Command Palette
Search for a command to run...
CVEvolve : Découverte autonome d'algorithmes pour le traitement des données scientifiques non structurées
CVEvolve : Découverte autonome d'algorithmes pour le traitement des données scientifiques non structurées
Ming Du Xiangyu Yin Yanqi Luo Dishant Beniwal Songyuan Tang Hemant Sharma Mathew J. Cherukara
Résumé
Le traitement des données scientifiques nécessite souvent des algorithmes ou des modèles d’IA spécifiques à la tâche, ce qui constitue une barrière pour les scientifiques de domaine qui doivent analyser leurs données mais ne disposent pas d’une expertise étendue en informatique ou en traitement d’image. Cette barrière est particulièrement prononcée lorsque les données sont bruitées, présentent une plage dynamique élevée, sont faiblement annotées ou ne sont que partiellement définies. Nous présentons CVEvolve, un environnement autonome agentic doté d’une interface en zéro code pour la découverte d’algorithmes de traitement des données scientifiques. CVEvolve combine une stratégie de recherche multi-tours avec des outils permettant l’exécution du code, la mise en œuvre de l’évaluation, la gestion de l’historique, les tests sur des données hors jeu (holdout testing), et une inspection optionnelle des données scientifiques et des sorties visuelles. La recherche alterne entre des actions de découverte et d’amélioration, et utilise un échantillonnage stochastique des candidats conscient de la lignée (lineage-aware) pour équilibrer exploration et exploitation. Nous démontrons l’efficacité de CVEvolve sur l’enregistrement d’images en microscopie de fluorescence X, la détection des pics de Bragg et la segmentation d’images en microscopie de diffraction à haute énergie. Au fil de ces tâches, CVEvolve découvre des algorithmes qui surpassent les méthodes de référence, tandis que le suivi des tests sur des données hors jeu permet d’identifier les candidats qui généralisent mieux que des alternatives ultérieures ayant fait l’objet d’une sur-optimisation.
One-sentence Summary
CVEvolve, an autonomous agentic harness with a zero-code interface, discovers scientific data-processing algorithms by combining a multi-round search strategy with lineage-aware stochastic candidate sampling to balance exploration and exploitation, demonstrating improvements over baseline methods on x-ray fluorescence microscopy image registration, Bragg peak detection, and high-energy diffraction microscopy image segmentation while utilizing holdout test tracking to identify candidates that generalize better than later over-optimized alternatives.
Key Contributions
- This work introduces CVEvolve, an autonomous agentic harness featuring a zero-code interface for scientific data-processing algorithm discovery. The system combines a multi-round search strategy with tools for code execution, evaluation implementation, and history management.
- The framework employs a dynamic workflow that grants agents freedom to configure development environments and translate user-provided metric descriptions into executable evaluation procedures. Lineage-aware stochastic candidate sampling balances exploration and exploitation during the search process.
- Experiments demonstrate the framework on representative scientific imaging problems such as X-ray fluorescence microscopy image registration and Bragg peak detection. Results show the agent synthesizes algorithms that rival or exceed manual baselines while using holdout test tracking to ensure robust generalization.
Introduction
Domain scientists frequently encounter bottlenecks when processing complex unstructured data such as microscopy images due to a lack of specialized programming expertise. Prior automated research systems typically rely on structured optimization problems with predefined evaluators, which limits their ability to handle the noisy or variable nature of real-world scientific datasets. To address this challenge, the authors introduce CVEvolve, an autonomous agentic harness designed for zero-code algorithm discovery. The system employs a multi-round search strategy alongside tools for code execution, visual inspection, and agent-managed holdout testing to prevent over-optimization. CVEvolve translates natural language instructions into robust processing pipelines, allowing scientists to develop task-specific algorithms without writing custom evaluation scripts.
Method
CVEvolve is designed as an autonomous search controller wrapped around a large language model (LLM) agent. The system leverages code, data, evaluation, history, and visualization tools to propose, run, and evaluate candidate algorithms. The overall workflow is structured into three primary stages: workspace preparation, baseline evaluation, and algorithm development. Refer to the framework diagram for a comprehensive view of these stages and their interactions.
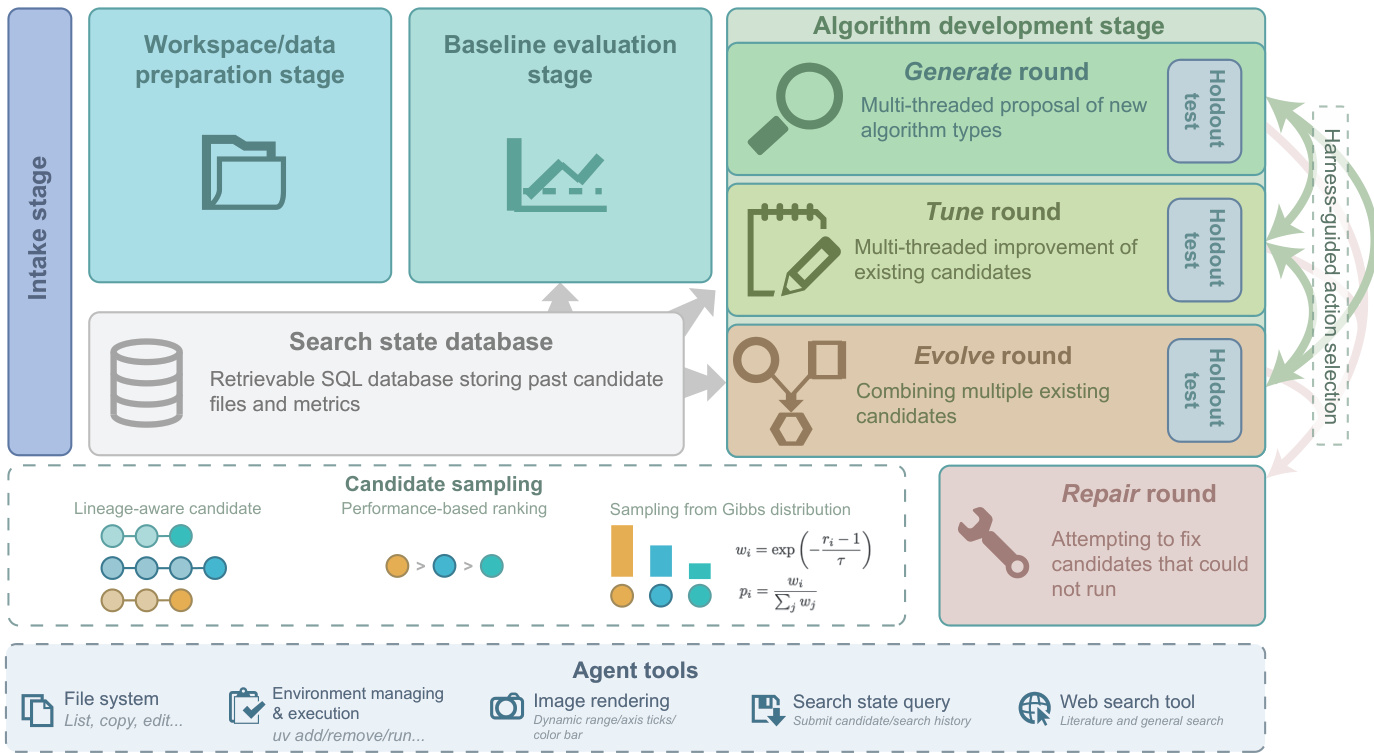
During the intake stage, the agent prepares the workspace, builds the environment, and implements the performance evaluation. The baseline evaluation stage follows, where the agent assesses user-provided or suggested baseline algorithms to establish a performance benchmark. The core of the system lies in the algorithm development stage, which operates through a series of rounds. In each round, a harness selects one of three actions with distinct strategic focuses: generate, tune, or evolve. The generate action proposes new algorithm types, the tune action improves existing candidates, and the evolve action combines multiple existing candidates. For rounds involving parent candidates, the system employs lineage-aware sampling inspired by MAP-Elites. A holdout test may optionally run at the end of each round on a separate dataset using a dedicated agent to handle unstructured data and evaluation schemes.
To manage the search state, CVEvolve utilizes a persistent relational database. This SQL-backed store retains the candidate pool, round history, and metric definitions, allowing the agent to query past performance and lineage information without relying on in-context memory or vector stores. This design ensures reproducibility and deterministic ranking. Candidate sampling for tune and evolve rounds uses a stochastic approach based on a Gibbs distribution. Let ri∈{1,2,…} denote the rank of candidate i in the eligible pool, where ri=1 is the best. CVEvolve assigns each candidate an unnormalized selection weight:
wi=exp(−τri−1),where τ>0 is a temperature parameter controlling exploration. The actual sampling probability is the normalized Gibbs distribution:
pi=∑jwjwi.As τ→0+, the distribution becomes greedy, concentrating on top-ranked candidates. Larger τ values spread probability mass more broadly. For evolve rounds, a same-lineage penalty is applied to encourage combining different lineages:
w~i=wiλmi,where λ∈[0,1] is the penalty factor and mi is the count of already selected parents sharing the candidate's lineage.
The underlying agent application is implemented using a LangGraph-based framework. The runtime employs a compact node graph that separates message ingestion, model reasoning, tool execution, and optional image follow-up handling. As shown in the figure below:
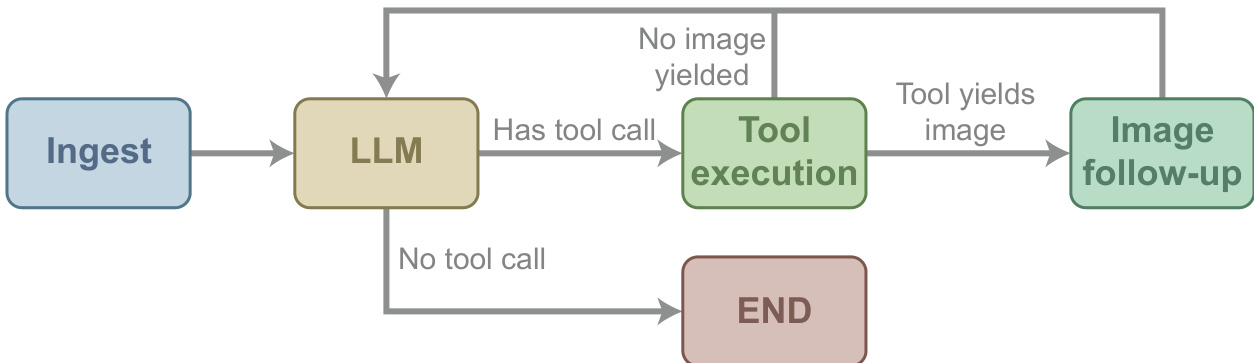
The workflow begins at the Ingest node, which prepares the system and task prompts. The state is passed to the LLM node for reasoning. If the response contains a tool call, it routes to the Tool execution node. If the tool returns a structured response containing an image path, the flow moves to the Image follow-up node. Here, the image is loaded, encoded, and appended as a multimodal observation before returning to the LLM for the next reasoning step. This mechanism allows the agent to inspect visual outputs, such as plots or scientific images, which is critical for tasks involving image processing pipelines like the one illustrated in the flowchart below.
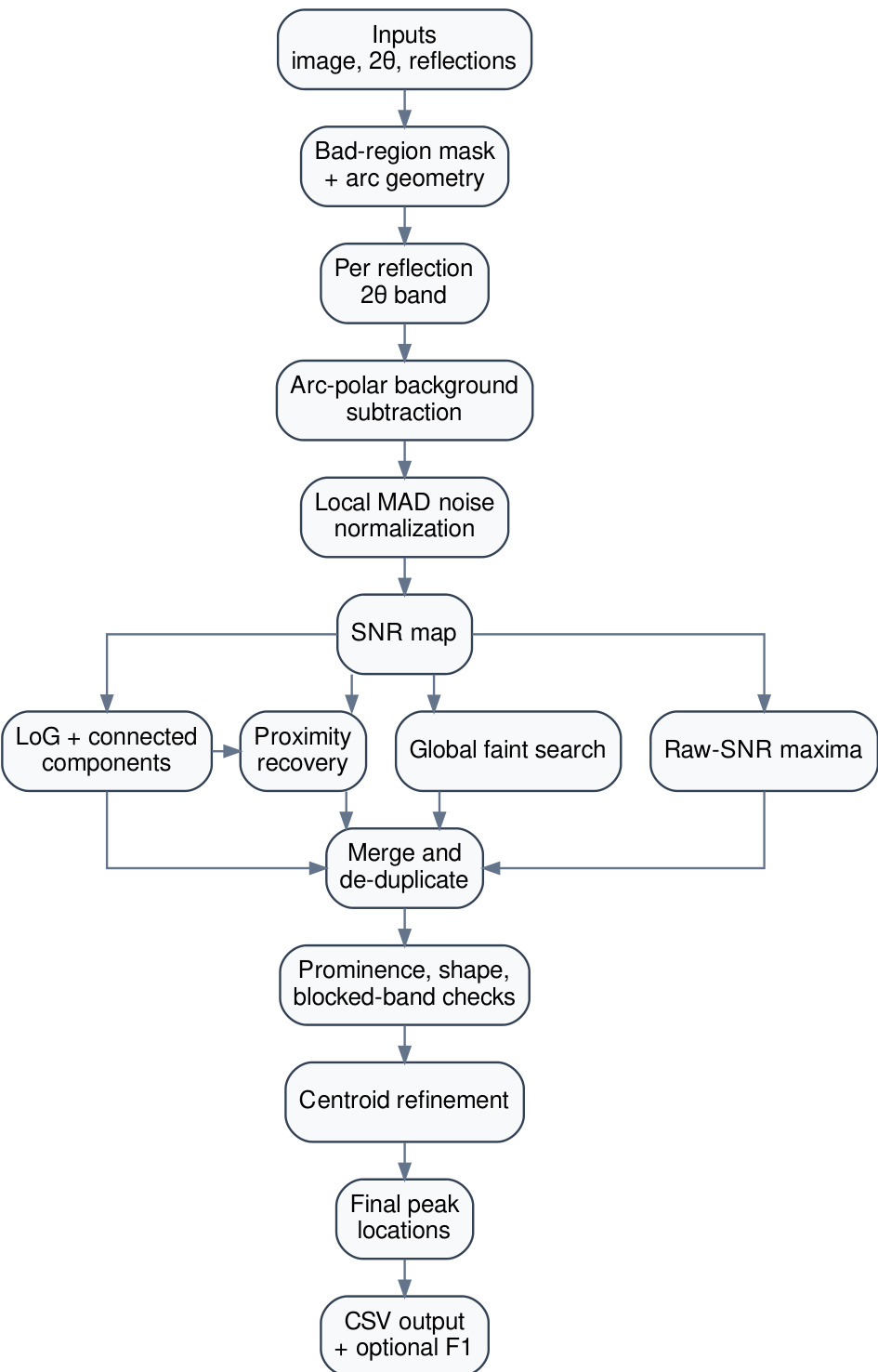
CVEvolve exposes several tool families to support these operations. File system tools allow listing, reading, writing, and editing files within the workspace. Environment management tools enable the installation of dependencies and execution of Python scripts via commands like uv add and uv run. The image viewing tool renders images into agent-viewable PNGs, supporting dynamic range selection and logarithmic scaling to inspect weak structures or high-dynamic-range data. Search state tools permit the agent to log results, inspect history, and submit new candidates. Additionally, web search tools provide access to literature repositories to inform algorithm development.
The system also supports an optional holdout test to evaluate generalization without exposing holdout data during design. When enabled, the main agent receives a prompt describing the holdout folder structure but cannot inspect the data. Upon candidate submission, a separate holdout test agent is spawned in a temporary workspace to run the evaluation and record metrics, ensuring data isolation. Failed candidates are routed to a repair round where the system attempts to fix issues preventing execution.
Experiment
CVEvolve was evaluated across three computer vision tasks involving image registration, peak detection, and segmentation, where it successfully generated robust analytical algorithms that outperformed baseline algorithms and alternative evolution methods. Holdout testing proved critical in preventing overfitting during development, particularly when training data was scarce, while a separate optimization experiment demonstrated the value of stochastic sampling in avoiding local optima. These findings collectively validate the system's ability to produce interpretable, high-performance workflows for complex scientific imaging problems without requiring dedicated GPU resources.
The the the table presents the holdout test errors for the XRF image registration task, comparing baseline algorithms against candidates generated by evolutionary methods. The results demonstrate that the algorithm discovered by CVEvolve achieved the lowest average Euclidean distance, significantly outperforming the brute-force baseline and the candidate found by OpenEvolve. Phase correlation exhibited the highest error, indicating it is less effective for this specific registration problem than the other methods. CVEvolve identified the most accurate algorithm, achieving the lowest registration error among all tested methods. Evolved candidates significantly outperformed the brute-force baseline, which in turn performed better than phase correlation. Phase correlation resulted in the highest error, suggesting standard strategies struggle with the image characteristics of this task.

This experiment evaluates XRF image registration by comparing baseline algorithms against candidates generated through evolutionary methods. The results demonstrate that the algorithm discovered by CVEvolve achieved the lowest registration error, significantly outperforming the brute-force baseline and the candidate found by OpenEvolve. In contrast, phase correlation exhibited the highest error, indicating that standard strategies struggle with the image characteristics of this task compared to the evolved solutions.