Command Palette
Search for a command to run...
Réparation chirurgicale des têtes d'attention effondrées dans les transformateurs ALiBi
Réparation chirurgicale des têtes d'attention effondrées dans les transformateurs ALiBi
Palmer Schallon
Attention avec biais linéaires (ALiBi)
Résumé
Nous identifions une pathologie systématique d’effondrement de l’attention dans la famille de modèles de langage à base de transformeurs BLOOM, où l’encodage positionnel ALiBi conduit 31 à 44 % des têtes d’attention à se concentrer presque exclusivement sur le jeton de début de séquence. Cet effondrement suit un motif prévisible à travers quatre échelles de modèles (de 560 millions à 7,1 milliards de paramètres), se concentrant dans les indices de têtes où le calendrier des pentes d’ALiBi impose les pénalités de distance les plus sévères. Nous introduisons la réinitialisation chirurgicale : une réinitialisation ciblée des projections Q/K/V avec des projections de sortie nulles et un gel masqué par gradient de tous les paramètres non chirurgicaux. Appliquée à BLOOM-1b7 sur un seul GPU grand public, cette technique permet de récupérer 98,7 % de la capacité opérationnelle des têtes (passant de 242 à 379 des 384 têtes) en deux passes. Une comparaison contrôlée avec les données d’entraînement C4 confirme que c’est la réinitialisation, et non le contenu du corpus, qui entraîne la récupération, et révèle deux phénomènes distincts post-chirurgicaux : une redistribution fonctionnelle globale précoce qui améliore le modèle, et une dégradation locale tardive qui s’accumule sous l’effet d’un signal d’entraînement bruité. Une expérience prolongée consistant à réinitialiser des têtes majoritairement saines ainsi que des têtes effondrées produit un modèle qui surpasse temporairement le BLOOM-1b7 standard de 25 % en perplexité d’entraînement (12,70 contre 16,99), suggérant que les configurations d’attention pré-entraînées constituent des minima locaux sous-optimaux. Le code, les points de contrôle et les outils de diagnostic sont publiés en tant que logiciel open source.
One-sentence Summary
To repair the systematic attention collapse in ALiBi-based BLOOM transformers, this study introduces surgical reinitialization, defined as targeted Q/K/V reinitialization with zeroed output projections and gradient-masked freezing of non-surgical parameters, which successfully restores 98.7% of operational head capacity (242 to 379 of 384 heads) in BLOOM-1b7 on a single consumer GPU, reduces training perplexity to 12.70 from 16.99, and demonstrates through controlled C4 comparisons that the technique itself drives recovery while suggesting pretrained configurations occupy suboptimal local minima.
Key Contributions
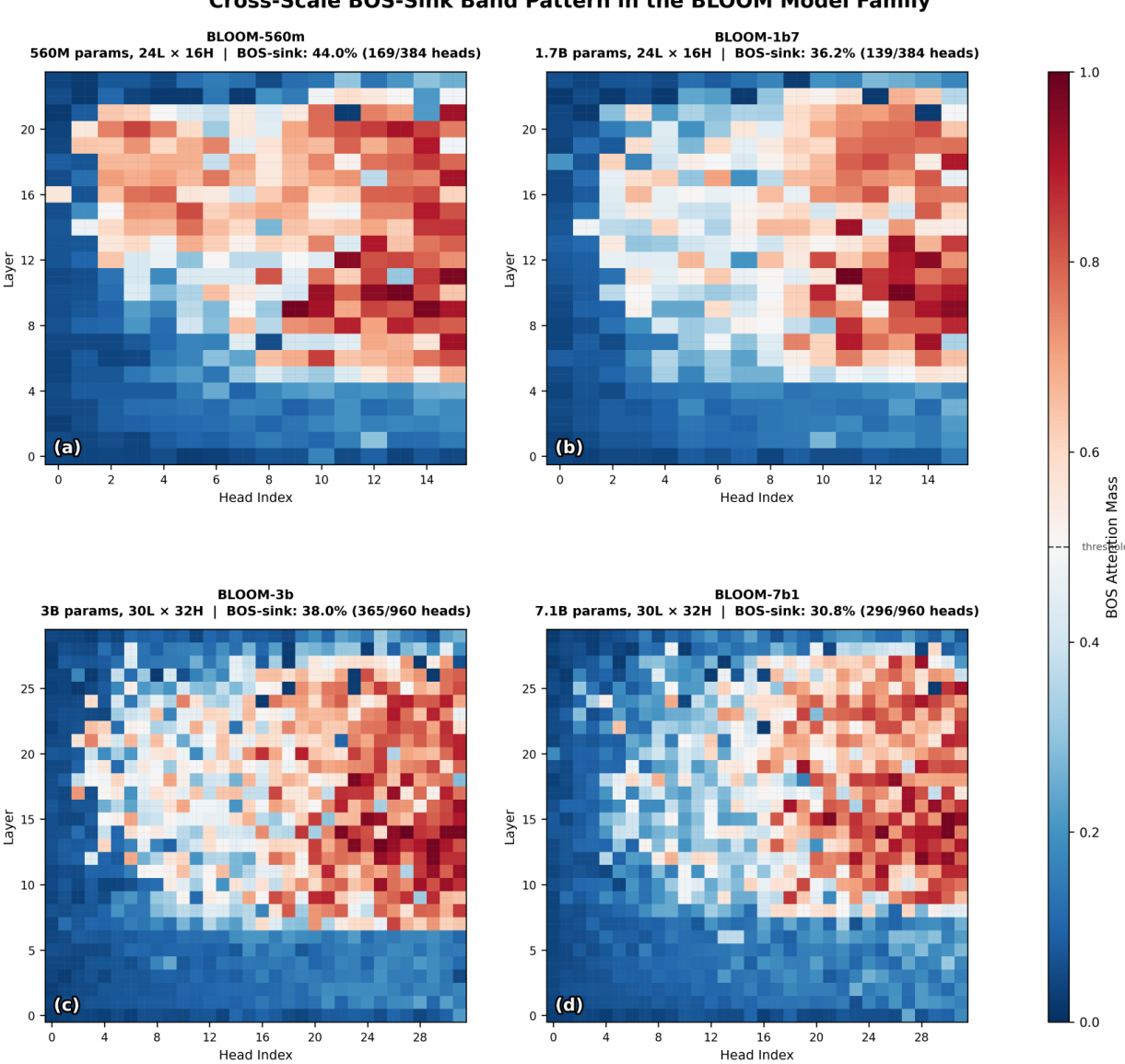
- The analysis identifies a systematic attention collapse pathology in the BLOOM family of transformer models, where ALiBi positional encoding forces 31-44% of attention heads to disproportionately attend to the beginning-of-sequence token. This collapse follows a predictable distribution across model scales from 560M to 7.1B parameters, concentrating in head indices where ALiBi slope schedules impose the steepest distance penalties.
- A surgical reinitialization procedure is introduced that selectively updates query, key, and value matrices while applying zeroed output projections and gradient-masked freezing to all non-surgical parameters. This targeted update strategy revives dormant attention capacity without requiring architectural modifications.
- Applied to the BLOOM-1b7 model on a single consumer GPU, the technique recovers 98.7% of operational attention heads in two training passes. Extended experiments demonstrate a 25% reduction in training perplexity compared to the stock model, indicating that standard pretrained attention configurations often reside in suboptimal local minima.
Introduction
Attention head pruning has become a standard compression technique for transformer language models, enabling faster inference by removing components that disproportionately attend to the beginning-of-sequence token. Prior research treats these collapsed heads as functionally redundant, operating under the assumption that their removal safely reduces computational overhead without degrading performance. The authors challenge this premise by demonstrating that BOS-sink collapse is not a symptom of unused capacity but a systematic artifact induced by ALiBi positional encoding. Rather than discarding these components, they show that collapsed heads remain dormant and can be successfully reinitialized, recovering functional attention capacity that measurably enhances model behavior while avoiding irreversible structural damage.
Dataset
- Dataset composition and sources: The authors do not specify the dataset composition or sources in the provided excerpt.
- Key details for each subset: Information regarding subset sizes, origins, and filtering rules is absent.
- Data usage and splits: The authors do not describe training splits, mixture ratios, or processing workflows.
- Processing and metadata: No cropping strategies, metadata construction steps, or additional preprocessing details are mentioned. The provided text only contains the paper title and author attribution.
Method
The authors leverage a targeted surgical reinitialization approach to repair attention collapse in BLOOM-family transformer models, addressing a systematic pathology where a significant fraction of attention heads disproportionately attend to the beginning-of-sequence (BOS) token. This collapse, observed across four model scales, is linked to the ALiBi positional encoding scheme, which imposes steeper distance penalties on higher head indices, leading to a predictable concentration of collapsed heads in specific layers and head positions.
The overall framework begins with a diagnostic phase to identify collapsed attention heads. For each head, two metrics are computed: BOS mass, which measures the average attention weight assigned to the BOS token across all query positions, and entropy, which quantifies the distributional breadth of attention across positions. These metrics are derived from attention matrices Aℓ,h for layer ℓ and head h over a sequence length T. The diagnostic prompt is chosen for its semantic density and varied dependency structure, ensuring that the observed bimodal distribution of head behavior reflects intrinsic weight properties rather than input-specific effects. Heads are classified as collapsed based on thresholds: high BOS mass (above 0.50) and low entropy (below 0.50), with additional confirmation via a DEAD score threshold of 0.95.
Following diagnosis, the surgical reinitialization process is applied to recover functional capacity. For each identified collapsed head, four operations are performed: the Q, K, and V projection weights are reinitialized using Xavier normal initialization to escape the BOS-sink local minimum; the dense output projection is zeroed to ensure the head contributes nothing to the residual stream during the initial recovery phase, thus preventing destabilization; all non-surgical parameters are frozen via gradient masking, which zeros gradients during backpropagation; and only the surgical parameters are trained on a training corpus. This approach is motivated by empirical evidence showing that gradient-only fine-tuning fails to recover collapsed heads, as the BOS-sink state represents a sharp local minimum that gradient descent cannot escape without a reset.
The technique is applied in two passes to BLOOM-1b7. In the first pass, 108 heads in the H9–H15 band across layers 5–22 are targeted, with five already-healthy in-band heads kept frozen to maintain stability. This pass recovers a substantial portion of the lost capacity, but introduces a rare iatrogenic effect where two previously healthy heads at layer 23 become collapsed. The second pass addresses the remaining 39 collapsed heads outside the H9–H15 band, using the best checkpoint from the first pass as the starting point. This two-pass strategy reflects an attention ecology where stabilizing the primary band first allows the model’s attention topology to reorganize before addressing outliers, enabling full recovery of 98.7% of operational head capacity (242 → 379 of 384 heads).
An extended experiment demonstrates that the same surgical technique, when applied to mostly-healthy heads, yields a model that transiently outperforms the stock model by 25% on training perplexity. This suggests that pretrained attention configurations may represent suboptimal local minima, and targeted reinitialization can access better configurations that standard training dynamics cannot reach. The recovery process is driven by the surgical intervention itself, not the training corpus, as confirmed by a controlled comparison with C4 data. This comparison reveals two distinct post-surgical phenomena: early global functional redistribution that enhances model performance, and late local degradation that accumulates under noisy training signals.
Experiment
The evaluation employs targeted reinitialization of specific attention heads followed by brief fine-tuning on curated or generic corpora, with experiments validating head recovery, global topology shifts, and generation quality. Qualitative analysis reveals that surgical intervention successfully revives collapsed heads and triggers widespread, functional reorganization across the attention network through the shared residual stream. Additionally, experiments demonstrate that pretrained attention patterns frequently occupy suboptimal local minima, as reinitializing both collapsed and nominally healthy heads enables the discovery of superior configurations. Ultimately, the findings establish that transformer attention operates as an interconnected ecology where targeted modifications yield both therapeutic repair and structural reoptimization, though sustained performance gains require sufficiently large corpora to prevent overfitting.
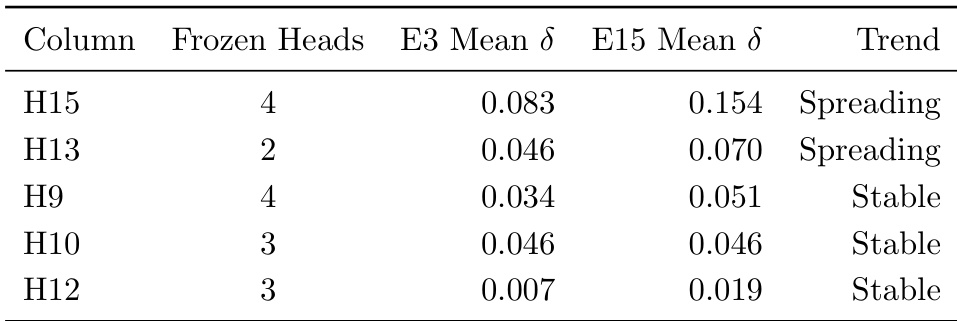
The the the table compares the effects of different training conditions on attention head redistribution in a BLOOM model. Results show that the curated corpus leads to more extensive global redistribution of attention heads compared to the C4 corpus, with a higher number of drifting heads and a larger average change in BOS mass. The C4 corpus, especially after extended training, exhibits a higher worst-case drift in specific heads, indicating localized degradation. These findings support the conclusion that training data influences the quality and scope of attention redistribution following surgical intervention. The curated corpus induces more global attention head redistribution than the C4 corpus, as measured by a higher number of drifting heads and larger average change in BOS mass. Extended training on the C4 corpus leads to increased worst-case drift in specific heads, suggesting localized degradation not observed in the curated condition. The curated corpus achieves more effective redistribution at matched epochs, resulting in lower training perplexity compared to the C4 baseline.

The authors compare training perplexity across different surgical interventions on the BLOOM-1b7 model, showing that both band-only surgery and extended surgery including healthy heads reduce training perplexity compared to the stock model. The best performance is achieved with the extended surgery when evaluated at the optimal sub-epoch point, indicating that reinitializing non-collapsed heads can lead to improved attention patterns. The improvements are transient, as perplexity increases after overfitting begins. Extended surgery including healthy heads achieves lower training perplexity than band-only surgery. The best training performance occurs at an intermediate sub-epoch point before overfitting begins. Reinitializing non-collapsed heads leads to improved attention patterns, suggesting the pretrained model was in a local minimum.

The the the table compares the effects of different training conditions on attention head behavior, showing that the curated corpus leads to more drifting heads and a higher mean change in BOS mass compared to the C4 corpus at the same epoch, while the C4 corpus at a later epoch shows increased drifting heads and a higher mean change. This suggests that the curated corpus drives more significant global redistribution of attention patterns early in training, whereas the C4 corpus results in more localized drift over time. The curated corpus induces more attention head drifting and higher mean change in BOS mass than the C4 corpus at the same training epoch. The C4 corpus at a later epoch shows increased head drifting and mean change compared to an earlier epoch, indicating local degradation over time. The curated corpus achieves more global redistribution early in training, while the C4 corpus exhibits more localized drift as training progresses.
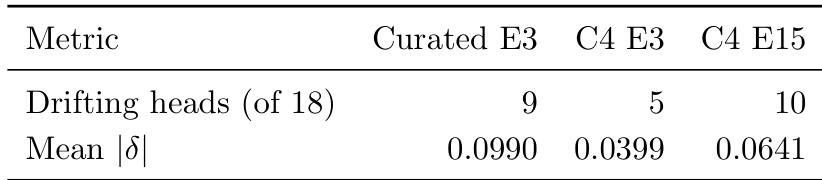
The the the table presents data on frozen head drift across different head columns during training, showing that H15 exhibits spreading drift while H9, H10, and H12 remain stable. The drift is measured as the mean change in BOS mass between epoch 3 and epoch 15, with H15 showing significantly higher values, indicating a progressive increase in attention pattern changes. This suggests that certain head indices are more susceptible to redistribution over time, particularly under continued training on noisy data. H15 shows spreading drift with higher mean delta values, indicating progressive attention pattern changes H9, H10, and H12 exhibit stable drift, suggesting resistance to redistribution The difference in drift patterns across columns highlights architectural vulnerability to cascade effects
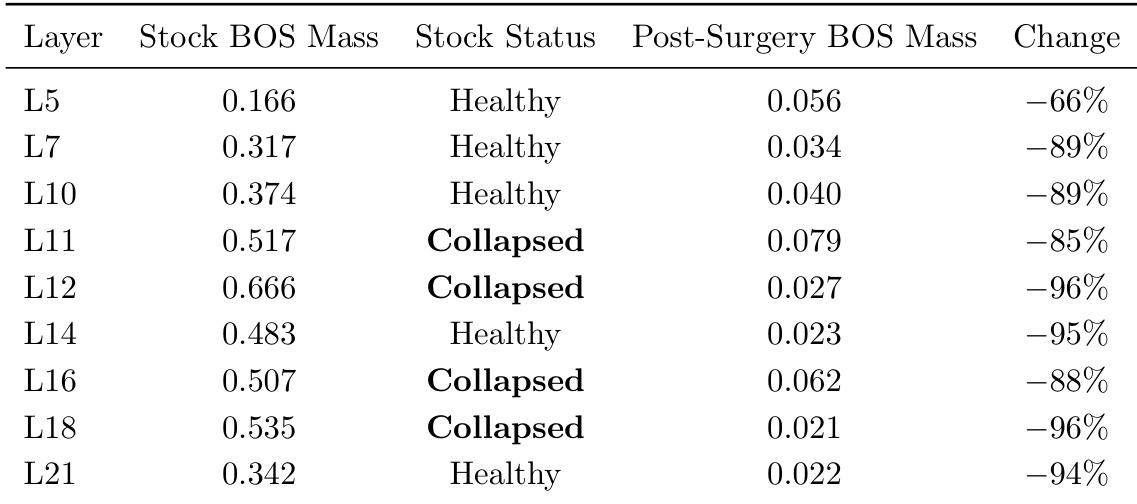
The the the table shows the BOS mass for selected heads in the BLOOM-1b7 model before and after surgical reinitialization, indicating a significant reduction in BOS mass for both healthy and collapsed heads. The results demonstrate that the surgical technique not only recovers collapsed heads but also improves the attention patterns of healthy ones, leading to a more optimal configuration. This supports the finding that the pretrained attention topology is a local minimum, and reinitialization enables access to better configurations. Surgical reinitialization reduces BOS mass for both healthy and collapsed heads, indicating improved attention patterns. The technique enables recovery of collapsed heads and enhances healthy heads, suggesting it is not just repair but reoptimization. The results support the idea that pretrained attention patterns are local minima, and better configurations can be accessed through reinitialization.
The experiments evaluate attention head redistribution and training dynamics in a BLOOM-1b7 model under varying surgical interventions and training corpora. Comparisons across data sources validate that curated corpora drive more global attention redistribution early in training, while standard datasets tend to cause localized degradation over extended periods. Surgical intervention tests confirm that reinitializing both collapsed and healthy heads successfully escapes local minima, reoptimizing attention patterns and reducing perplexity more effectively than partial approaches. Finally, head drift analyses reveal that certain architectural positions are inherently more susceptible to progressive redistribution, underscoring the importance of holistic retraining strategies for model stability.