Command Palette
Search for a command to run...
Lens : Repenser l'efficacité de l'entraînement pour les modèles fondamentaux de texte vers image
Lens : Repenser l'efficacité de l'entraînement pour les modèles fondamentaux de texte vers image
Résumé
Nous présentons Lens, un modèle T2I de 3,8 milliards de paramètres qui atteint des performances compétitives avec, et dans plusieurs cas supérieures à, celles des modèles de pointe de plus de 6 milliards de paramètres sur divers jeux de tests, tout en nécessitant considérablement moins de puissance de calcul pour l'entraînement. Par exemple, Lens nécessite seulement environ 19,3 % de la puissance de calcul d'entraînement utilisée par Z-Image. L'efficacité de l'entraînement de Lens découle de deux stratégies clés au-delà de la taille compacte de son modèle. Premièrement, nous maximisons la densité d'information des données par lot d'entraînement en (i) entraînant le modèle sur Lens-800M, un jeu de données de 800 millions de paires image-texte densément légendées, dont les légendes sont générées par GPT-4.1 et contiennent environ 109 mots en moyenne, fournissant ainsi une supervision sémantique plus riche que les légendes courtes conventionnelles, et (ii) en construisant chaque lot à partir d'images de multiples résolutions et de rapports d'aspect diversifiés, élargissant ainsi la couverture visuelle effective de chaque étape d'optimisation. Deuxièmement, nous améliorons la vitesse de convergence grâce à des choix architecturaux soignés, notamment l'adoption d'un VAE sémantique qui fournit de meilleures représentations latentes et l'utilisation d'un puissant encodeur de langage qui accélère l'optimisation tout en permettant une généralisation multilingue à partir de données d'entraînement uniquement en anglais. Après le pré-entraînement, nous appliquons l'apprentissage par renforcement avec des invites guidées par taxonomie (Lens-RL-8K) et des grilles de récompense structurées pour supprimer les artefacts et améliorer la qualité visuelle, un module de raisonnement avec recherche d'invite système sans entraînement pour mieux aligner les demandes des utilisateurs avec le modèle, et une accélération basée sur la distillation pour l'inférence en 4 étapes. Grâce à un entraînement efficace et à une optimisation systématique, Lens généralise à des rapports d'aspect arbitraires de 1:2 à 2:1 et à des résolutions allant jusqu'à 1440^2, et prend en charge les invites dans plusieurs langues couramment utilisées. Grâce à sa taille compacte, Lens génère une image de 1024^2 en 3,15 secondes sur un seul GPU NVIDIA H100, tandis que sa version turbo distillée effectue une génération en 4 étapes en 0,84 seconde.
One-sentence Summary
Lens, a 3.8B-parameter text-to-image model, matches or surpasses models exceeding 6B parameters while consuming only 19.3% of Z-Image’s training compute by maximizing batch information density through the Lens-800M dataset of GPT-4.1-generated long captions and multi-resolution batching, accelerating convergence via a semantic VAE and robust language encoder, and enabling multilingual generation across 1:2 to 2:1 aspect ratios up to 1440² resolution.
Key Contributions
- Lens is a 3.8B-parameter text-to-image model that delivers performance competitive with or superior to state-of-the-art models exceeding 6B parameters while requiring only 19.3% of the training compute used by Z-Image.
- Training efficiency stems from a semantic VAE and a strong language encoder paired with Lens-800M, a dataset of 800 million densely captioned image-text pairs generated by GPT-4.1 with an average of 109 words per caption. Multi-resolution batching further maximizes information density per optimization step by incorporating diverse aspect ratios and resolutions.
- Post-training optimization applies taxonomy-driven reinforcement learning with structured reward rubrics to suppress visual artifacts and utilizes a training-free reasoner to align user prompts. Distillation-based acceleration enables 4-step generation in 0.84 seconds on a single NVIDIA H100 GPU.
Introduction
Foundational text-to-image models have transformed digital content creation but demand massive computational resources, making large-scale training financially and environmentally unsustainable. Prior research typically addresses this by scaling up parameter counts, which inflates training costs, increases inference latency, and overlooks critical efficiency bottlenecks like data density and convergence speed. The authors introduce Lens, a compact 3.8B-parameter T2I model engineered for training-time efficiency. They leverage constrained model scale, boosted batch information density through dense captions and multi-resolution training, and accelerated optimization convergence via strategic VAE and language encoder selections. This approach enables Lens to match or surpass larger state-of-the-art models in generation quality while reducing training compute by over 80 percent and supporting rapid inference.
Dataset
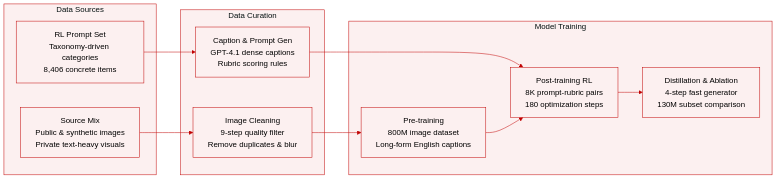
- Dataset composition and sources
- The authors build a pre-training corpus from four complementary sources: public real-world images, public synthetic data, private text-heavy visual content (posters, slides, graphic designs, and general images), and synthetic text data rendered on random backgrounds with blur, color, font, scale, and rotation augmentations.
- For post-training, they develop a taxonomy-driven prompt dataset spanning ten broad categories including humans, objects, animals, scenes, food, events, fictional worlds, text, and UI design. Each category is broken into fine-grained subcategories and concrete items.
- Key details for each subset
- Lens-800M (Pre-training): Contains approximately 800 million high-quality images. The authors apply a nine-step cleaning pipeline that removes corrupted files, filters out images below a 384 squared resolution, and uses specialized models to discard NSFW content, low-aesthetic samples (score below 3), watermarked images, blurry or low-entropy samples, and improperly exposed images. Near-duplicates are removed using CLIP embeddings with a cosine similarity threshold above 0.985.
- Lens-RL-8K (Post-training): Comprises 8,406 carefully curated prompts. Each prompt is generated by sampling one to four description dimensions (attributes, spatial relationships, counts, interactions, colors) and feeding them into GPT-4.1. Every prompt is paired with up to ten task-specific evaluation rubrics plus a global structural coherence rubric.
- Lens-130M (Ablation): A randomly sampled 130 million image subset extracted from Lens-800M to compare captioning strategies.
- How the paper uses the data
- The base model is pre-trained on Lens-800M using dense, long-form English captions generated by GPT-4.1, with original text in images preserved in its source language.
- Post-training applies reinforcement learning via DiffusionNFT. The authors sample 48 prompt-rubric pairs per step, generate 24 images at varying resolutions, and use GPT-4.1-mini to score each image against the rubrics. The policy model is optimized for 180 steps across 64 A100 GPUs.
- The final model is distilled into a four-step generator using techniques from DMD2, decoupled-DMD, SenseFlow, and R1 regularization on the adversarial loss.
- Ablation studies train smaller variants on the Lens-130M subset to prove that dense captions outperform brief or mixed captioning. Additional RL ablations compare the full prompt set against half, quarter, and text-removed subsets to validate the importance of scenario diversity.
- Cropping strategy, metadata construction, and processing details
- Resolution and quality filtering serve as the primary downsizing strategy, ensuring all retained images meet minimum size and clarity standards before training.
- Caption generation follows a strict system prompt designed to produce detailed, compositionally rich descriptions while maintaining multilingual text accuracy.
- RL prompt construction relies on explicit metadata guidelines to ensure reliable evaluation. The authors enforce rules that require fully visible, unobstructed subjects, precise object counts, uniform color presentation, and clear label-object pairing.
- Reward signals are generated through a binary scoring format where the vision-language model outputs a 1 or 0 based strictly on rubric compliance, eliminating subjective elaboration and standardizing the reinforcement learning feedback loop.
Method
The Lens model architecture is designed to achieve high training efficiency and strong generative performance through a combination of a compact yet powerful latent diffusion framework, a carefully selected language encoder, and a modular post-training system. The overall framework, illustrated in the diagram, consists of three primary components: a Variational Autoencoder (VAE) for image compression, a Latent Diffusion Transformer for generating image latents conditioned on text, and a Reasoner module for prompt refinement. The process begins with the input image being encoded into a compact latent representation by the VAE encoder, which reduces the spatial resolution by a factor of 8. This latent representation is then processed by the diffusion transformer, which operates in the latent space to iteratively denoise the image. The text prompt is first encoded by GPT-OSS, a 20B-parameter Mixture-of-Experts (MoE) language model, from which features are extracted at multiple layers (4th, 12th, 18th, and 24th) and concatenated to form a rich, multi-level semantic representation. A linear adapter projects these text features to match the dimensionality of the image latents. These text features are then fed into the diffusion transformer alongside the noisy image latents at each step. The core of the diffusion model is the MMDiT block, which processes the concatenated features through separate image and text branches, employing RMSNorm for normalization and RoPE for positional encoding. The MMDiT blocks are stacked 48 times to form the denoising backbone. After the final denoising step, the latent representation is decoded back into an output image by the VAE decoder, with an unpatchify operation restoring the original resolution. 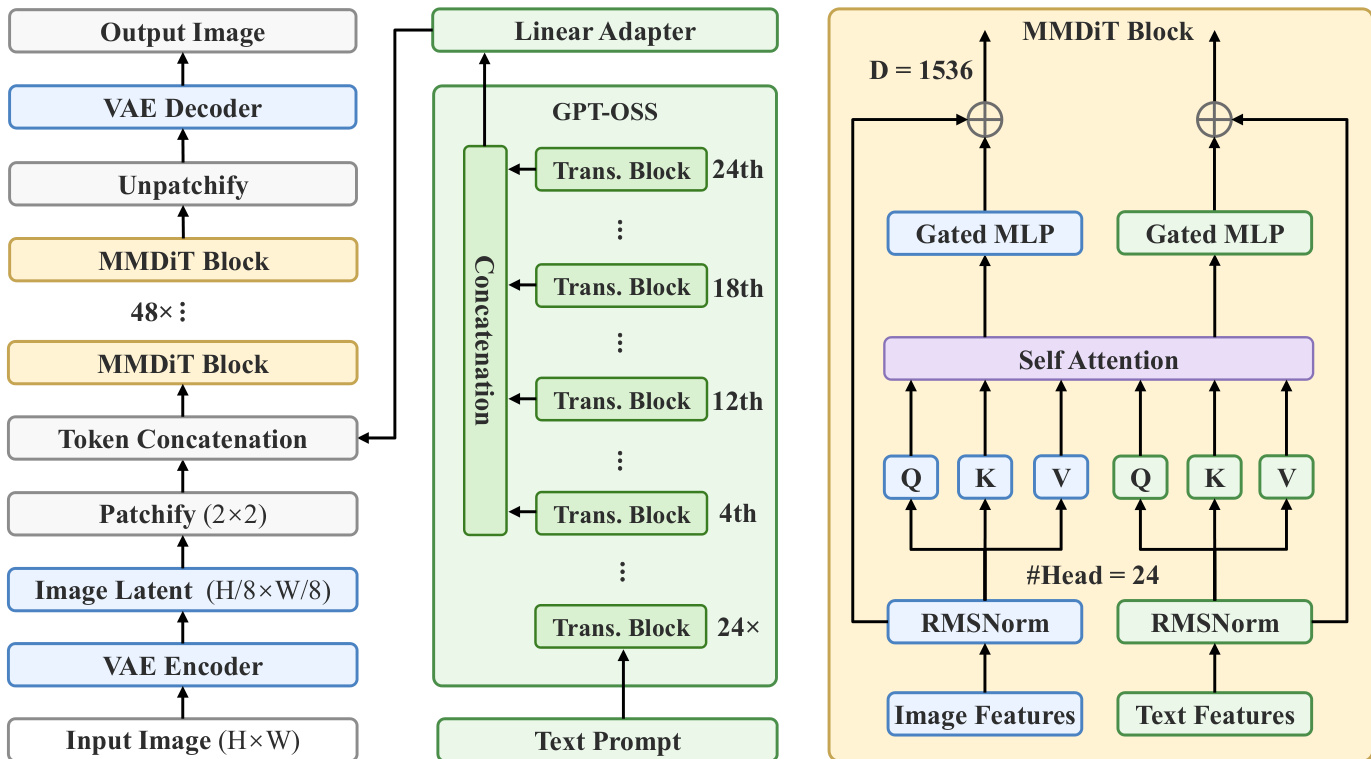 The architecture's efficiency is further enhanced by the use of a strong semantic VAE, which provides a more compact and semantically meaningful latent space, facilitating faster convergence and better text-image alignment. The model also incorporates a Reasoner module, an independent language model that refines user inputs into detailed, coherent prompts before they are passed to the generation model, enabling robust handling of ambiguous requests without retraining the core generator. This modular design allows for flexibility in the choice of the Reasoner, with GPT-OSS being a cost-effective option due to its shared use as the text encoder.
The architecture's efficiency is further enhanced by the use of a strong semantic VAE, which provides a more compact and semantically meaningful latent space, facilitating faster convergence and better text-image alignment. The model also incorporates a Reasoner module, an independent language model that refines user inputs into detailed, coherent prompts before they are passed to the generation model, enabling robust handling of ambiguous requests without retraining the core generator. This modular design allows for flexibility in the choice of the Reasoner, with GPT-OSS being a cost-effective option due to its shared use as the text encoder.
Experiment
The evaluation compares the proposed approach against state-of-the-art baselines across four benchmarks that validate general generation, compositional alignment, text-rich scenarios, and complex multi-region visual text, supplemented by ablation studies on different reasoning modules. Qualitative visualizations and comparative results demonstrate that the method consistently yields high-quality images, accurately renders multilingual text, generates realistic portraits, and faithfully follows complex multilingual instructions. These findings confirm that incorporating specialized reasoning capabilities substantially improves the model's versatility and robustness across diverse text-to-image generation tasks.
The authors evaluate the impact of different RL training set sizes on model performance across multiple benchmarks. Results show that increasing the training set size leads to improved performance on GenEval, while on CVTG and OneIG (EN), performance varies across metrics with some improvements observed in text-related scores and overall quality. Increasing the RL training set size improves performance on GenEval. Performance on CVTG and OneIG (EN) shows mixed trends across different metrics, with some gains in text-related scores and overall quality. The model's performance is sensitive to training set size, particularly in tasks requiring precise compositional alignment and text rendering.

The authors compare Lens and Lens-Turbo with various state-of-the-art models across multiple benchmarks, including text-to-image generation, compositional alignment, and complex visual text generation. Results show that Lens-Turbo achieves competitive performance, particularly in text-related tasks, while Lens performs well in alignment and overall quality, outperforming several open-source models. Lens-Turbo achieves strong performance in text-related tasks, outperforming many open-source models. Lens demonstrates high alignment and overall quality, ranking among the top models in the comparison. Open-source models vary significantly in performance, with some showing strong text accuracy but weaker reasoning and diversity.
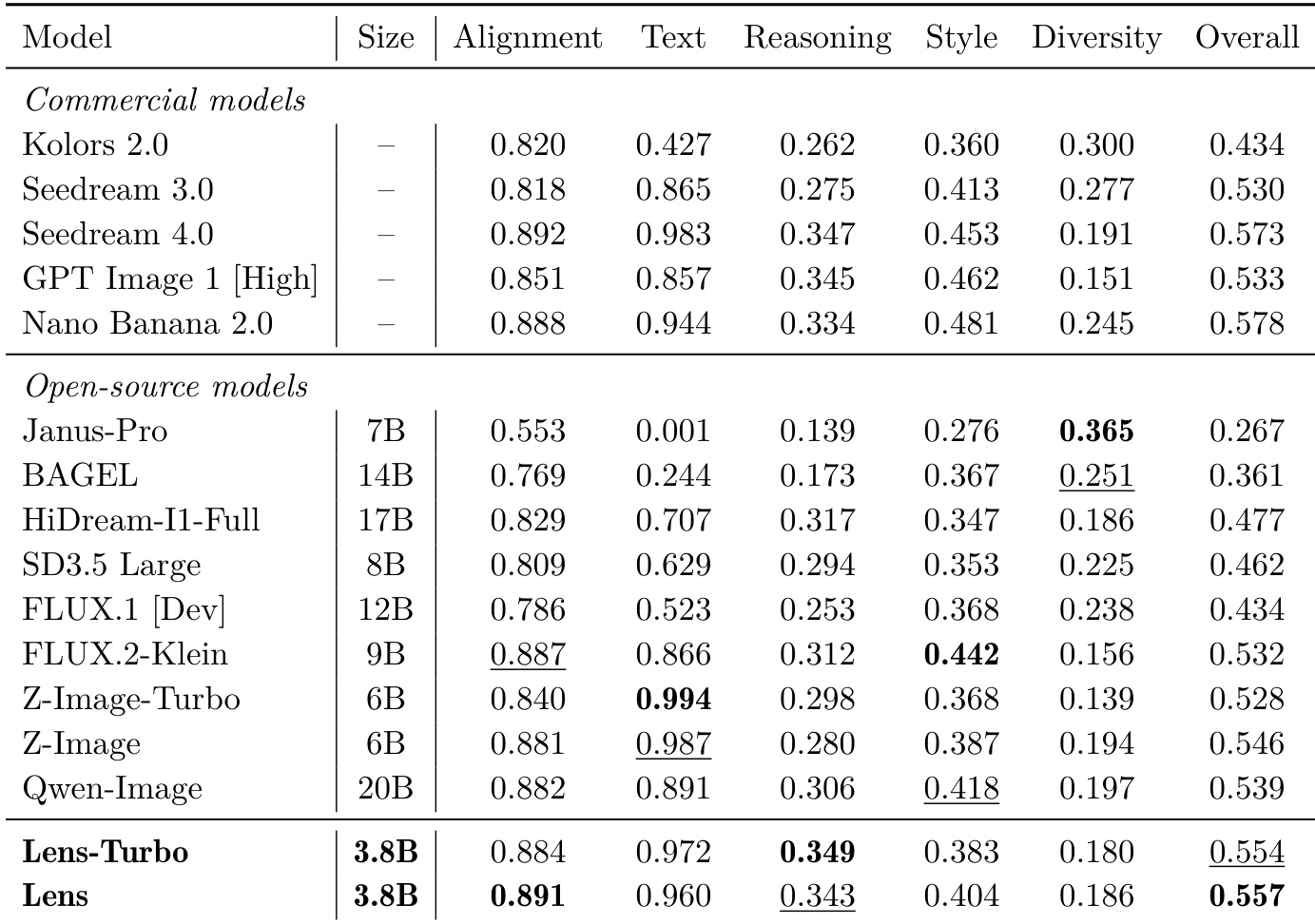
The authors compare Lens and Lens-Turbo with various state-of-the-art models across multiple text-to-image benchmarks, including text-rich scenarios and complex visual text generation. Results show that Lens and Lens-Turbo achieve competitive performance, particularly in text rendering and compositional alignment, with Lens-Turbo often ranking among the top open-source models. Lens-Turbo achieves top performance among open-source models in text-rich generation benchmarks. Lens and Lens-Turbo show strong results in complex visual text generation tasks with multiple text regions. Lens-Turbo outperforms many commercial models in specific text alignment and rendering tasks.
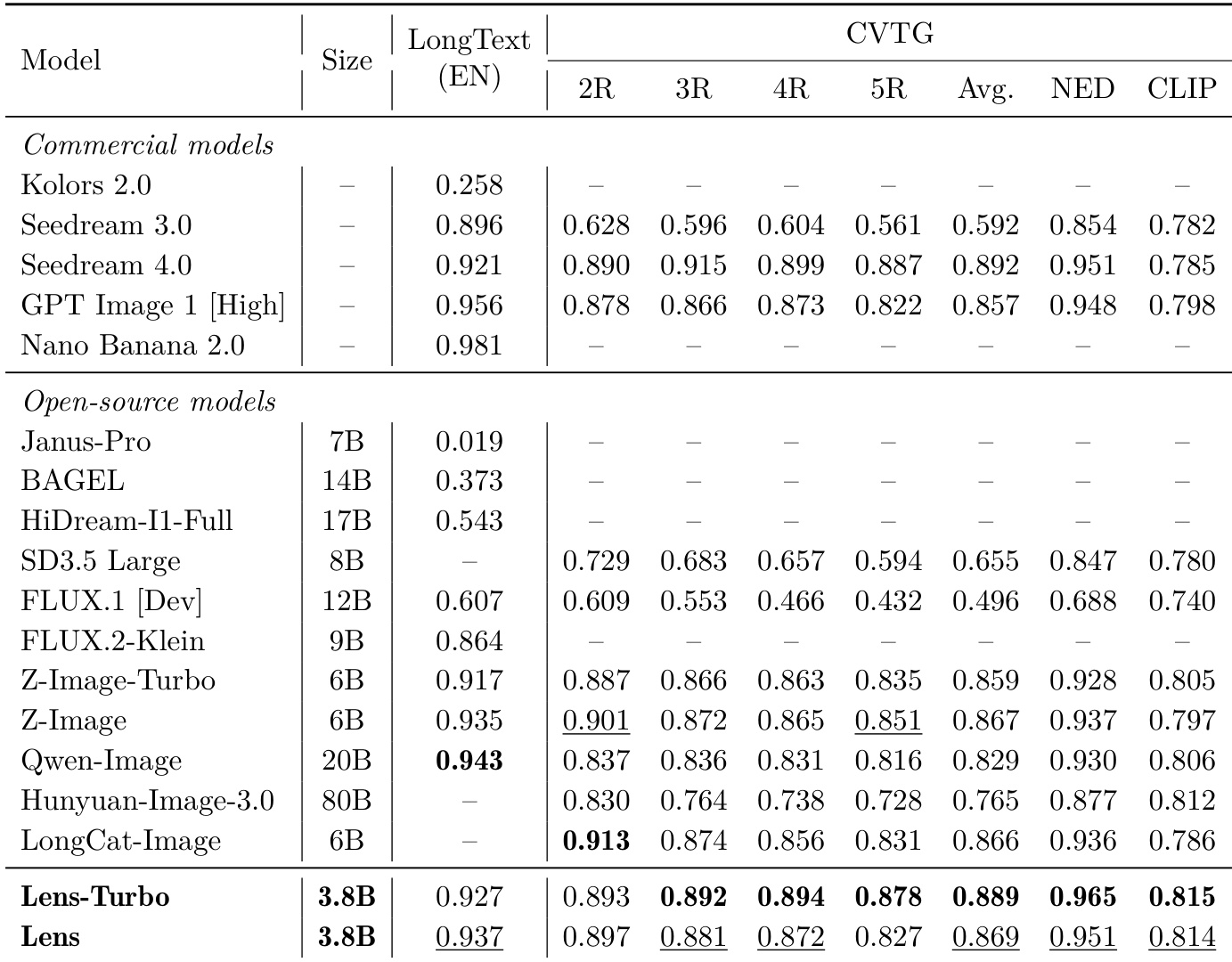
The authors compare Lens with various models across multiple benchmarks, including text-to-image generation tasks that evaluate subject alignment, text accuracy, and compositional constraints. Results show that different configurations of Lens perform competitively, with some variants achieving top or near-top performance on specific benchmarks. Lens variants achieve competitive performance across multiple text-to-image benchmarks, including tasks involving text accuracy and compositional alignment. Certain configurations of Lens outperform other models on specific benchmarks, demonstrating strong performance in text rendering and visual composition. The inclusion of different reasoners affects performance, with some variants showing improved results on particular evaluation metrics.
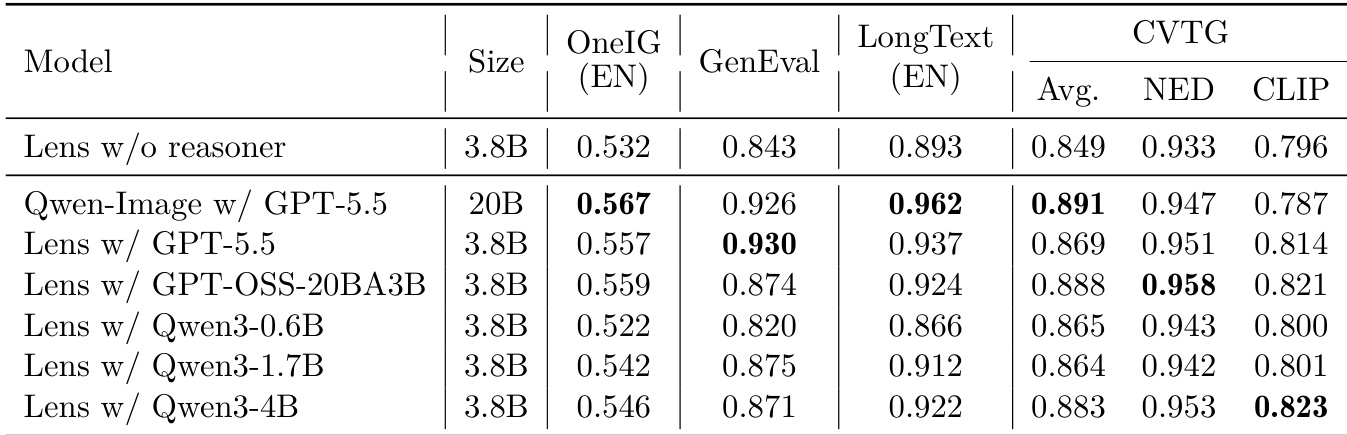
The authors compare Lens and Lens-Turbo against various state-of-the-art models across multiple benchmarks, including object-centric compositional alignment, text-rich scenarios, and complex visual text generation. Results show that Lens and Lens-Turbo achieve competitive performance, particularly in tasks involving text accuracy and multi-object alignment, with Lens-Turbo demonstrating strong overall scores across most categories. Lens-Turbo achieves high scores in multiple evaluation categories, particularly in text-related tasks and multi-object alignment. Lens outperforms several open-source models in overall performance and specific tasks like counting and attribute binding. Commercial models like Seedream 3.0 and GPT Image 1 show strong performance in single-object generation but lag in complex visual text and spatial reasoning tasks.
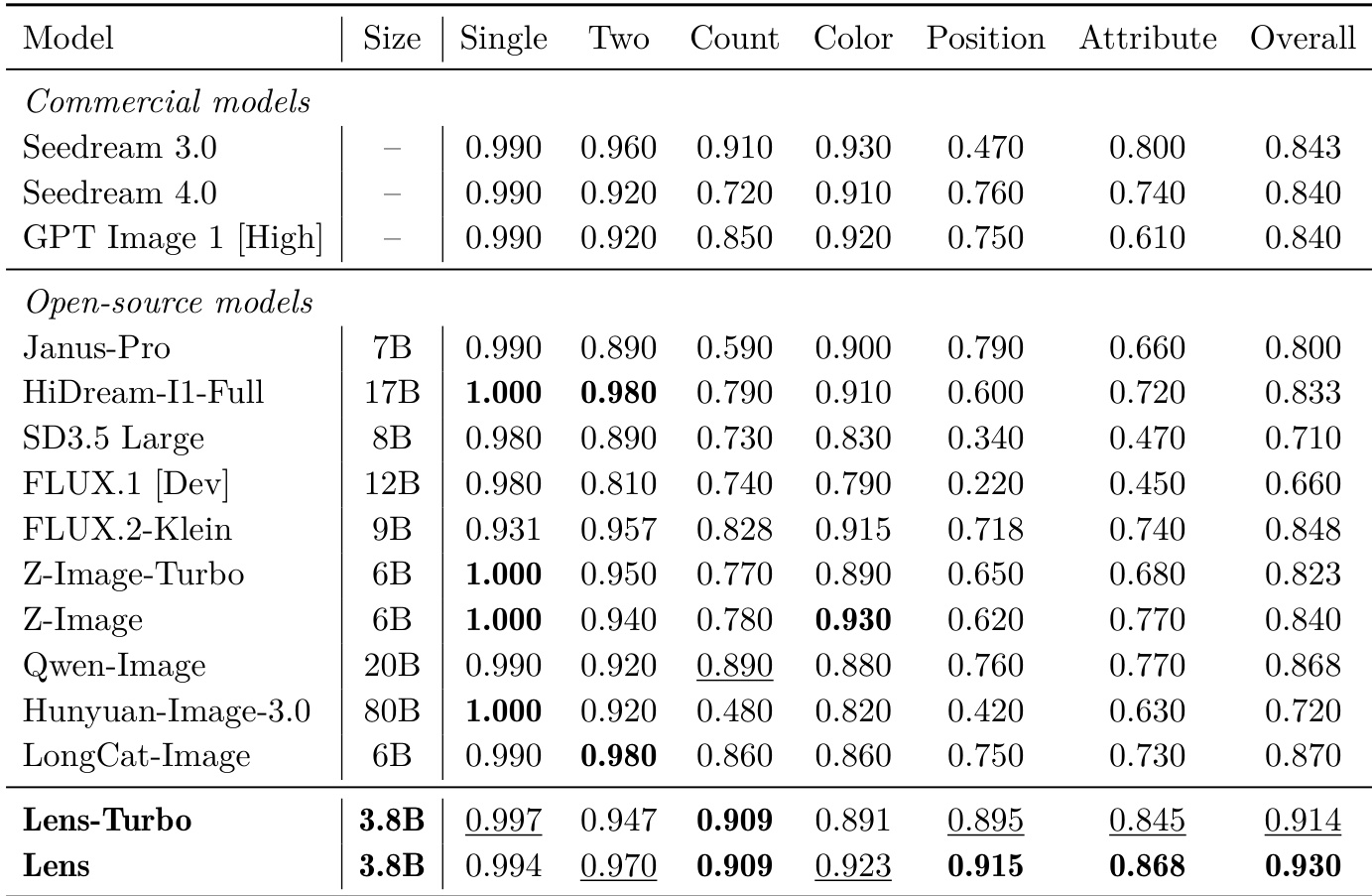
The experiments evaluate the impact of reinforcement learning training set sizes and benchmark the performance of Lens and Lens-Turbo against state-of-the-art models across text-to-image generation, compositional alignment, and complex visual text tasks. Scaling the training data consistently improves performance on alignment benchmarks, while different model configurations demonstrate robust capabilities in text accuracy and multi-object reasoning. Lens-Turbo achieves highly competitive results in text-rich generation and frequently ranks among the top open-source models, whereas the standard Lens variant excels in overall quality and precise visual-text alignment. Ultimately, both architectures validate their effectiveness by outperforming commercial alternatives in complex rendering and spatial reasoning, confirming their strong potential for demanding generative applications.