Command Palette
Search for a command to run...
Le mise à jour du harnais n'est pas un bénéfice du harnais : dissocier les capacités d'évolution dans les Agents LLM auto-évoluants
Le mise à jour du harnais n'est pas un bénéfice du harnais : dissocier les capacités d'évolution dans les Agents LLM auto-évoluants
Résumé
Les agents LLM sont de plus en plus déployés sous la forme de systèmes s’appuyant sur des harnais externes modifiables, incluant prompts, compétences (skills), mémoires et outils, qui façonnent l’exécution des tâches sans modifier les paramètres du modèle. L’auto-évolution de ces harnais permet d’adapter les agents en mettant à jour ces composants à partir des preuves tirées de l’exécution. Cependant, il reste incertain si la capacité fondamentale d’un modèle à résoudre des tâches prédit sa capacité à l’auto-évolution des harnais : quels modèles produisent des mises à jour utiles des harnais et lesquels en tirent réellement bénéfice ?Nous analysons deux capacités liées à l’auto-évolution des harnais : (i) la capacité de mise à jour des harnais (harness-updating), qui désigne la capacité à générer, à partir des preuves d’exécution, des mises à jour persistantes et utiles des harnais ; et (ii) la capacité à bénéficier des harnais mis à jour (harness-benefit), qui désigne la capacité à tirer parti de ces harnais mis à jour lors de la résolution de tâches.Nos analyses révèlent deux constats. Premièrement, la capacité de mise à jour des harnais est indépendante de la capacité de base : les modèles issus de différents niveaux de capacité produisent des mises à jour de harnais conduisant à des gains surprenamment similaires ; ainsi, les mises à jour générées par Qwen3.5-9B aboutissent à des performances comparables à celles obtenues avec Claude Opus 4.6. Deuxièmement, la capacité à bénéficier des harnais mis à jour présente une relation non monotone avec la capacité de base : les modèles de niveau faible tirent peu avantage des harnais mis à jour, les modèles de niveau intermédiaire en tirent le plus grand bénéfice, tandis que les modèles de niveau avancé en bénéficient moins que ceux de niveau intermédiaire.Nous attribuons les faibles gains observés au niveau faible à deux modes d’échec : les modèles de niveau faible peuvent ne pas activer les artefacts de harnais pertinents, ou bien les activer sans les suivre fidèlement. Ces résultats suggèrent d’orienter les investissements en termes de capacité vers l’agent de résolution de tâches plutôt que vers le module d’évolution, et de cibler l’invocation des harnais ainsi que le respect fidèle des instructions sur le long horizon lors de l’entraînement des agents. Notre code source est publiquement disponible à l’adresse suivante.
One-sentence Summary
This analysis disentangles harness-updating from harness-benefit in self-evolving LLM agents to reveal that harness-updating yields similar gains across tiers, with Qwen3.5-9B updates yielding gains comparable to those of Claude Opus 4.6, whereas harness-benefit is non-monotonic with mid-tier models benefiting most, suggesting capability budgets should prioritize task-solving agents over evolvers.
Key Contributions
- This work introduces a controlled capability analysis framework that separates harness-updating from harness-benefit to measure these capabilities separately. The methodology varies agents and evolvers independently to isolate specific capabilities rather than conflating end-to-end gains.
- Experiments demonstrate that harness-updating capability remains flat across base model tiers, producing similar gains regardless of underlying model size. Results show that updates from smaller models like Qwen3.5-9B yield performance improvements comparable to those from stronger models like Claude Opus 4.6.
- The analysis reveals that harness-benefit capability follows a non-monotonic pattern where mid-tier models benefit most while weak-tier models fail to activate or follow harness artifacts faithfully. These findings suggest prioritizing the task-solving agent over the evolver and targeting harness invocation and long-horizon instruction following in agent training.
Introduction
Large language model agents increasingly rely on editable external harnesses such as prompts, tools, and memory to shape behavior without updating model weights. While harness self-evolution allows these systems to adapt by refining artifacts based on execution evidence, prior evaluations often conflate the agent's base performance with the quality of updates and the agent's ability to utilize them. The authors disentangle these factors by distinguishing between harness-updating, the ability to produce useful artifacts, and harness-benefit, the ability to leverage them during task solving. Their analysis reveals that updating capability remains consistent across model tiers while benefit capability peaks at mid-tier levels, suggesting developers should prioritize investing in the task-solving agent rather than the evolver.
Dataset
- Dataset Composition: The authors evaluate on three benchmarks: SWE-bench Verified for software engineering, MCP-Atlas for tool use over real servers, and SkillsBench for skill-based execution.
- Subset Details: SWE-bench Verified contains 500 human-validated tasks from 12 Python repositories where patches must pass hidden tests. MCP-Atlas includes 500 tasks requiring orchestration across 36 servers using a claims-based scoring rubric. SkillsBench offers 86 tasks across 11 domains with deterministic verifiers.
- Evaluation Protocol: The team employs an in-situ setting where tasks are scored under the previous harness before evidence updates the current one. Pass rate is the primary metric aggregated over the task stream.
- Processing and Constraints: Harness editing is benchmark-specific. SWE-bench and SkillsBench restrict edits to the skills directory while MCP-Atlas allows changes to prompts and memory files. All models use fixed prompt templates and evolution budgets to maintain fair comparison.
Method
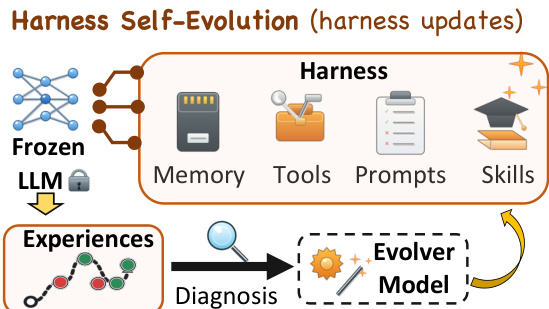
The authors leverage a harness self-evolution protocol designed to adapt an LLM agent by updating the external harness surrounding a fixed model during task execution. In this framework, the agent attempts a stream of tasks, and the harness is iteratively updated based on the agent's execution evidence. This approach distinguishes between the parametric model backbone and the non-parametric context, allowing for continuous improvement without retraining the underlying LLM.
Refer to the framework diagram to visualize the overall architecture. The system consists of a Frozen LLM connected to a dynamic Harness containing Memory, Tools, Prompts, and Skills. The process operates as a closed loop: execution experiences are gathered and subjected to Diagnosis, which feeds into an Evolver Model. The Evolver Model then generates updates that modify the Harness components, such as injecting new skills or refining prompts, to better handle future tasks.
Formally, at evolution step t, the agent is defined as At=(f,Ht), where f represents the fixed model backbone and Ht denotes the harness state. The system adheres to a protocol where f remains constant while editable components of Ht (e.g., prompts, skills, memories) are updated. The evolver e functions as the update procedure that converts execution evidence into harness modifications. Given the previous harness Ht−1 and accumulated execution evidence Dt, the evolver proposes an update ΔHt and applies it to obtain the next harness state:
ΔHt=e(Ht−1,Dt),Ht=Apply(Ht−1,ΔHt).The evolution protocol follows an iterative loop over T steps. At each step, the agent At−1 attempts to solve a batch of tasks Xt, outputting execution trajectories τt,x and final outputs yt,x. The evidence Dt is collected from these interactions, and the evolver produces the updated harness Ht for the subsequent step.
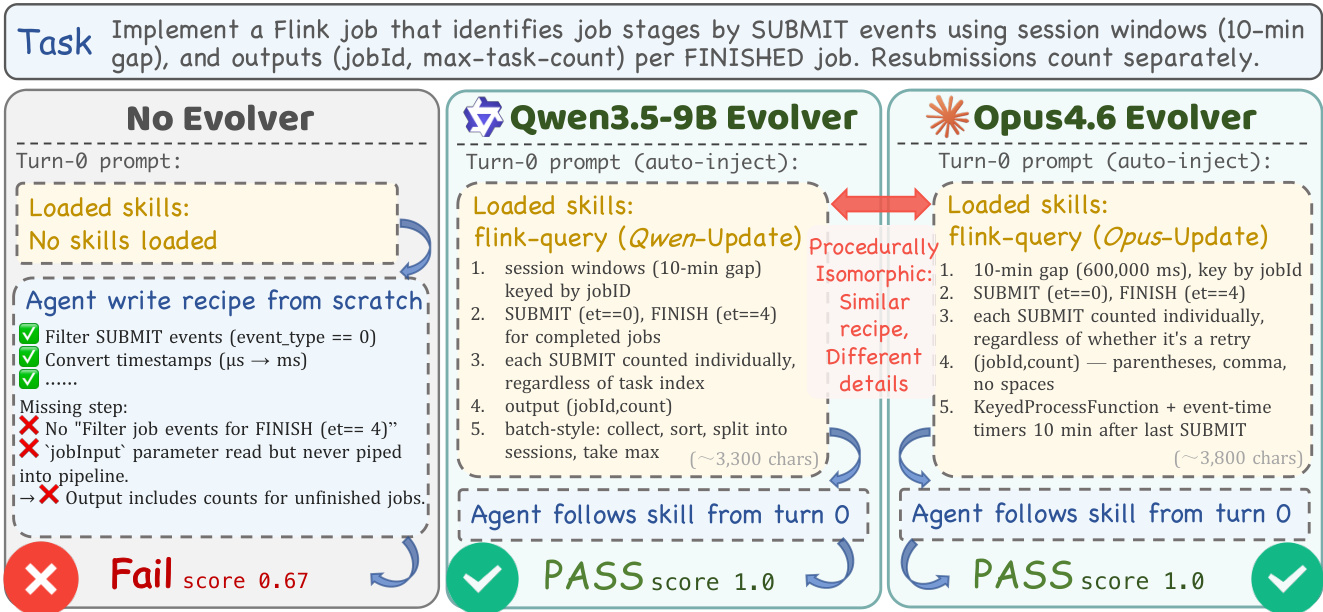
As shown in the figure below, the practical application of this method involves the evolver diagnosing failures and injecting specific procedural skills into the harness. The comparison illustrates a scenario where an agent without an evolver fails to complete a Flink job task due to missing steps. In contrast, agents utilizing a Qwen3.5-9B or Opus4.6 Evolver successfully pass the task. This success is attributed to the evolver auto-injecting a flink-query skill into the loaded skills list. The figure highlights that while different evolver models may produce procedurally isomorphic recipes with similar logic, the specific details and phrasing of the injected skills differ, yet both lead to a successful outcome where the base agent would have failed.
Experiment
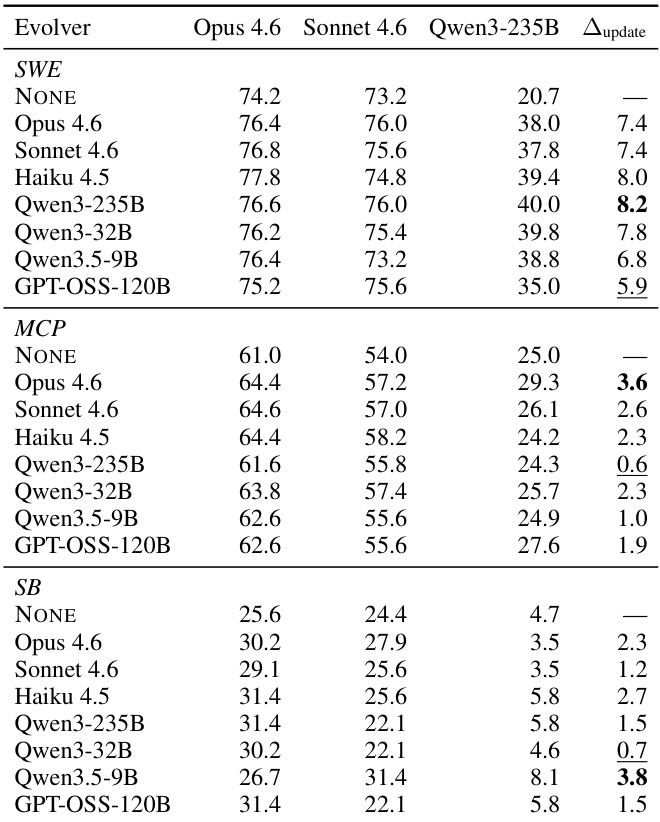
This study evaluates harness self-evolution across seven LLMs and three agentic benchmarks by decoupling harness-updating, where models generate improvements from execution evidence, from harness-benefit, where models utilize those updates during task solving. Experiments reveal that harness-updating capability is independent of base model strength, while harness-benefit follows a non-monotonic pattern where mid-tier models gain the most and weaker models struggle due to failures in activating artifacts or adhering to guidance. These findings suggest that system design should prioritize investing capability in the task-solving agent and training it to reliably invoke and follow external harness instructions.
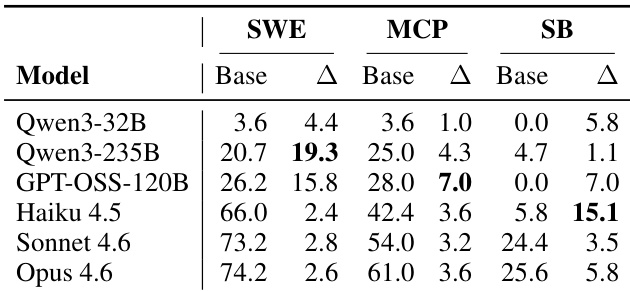
The authors evaluate harness-updating capability by pairing various evolver models with fixed task-solving agents across three benchmarks. Results indicate that the ability to generate useful harness updates is relatively consistent across different model tiers, with no single evolver dominating all tasks. Furthermore, the final system performance is driven more by the base capability of the task-solving agent than by the specific evolver model used. Harness-updating gains remain stable across evolver capability tiers, showing that smaller models can produce updates comparable to larger ones. No evolver model consistently outperforms others across all benchmarks, indicating a reshuffling of effectiveness depending on the task domain. The base capability of the task-solving agent is the dominant factor in post-evolution performance, while the evolver identity contributes less variance.
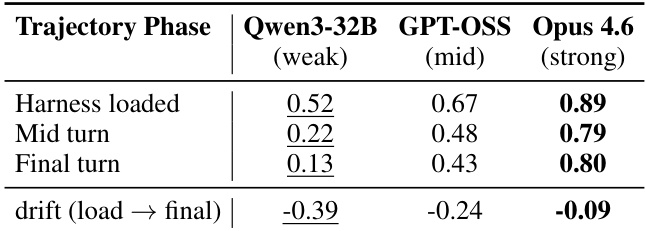
The authors analyze per-phase adherence scores to diagnose why weak-tier models derive low benefit from harness updates. The results show that while strong models maintain stable adherence throughout task execution, weaker models suffer from significant drift as the trajectory unfolds. This indicates a long-horizon instruction-following bottleneck where adherence decays much more steeply for weaker models compared to their stronger counterparts. Strong models maintain the highest adherence scores across all trajectory phases. Weak models exhibit the largest negative drift in adherence from loading to the final turn. Mid-tier models show moderate adherence decay, falling between weak and strong model performance.
The authors analyze agent-side capabilities in harness self-evolution by measuring activation, adherence, and success rates across models of varying capabilities. The data reveals that weaker models suffer from both low skill-load rates and poor adherence to loaded instructions, whereas stronger models consistently activate and follow harness artifacts. Notably, mid-capability models show high activation rates but struggle with adherence, indicating that loading a skill does not guarantee effective utilization. Weak-tier models exhibit significantly lower skill-load rates compared to strong-tier models, failing to activate harness artifacts in the majority of trajectories. Strong-tier models demonstrate superior adherence to loaded skills, maintaining high following rates while weaker models often deviate from instructions. A disparity exists between activation and adherence for mid-tier models, where high skill-load rates do not necessarily translate to high instruction-following performance.
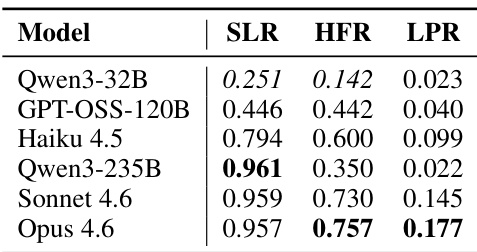
The authors analyze harness-benefit capability across seven LLMs and three benchmarks to determine which models benefit most from updated agent harnesses. Results indicate that the improvement from harness evolution is non-monotonic with respect to base model capability, where mid-tier models show the largest gains while both weaker and stronger models benefit less. This pattern suggests that weak models struggle to activate or adhere to harness instructions, whereas strong models face diminishing returns due to performance ceilings. Mid-tier models demonstrate the highest improvement from harness evolution compared to weaker or stronger counterparts. Stronger models experience limited gains as they approach performance ceilings on the benchmarks. Weaker models fail to leverage harness updates effectively due to difficulties in activating and following procedural guidance.
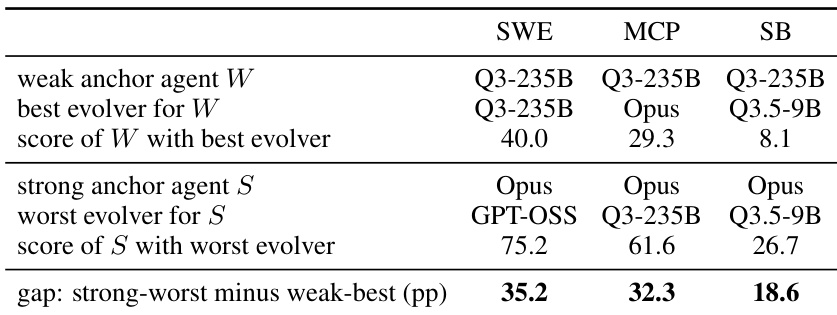
The authors analyze extreme pairings where the strongest task-solving agent uses its worst evolver and the weakest agent uses its best evolver. Results indicate that the strong agent consistently outperforms the weak agent by a significant margin across all benchmarks, demonstrating that the agent's base capability is the primary determinant of post-evolution performance. Strong agents maintain a substantial performance lead over weak agents even when paired with their least effective evolvers. The performance gap favors the strong agent across all tested benchmarks, highlighting the dominance of agent capability over evolver quality. Results suggest that optimizing the task-solving agent yields greater returns than optimizing the model responsible for generating harness updates.
The authors evaluate harness-updating capabilities by pairing various evolver models with fixed task-solving agents across multiple benchmarks. Findings reveal that the base capability of the task-solving agent is the primary determinant of performance, outweighing the specific evolver model used. Although mid-tier models benefit most from harness evolution, weaker models struggle with instruction adherence while stronger models face diminishing returns, indicating that optimizing the agent yields greater returns than refining the evolver.