Command Palette
Search for a command to run...
VLM3 : Les modèles de langage visuels sont des apprenants natifs en 3D
VLM3 : Les modèles de langage visuels sont des apprenants natifs en 3D
Zhipeng Cai Zhuang Liu Yunyang Xiong Zechun Liu Vikas Chandra Yangyang Shi
Résumé
Les modèles de langage et de vision (Vision Language Models, VLMs) permettent à un modèle unifié de résoudre diverses tâches de vision grâce à l’utilisation de prompts. Ils ont démontré des performances prometteuses en matière de compréhension sémantique. Cependant, la compréhension tridimensionnelle (3D) repose encore largement sur des modèles de vision experts, dont la conception est complexe et spécifique à chaque tâche. La thèse principale de ce travail est que les VLMs sont des apprenants natifs de la 3D. Notre étude approfondie à grande échelle montre que trois éléments suffisent pour un apprentissage 3D efficace : 1) l’unification de la longueur focale, 2) la référence pixelique basée sur le texte et 3) le mélange des données et leur mise à l’échelle (scaling). Les modifications de l’architecture du modèle, l’utilisation de modèles volumineux, les fortes augmentations de données et les pertes complexes, y compris la formulation par régression, qui constituent souvent la base des modèles de vision experts, ne sont en réalité pas des conditions nécessaires. Nous proposons donc VLM^3, une méthode évolutive et au design le plus simple possible, permettant aux VLMs standard de maîtriser une grande variété de tâches 3D. VLM^3 améliore significativement la précision de l’estimation de la profondeur des VLMs (passant de 0,84 à 0,9), tout en permettant la réalisation de diverses tâches 3D telles que la correspondance pixelique, l’estimation de la pose de la caméra et la compréhension 3D au niveau des objets, atteignant ainsi les performances des modèles de vision experts tout en conservant des architectures standards et un entraînement basé sur le texte. Nous estimons que VLM^3 ouvre la voie à un nouveau paradigme pour un apprentissage 3D simple et évolutif.
One-sentence Summary
The authors propose VLM3, a scalable method demonstrating that vision language models are native 3D learners through focal length unification, text-based pixel reference, and data mixture and scaling, advancing depth estimation accuracy from 0.84 to 0.9 and enabling pixel correspondence, camera pose estimation, and object-level 3D understanding while matching expert vision model accuracy using standard architectures and text-based training.
Key Contributions
- A large-scale study establishes that focal length unification, text-based pixel reference, and data mixture scaling are sufficient for effective 3D learning. This finding challenges the necessity of expert vision model foundations such as architecture changes, heavy data augmentations, and complex regression losses.
- The proposed VLM^3 enables standard VLM architectures to handle diverse 3D tasks through focal length resizing to 1000 pixels and normalized text-based pixel referencing within [0, 2000). This approach avoids extra encoders or task-specific modules by relying on standard text-based training procedures.
- Experimental results show the method advances VLM depth estimation accuracy from 0.84 to 0.9 while matching expert vision model performance on tasks including pixel correspondence and camera pose estimation. Object-level 3D understanding is also achieved alongside these capabilities without requiring complex task-specific designs.
Introduction
Understanding 3D geometry from 2D inputs is central to visual intelligence, yet Vision Language Models (VLMs) have traditionally underperformed in fine-grained tasks compared to specialized expert models. Prior research either focuses on coarse object-level understanding or relies on complex task-specific architectures and losses that compromise standard VLM compatibility. The authors demonstrate that VLMs are inherently capable of 3D learning and propose VLM3 to unlock this potential without modifying model structures. They leverage focal length unification, text-based pixel references, and data scaling to enable standard VLMs to match expert accuracy on diverse tasks including depth estimation and camera pose. This approach eliminates the need for heavy data augmentations or regression losses while maintaining a scalable design.
Method
The authors propose VLM3, a scalable framework designed to enable standard Vision-Language Models (VLMs) to master diverse 3D understanding tasks without requiring complex architectural modifications. The core philosophy relies on solving fundamental ambiguities in 3D data through preprocessing and prompt engineering rather than designing task-specific heads or losses.
A primary component of this method is focal length unification. To address the camera ambiguity problem often found in 3D vision, the framework resizes input images so that their focal length is standardized to 1000 pixels. This preprocessing step allows for effective mixed-data training across diverse sources. Unlike previous approaches that required rendered visual markers to reference specific pixels, VLM3 employs a text-based reference strategy. By normalizing the pixel space to a range of [0,2000) for both horizontal and vertical axes, the model can understand and generate precise pixel coordinates through natural language prompts. As illustrated in the architecture comparison below, VLM3 (c) avoids the need for extra modules or rendered markers found in prior object-level methods (a) and DepthLM (b).

This text-based approach significantly improves efficiency and scalability. It allows multiple questions to be packed for the same image during training without duplicating inputs, enabling the model to learn from 10 labeled pixels per sample instead of just one with negligible overhead. Furthermore, the framework leverages data mixture and scaling as a critical ingredient. The authors find that simply scaling up training data with appropriate weighting based on dataset size is often more effective than complex data augmentations or architectural tweaks.
The framework is demonstrated across four distinct 3D tasks: object-level 3D understanding, metric depth estimation, pixel correspondence estimation, and camera pose estimation. Refer to the task performance breakdown below, which highlights how VLM3 achieves competitive accuracy against expert vision models across these domains.
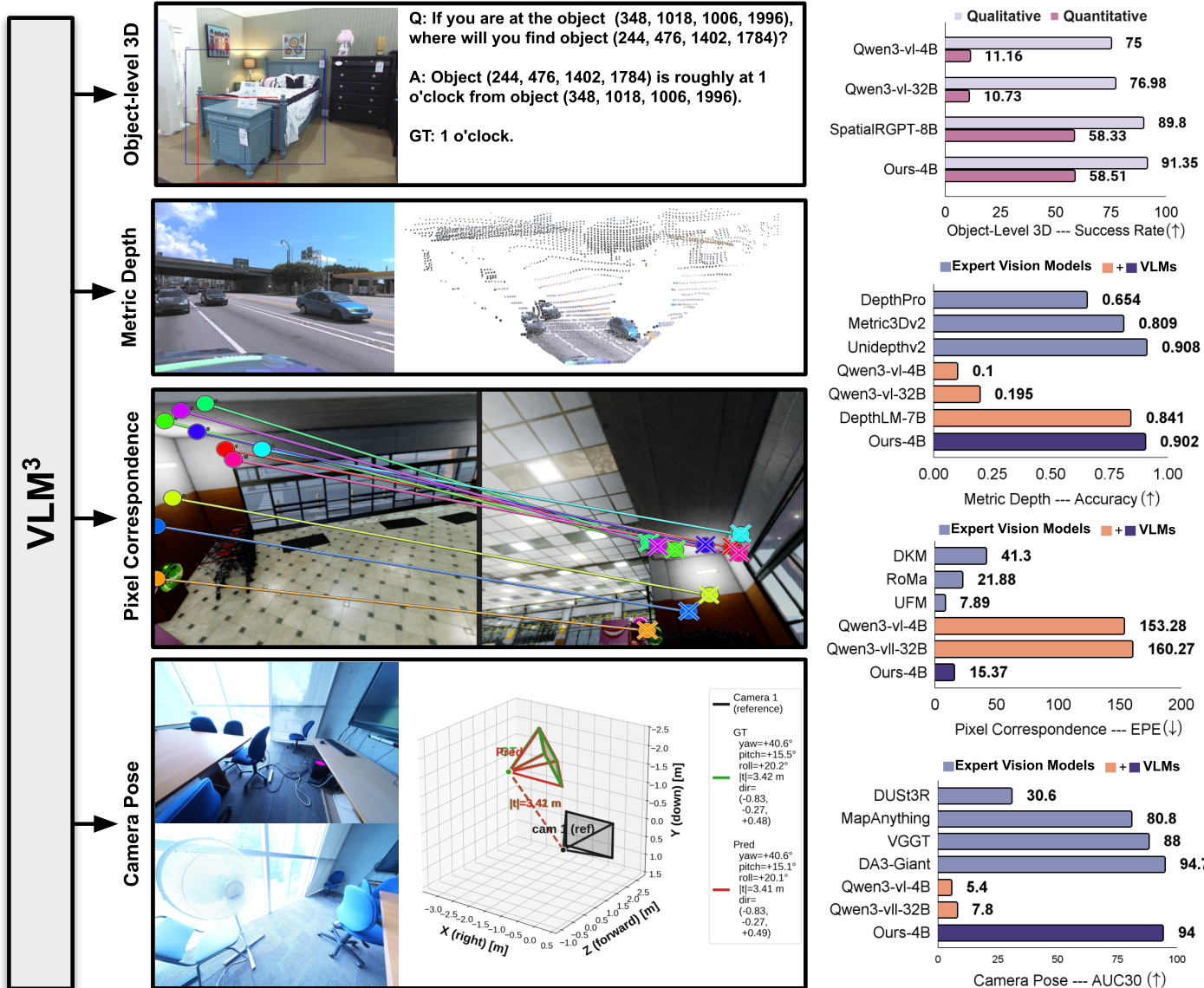
For implementation, the authors utilize Qwen3-vl-4B as the base VLM and apply standard text-based Supervised Fine-Tuning (SFT). In cases where camera intrinsics are unavailable, pre-trained single-image calibration models are used to estimate them before unification. This minimalistic design proves that standard VLMs can function as native 3D learners when provided with the correct data preprocessing and reference strategies.
Experiment
The study validates the generality of VLM3 across four diverse 3D understanding tasks ranging from single-view metric depth estimation to multi-view camera pose estimation. Experiments demonstrate that the model achieves state-of-the-art performance among vision language models and matches expert vision systems using a simplified text-based prompting paradigm without specialized encoders. Further analysis confirms that text-based pixel references perform comparably to visual prompting while emphasizing that careful data mixture weighting is more impactful for scaling than increasing model size.
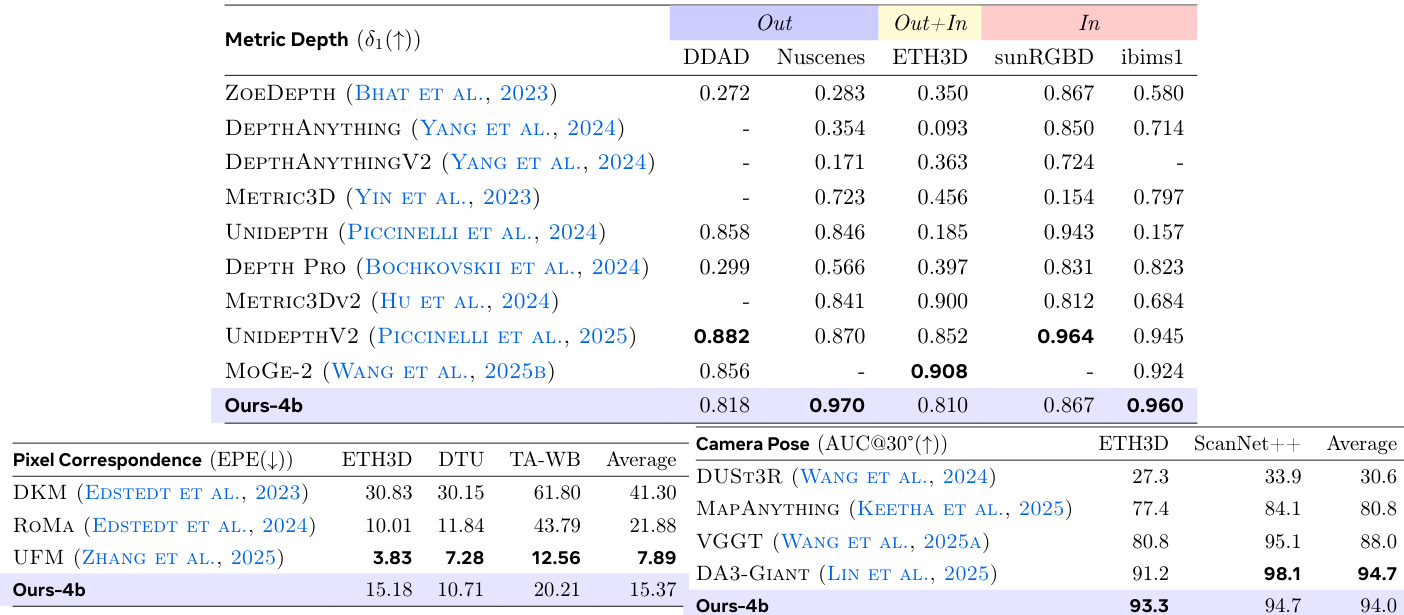
The authors evaluate their proposed model, VLM3, on three diverse 3D understanding tasks including metric depth estimation, pixel correspondence, and camera pose estimation. The results demonstrate that this compact 4B parameter model achieves performance comparable to specialized expert vision models across various datasets, often matching or surpassing previous state-of-the-art methods without requiring complex architectural changes. Specifically, the model achieves competitive accuracy in depth estimation and camera pose estimation while significantly outperforming baseline VLMs in pixel correspondence. The model achieves top-tier performance on NuScenes and iBims1 datasets, rivaling specialized depth estimation models like UniDepthV2. The proposed method significantly reduces error rates compared to baseline VLMs and outperforms expert models DKM and RoMa in average pixel error. The model reaches an average accuracy nearly identical to the SOTA DA3-Giant method, substantially outperforming other recent approaches like VGGT.
The authors evaluate how pixel reference methods, data mixture weighting, and model size influence 3D understanding capabilities. Results demonstrate that text-based pixel reference is a viable alternative to visual prompting, while specialized data mixture weighting significantly improves performance over standard baselines. Furthermore, smaller 4B models outperform larger 32B and 8B models, indicating that current data scales may be better suited for smaller architectures. Text-based pixel reference achieves accuracy comparable to visual prompting methods. Custom data mixture weighting yields higher performance than uniform or dataset-size based weighting. Smaller 4B models achieve superior accuracy compared to larger 32B and 8B models with the same data volume.

The authors present a model that achieves state-of-the-art performance across four diverse 3D understanding tasks including metric depth estimation and object-level reasoning. Results indicate that this approach significantly outperforms both general VLMs and specialized expert models in single-view and multi-view settings. Notably, the method achieves these high accuracy levels using a smaller model size and without requiring complex architectural changes like extra encoders. The model secures the highest average accuracy in metric depth estimation among all compared VLMs. It surpasses specialized baselines in object-level 3D understanding for both qualitative and quantitative evaluations. Performance in multi-view tasks shows substantial gains, particularly in reducing pixel correspondence error and improving camera pose estimation accuracy.
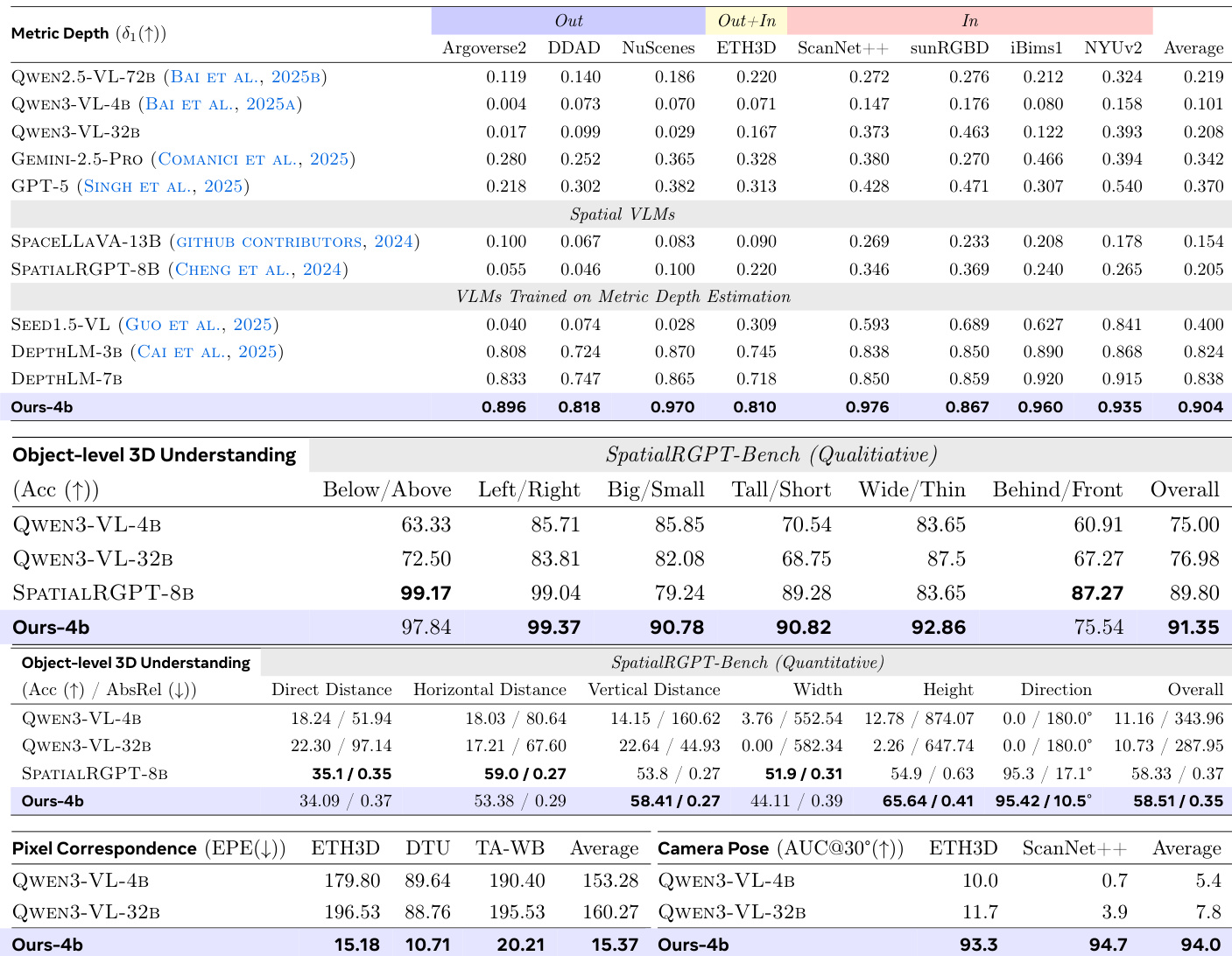
The authors evaluate a compact model on diverse 3D understanding tasks including metric depth estimation, pixel correspondence, and camera pose estimation, demonstrating performance comparable to specialized expert models without complex architectural changes. Ablation studies indicate that text-based pixel reference serves as an effective alternative to visual prompting while specialized data mixture weighting significantly enhances performance. Notably, smaller model configurations outperform larger architectures to secure top-tier accuracy across single and multi-view settings, surpassing both general VLMs and specialized baselines.