Command Palette
Search for a command to run...
COLLEAGUE.SKILL : Génération automatisée de compétences d'IA via la distillation des connaissances d'expert
COLLEAGUE.SKILL : Génération automatisée de compétences d'IA via la distillation des connaissances d'expert
Tianyi Zhou Dongrui Liu Leitao Yuan Jing Shao Xia Hu
Résumé
Les agents LLM sont de plus en plus appelés à non seulement accomplir des tâches isolées, mais également à porter des représentations bornées de l'expertise humaine, du jugement et du style d'interaction. La conception de tels agents ancrés sur une personne demeure difficile, car les connaissances actionnables associées à un individu ou à un rôle sont généralement enfouies dans des traces hétérogènes plutôt que formalisées sous forme d'instructions claires. Les systèmes de mémoire et de persona existants capturent des fragments de ces éléments, tandis que les cadres de compétences proposent des formats d'emballage portables ; toutefois, aucun flux de travail de bout en bout ne permet actuellement de distiller ces traces en compétences inspectables, correctables et exploitables par les agents. Nous présentons un système automatisé de distillation de traces vers compétences afin de générer des compétences d'IA ancrées sur une personne, par le biais de la distillation de connaissances expertes. À partir de matériaux fournis par une personne cible ou un rôle spécifique, COLLEAGUE.SKILL génère un package de compétences versionné comportant deux volets coordonnés : un volet de capacités dédié aux pratiques, aux modèles mentaux et aux heuristiques de décision, et un volet de comportement borné consacré au style de communication, aux règles d'interaction et à l'historique des corrections. Ce package peut être inspecté, invoqué, mis à jour grâce à des retours en langage naturel, annulé, déployé sur des hôtes d'agents, et éventuellement préparé pour une distribution contrôlée. Nous décrivons le contrat d'artefact, le flux de travail de génération, le cycle de vie des corrections, la surface de déploiement et les préréglages par domaine implémentés dans ce système open source. Au moment de la rédaction, le dépôt public compte environ 18,5 k étoiles sur GitHub ; la galerie répertorie 215 compétences issues de 165 contributeurs, totalisant plus de 100 k étoiles cumulées sur les fiches de compétences listées. Ce système illustre comment les compétences ancrées sur une personne peuvent être représentées sous la forme de packages portables et correctables, plutôt que comme des prompts opaques ou des mémoires cachées.
One-sentence Summary
The authors propose COLLEAGUE.SKILL, an automated expert knowledge distillation system that converts heterogeneous traces from a target person into a versioned skill package containing a capability track for decision heuristics and a bounded behavior track for interaction rules, enabling the package to be inspected, updated through natural-language feedback, and installed across agent hosts.
Key Contributions
- The paper introduces COLLEAGUE.SKILL, an automated trace-to-skill distillation system that converts heterogeneous human interaction traces into portable, person-grounded AI skills.
- The method generates a versioned skill package with two coordinated tracks that explicitly separate operational capabilities (practices, mental models, and decision heuristics) from bounded behavioral constraints (communication style, interaction rules, and correction history).
- The system provides a transparent workflow that supports package inspection, natural-language feedback, state rollback, and installation across agent hosts to ensure distilled skills remain editable, portable, and accountable across deployment environments.
Introduction
As LLM agents evolve from executing isolated instructions to carrying reusable expertise, the field is rapidly adopting modular skill architectures that package domain knowledge and interaction patterns for on-demand deployment. However, transforming unstructured human traces, such as chat logs, documents, and public records, into structured agent capabilities remains a significant hurdle. Prior memory and persona systems typically fragment this evidence or rely on opaque prompts that lack provenance, correction mechanisms, and clear usage boundaries. The authors leverage an automated distillation pipeline to bridge this gap with COLLEAGUE.SKILL, a system that converts heterogeneous human traces into versioned, portable skill packages. By explicitly separating operational capabilities from bounded behavioral constraints, the framework enables users to inspect, correct, rollback, and deploy person-grounded skills across multiple agent hosts while maintaining full transparency over source material and distribution limits.
Dataset

- Dataset Composition and Sources: The authors construct a person-grounded skill ecosystem centered on public figures, drawing primarily from first-person works, long-form interviews, documented decisions, and clearly marked inferences. The corpus is further expanded through community contributions to the COLLEAGUE.SKILL platform.
- Subset Details: While exact subset sizes are not specified, the data is organized around a dedicated celebrity preset and modular community skills. Each entry is filtered to prioritize substantive, long-form material while explicitly excluding short summaries and low-quality content aggregators.
- Data Usage and Training: The authors leverage this curated dataset for public-source expert distillation. During inference, the system tracks evidence availability and automatically downgrades confidence scores when source material is sparse, preventing the model from filling gaps with generic persona text. The pipeline supports iterative creation, versioned corrections, and transparent public distribution.
- Processing and Metadata Construction: The preprocessing workflow automates subtitle extraction, audio transcription, and text cleanup before merging research notes. A dedicated quality checker evaluates each artifact for mental-model coverage, stylistic patterns, internal contradictions, grounding URLs, and copyright compliance. All evidence constraints and quality metrics are packaged as explicit metadata that accompanies the final distributed outputs.
Method
The authors leverage a structured pipeline for person-grounded skill distillation, designed to transform heterogeneous human traces into a portable, inspectable, and governable skill artifact. The core framework, referred to as COLLEAGUE.SKILL, operates through a sequence of well-defined stages: trace intake, preset routing, dual distillation, artifact writing, and productization. As shown in the figure below, the process begins with trace intake, where raw materials such as work documents, chat logs, review comments, or public interviews are collected and stored locally. These inputs are then routed through a preset router, which selects the appropriate domain-specific configuration—such as colleague, celebrity, or relationship—based on the source type and governance assumptions. The selected preset defines the evidence scope, access controls, and invocation semantics. 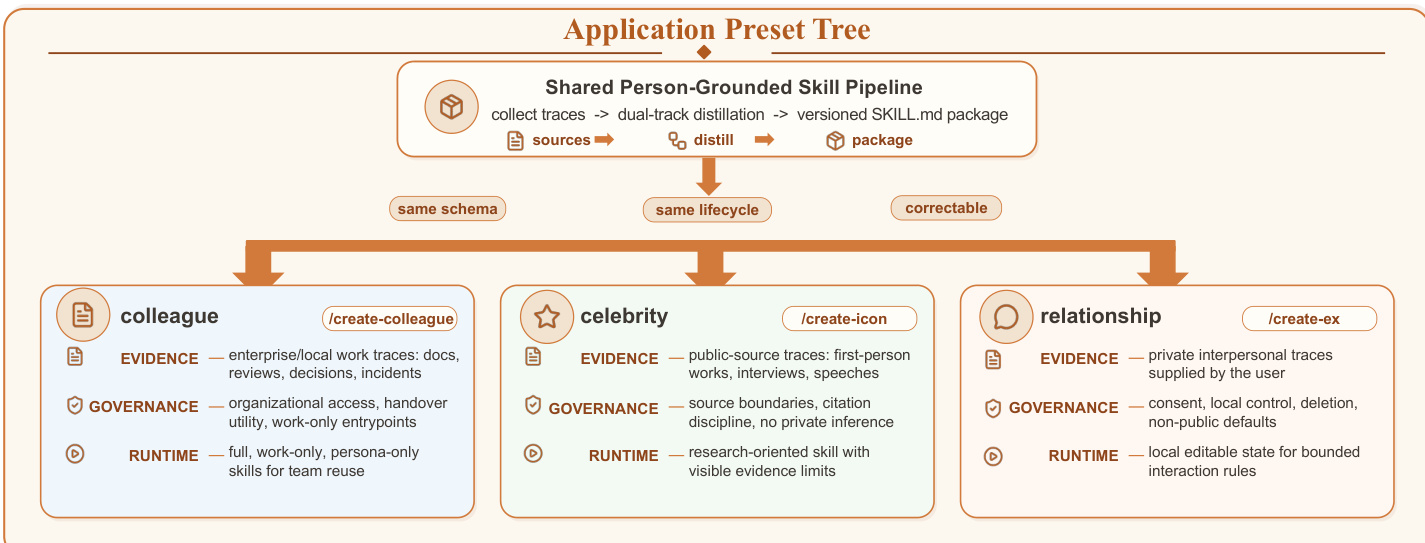
Following routing, the dual distillation stage separates the skill into two distinct tracks: a capability track and a persona track. The capability track captures durable mental models, procedural judgment, and technical standards derived from the source material, while the persona track encodes bounded behavior constraints, interaction rules, and expression preferences. This separation ensures that the generated skill maintains a clear distinction between expert judgment and surface behavior, enabling separate invocation of full, capability-only, or persona-only entrypoints. The dual representation is central to the system's design, preventing conflation of factual knowledge with interaction style and supporting composability and correctness. 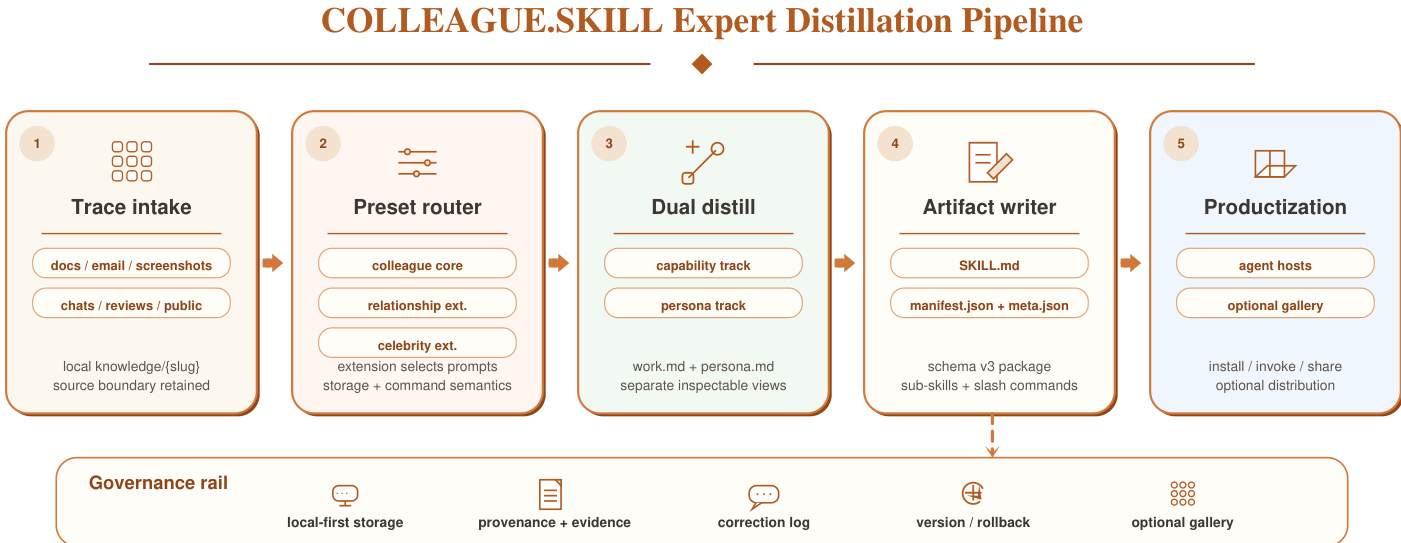
The distilled tracks are then processed by the artifact writer, which normalizes metadata into a versioned schema and renders the final skill package. This package includes a primary SKILL.md file that combines both tracks, alongside separate work.md and persona.md source documents, independently invokable sub-skills, and metadata files such as manifest.json and meta.json. The writer ensures alignment with the Agent Skills standard, where SKILL.md serves as the required entrypoint and optional files provide scripts or references. The resulting artifact is a self-contained, versioned package that can be installed into supported agent hosts, shared via an optional gallery, or modified through correction records. 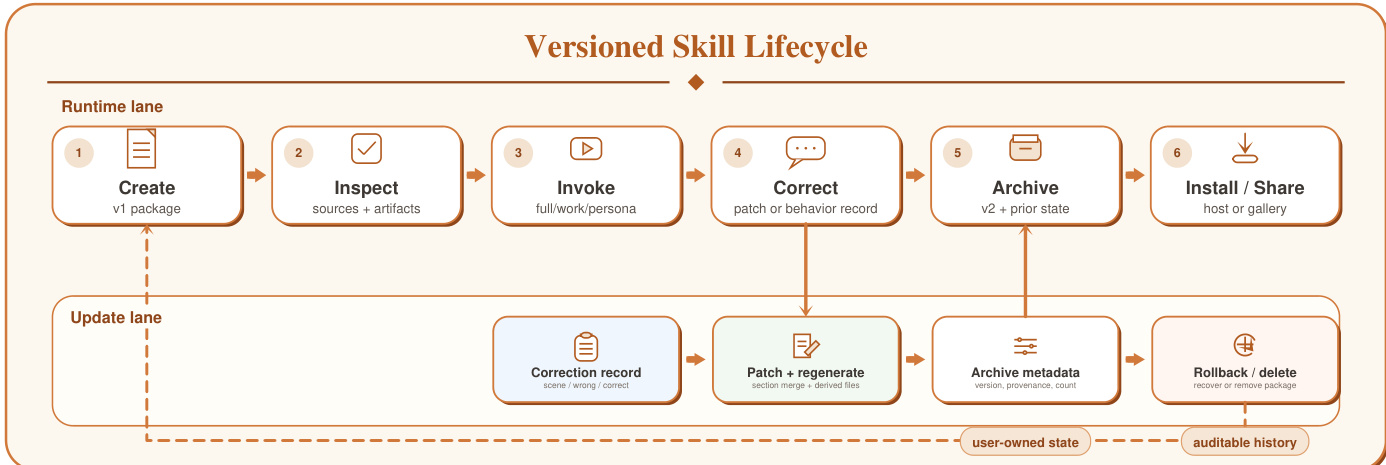
The system supports a comprehensive lifecycle for skill management, including correction, rollback, and optional distribution. Corrections are processed through a handler that interprets natural-language feedback and generates either a Markdown patch for capability updates or a structured correction record for behavior adjustments. These changes trigger a regeneration of the artifact, incrementing the lifecycle version and preserving the prior state. The version manager enables listing, backing up, rolling back, and cleaning archives, ensuring that the artifact remains auditable and correctable over time. This lifecycle is supported by a governance rail that enforces local-first storage, provenance tracking, and user-owned correction logs, making the entire process transparent and accountable.