Command Palette
Search for a command to run...
Modèles d'action mondiaux : La prochaine frontière en IA incarnée
Modèles d'action mondiaux : La prochaine frontière en IA incarnée
Résumé
Les modèles Vision-Language-Action (VLA) ont démontré une forte capacité de généralisation sémantique pour l’apprentissage de politiques incarnées, mais ils apprennent des mappages réactifs d’observation vers l’action sans modéliser explicitement l’évolution du monde physique sous l’effet d’interventions. Un nombre croissant de travaux tente de pallier cette limitation en intégrant des modèles mondiaux (world models), qui sont des modèles prédictifs de la dynamique de l’environnement, dans le pipeline de génération d’actions. Nous qualifions ce paradigme émergent de Modèles d’Action Mondiale (World Action Models, WAMs) : des modèles fondamentaux incarnés qui unifient la modélisation prédictive de l’état et la génération d’actions, en visant une distribution conjointe des états futurs et des actions plutôt que les seules actions. Toutefois, la littérature reste fragmentée entre architectures, objectifs d’apprentissage et scénarios d’application, et souffre d’un manque de cadre conceptuel unifié. Nous définissons formellement les WAMs, les distinguons des concepts apparentés, et retraçons les fondements ainsi que les premières intégrations des recherches sur les VLA et les modèles mondiaux qui ont conduit à ce paradigme. Nous organisons les méthodes existantes selon une taxonomie structurée opposant les WAMs en cascade et les WAMs joints, avec une subdivision supplémentaire par modalité de génération, mécanisme de conditionnement et stratégie de décodage des actions.
One-sentence Summary
This work formally defines World Action Models as embodied foundation models that unify predictive state modeling with action generation to target a joint distribution over future states and actions, addressing limitations in reactive Vision-Language-Action frameworks, and organizes existing methods into a structured taxonomy of Cascaded and Joint WAMs.
Key Contributions
- This survey formally defines World Action Models and establishes a conceptual framework that disambiguates them from related methodologies in embodied AI. It traces the foundations of vision-language-action research and world model integration to unify predictive state modeling with action generation.
- Existing methods are organized into a structured taxonomy of Cascaded and Joint paradigms based on generation modality, conditioning mechanism, and action decoding strategy. This categorization maps the architectural design space to clarify terminological boundaries within the field.
- The survey synthesizes efforts in scalable training datasets and summarizes emerging evaluation protocols spanning visual fidelity, physical commonsense, and action plausibility. Critical open challenges and future trajectories are outlined to guide the next phase of progress.
Introduction
Vision-Language-Action models currently drive embodied AI by leveraging semantic generalization, yet they operate as reactive systems that map observations directly to actions without modeling physical dynamics. This absence of predictive reasoning limits an agent's ability to generalize across novel environments where anticipating state changes is crucial. While recent work integrates world models to provide physical foresight, the field remains fragmented across disparate architectures and learning objectives. The authors address this gap by formally defining World Action Models as embodied foundation models that unify predictive state modeling with action generation. They present the first systematic survey of the landscape, categorizing methods into Cascaded and Joint paradigms while synthesizing data ecosystems and evaluation protocols to guide future research.
Dataset
-
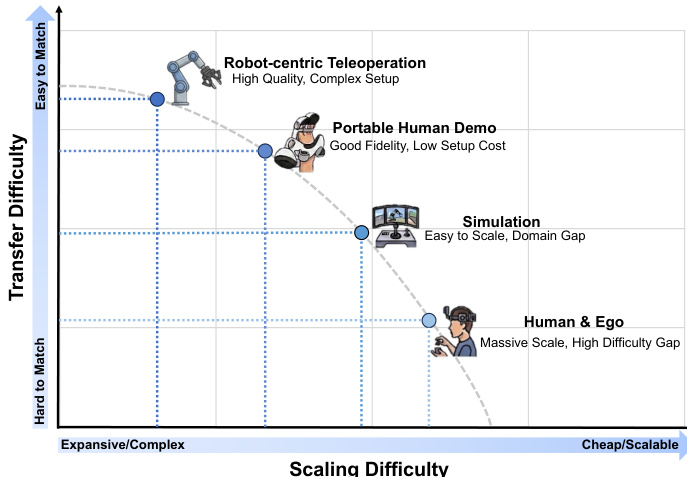
Dataset Composition and Sources The authors categorize the training landscape into four dominant paradigms to balance precise physical grounding with broad generalization. These include high-fidelity Robot-Centric Teleoperation, agile Portable Human Demonstrations, scalable Simulation Data, and broad Human and Ego-Centric Data.
-
Key Details for Each Subset
- Robot-Centric Teleoperation: Sources include Open-X Embodiment and DROID. Data consists of strictly aligned, high-frequency action-state pairs with multimodal signals such as RGB, proprioception, depth, audio, and tactile feedback.
- Portable Human Demonstrations: Utilizes UMI-style hardware like handheld grippers and wearable cameras for in-the-wild collection. Datasets include FastUMI and RealOmin, offering centimeter-level action constraints across diverse environments.
- Simulation Data: Generated via physics engines like MuJoCo and Isaac Sim. Examples include SynGrasp-1B with millions of trajectories. This subset provides privileged spatial supervision such as perfect depth and exact 6D object poses.
- Human and Ego-Centric Data: Sourced from internet-scale videos like Ego4D and HowTo100M. These provide passive world dynamics or active dynamics extracted through 3D hand pose and motion tracking.
-
Data Usage and Training Strategy The framework employs joint training strategies to ingest both paired (ot,at,ot+1) triplets and unpaired action-free sequences. This mixture allows the model to couple internal representations with massive unconstrained observations for visual physics. The authors note that this approach bridges the gap between low-level robotic control and open-world generalization.
-
Processing and Metadata Construction
- Augmentation: Automated and generative augmentation is used to scale data beyond manual collection limits.
- Alignment: Human actions are retargeted to robot-executable actions via vision-based tracking.
- Spatial Grounding: Simulation data undergoes domain randomization over textures and lighting to reduce the sim-to-real gap.
- Pose Estimation: Ego-centric videos are processed with pose estimation and 3D hand-object mesh alignment to bridge the action gap in passive data.
Method
World Action Models (WAMs) represent a class of embodied foundation models that unify environmental dynamics modeling with motor control. Unlike standard Vision-Language-Action (VLA) models that learn direct observation-to-action mappings, or World Models (WMs) that solely predict state evolution, WAMs predict the future evolution of the physical environment alongside motor commands. As shown in the figure below, the WAM architecture contrasts with VLA and WM by jointly processing current observations and language to output both the next observation and the action.
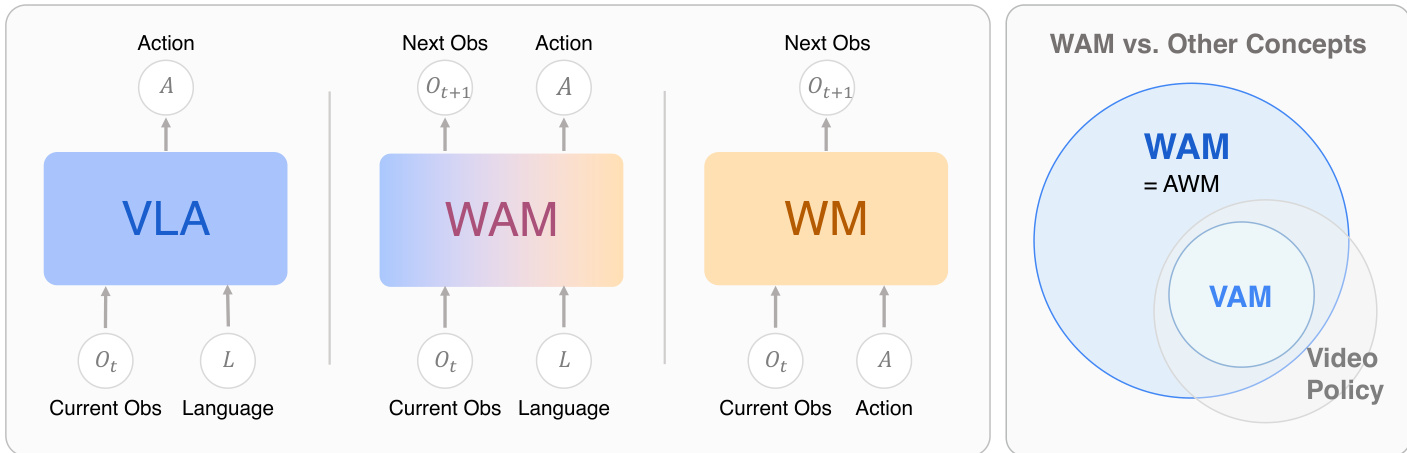
Formally, a WAM seeks to characterize the joint distribution of future states and actions within a unified framework: LWAM=E(o,l,o′,a)∼D[−logp(o′,a∣o,l)].
The literature is systematically categorized into core dimensions including architecture and training data. Refer to the framework diagram for the comprehensive taxonomy of World Action Models reviewed in this survey.
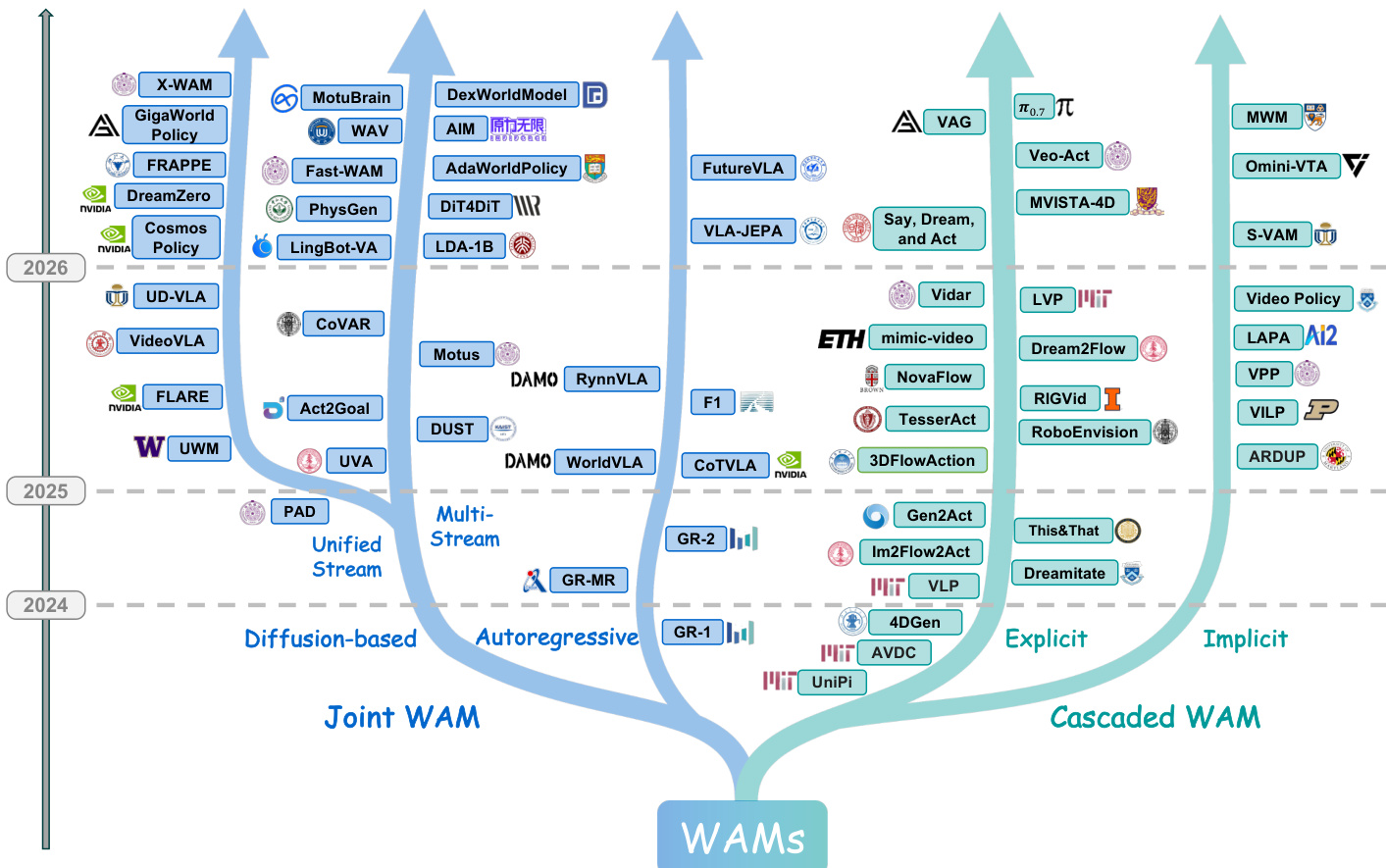
Recent advances have shifted toward integrating world modeling directly into the policy architecture. the paper categorize these architectures into two primary paradigms: Cascaded WAMs and Joint WAMs.
Cascaded World-Action Models implement the world-action mapping through a sequential two-stage pipeline. A world model first synthesizes a visual plan representing the anticipated future, after which a separate action model decodes executable robot commands from that plan. This decomposition offers a natural inductive bias where the world model need not reason about robot kinematics, while the action model need not solve long-horizon scene prediction. Based on the type of intermediate planning carrier, Cascaded WAMs are categorized into Explicit Planning via pixel-space representations and Implicit Planning via latent representations. The schematic below provides an overview of these cascaded patterns.
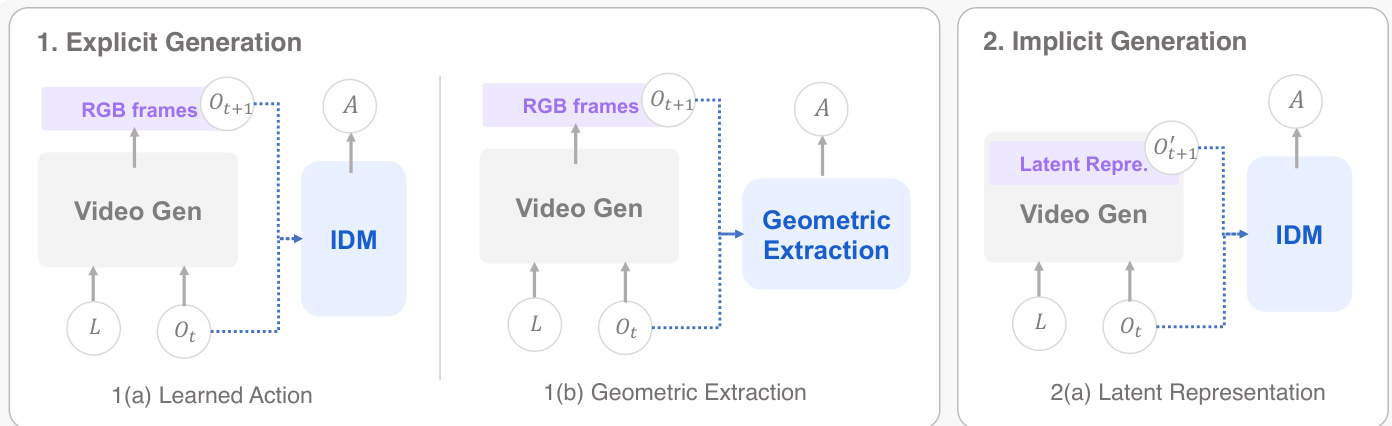
Explicit Planning uses raw pixel frames as the intermediate representation. Work in this space divides by how actions are subsequently extracted from the synthesized video, either through learned inverse dynamics or through closed-form geometric computation. Implicit Planning is motivated by the observation that intermediate latent representations formed during diffusion already encode the dynamical information required for planning. The planning carrier is replaced by latent feature sequences that remain in the compressed representation space throughout. A comparison of Cascaded World-Action-Model methods is provided in the table below.
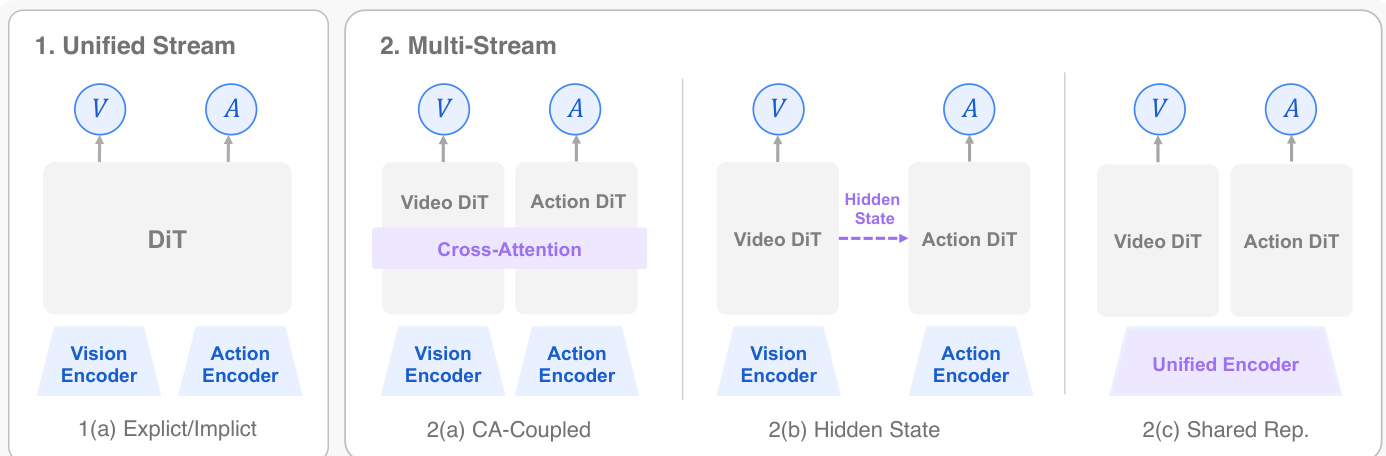
Joint World-Action Models denote a family of architectures in which future world states and actions are predicted within a single unified model. Under this unified definition, existing joint world-action models are organized into two broad generation routes. Autoregressive Generation relies on causal, left-to-right sequential decoding to parameterize both future states and control signals. In these architectures, heterogeneous variables are serialized into a unified temporal sequence where the joint distribution of world and action is factorized sequentially. Table 2 presents a taxonomy-oriented summary of Autoregressive Generation papers.
Diffusion-based Generation constitutes a significant technical route characterized by multi-step generative processes to capture the complex distributions of future states. These architectures generate future world states and action sequences concurrently across a multi-step horizon. This approach fundamentally overcomes the sequential bottleneck of autoregressive modeling, enabling the high-frequency execution necessary for closed-loop control.
Experiment
The evaluation framework assesses world modeling capability through three dimensions: visual fidelity, physical commonsense, and action plausibility, alongside specific benchmarks for action policy generation. While visual metrics ensure perceptual consistency, action plausibility tests highlight a critical gap where visually convincing models often fail to support executable robot behavior. Furthermore, action policy evaluation categorizes benchmarks by robot morphology to validate the model's ability to generate robust control signals across diverse manipulation scenarios.
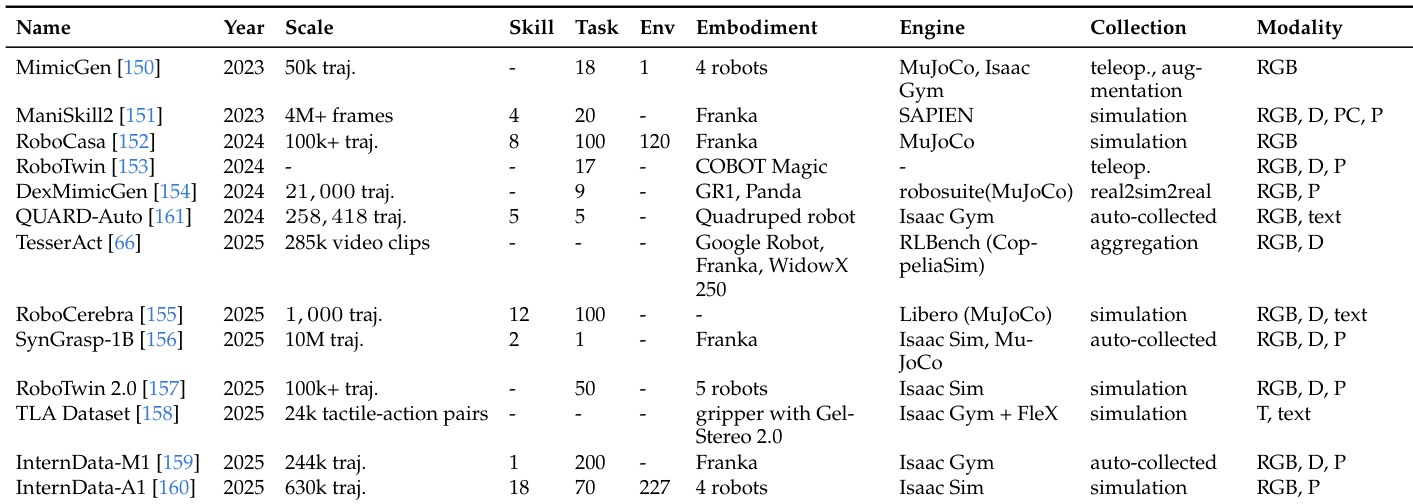
The the the table presents a systematic review of datasets and benchmarks used for evaluating action policies and world models in robotics. It details various entries categorized by scale, task complexity, simulation engines, and sensor modalities. The data highlights a trend towards larger-scale datasets and diverse embodied setups, including both simulation and real-world collection methods. Data scale varies significantly, ranging from small trajectory sets to massive collections containing millions of frames. Sensor modalities extend beyond standard RGB to include depth, point clouds, text, and tactile data in many entries. Data collection approaches are diverse, utilizing teleoperation, simulation, auto-collection, and aggregation strategies.
The the the table categorizes action policy evaluation methods based on their intermediate representations, distinguishing between pixel-space approaches and those utilizing latent features. Pixel-space methods are further divided into those employing learned action extraction versus geometric extraction pipelines. The evaluation column demonstrates extensive testing across diverse simulated environments and real-world robotic hardware setups. The methods are classified into three main groups: pixel-space learned extraction, pixel-space geometric extraction, and implicit planning via latent representations. Evaluation environments include various simulation platforms and real-world robots such as Franka, WidowX, and Aloha. While the majority of methods utilize action labels during training, a subset of geometric extraction approaches supports zero-shot evaluation.
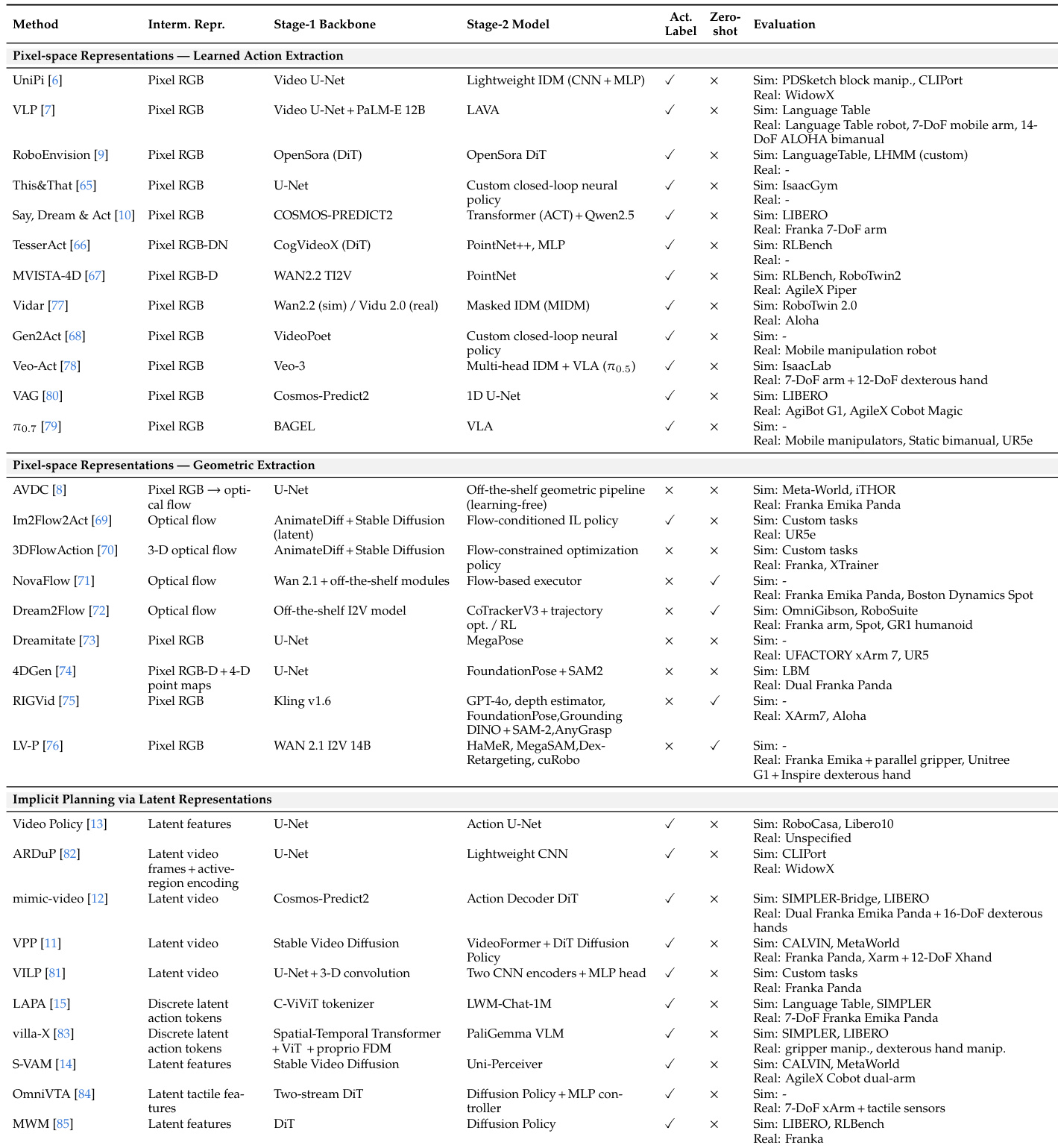
The evaluation framework systematically reviews robotics datasets and benchmarks, highlighting a trend towards larger-scale collections with diverse sensor modalities ranging from RGB to tactile data. Action policy assessment is categorized by intermediate representations, distinguishing between pixel-space approaches and those utilizing latent features across various simulated and real-world hardware setups. While most methods rely on action labels during training, the analysis reveals significant diversity in data collection strategies and notes that zero-shot evaluation is supported by specific geometric extraction pipelines.