Command Palette
Search for a command to run...
Les modèles de langage ont besoin de sommeil
Les modèles de langage ont besoin de sommeil
Sangyun Lee Sean McLeish Tom Goldstein Giulia Fanti
Résumé
Les grands modèles de langage (LLMs) basés sur l’architecture Transformer sont de plus en plus employés pour des tâches à long horizon ; toutefois, leur mécanisme d’attention présente une scalabilité limitée lorsque la longueur du contexte augmente. Pour pallier cette limitation, nous étudions un mécanisme de consolidation de type « sommeil », au cours duquel le modèle convertit périodiquement le contexte récent en poids rapides persistants avant de vider son cache clé-valeur (key-value cache). Pendant la phase de sommeil, le modèle effectue N passes récurrentes hors ligne sur le contexte accumulé et met à jour les poids rapides de ses blocs de modèle d’espace d’état (SSM) via une règle locale apprise. Lors de l’inférence, cette approche décale la charge de calcul supplémentaire vers la phase de sommeil tout en préservant la latence des prédictions en phase active. Nous évaluons notre méthode sur des tâches synthétiques contrôlées, incluant les automates cellulaires et la recherche de chemins multiples sur graphes, ainsi que sur une tâche réaliste de raisonnement mathématique, pour laquelle ni les Transformers classiques ni les modèles hybrides combinant SSM et attention ne parviennent à obtenir de bons résultats. Nous montrons ensuite qu’augmenter la durée du sommeil (N) améliore les performances de nos modèles, avec les gains les plus significatifs sur les exemples nécessitant un raisonnement plus profond.
One-sentence Summary
To address poor attention scaling in transformer-based large language models, the authors propose a sleep-like consolidation mechanism that converts recent context into persistent fast weights within state-space model blocks through N offline recurrent passes, shifting computation to sleep periods to preserve the latency of wake-time prediction while achieving improved performance on cellular automata, multi-hop graph retrieval, and a realistic math reasoning task where regular transformers and SSM-attention hybrids fail.
Key Contributions
- A sleep-like consolidation mechanism is introduced where a model periodically converts recent context into persistent fast weights before clearing its key-value cache. Offline recurrent passes update fast weights within state-space model blocks through a learned local rule, shifting computation to sleep periods without increasing inference latency.
- The approach is evaluated on controlled synthetic tasks including cellular automata and multi-hop graph retrieval, as well as a realistic math reasoning task. Regular transformers and SSM-attention hybrid models fail on these tasks, while the method demonstrates performance improvements.
- Increasing sleep duration N improves performance, with the largest gains observed on examples that require deeper reasoning. This indicates that additional sleep-time computation is most beneficial when reasoning depth increases.
Introduction
Large Language Models typically rely on attention mechanisms that scale poorly with context length, leading to the adoption of hybrid architectures combining attention with fixed size fast weight memories. Yet these prior models struggle with deep reasoning tasks even when memory capacity is sufficient because they lack the computation needed to transform evicted context into useful internal states. The authors leverage biological sleep as inspiration to introduce a consolidation phase where the model performs recurrent forward passes on accumulated context without external input. This process updates fast weights to preserve information for later inference, significantly improving reasoning performance on tasks requiring deep computation over evicted tokens.
Method
The proposed architecture addresses the memory scaling issues of standard transformers by interleaving attention layers with State Space Model (SSM) blocks. In this hybrid design, attention layers maintain a Key-Value (KV) cache that grows linearly with the sequence length, while SSM layers store information in a fixed-size fast-weight state. The model is constructed by stacking these blocks, where an attention block is denoted as Bℓattn and an SSM block as Bℓssm. The SSM blocks utilize a gated Hebbian-like update rule to compress past information into their internal state St:
St=αtSt−1+βtvtkt⊤
Here, αt and βt serve as data-dependent forget and input gates, enabling the model to retain relevant history without expanding memory requirements.
To manage contexts that exceed the attention window, the system implements a consolidation mechanism known as "LLM Sleep." This process involves performing multiple offline recurrent passes over the context before discarding the attention cache.
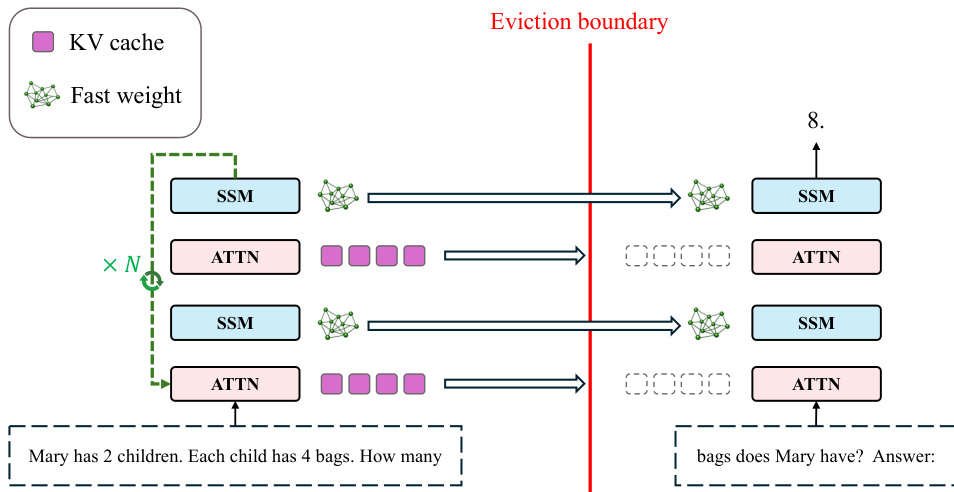
As illustrated in the framework diagram, the model processes input tokens until it reaches the eviction boundary. At this point, the system executes N recurrent passes over the current context, indicated by the green dashed loop labeled ×N. During these passes, the fast weights in the SSM blocks are iteratively refined to encode the accumulated information. Simultaneously, the KV cache in the attention blocks, represented by purple squares, is cleared. The refined fast weights, shown as green network icons, persist across the boundary to support subsequent predictions. This approach allows the model to perform deep reasoning on evicted context during the sleep phase while maintaining constant latency during the inference phase. Training is conducted by backpropagating through the entire computational graph, including the recurrent consolidation steps.
Experiment
This study evaluates attention-SSM hybrid models under hard context eviction constraints using synthetic reasoning tasks like Rule 110 and Depo, alongside the GSM-Infinite math benchmark. By varying the number of offline sleep loops during memory consolidation, the results demonstrate that additional recurrence significantly improves performance on deep sequential computation and multi-hop retrieval where standard single-pass models fail. These findings confirm that extending sleep-time computation allows models to encode evicted context into fast weights more effectively, a trend that persists across both controlled synthetic environments and realistic pretrained LLMs.