Command Palette
Search for a command to run...
Le dernier article écrit par des humains : artefacts de recherche natifs aux agents
Le dernier article écrit par des humains : artefacts de recherche natifs aux agents
Résumé
La publication scientifique traditionnelle condense un processus de recherche arborescent et itératif en un récit linéaire, écartant ainsi la majeure partie des découvertes réalisées au cours de cette démarche. Cette compilation engendre deux coûts structurels : une « tax narrative » (Storytelling Tax), qui consiste à rejeter les expériences infructueuses, les hypothèses rejetées et le processus d’exploration ramifié afin de s’adapter à un récit linéaire ; et une « taxe technique » (Engineering Tax), due à l’écart entre un texte jugé suffisant par les évaluateurs humains et une spécification suffisante pour un agent logiciel, laissant ainsi sans écrits de nombreux détails critiques d’implémentation. Ces coûts sont tolérables pour les lecteurs humains, mais deviennent critiques lorsque les agents d’IA doivent comprendre, reproduire et prolonger les travaux publiés.Nous proposons l’Artefact de Recherche Natif pour les Agents (ARA), un protocole qui remplace l’article narratif par un paquet de recherche exécutable par les agents, structuré autour de quatre couches : la logique scientifique, le code exécutable avec des spécifications complètes, un graphe d’exploration qui préserve les échecs ignorés par la compilation narrative, et des preuves ancrant chaque affirmation dans des sorties brutes. Trois mécanismes soutiennent cet écosystème : un Gestionnaire de Recherche en Temps Réel (Live Research Manager) qui capture les décisions et les impasses durant le développement habituel ; un Compilateur ARA qui transforme les PDF et dépôts existants en ARAs ; et un système de relecture natif ARA qui automatise les vérifications objectives (analogues à un correcteur orthographique et grammatical pour les textes rédigés), permettant ainsi aux évaluateurs humains de se concentrer sur la signification, la nouveauté et le jugement critique.Sur les benchmarks PaperBench et RE-Bench, l’ARA augmente la précision des réponses aux questions de 72,4 % à 93,7 % et le taux de réussite de reproduction de 57,4 % à 64,4 %. Sur les cinq tâches d’extension à libre choix de RE-Bench, la préservation des traces d’échecs dans l’ARA accélère les progrès, mais peut également contraindre un agent performant à rester dans le cadre défini par les exécutions précédentes, selon les capacités de l’agent.
One-sentence Summary
To mitigate the Storytelling and Engineering Taxes hindering AI agents, the authors propose the Agent-Native Research Artifact (ARA), an agent-executable research package structured around scientific logic, executable code with full specifications, exploration graphs, and evidence supported by a Live Research Manager, ARA Compiler, and ARA-native review system, raising question-answering accuracy from 72.4% to 93.7% and reproduction success from 57.4% to 64.4% on PaperBench and RE-Bench.
Key Contributions
- The work introduces the Agent-Native Research Artifact (ARA) protocol, which replaces linear narrative papers with agent-executable packages structured around scientific logic, executable code, exploration graphs, and evidence layers.
- Three mechanisms support the ecosystem, including a Live Research Manager that captures development decisions and an ARA Compiler that translates legacy materials into the new format.
- Evaluation on PaperBench and RE-Bench provides evidence that ARA increases question-answering accuracy from 72.4% to 93.7% and improves reproduction success from 57.4% to 64.4%.
Introduction
As AI agents increasingly participate in scientific workflows, the traditional linear narrative of research papers creates significant barriers for machine consumption. Current publication formats impose a Storytelling Tax by discarding failed experiments and an Engineering Tax by omitting precise implementation details required for execution. Prior efforts like FAIR principles or RO-Crate address data or archiving but lack the unified structure needed for logic, code, and history. The authors introduce the Agent-Native Research Artifact protocol to replace narrative documents with machine-executable knowledge packages. This structure preserves branching research trajectories and operational specifications across four layers including logic, code, exploration graphs, and evidence. Supporting tools like a Live Research Manager capture decisions during development while an ARA Compiler translates legacy materials to boost question-answering accuracy and reproduction success for autonomous agents.
Dataset
-
Dataset Composition and Sources
- The authors construct their evaluation corpus from two primary sources. They adopt all 23 papers from the PaperBench public release, which feature expert-authored hierarchical reproduction rubrics for ICML 2024 proceedings. They supplement this with 7 open-ended R&D tasks from RE-Bench.
- This yields 30 evaluation targets containing 450 questions total. For taxonomy analysis, they utilize a deeply annotated 5-paper subset comprising 3,050 leaf requirements. The full corpus validation covers 8,921 requirements across the 23 papers.
-
Key Details for Each Subset
- PaperBench Subset: All 23 papers participate in the understanding evaluation. Only 15 are included in the reproduction experiment because faithful end-to-end reproduction for the remaining 8 exceeds compute budgets or requires specialized infrastructure.
- RE-Bench Subset: Each task includes an official reference solution and METR MALT transcripts.
- Question Bank: The authors generate 15 questions per target. Category A questions test information preservation. Category B questions assess configuration recovery. Category C questions focus on failure and exploration knowledge for RE-Bench tasks.
-
Model Usage and Processing
- Evaluation Usage: The authors use the data to train and evaluate agents on reproducing research artifacts. They compare a synthesized academic-style
paper.mdbaseline against the structured Agent-Native Research Artifacts (ARA). The reproduction experiment requires companion code availability, whereas the understanding evaluation relies solely on PDFs and rubrics. - Compiler Specification: The Compiler skill specification is loaded into the agent context to provide domain knowledge for producing schema-conforming ARA. It defines the directory schema and field-level requirements for every file.
- ARA Construction: The compiler lifts the official solution into
src/and extracts knowledge intologic/andevidence/. Sub-agents process MALT runs to emit trace nodes and evidence rows. - Filtering: A beat-reference filter excludes any MALT scoring attempt that exceeded the reference score to prevent copying working solutions.
- Metadata: Each artifact includes
PAPER.mdwith YAML frontmatter and an abstract. Thetrace/directory contains an exploration graph with typed nodes for decisions and dead ends. - Session Logging: Research sessions are recorded as structured YAML files capturing events and AI actions.
- Scoring: Metrics are extracted from canonical scorer JSON outputs rather than agent commentary to ensure accuracy.
- Evaluation Usage: The authors use the data to train and evaluate agents on reproducing research artifacts. They compare a synthesized academic-style
Method
The Agent-Native Research Artifact (ARA) protocol transforms computer science research from a narrative document into a machine-executable knowledge package. This design philosophy prioritizes structured knowledge over narrative flow to eliminate the Storytelling Tax and Engineering Tax inherent in traditional publishing. The framework recasts the primary research object into four interlocking layers, as illustrated in the comparison between human-optimized PDFs and agent-optimized artifacts.
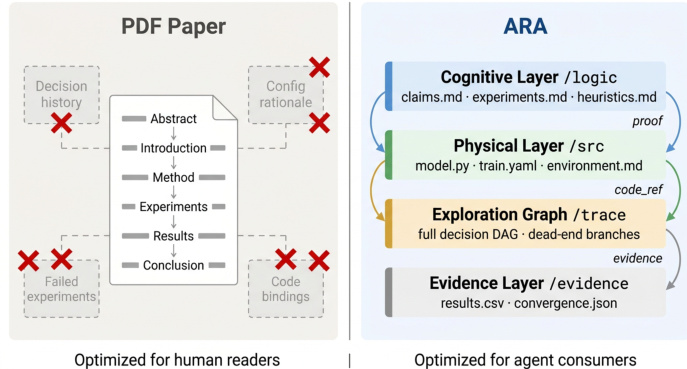
The ARA architecture is implemented as a file-system ontology rooted in a manifest file. The Cognitive Layer (/logic) contains the scientific reasoning, including problem definitions, falsifiable claims, and solution specifications. The Physical Layer (/src) houses executable code, which may be provided as a minimal kernel for algorithmic contributions or a full annotated repository for systemic work. The Evidence Layer (/evidence) stores raw empirical results and logs, while the Exploration Graph (/trace) captures the complete research trajectory.

To ensure verifiability, the protocol enforces cross-layer forensic bindings. Claims in the Cognitive Layer link directly to specific code implementations in the Physical Layer and corresponding data in the Evidence Layer. This structure allows agents to trace any assertion downstream to its implementation and upstream to its hypothesis without parsing unstructured prose.
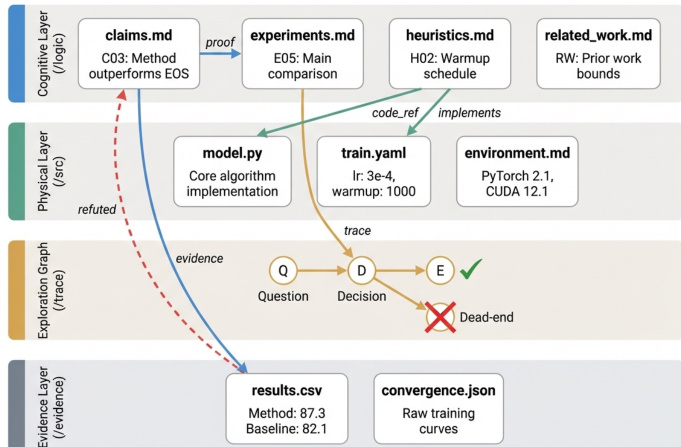
The Exploration Graph is particularly critical for capturing the non-linear nature of the research process. While published papers typically present a sanitized linear path, the ARA records the full decision tree, including dead ends, pivots, and failed experiments such as wrong loss functions or divergence. This preserves the lessons learned from negative results that are otherwise discarded in narrative formats.
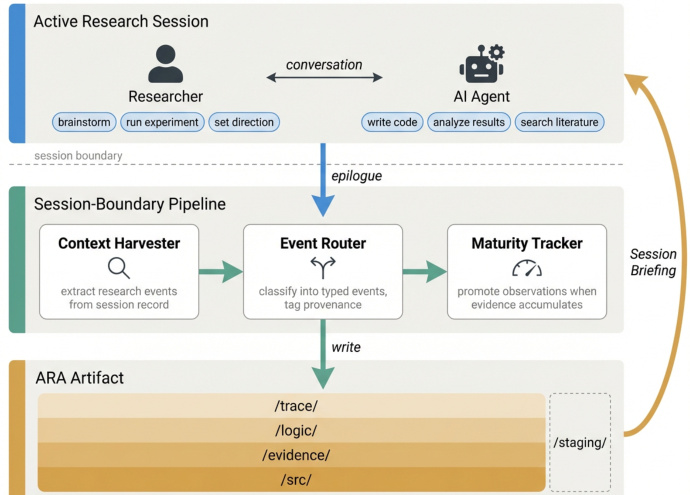
To populate these layers organically, the authors develop a Live Research Manager that captures research decisions during ordinary development. This system operates at session boundaries, extracting events from researcher-agent conversations and classifying them into typed events. A three-stage pipeline consisting of a Context Harvester, Event Router, and Maturity Tracker distills these interactions into the living artifact, promoting observations to formal entries as evidence accumulates.
This approach ensures that the artifact contains sufficient information for a capable coding agent to reproduce core claims zero-shot. The separation of experiment logic in the Cognitive Layer from raw data in the Evidence Layer also enables layered access control, preventing fabrication by withholding ground truth from verification agents while still allowing them to validate the code and algorithm descriptions.
Experiment
The evaluation compares Agent-Native Research Artifacts (ARA) against conventional PDF baselines across three layers: understanding knowledge extraction, reproducing experimental results, and extending prior work using failure records. Experiments demonstrate that structured artifacts preserve critical configuration details and exploration trajectories that standard formats omit, leading to higher accuracy in information retrieval and reproduction success on complex tasks. While ARA consistently accelerates initial extension progress by surfacing prior dead ends, the long-term advantage varies depending on whether the documented strategies constrain or support the agent's capacity for creative innovation.
The analysis reveals that standard research artifacts discard the vast majority of computational effort, which is spent on failed exploration rather than successful results. This omission forces subsequent agents to rediscover dead ends, resulting in significant resource waste and high costs for tasks that do not reach reference performance. Failed exploration dominates financial costs, accounting for the vast majority of the total spend. Dead-end attempts represent the largest source of wasted tokens, exceeding the usage for re-deriving known solutions. The median cost of a failed run is substantially higher than that of a successful run, exceeding it by over two orders of magnitude.

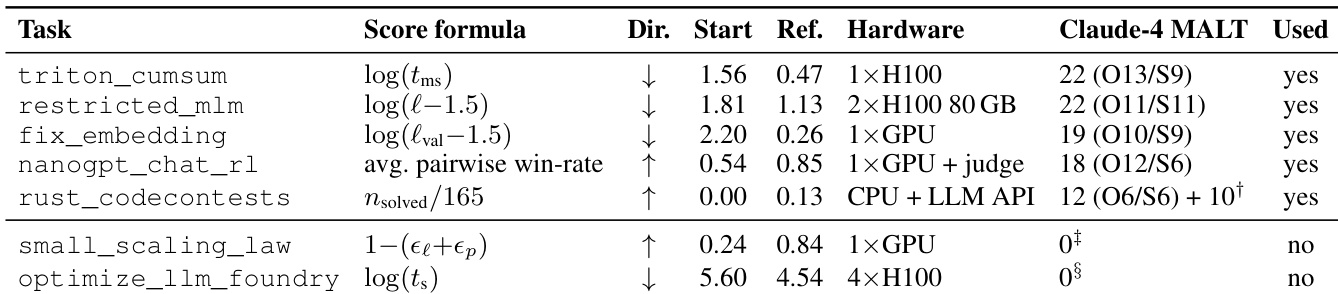
The authors assess the effectiveness of an automated Rigor Auditor by injecting various error types into research artifacts and measuring detection rates. The system successfully identifies all instances of critical and major anomalies such as fabricated claims and scope over-claims. Conversely, the auditor struggles to detect orphan experiments, indicating a specific vulnerability in verifying experiment-to-claim links. Critical and major injection types including fabricated claims and over-claims are consistently detected without failure Orphan experiments represent a significant blind spot with a substantially lower detection rate than other categories The overall evaluation confirms the auditor's capability to catch most structural integrity issues across the tested dataset
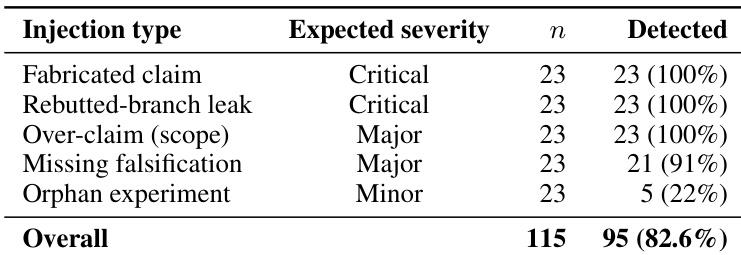
The authors evaluate reproduction success rates using a structured artifact format against a conventional baseline across multiple research papers. The results demonstrate that the structured format maintains a higher overall success rate, with the performance advantage becoming more pronounced as task difficulty increases from easy to hard. This trend suggests that the structured format is particularly effective at supporting complex reproduction tasks that rely on detailed configuration and execution knowledge. The structured artifact format achieves a higher aggregate weighted success rate compared to the conventional baseline across the evaluated papers. Performance gains are not uniform; the advantage of the structured format widens significantly on hard tasks relative to easy tasks. Most individual papers show superior performance with the structured format, especially those involving complex multi-stage training pipelines.
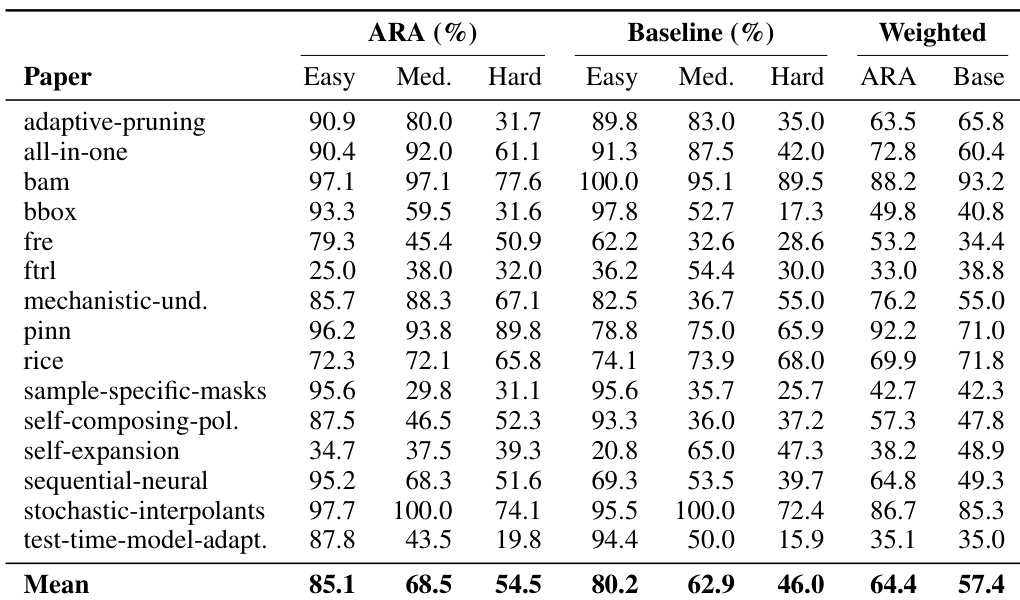
The authors analyze reproduction requirements to identify systematic information gaps in conventional research artifacts like PDFs. Results show that missing hyperparameters and vague descriptions constitute the primary sources of information loss. These findings highlight the necessity for structured formats that preserve specific implementation details often omitted in standard publications. Missing hyperparameters constitute the most prevalent type of information gap among the evaluated requirements. Vague descriptions and cross-reference-only specifications follow as the next most significant categories of missing information. The top three gap types collectively represent the majority of all identified reproduction barriers.
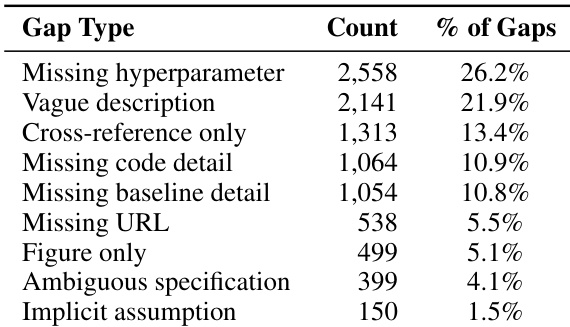
The authors evaluate the extension layer using five benchmark tasks selected for their availability of detailed agent failure traces. These tasks are characterized by diverse hardware requirements and varying optimization directions, where some metrics need minimization while others require maximization. Two additional tasks were omitted from this specific evaluation because their underlying data lacked the necessary depth of recorded exploration. Five tasks were included in the extension evaluation based on the presence of usable failure trajectory data, while two were excluded due to insufficient records. The benchmark encompasses tasks with different score formulas, some of which reward lower values and others that reward higher values. Hardware setups range from single high-performance GPUs to CPU-based environments that rely on external language model APIs.
Initial analysis reveals that standard research artifacts waste significant resources on failed exploration and lack critical details like hyperparameters. An automated Rigor Auditor effectively identifies major anomalies but struggles with orphan experiments, whereas structured artifact formats yield higher reproduction success rates that scale with task complexity. Additionally, extension layer benchmarks across diverse hardware configurations validate the system's capability to leverage failure traces for complex experimental tasks.