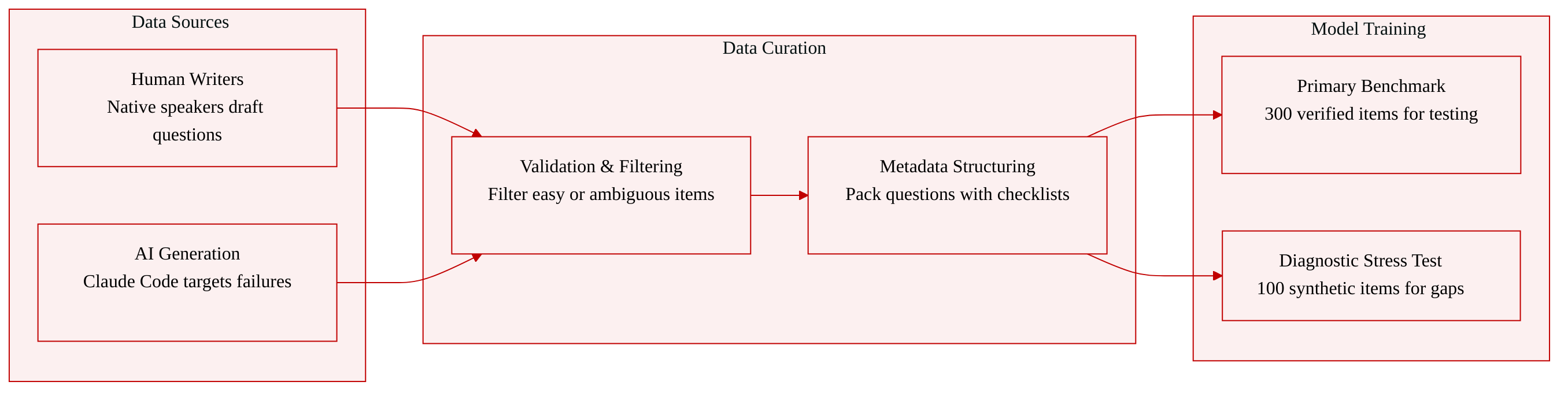
-
Dataset Composition and Sources
- The authors introduce K-BROWSECOMP, a 400-item benchmark designed to evaluate Korean web-browsing agents on hard-to-find public information. All items are grounded in Korean contexts and strictly sourced from publicly accessible, textual web pages. The dataset explicitly excludes private, paid, login-required, or non-textual sources like PDFs and images.
-
Subset Details
- K-BROWSECOMP-VERIFIED (300 items): Manually constructed by native Korean speakers and rigorously validated by the research team. Contributors follow strict guidelines requiring multi-hop or parallel-branching reasoning with at least four steps, unique and temporally stable answers, and answers that are difficult to find via direct search but easy to verify once located. The subset is evenly split between multi-hop (53.3%) and parallel-branching (46.7%) formats, with Entertainment and Media comprising the largest category (36.3%).
- SYNTHETIC (100 items): Generated using an AI agent (Claude Code) to create adversarial questions targeting specific model failure modes identified in the verified set. The generation pipeline uses seed pages and a nine-mode failure taxonomy, refining drafts through a draft, test, and revise loop. Each candidate passes three sequential filters: searchability (preventing direct answer exposure), well-formedness (ensuring the answer is uniquely extractable from the source), and adversarial difficulty (requiring baseline search-only models to fail). This split preserves the reasoning format balance but shifts category distribution toward Science, IT, and Academia (33.0%) and features longer prompts.
-
Data Usage and Processing
- The authors use the dataset exclusively for evaluation rather than model training. There are no training splits or mixture ratios. The verified subset serves as the primary benchmark for measuring frontier and Korean LLM performance, while the synthetic split is reported separately as a targeted diagnostic stress test. The authors analyze model trajectories to identify where failures occur, focusing on state maintenance, constraint tracking, and source pointer preservation rather than simple retrieval errors.
-
Metadata Construction and Processing Details
- All items are submitted and stored in a structured JSON format containing the problem statement, gold answer, expected reasoning trajectory, source URLs, Korean-specific keywords, and a rationale. The authors implement a checklist system to verify intermediate reasoning steps and validate evidence paths. A trajectory-level failure taxonomy (F1 to F8) is manually constructed from baseline model errors to guide synthetic generation and post-hoc analysis. For split diagnostics, the authors embed all questions using a multilingual sentence transformer and train classifiers to measure distributional shifts in question length, category, and reasoning format. No visual cropping is applied, as the benchmark operates entirely on textual evidence and reasoning trajectories.
Method
The authors leverage a multi-stage reasoning framework designed to address complex, multi-hop questions that require the integration of information across diverse sources and constraints. The model's operation is structured around a sequence of search and verification steps, where each stage involves retrieving candidate entities or evidence and applying logical constraints to refine the solution. At the core of this process is a trajectory-based approach, where the model generates a series of search queries guided by the required state, which specifies the necessary conditions for a correct answer. The framework distinguishes between the "gold trajectory," representing the ideal path to the solution, and the "model trajectory," which reflects the actual, often flawed, sequence of actions taken by the model.
The model begins by analyzing the question to identify the required state, which encapsulates the logical conditions that the final answer must satisfy. This state is then used to guide a series of search queries, each designed to retrieve relevant information or narrow down candidate sets. The model may perform multiple search branches in parallel, each targeting a different aspect of the problem. For example, in a question requiring the identification of a K-pop group, the model might first search for top-12 contestants and then verify their nationality and album release dates. However, the model's trajectory often deviates from the optimal path due to errors in constraint application or premature commitment to candidates. As shown in the figure below, the model may commit to a plausible candidate before all upstream constraints are verified, leading to a final answer that appears supported by local evidence but fails to satisfy the complete set of requirements.
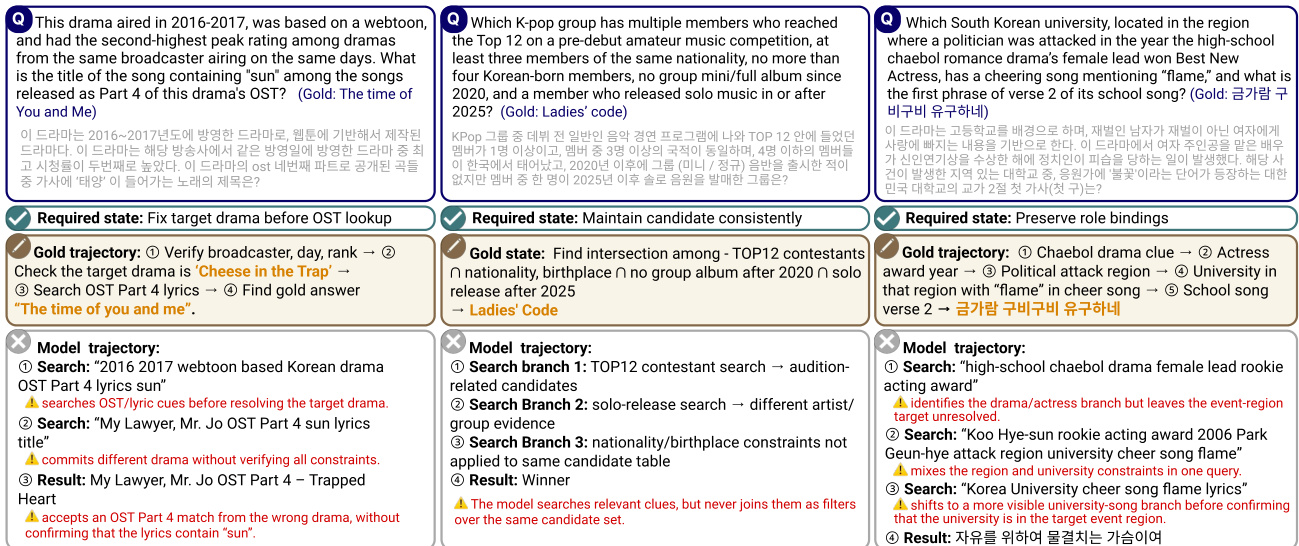
The model's search process is heavily influenced by the order in which it processes information. The framework is susceptible to failures when the model commits to a candidate based on partial evidence. For instance, if the model searches for award products before establishing the correct company and brand, it may be led down a plausible but incorrect path, resulting in a set of locally valid answers that do not meet the full constraint chain. This behavior is a key failure mode, where the model's trajectory is guided by the most salient or immediately accessible evidence, rather than a systematic verification of all required conditions. The model's trajectory is often marked by a series of search steps, each of which may introduce errors such as incorrect filtering, failure to join candidate sets, or miscomputing intermediate results, ultimately leading to an incorrect final answer.
Experiment
The evaluation utilizes a constrained deep-research agent to assess proprietary and open-weight models, including Korean-specialized variants, on the K-BROWSECOMP benchmark and a diagnostic synthetic split. Qualitative trajectory analysis demonstrates that performance bottlenecks stem primarily from post-retrieval failures, such as poor constraint tracking, premature candidate commitment, and unstable answer finalization, rather than insufficient search effort. While simpler domain queries are relatively manageable, complex multi-step reasoning consistently exposes weaknesses in long-horizon state maintenance across all model families. Ultimately, the experiments indicate that current large language models struggle to sustain coherent browsing trajectories, and Korean-focused architectures currently offer no distinct advantage over global counterparts in realistic web-search environments.
The authors evaluate a range of proprietary and open-weight models on a Korean web-browsing benchmark, with results showing that even high-performing models achieve low accuracy, particularly on a diagnostic synthetic split. Performance varies significantly across domains, with entertainment and sports questions being easier than science, IT, and education-related ones, and Korean open-weight models underperform compared to global counterparts. The analysis reveals that many failures occur after evidence retrieval, often due to issues in maintaining constraints, candidates, and role bindings across multiple steps. Performance on the benchmark remains low even for leading models, with accuracy dropping substantially on a diagnostic synthetic split. Entertainment and sports categories are easier than science, IT, and education, indicating domain-specific challenges in web browsing. Many errors occur after retrieval, with models failing to maintain consistent candidate, constraint, and role states across steps.
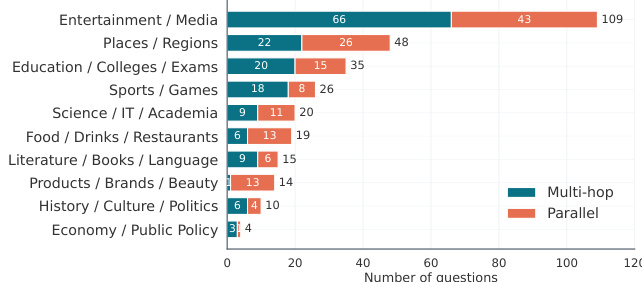
The authors evaluate a range of proprietary and open-weight models on a Korean web-browsing benchmark, assessing performance across multiple categories and failure modes. Results show that while top-performing models achieve high accuracy on certain domains, most models struggle with complex, multi-step reasoning and evidence integration, particularly in the Korean context. Top-performing models achieve high accuracy on some categories but show significant variation across different domains. Many models fail to maintain consistent evidence and constraints across multiple search steps, even after retrieving relevant information. Korean open-weight models underperform global counterparts, indicating challenges in long-horizon reasoning and state maintenance despite specialized training.
The authors evaluate a set of proprietary and open-weight models on a web-browsing benchmark, focusing on performance and search-effort patterns. Results show that models often fail to maintain consistent state across multiple steps, even after retrieving relevant evidence, and that higher search usage on incorrect trials indicates failures in reasoning and finalization rather than insufficient retrieval. Korean open-weight models underperform global counterparts, with issues related to state maintenance and answer stabilization. Models frequently fail after retrieving relevant evidence, with errors arising from losing track of constraints and candidates across steps. Incorrect trials generally use more search calls than correct ones, suggesting failures occur during reasoning and finalization rather than retrieval. Korean open-weight models show significant performance gaps compared to global models, with issues in maintaining trajectory state and producing well-formed answers.
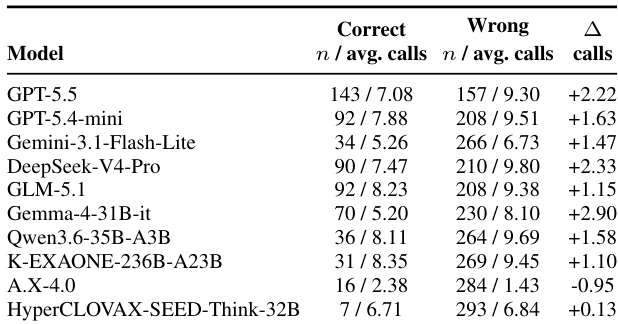
The authors evaluate a range of closed and open-weight models on a Korean web-browsing benchmark, with results showing that proprietary models significantly outperform open-weight models, especially in the verified subset. Performance on a synthetic split remains low across all models, indicating persistent challenges in maintaining consistent evidence integration and finalizing answers. Korean open-weight models exhibit notable shortcomings in trajectory-level reasoning despite specialized training, with failures often arising after relevant evidence has been retrieved. Proprietary models achieve substantially higher accuracy than open-weight models on the verified subset, with the highest-performing model reaching over 45% pass@1. All models show significantly reduced performance on the synthetic split, indicating challenges in maintaining consistent reasoning and evidence integration. Korean open-weight models underperform global counterparts, with failures often occurring after retrieval due to issues in constraint tracking and answer finalization.
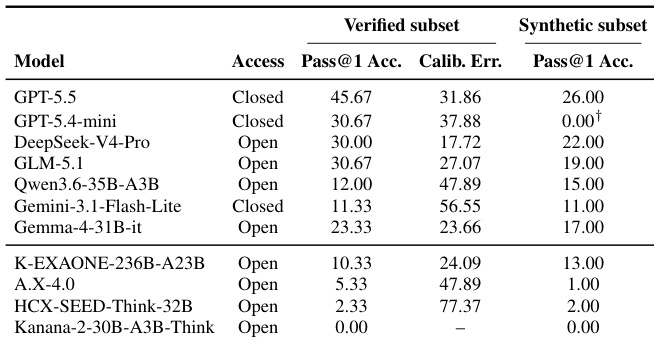
The experiments evaluate proprietary and open-weight models on a Korean web-browsing benchmark to validate their multi-step reasoning, evidence integration, and state maintenance capabilities across diverse domains. Qualitative analysis reveals that performance varies significantly by topic, with entertainment and sports proving easier than technical fields, while most errors occur after relevant evidence is retrieved due to difficulties in tracking constraints and maintaining consistent reasoning states. Ultimately, proprietary models substantially outperform open-weight alternatives, which consistently struggle with long-horizon trajectory management and answer finalization despite specialized training.