Command Palette
Search for a command to run...
WBench : Un benchmark complet multi-tours pour l'évaluation des modèles de monde vidéo interactifs
WBench : Un benchmark complet multi-tours pour l'évaluation des modèles de monde vidéo interactifs
Kaining Ying Hengrui Hu Siyu Ren Jiamu Li Fengjiao Chen Ziwen Wang Xuezhi Cao Xunliang Cai Henghui Ding
Résumé
Les modèles du monde interactifs progressent rapidement, mais les benchmarks existants ne couvrent qu'une partie des compétences requises, ne laissant place à aucune norme unifiée pour une évaluation systématique. Pour combler cette lacune, nous présentons WBench, un benchmark complet multi-tours pour l'évaluation des modèles du monde interactifs selon cinq dimensions, à savoir la qualité vidéo, le respect du cadre (setting adherence), le respect de l'interaction, la cohérence et la conformité physique. WBench comprend 289 cas de test et 1 058 tours d'interaction, où chaque cas spécifie un cadre du monde et une séquence d'interaction multi-tours, couvrant des scènes, des styles, des sujets et des perspectives à la première et à la troisième personne variés, ainsi que quatre types d'interaction, notamment la navigation, l'action du sujet, l'édition d'événements et le changement de perspective. Pour la navigation, WBench unifie le contrôle par texte, par pose 6-DoF et par actions discrètes, permettant l'évaluation de modèles disposant d'interfaces d'entrée natives différentes. L'évaluation utilise 22 sous-métriques automatiques qui combinent des modèles de vision spécialisés avec de grands modèles multimodaux, et toutes les métriques sont validées par rapport aux jugements humains. Sur 20 modèles de pointe, nous constatons qu'aucun modèle ne performe de manière forte sur toutes les dimensions. Nous fournissons des analyses diagnostiques détaillées sur les forces caractéristiques, les faiblesses et les défis ouverts de chaque modèle. Le code et les données sont disponibles à l'adresse https://github.com/meituan-longcat/WBench.
One-sentence Summary
The authors propose WBENCH, a comprehensive multi-turn benchmark that evaluates interactive video world models across five dimensions using twenty-two human-validated automated metrics, unifies text, 6-DoF pose, and discrete-action controls to accommodate diverse input interfaces, and provides detailed diagnostic insights into the performance trade-offs of twenty state-of-the-art models.
Key Contributions
- WBENCH is introduced as a unified multi-turn benchmark that systematically evaluates interactive world models across five dimensions: video quality, setting adherence, interaction adherence, consistency, and physics compliance.
- A dataset of 289 test cases and 1,058 interaction turns standardizes cross-paradigm comparison through a unified navigation interface that supports text, 6-DoF pose, and discrete-action controls across diverse scenes and perspectives.
- A fully automatic evaluation pipeline with 22 fine-grained sub-metrics validated against human judgments is applied to 20 state-of-the-art models to establish diagnostic baselines and demonstrate that no single system achieves strong performance across all dimensions.
Introduction
Interactive video world models are rapidly advancing to power applications in gaming, autonomous systems, and embodied AI by simulating dynamic environments that respond to user actions. Despite this progress, evaluation remains fragmented because existing benchmarks typically assess only isolated capabilities like visual quality or single-perspective navigation, making fair comparison and reliable failure diagnosis nearly impossible. To address these limitations, the authors introduce WBENCH, a comprehensive multi-turn benchmark that evaluates world models across five core dimensions using twenty-two fine-grained automatic metrics. The framework standardizes testing across diverse open-domain scenes, both camera perspectives, and four distinct interaction types while providing a unified navigation interface for cross-paradigm comparison. This fully automated evaluation pipeline establishes clear diagnostic baselines and surfaces actionable insights to guide future model development.
Dataset

- Dataset Composition and Sources: The authors introduce WBENCH, a multi-turn evaluation benchmark comprising 289 test cases and 1,058 interaction turns. Initial frames are sourced from Nano Banana 2 and GPT-Image-1.5, supplemented by web-collected and manually captured imagery. All assets undergo manual verification. The dataset spans six scene categories, five subject types, and seven visual styles, maintaining a 62 to 38 split between first- and third-person perspectives.
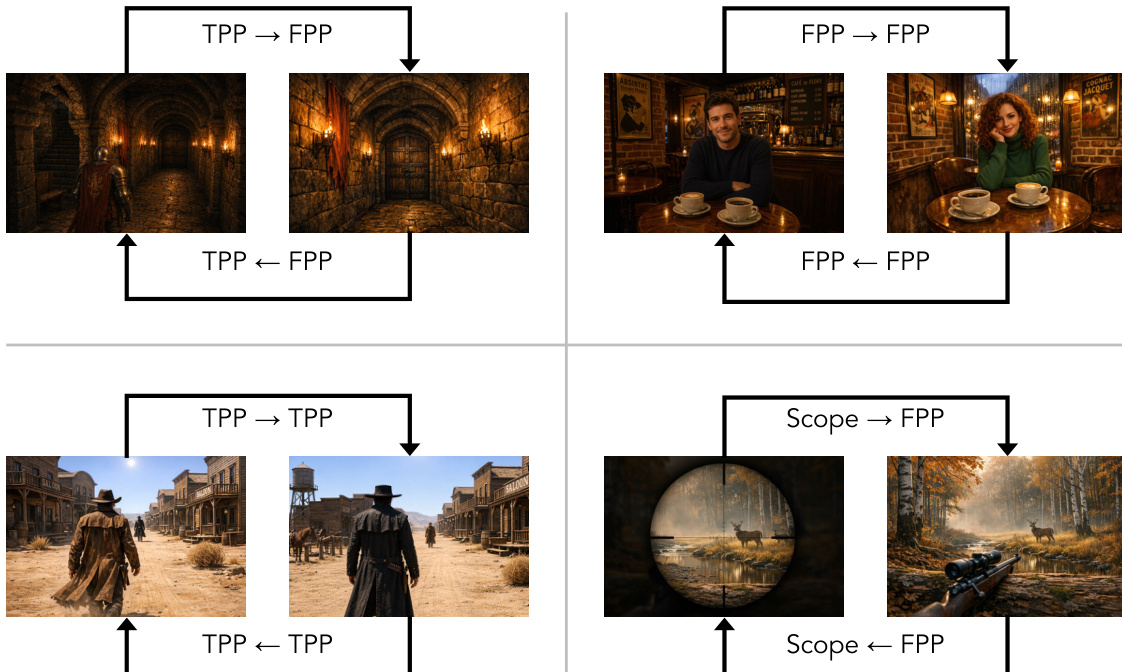
- Subset Details and Construction: The authors organize the benchmark using a setting-first methodology. Annotators design world settings and derive physically executable, causally ordered interaction sequences. Stratified sampling ensures balanced coverage across scenes, styles, perspectives, subjects, and four interaction types. Navigation accounts for 57 percent of cases and is divided into six trajectory topologies, while subject actions, event editing, and perspective switching comprise the remainder. Every case undergoes manual review to verify prompt-to-frame consistency and inter-turn coherence.
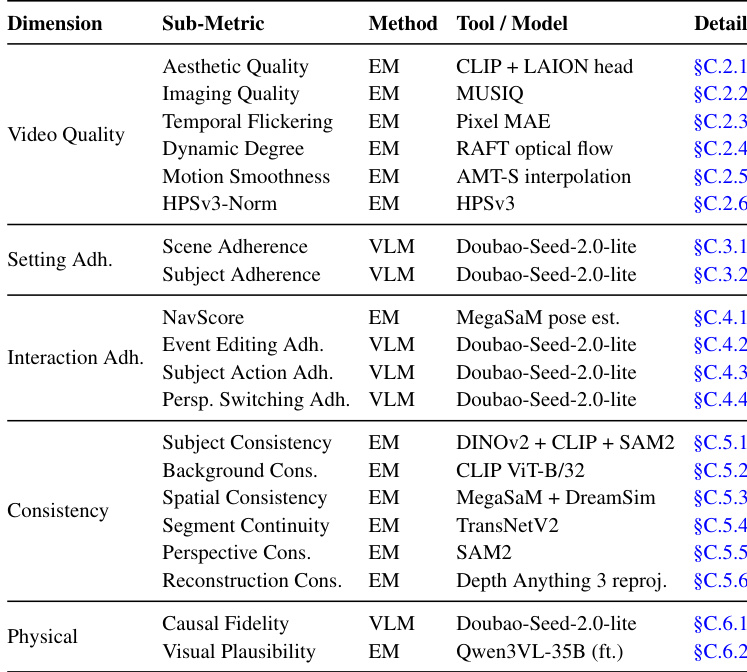
- Usage and Evaluation Protocol: The authors use WBENCH strictly as a held-out test benchmark to evaluate twenty interactive world models rather than for training. Consequently, the dataset contains no training splits or mixture ratios. They apply an iterative image-to-video protocol for text-driven models and native control interfaces for others. The benchmark is processed through twenty-two automatic sub-metrics that combine specialist vision models with large multimodal models. All metrics are validated against human judgments to assess video quality, setting adherence, interaction adherence, consistency, and physics compliance.
- Metadata and Processing Details: The authors construct metadata by defining each world setting through four attributes: scene, style, perspective, and subject. These combine into environment and subject prompts that feed into the initial frame. For evaluation, the authors sample frames at two to three frames per second and resize videos so the longer edge does not exceed 512 pixels. Navigation commands are unified across text, six-degree-of-freedom poses, and discrete WASD inputs with perspective-dependent mappings. The authors also implement structured VLM prompts with JSON scoring rubrics to evaluate specific physics dimensions like fluid dynamics, collisions, and surface interactions.
Method
The authors present a comprehensive framework for evaluating interactive world models, centered on a structured decomposition of inputs and a multi-dimensional assessment of generated video quality. The core methodology begins with the decomposition of each evaluation case into a World Setting W, which defines the initial state of the environment, and an Interaction sequence I, which specifies the user's control signals over a series of turns. This framework enables a systematic assessment of the model's ability to generate coherent, physically plausible, and behaviorally consistent video outputs conditioned on both the initial context and the temporal sequence of actions. The overall architecture is illustrated in the figure below, which depicts the key components of the evaluation process, including the initial image, the interaction types (navigation, subject action, event, perspective switch), and the unified evaluation system.
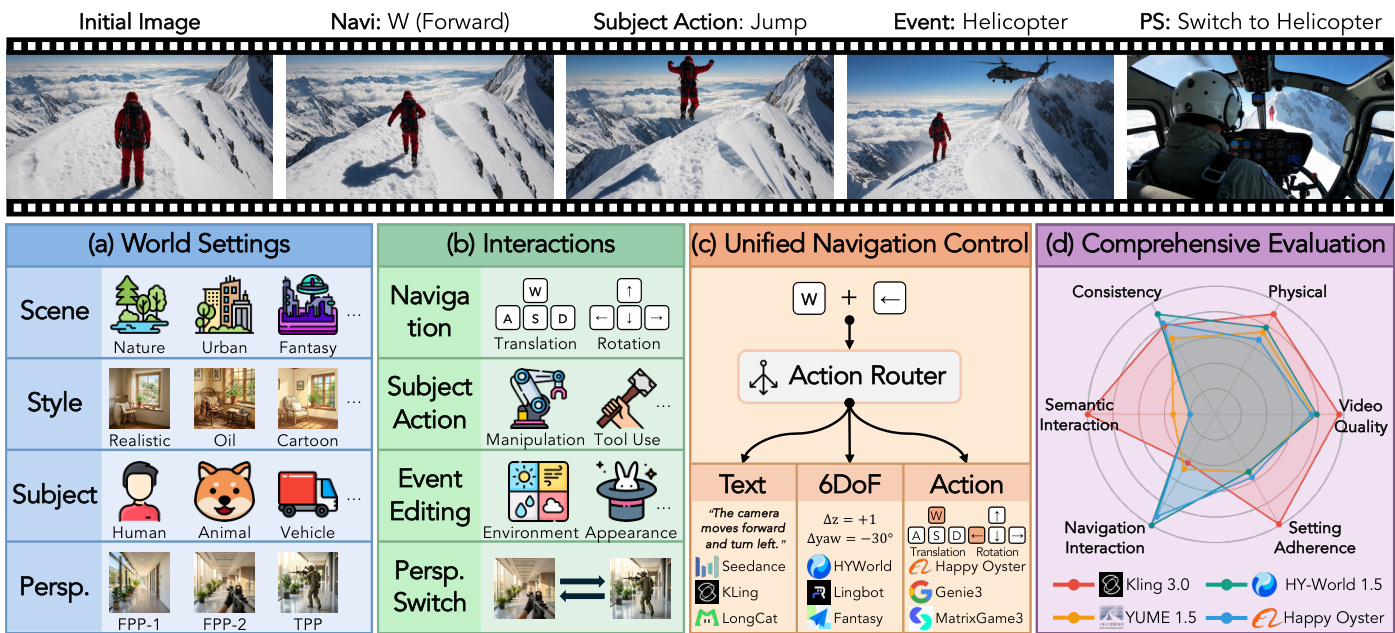
The evaluation suite is structured into five complementary dimensions: Video Quality, Setting Adherence, Interaction Adherence, Consistency, and Physical fidelity. Video Quality measures the perceptual quality of the generated video, incorporating sub-metrics such as aesthetic quality, imaging quality, temporal flickering, motion smoothness, and a human-preference reward score. Setting Adherence evaluates the faithfulness to the specified world setting, with sub-metrics assessing scene and subject adherence. Interaction Adherence focuses on the correct execution of the interaction sequence, including navigation accuracy, event editing, subject action, and perspective switching. Consistency measures the stability of scene geometry, object appearance, and perspective over time. Physical fidelity assesses whether the generated world obeys declared physical rules, covering both high-level causal fidelity and low-level visual plausibility.
The framework supports a variety of action-conditioned models, which are evaluated using a standardized web-interface protocol. These models, including Happy Oyster, Matrix-Game, Genie 3, Hunyuan-GameCraft, and Infinite-World, are designed to accept discrete or continuous action signals and generate subsequent observations conditioned on the full action history. The evaluation process involves a human operator issuing keyboard commands, with the resulting video stream screen-captured for offline metric computation. The authors emphasize the importance of a robust evaluation protocol that accounts for the diverse input interfaces and motion magnitudes of different models.
For navigation evaluation, the authors introduce a navigation score (NavScore) that combines navigation accuracy and trajectory consistency. Navigation accuracy is measured using normalized Absolute Trajectory Error (nATE) after adaptive ground-truth trajectory construction and arc-length resampling. Trajectory consistency is evaluated by comparing symmetric or repeated action pairs, with a consistency score derived from the average normalized ATE. The final NavScore is the mean of the accuracy and consistency terms, rescaled to a 0–100 scale. The figure below illustrates a four-turn navigation case, highlighting how the adaptive ground-truth construction ensures fair evaluation across models with different motion amplitudes.

The consistency dimension is evaluated through several sub-metrics. Spatial Consistency measures the perceptual similarity between the initial frame and a return frame after a roundtrip trajectory, while Gated Spatial Consistency suppresses the score if the video barely moves. Segment Continuity detects unexpected hard cuts within the video, and Perspective Consistency tracks the stability of the subject's centroid across frames. Geometric and Photometric Consistency are evaluated using a unified depth-based reprojection pipeline, where geometric consistency measures 3D structural coherence via reprojection displacement and photometric consistency measures appearance stability via pixel-level PSNR between reprojected frame pairs.
The physical dimension is assessed through a two-stage process. Causal Fidelity uses a VLM to evaluate global plausibility and context-conditioned accuracy across seven physics sub-dimensions, with the final score averaging the results from both stages. Visual Plausibility is evaluated using a fine-tuned Qwen3-VL-30B-A3B model, which predicts a continuous score based on a five-category rating system, optimized to align with human judgments. The figure below shows the overall evaluation process, from the initial image to the final comprehensive evaluation, highlighting the step-by-step workflow for generating and evaluating the video output.
Experiment
The evaluation assesses twenty models across text-driven, camera-controlled, and action-conditioned paradigms to validate performance across video quality, setting adherence, interactive control, temporal consistency, and physical plausibility. Qualitative analysis reveals that no single paradigm dominates uniformly, as text-driven models excel at scene grounding and semantic interactions while dedicated world models lead in spatial navigation and geometric consistency. Crucially, navigation capabilities are structurally decoupled from rendering quality and physics, deteriorating rapidly over multi-turn sequences due to accumulated spatial drift rather than generative limitations. Ultimately, the findings demonstrate that open-source architectures can match proprietary systems when optimized for specific control tasks, and that benchmark difficulty is primarily governed by the complexity of spatial mapping and scene dynamics.
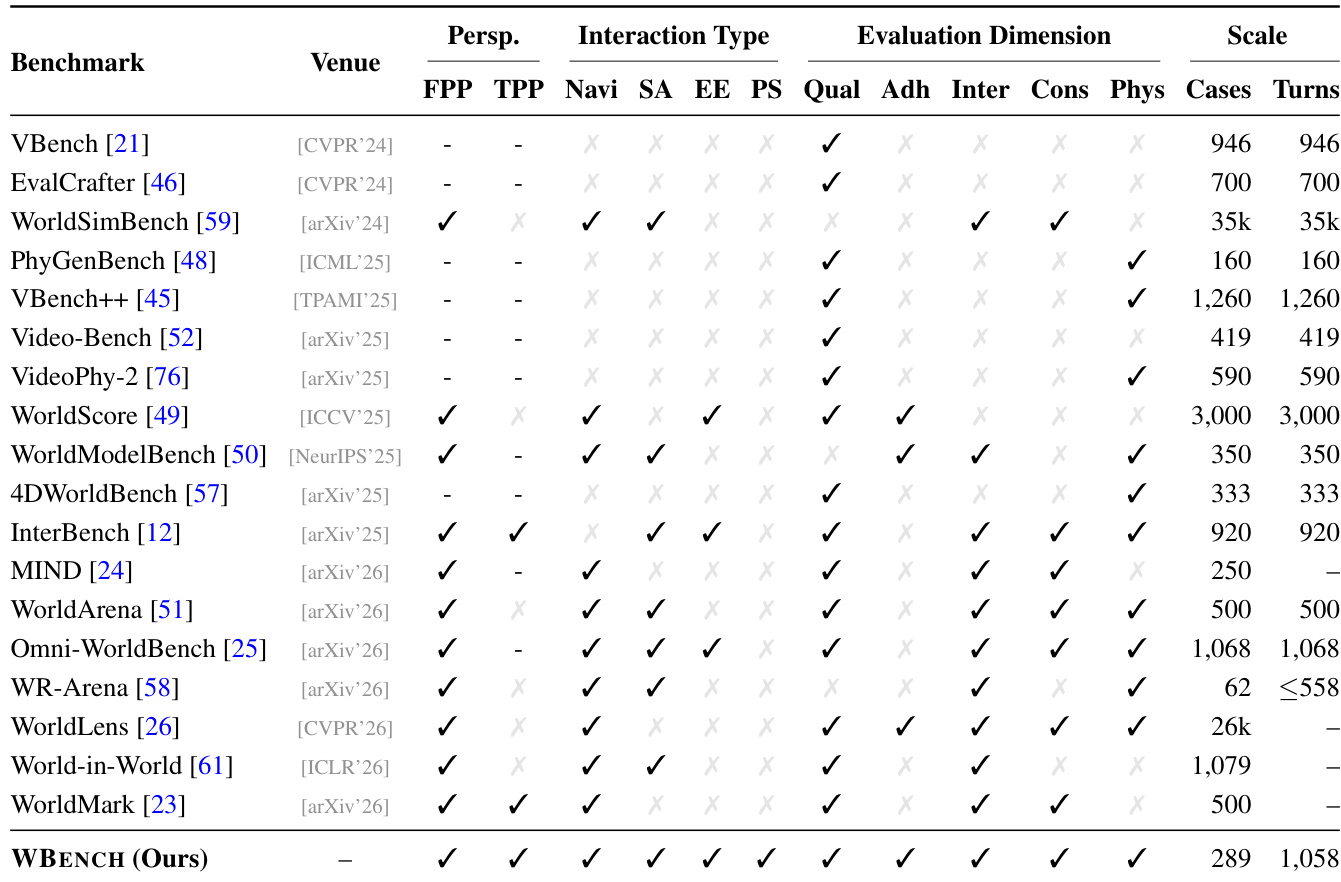
The the the table compares WBENCH with existing benchmarks across input modalities, interaction types, evaluation dimensions, and scale. WBENCH supports a broader range of interaction types and dimensions than other benchmarks, including navigation, event editing, subject action, and perspective switching, and evaluates on a larger number of cases and turns. It also introduces a unified framework that enables fair comparison across different model paradigms. WBENCH evaluates a wider range of interaction types and dimensions compared to other benchmarks. WBENCH covers a larger number of cases and turns than most existing benchmarks. WBENCH supports cross-paradigm comparison by evaluating different model types on a unified framework.
The authors evaluate multiple video generation models across various dimensions of performance, including physical plausibility, interaction adherence, and consistency. The results show that no single model excels across all tasks, with different models demonstrating strengths in specific areas such as collision avoidance, human motion, or reflection handling. Models often fail on complex physics tasks like deformation and destruction, indicating these remain challenging. The evaluation highlights trade-offs between motion dynamics and temporal stability, with some models achieving high consistency but low dynamic degree. No model dominates all physical plausibility sub-dimensions, with performance varying significantly across tasks like collision, deformation, and human motion. Text-driven models like Wan 2.7 and Kling 3.0 lead in interaction adherence, particularly for event editing and subject action, while perspective switching remains broadly difficult. Consistency metrics reveal a trade-off between motion dynamics and temporal stability, with models achieving high consistency often showing low dynamic degree.

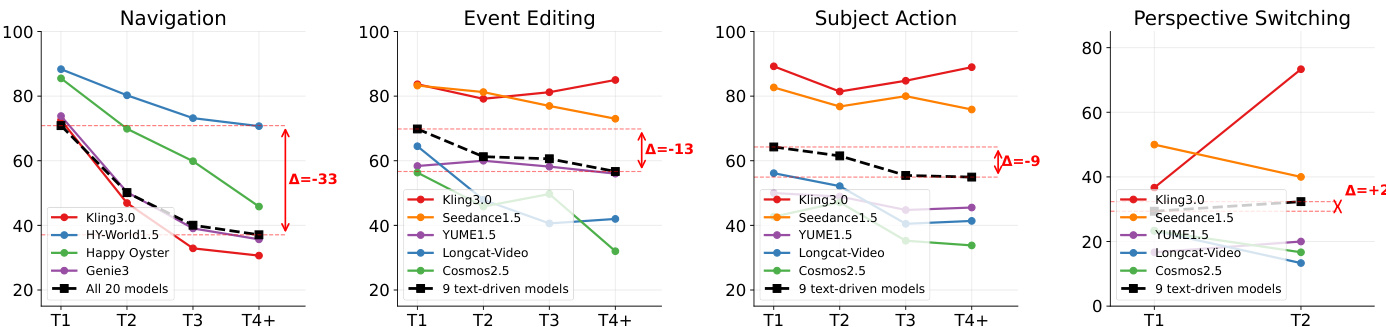
The authors analyze model performance across four interaction types: navigation, event editing, subject action, and perspective switching, using a set of evaluation metrics. Results show that no single model dominates all tasks, with trade-offs evident between different paradigms and capabilities. Navigation performance degrades significantly over turns, while perspective switching remains consistently low across models. Text-driven models excel in semantic interactions like event editing and subject action, but lag in navigation compared to camera-controlled and action-conditioned models. Navigation performance degrades rapidly over interaction turns, with the largest drop observed in text-driven models. Text-driven models achieve the highest scores in event editing and subject action, while camera-controlled and action-conditioned models outperform them in navigation. Perspective switching remains the most challenging interaction type, with all models scoring low and showing minimal improvement across turns.
The the the table compares WBENCH with existing benchmarks across multiple dimensions including video quality, setting adherence, interaction adherence, consistency, and physical compliance. It highlights that WBENCH evaluates a broader range of interaction types and dimensions, particularly supporting both first- and third-person perspectives and incorporating diverse interaction modalities such as event editing and perspective switching. The benchmark also features a larger scale in terms of cases and turns compared to most existing benchmarks, enabling comprehensive evaluation of interactive video generation models. WBENCH evaluates a wider range of interaction types and dimensions compared to existing benchmarks, including perspective switching and event editing. WBENCH supports both first- and third-person perspectives, enabling more comprehensive evaluation of camera control and subject interaction. WBENCH has a larger scale in terms of cases and turns, allowing for more extensive testing of model performance over extended interactions.
The experiment evaluates multiple video generation models across several dimensions including video quality, setting adherence, interaction adherence, consistency, and physical plausibility. The results show that text-driven models generally lead in setting adherence and interaction adherence, while camera-controlled and action-conditioned models perform better in navigation-related tasks. Consistency and physical dimensions reveal trade-offs between motion dynamics and stability, with different models excelling in specific sub-metrics. Text-driven models achieve higher setting adherence and interaction adherence compared to camera-controlled and action-conditioned models. Camera-controlled and action-conditioned models perform better in navigation tasks, while text-driven models lead in semantic interactions. Consistency and physical dimensions show varied performance across models, with some excelling in specific sub-metrics like causal fidelity or geometric consistency.
The evaluation leverages WBENCH to validate interactive video generation models across physical plausibility, interaction adherence, and temporal consistency. Results demonstrate that no single model dominates all tasks, revealing inherent trade-offs between motion dynamics and stability. Text-driven architectures excel in semantic interactions and setting adherence, whereas camera-controlled and action-conditioned models perform better in navigation. Complex physical phenomena, perspective switching, and extended navigation turns remain consistently challenging across all paradigms.