Command Palette
Search for a command to run...
Distillation par région de confiance sur politique
Distillation par région de confiance sur politique
Xingrun Xing Haoqing Wang Boyan Gao Ziheng Li Yehui Tang
Résumé
La Distillation On-Policy (OPD) est une technique fondamentale pour le post-entraînement efficace des grands modèles de langage (LLM), avec de larges applications dans l'apprentissage d'agent, l'amélioration multi-tâches et la compression de modèle. Cependant, l'entraînement OPD devient instable lorsque les distributions du professeur et de l'élève diffèrent considérablement, car la supervision du professeur sur les tokens générés par l'élève peut produire des gradients de politique peu fiables et même entraîner un échec de l'optimisation. Ce travail traite de la supervision fiable au niveau du token on-policy via des stratégies d'attribution de crédit, et propose la Distillation On-Policy à Région de Confiance, TrOPD. Elle présente les caractéristiques suivantes : 1) Apprentissage On-Policy à Région de Confiance : TrOPD effectue l'OPD uniquement dans les régions où le professeur fournit une supervision fiable, atténuant la difficulté d'optimisation de l'estimateur K1 reverse-KL en cas d'inadéquation de distribution. 2) Estimation des valeurs aberrantes : Pour les régions aberrantes, nous explorons le clipping de gradient, le masquage et l'estimation forward-KL afin de réduire les effets néfastes d'une supervision peu fiable. 3) Guidance Off-Policy : L'élève poursuit la génération à partir des préfixes du professeur et utilise le forward KL pour imiter la guidance off-policy, encourageant l'exploration on-policy vers des régions fiables. Les expériences montrent que TrOPD surpasse systématiquement les méthodes de référence OPD SoTA, y compris OPD, EOPD et REOPOLD, sur les tâches de raisonnement mathématique, de génération de code et les benchmarks de domaine général.
One-sentence Summary
The authors propose Trust Region On-Policy Distillation (TrOPD), a framework that stabilizes large language model post-training by restricting on-policy distillation to regions of reliable teacher supervision, mitigating outlier impacts via gradient clipping and forward-KL estimation, and leveraging teacher prefixes for off-policy guidance to encourage robust on-policy exploration.
Key Contributions
- The paper establishes a unified benchmark for reasoning-oriented on-policy distillation that evaluates mathematics, code generation, instruction following, and STEM reasoning tasks under consistent training settings. This framework implements memory-efficient K1 and top-k KL estimators to demonstrate that conventional methods fail to suppress erroneous policy gradients during distribution mismatch.
- The work introduces Trust Region On-Policy Distillation (TrOPD), which partitions student-generated tokens into trust regions and outliers based on the decoding agreement ratio with the teacher model. By restricting optimization to reliable supervision zones and applying a top-k forward-KL estimator for outliers, the method mitigates unstable policy gradients caused by distribution shifts.
- Empirical evaluations on DeepSeek-Qwen2.5-1.5B and Qwen3-SFT-1.7B demonstrate that the framework improves reasoning performance by up to 6.18 points across mathematics, code generation, instruction following, and STEM benchmarks. The approach enables stable post-training of compact reasoning models while maintaining optimization under practical memory constraints.
Introduction
The authors leverage on-policy distillation to train small reasoning models that replicate the complex chain-of-thought capabilities of large reasoning models while drastically reducing inference costs. Prior methods, however, suffer from training instability because student-generated trajectories frequently drift outside the teacher model's reliable supervision region, producing erroneous policy gradients and triggering training collapse. To resolve this, the authors introduce Trust Region On-Policy Distillation, which partitions tokens by evaluating teacher-student decoding agreement to isolate reliable supervision regions. They stabilize the learning process by applying a top-k forward-KL estimator to preserve informative signals from outliers and integrate off-policy imitation guidance, ultimately establishing a unified benchmark that demonstrates substantial performance gains across mathematics, code generation, and STEM reasoning tasks.
Method
The authors leverage a three-part framework to address the instability of on-policy distillation (OPD) in language models, particularly when the student and teacher distributions diverge significantly. The overall architecture is designed to ensure reliable token-level supervision by distinguishing between trustworthy and unreliable regions of the student's output distribution. As shown in the figure below, the framework is divided into three main components: Trust-Region On-Policy Learning, Outlier Estimation, and Off-Policy Guidance, each addressing a specific challenge in the optimization process.
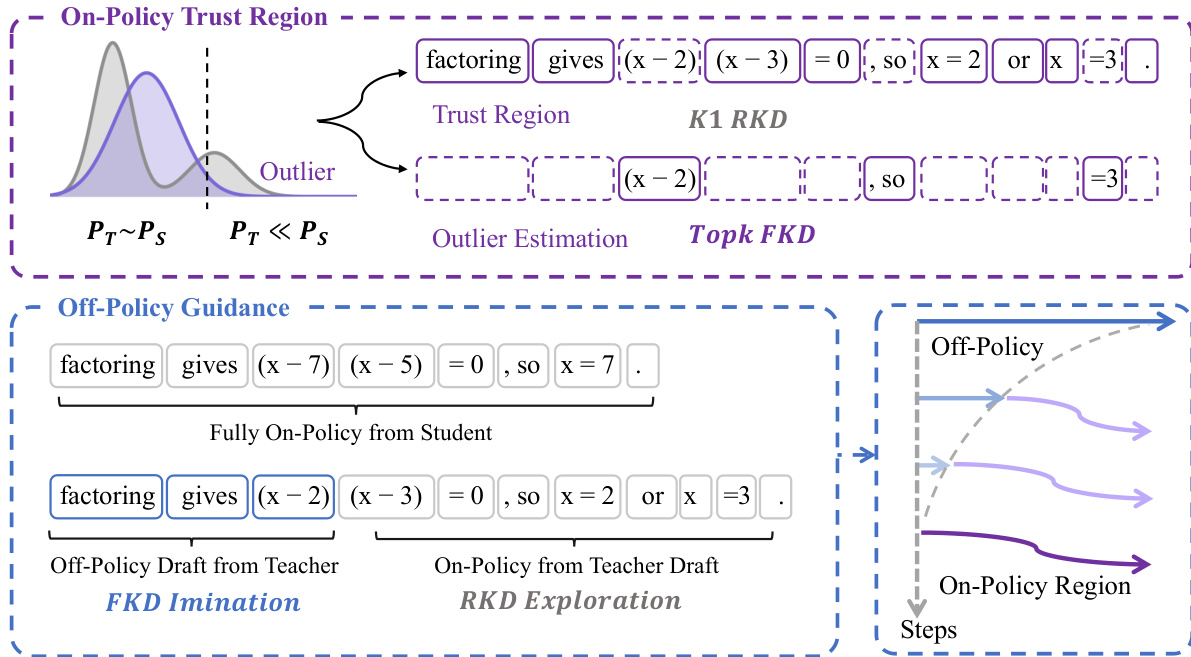
The first component, Trust-Region On-Policy Learning, restricts distillation to regions where the student's policy distribution is close to the teacher's, i.e., where PT≈PS. In these regions, the K1 reverse-KL estimator provides a stable and unbiased gradient signal, enabling effective policy optimization. The framework identifies this trust region by comparing the probability distributions of the teacher and student, ensuring that distillation only proceeds where the teacher can provide reliable supervision. This mitigates the optimization difficulty associated with the K1 estimator, which otherwise suffers from extreme negative gradients when the student generates sequences in low-probability regions of the teacher.
The second component, Outlier Estimation, handles regions where the student distribution diverges from the teacher's, i.e., PT≪PS. In these outlier regions, the policy gradients become unreliable and can destabilize training. To address this, the framework employs gradient clipping, masking, and forward-KL estimation to reduce the influence of these adverse signals. Forward-KL estimation is particularly effective in these regions, as it penalizes the student for generating sequences that the teacher does not support, providing a more stable and informative gradient signal compared to reverse-KL.
The third component, Off-Policy Guidance, encourages the student to explore trajectories that are supported by the teacher. This is achieved by having the student generate from teacher prefixes, allowing it to imitate off-policy guidance. The student continues generation from these prefixes using forward-KL to imitate the teacher's behavior, which encourages on-policy exploration toward reliable regions. This mechanism helps the student overcome the limitation of low-quality student-of-generation (SoG) trajectories, as it enables the student to access higher-quality responses that are not part of its own policy distribution.
Together, these components form a robust and stable framework for on-policy distillation, ensuring that the student receives reliable supervision and can effectively learn from the teacher's policy. The integration of trust-region optimization, outlier handling, and off-policy guidance enables the framework to overcome the key bottlenecks of existing OPD methods, leading to improved performance across various domains.
Experiment
The experiments benchmark off-policy distillation methods under unified single-domain and multi-domain reasoning settings to assess their stability, generalization, and effectiveness under constrained vocabulary constraints. Evaluations of divergence objectives reveal that standalone top-k forward KL produces distorted gradients, while analyses of filtering and clipping strategies show that entropy-based selection and reward clipping yield inconsistent benefits due to hyperparameter sensitivity. Ablation studies and comparative tests validate that the proposed TrOPD framework consistently outperforms baselines across mathematical, STEM, and code tasks by effectively leveraging outlier-aware token selection and trust-region learning. Ultimately, the results demonstrate that robust distillation for long-thinking models requires careful outlier management and complementary optimization strategies, with combined approaches offering promising directions for future improvements.
The authors evaluate various OPD methods under a unified setting, focusing on their performance in single- and multi-domain distillation tasks. Results show that TrOPD consistently outperforms baseline methods across different configurations, with improvements in both mathematical reasoning and general-domain tasks, while also demonstrating compatibility with complementary approaches like AOPD. TrOPD achieves consistent performance gains over baseline methods across single- and multi-domain distillation tasks. TrOPD outperforms methods that rely on reward clipping or entropy-based token selection, indicating the effectiveness of outlier-aware optimization. Combining TrOPD with AOPD further improves performance, suggesting complementary benefits from different optimization strategies.

The authors analyze the effectiveness of different divergence objectives and optimization strategies in off-policy distillation (OPD) for long-thinking reasoning models. They evaluate methods based on trust-region learning and outlier estimation, comparing their performance across single-domain and multi-domain distillation tasks. Results show that trust-region approaches outperform existing methods that rely on entropy-based filtering or reward clipping, and that combining trust-region learning with off-policy guidance leads to consistent improvements. Trust-region learning methods outperform entropy-based filtering and reward clipping in off-policy distillation. Outlier-aware token selection provides better performance than entropy-based selection for training. Combining trust-region learning with off-policy guidance leads to consistent improvements across different distillation settings.

The authors evaluate various outlier estimation and off-policy guidance methods in the context of OPD for reasoning models, focusing on their impact on performance across mathematical and general reasoning tasks. Results show that incorporating outlier-aware strategies and off-policy guidance leads to consistent improvements over baseline methods, with the proposed TrOPD framework outperforming existing approaches in both single- and multi-domain distillation settings. Outlier-aware methods such as FKL-based outlier estimation improve performance over baseline and filtering strategies in OPD. TrOPD with off-policy guidance consistently outperforms standard OPD and other advanced methods across different distillation configurations. Combining TrOPD with concurrent AOPD objectives yields further performance gains, indicating complementary benefits between different optimization strategies.
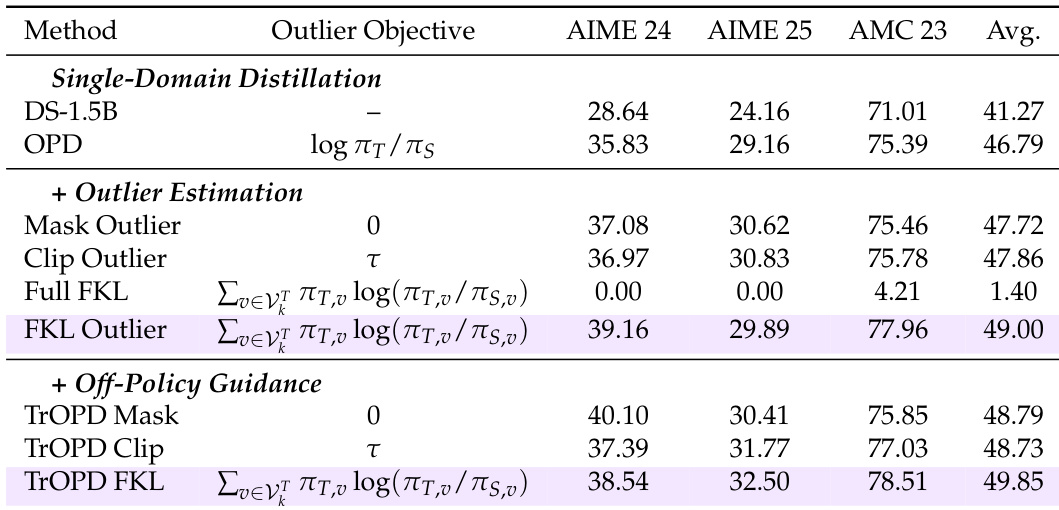
The authors evaluate various OPD methods under a unified setting, focusing on their effectiveness in single-domain and multi-domain reasoning tasks. Results show that TrOPD consistently outperforms baseline methods across different domains and student models, with notable improvements in mathematical reasoning and generalization. The effectiveness of outlier-aware token selection is highlighted, particularly through the use of FKL in outlier regions, while combining TrOPD with AOPD further enhances performance. TrOPD consistently outperforms baseline methods across mathematical and general reasoning tasks. Outlier-aware token selection using FKL in outlier regions proves more effective than entropy-based filtering or reward clipping. Combining TrOPD with AOPD leads to further performance improvements, indicating complementary benefits of different optimization strategies.
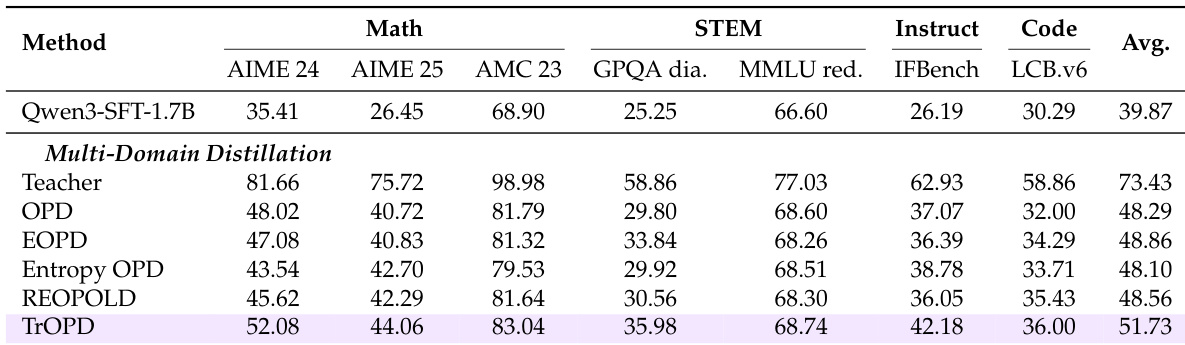
The authors evaluate various OPD methods under single-domain and multi-domain distillation settings, focusing on mathematical reasoning and general-domain tasks. Results show that TrOPD consistently outperforms baseline methods across different configurations, demonstrating the effectiveness of trust-region learning and outlier-aware token selection. The combination of TrOPD with AOPD further improves performance, indicating complementary benefits of different optimization strategies. TrOPD outperforms existing OPD methods in both single-domain and multi-domain distillation settings. Outlier-aware token selection in TrOPD provides better performance than entropy-based or reward clipping strategies. Combining TrOPD with AOPD leads to further improvements, suggesting complementary benefits of different optimization approaches.
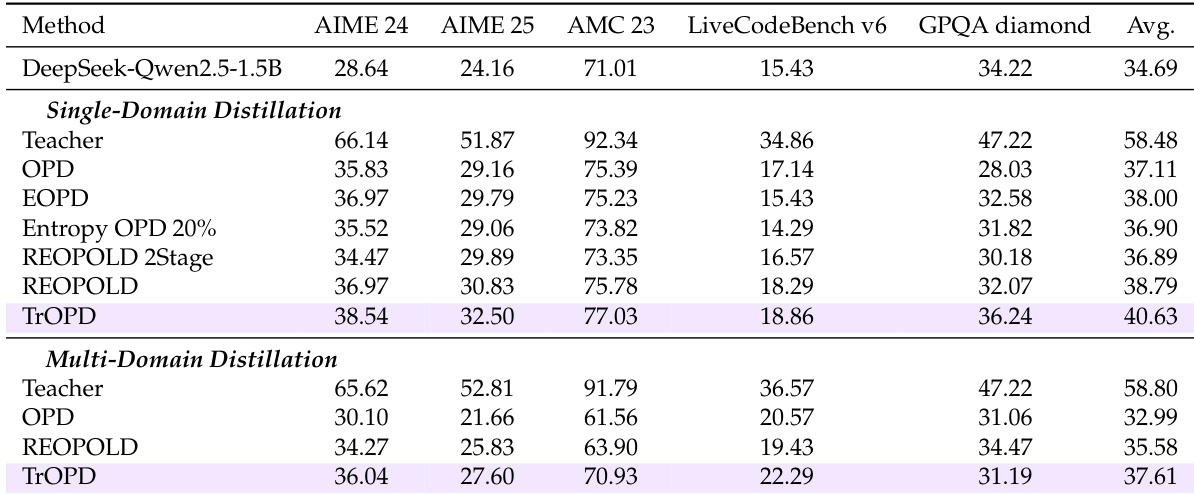
The authors evaluate various off-policy distillation methods under a unified framework across single- and multi-domain tasks, focusing on mathematical and general reasoning performance. The experiments validate that the proposed TrOPD framework consistently outperforms baselines relying on entropy-based filtering or reward clipping, primarily through effective trust-region learning and outlier-aware token selection. Furthermore, integrating TrOPD with AOPD yields additional gains, demonstrating the complementary value of combining distinct optimization strategies and establishing outlier-aware distillation as a robust approach for training long-thinking reasoning models.