Command Palette
Search for a command to run...
Voir ce que je veux dire : Aligner les représentations visuelles et linguistiques pour la compréhension fine des objets dans les vidéos
Voir ce que je veux dire : Aligner les représentations visuelles et linguistiques pour la compréhension fine des objets dans les vidéos
Boyuan Sun Bowen Yin Yuanming Li Xihan Wei Qibin Hou
Résumé
Nous présentons SWIM (See What I Mean), une nouvelle stratégie d’entraînement qui aligne les représentations visuelles et linguistiques afin de permettre une compréhension fine des objets uniquement à partir d’invites textuelles. Contrairement aux approches existantes qui nécessitent des invites visuelles explicites, telles que des masques ou des points, SWIM utilise la supervision par masque uniquement pendant l’entraînement pour guider l’attention inter-modale, permettant ainsi au modèle d’attacher automatiquement son attention à l’objet spécifié par l’utilisateur lors de l’inférence. Notre analyse de l’attention croisée sur les grands modèles de langage multimodaux pré-entraînés (MLLMs) révèle un écart systématique : les mots attributifs produisent des activations nettes et localisées dans la modalité visuelle, tandis que les noms d’objets génèrent des motifs diffus et dispersés en raison d’un biais de référence sémantique et de représentations de haut niveau distribuées. Pour remédier à ce désalignement, nous construisons NL-Refer, un jeu de données enrichi dans lequel chaque masque d’objet est associé à une expression de référence en langage naturel précise. SWIM extrait des cartes d’attention croisée multicouches à partir des noms d’objets et impose une cohérence spatiale avec les masques de référence. Les résultats expérimentaux démontrent que SWIM améliore substantiellement l’alignement texte-visuel et atteint des performances supérieures aux méthodes basées sur des invites visuelles sur les benchmarks de compréhension fine des objets. Le code et les données sont disponibles à l’adresse https://github.com/HumanMLLM/SWIM.
One-sentence Summary
SWIM (See What I Mean) is a training strategy that aligns vision and language representations by leveraging the NL-Refer dataset to enforce spatial consistency between multi-layer cross-attention maps from object nouns and ground-truth masks, enabling fine-grained object understanding from textual prompts alone and achieving superior performance over visual-prompt-based methods on fine-grained object understanding benchmarks.
Key Contributions
- The NL-Refer dataset pairs object masks with precise natural language referring expressions to address the systematic attention discrepancy where object nouns yield diffuse visual activations compared to attribute words.
- SWIM enforces spatial consistency between multi-layer cross-attention maps of object nouns and ground-truth masks during training, enabling precise visual grounding from purely textual prompts at inference.
- Experiments on fine-grained object understanding benchmarks demonstrate that SWIM substantially improves text-visual alignment and outperforms visual-prompt-based methods.
Introduction
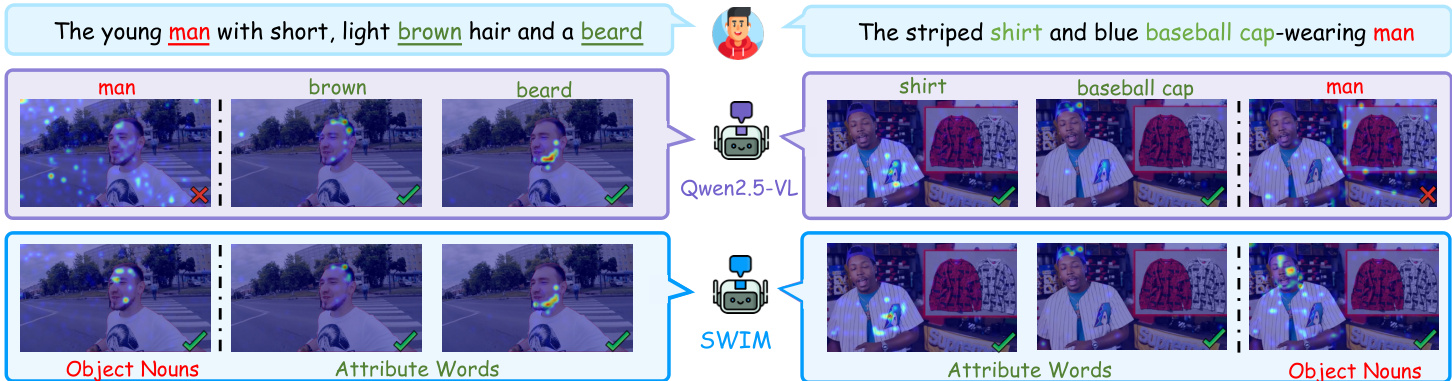
Multimodal large language models (MLLMs) excel at general scene understanding but struggle to precisely localize and reason about specific objects referenced in natural language, a limitation that impedes intuitive interaction where users expect text-only guidance. Prior methods typically rely on explicit visual prompts like masks or bounding boxes and require additional encoders, adding computational overhead and deviating from natural user workflows. The authors also uncover a systematic misalignment in existing models where attribute words generate sharp visual activations while object nouns produce diffuse patterns due to semantic reference bias and the distributed nature of high-level semantics. To address these issues, the authors introduce SWIM, a training strategy that leverages mask supervision exclusively during fine-tuning to enforce spatial consistency between the cross-attention maps of object nouns and ground-truth masks. They further release NL-Refer, a dataset enriched with precise natural language referring expressions, enabling the model to achieve superior fine-grained object understanding from pure text at inference without requiring visual prompts or architectural modifications.
Dataset

- Composition and Sources: The authors derive the NL-Refer dataset from VideoRefer, structuring each sample as a four-tuple containing a video, a refined human prompt, a GPT-generated description, and a pixel-level instance mask for the target region.
- Key Subset Details: Original human prompts contain generic
<region>placeholders. The authors replace these with concise referring expressions generated by GPT-4o using salient descriptors from the paired GPT responses. Each expression isolates the single most representative object noun and wraps it in<ins>markup tokens to enable deterministic token-level alignment. - Data Usage and Training Application: The authors use the refined dataset to provide explicit supervision for cross-attention mechanisms, enabling the model to learn direct text-visual correspondences for specific object nouns. During training, the marked lexical tokens are directly aligned with their corresponding ground-truth masks. The provided excerpt does not specify dataset size, filtering thresholds, or training split ratios.
- Metadata and Processing Details: The processing pipeline applies a two-step transformation where placeholders are substituted with generated phrases followed by inline tagging. This metadata construction preserves the original conversational structure while embedding explicit semantic content. No cropping strategies or additional filtering rules are detailed in the text.
Method
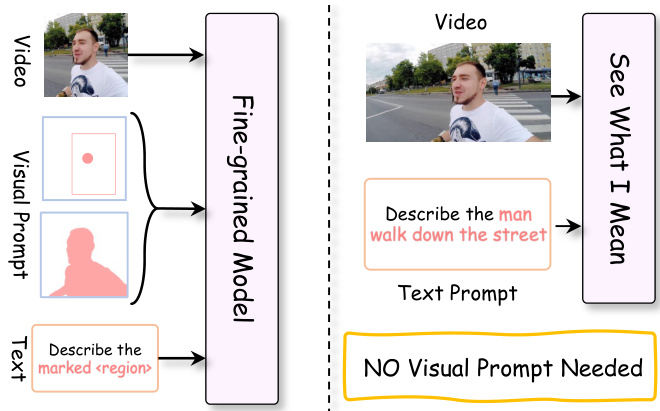
The authors leverage a fine-grained model architecture designed to improve cross-modal alignment between object nouns and their corresponding visual regions in multimodal large language models (MLLMs). The framework processes a video input and a textual prompt that contains a tagged object noun, which is linked to a ground-truth mask. The model operates in a manner that does not require any visual prompt during inference, as indicated in the framework diagram.
During training, the input text prompt Hi is first rewritten using a natural language rewriting module to generate a refined prompt H^i, which is then tokenized into a sequence of Lt tokens, producing text embeddings Xt∈RLt×d. The visual input, represented as a sequence of Lv visual tokens Xv∈RLv×d, is processed by a vision encoder. These visual tokens interact with the text embeddings through the cross-attention layers of the large language model.
As shown in the figure below, for a given tagged noun token wi at position ji, the cross-attention weights from this token to the visual tokens at layer l are computed using the standard attention mechanism. The query vector Qlt[ji] of the tagged noun token is used to compute attention scores with the key vectors Klv of all visual tokens. The attention weights are given by:
Al,i=softmax(dQlt[ji](Klv)⊤),where the softmax is applied over the Lv visual token positions. Each element of Al,i represents the degree to which the noun token attends to each visual token at layer l.
To enable spatial supervision, the attention vector Al,i is mapped to the original feature grid of resolution (H,W) that aligns with the ground-truth mask Mi. This mapping follows the spatial correspondence between visual tokens and encoder patches. If the resolution of the feature grid differs from the token grid, bilinear interpolation is applied to match the mask resolution exactly. The resulting attention map for layer l is denoted as Al,i∈[0,1]H×W.
Since attention patterns may vary across layers, the authors aggregate attention maps from a selected set of layers S by simple averaging:
Aˉi=∣S∣1l∈S∑Al,i.The aggregated map Aˉi captures the stable cross-modal correspondence between the tagged object noun wi and its visual region after accounting for multi-layer variability.
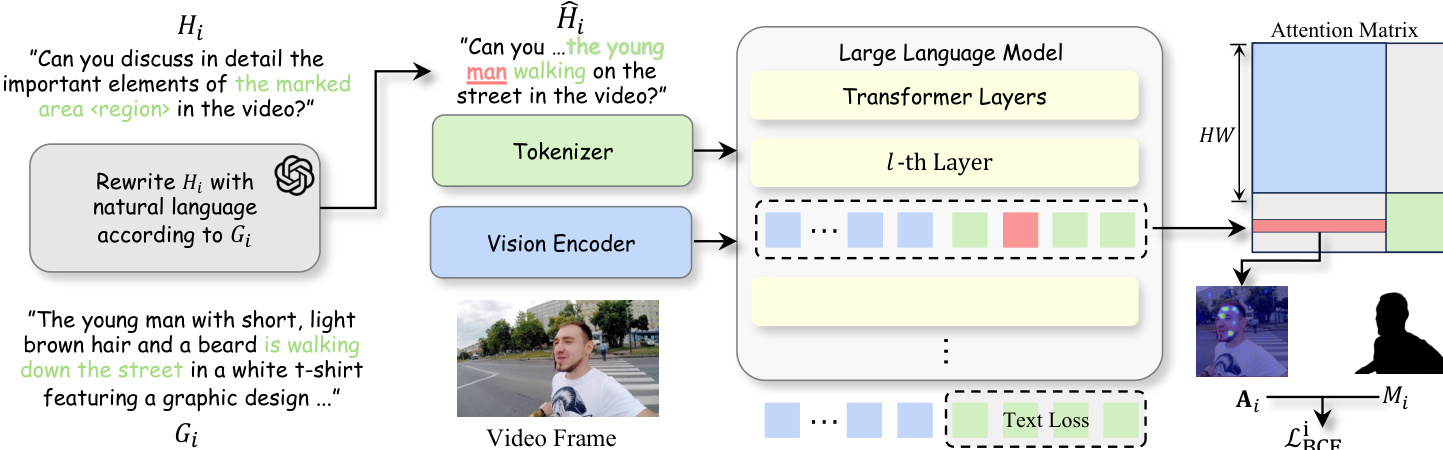
Finally, the aggregated attention map Aˉi is supervised with the binary mask Mi using a pixel-wise binary cross-entropy loss:
LBCE(i)=−HW1u=1∑Hv=1∑W[Mi(u,v)logAˉi(u,v)+(1−Mi(u,v))log(1−Aˉi(u,v))],where Mi(u,v)∈{0,1} indicates whether pixel (u,v) belongs to the target object. By providing this explicit alignment signal during supervised fine-tuning, the model learns to consistently concentrate cross-attention from object nouns onto their correct visual regions, enhancing fine-grained understanding without modifying the base architecture. Notably, the mask Mi is only used for attention regularization during training and is not required during inference.
Experiment
The evaluation assesses the model across dedicated fine-grained video object understanding benchmarks and broad general video comprehension suites to validate its cross-modal alignment capabilities. Fine-grained and qualitative assessments demonstrate that targeted attention regularization significantly sharpens spatial grounding, enabling the model to accurately localize and describe specific objects while adhering strictly to explicit textual prompts rather than defaulting to visually salient elements. Ablation studies validate optimal training configurations, confirming that evenly spaced attention supervision, mean fusion, and binary cross-entropy loss best stabilize cross-modal alignment. Finally, scalability experiments reveal that performance consistently improves with larger volumes of mask-annotated data, ultimately establishing a robust framework that enhances precise text-visual correspondence without compromising general video reasoning.
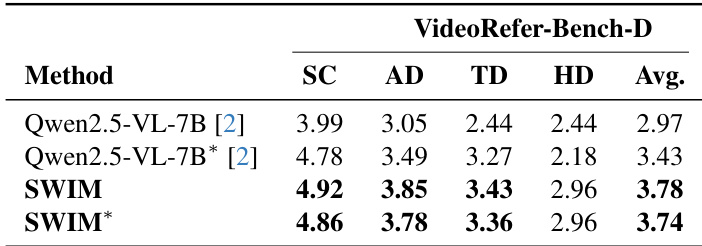
The authors evaluate SWIM on the VideoRefer-Bench-D benchmark, comparing it against Qwen2.5-VL-7B and its variants. Results show that SWIM achieves higher scores across all evaluation metrics, particularly in spatial correspondence and appearance description, indicating improved alignment between language and visual regions. The model's performance is further enhanced when using additional supervision, demonstrating its effectiveness in fine-grained object grounding. SWIM outperforms Qwen2.5-VL-7B across all metrics on VideoRefer-Bench-D, with notable gains in spatial and appearance description. The addition of explicit supervision improves alignment, leading to more accurate and focused attention on target objects. SWIM achieves stronger text-visual grounding, as evidenced by higher scores in precision, AUC, NSS, and AP compared to the baseline.
The authors evaluate SWIM on general video understanding benchmarks, comparing its performance against several state-of-the-art models. Results show that SWIM achieves competitive performance across multiple metrics, demonstrating that its training strategy for fine-grained alignment does not compromise general video understanding capabilities. The model outperforms existing methods on two of the three benchmarks, indicating strong generalization ability. SWIM achieves competitive results on general video understanding benchmarks compared to existing models. SWIM outperforms other methods on two of the three evaluated benchmarks. The model maintains strong generalization ability despite being optimized for fine-grained object understanding.
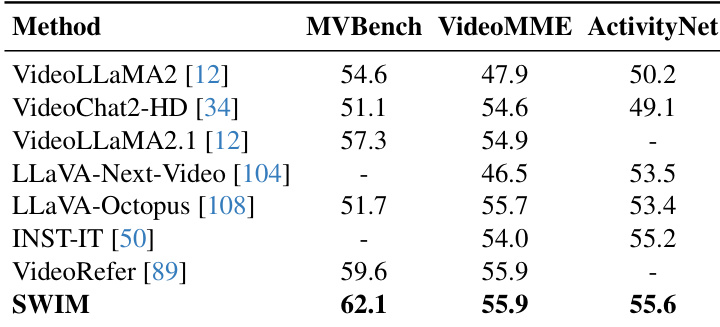
The authors evaluate different loss functions for cross-attention supervision in SWIM, measuring their impact on fine-grained video understanding tasks. Results show that the binary cross-entropy (BCE) loss achieves the highest average score and performs best across all individual metrics compared to alternative losses such as mIoU, Focal, and Dice. Binary cross-entropy loss achieves the highest average score and outperforms other loss functions across all metrics. BCE consistently improves performance on both subject correspondence and temporal description tasks compared to alternatives. The best-performing loss function leads to more accurate and stable attention alignment for fine-grained object grounding.
The authors compare SWIM with Qwen2.5-VL-7B on GamePoint metrics, which measure how well the highest attention regions align with object masks. Results show that SWIM consistently outperforms the baseline across all thresholds, indicating more focused and accurate attention on the specified objects. The improvement is most pronounced at the highest confidence levels, suggesting sharper attention peaks. SWIM achieves higher alignment with object masks compared to Qwen2.5-VL-7B across all attention thresholds. The performance gain is most significant at the top confidence levels, indicating more precise attention localization. SWIM produces sharper attention peaks, reducing diffuse activations and improving object grounding.

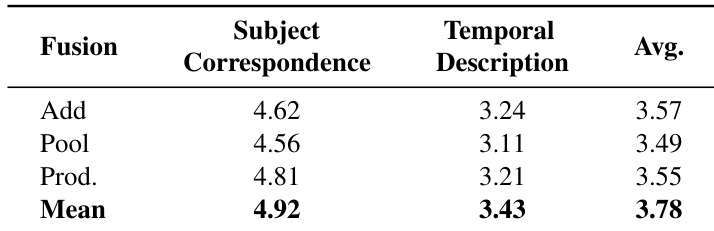
The authors compare different fusion methods for combining attention maps across layers in SWIM, evaluating their impact on fine-grained video understanding tasks. Results show that mean aggregation achieves the highest average performance, outperforming addition, pooling, and element-wise product, indicating that averaging attention maps provides a more effective alignment signal for precise object grounding. Mean fusion achieves the highest average performance among the tested methods. Element-wise product underperforms due to over-suppression of moderate attention regions. Addition and pooling fusion methods yield lower results compared to mean aggregation.
The authors evaluate SWIM across specialized video grounding benchmarks, general video understanding tasks, and component ablation studies to validate its alignment capabilities and architectural choices. The model consistently outperforms strong baselines in spatial correspondence and appearance description while maintaining competitive general comprehension, confirming that targeted fine-grained training does not compromise broader understanding. Ablation analyses further demonstrate that binary cross-entropy loss and mean attention fusion effectively sharpen object localization by reducing diffuse activations and stabilizing cross-attention alignment. Collectively, these results validate that SWIM’s design successfully strengthens precise visual-textual grounding without sacrificing general video reasoning.