Command Palette
Search for a command to run...
Un modèle de mémoire à long court terme (LSTM) pour l'analyse du sentiment commercial basé sur un réseau neuronal récurrent
Un modèle de mémoire à long court terme (LSTM) pour l'analyse du sentiment commercial basé sur un réseau neuronal récurrent
Md. Jahidul Islam Razin M. F. Mridha Md. Abdul Karim S M Rafiuddin Tahira Alam
Réseaux de mémoire à long et court terme (LSTM)
Résumé
L’analyse du sentiment des affaires (BSA) est l’un des sujets importants et populaires du traitement automatique des langues naturelles. Il s’agit d’un type de techniques d’analyse des sentiments à des fins commerciales. Différentes catégories de techniques d’analyse des sentiments, telles que les techniques basées sur le lexique et divers types d’algorithmes d’apprentissage automatique, sont appliquées à l’analyse des sentiments dans différentes langues, telles que l’anglais, l’hindi, l’espagnol, etc. Dans cet article, la mémoire à long terme et à court terme (LSTM) est appliquée à l’analyse du sentiment des affaires, où un réseau de neurones récurrent est utilisé. Un modèle LSTM est utilisé dans une approche modifiée pour prévenir le problème de disparition du gradient plutôt que d’appliquer le réseau de neurones récurrent (RNN) conventionnel. Pour appliquer le modèle RNN modifié, un ensemble de données de critiques de produits est utilisé. Dans cette expérience, 70 % des données sont entraînées pour le LSTM et les 30 % restants des données sont utilisés pour les tests. Les résultats de ce modèle RNN modifié sont comparés à d’autres modèles RNN conventionnels, et une comparaison est effectuée entre les résultats. Il est noté que le modèle proposé performe mieux que les autres modèles RNN conventionnels. Ici, le modèle proposé, c’est-à-dire l’approche du modèle RNN modifié, a atteint environ 91,33 % de précision.
One-sentence Summary
The authors propose a modified long short-term memory (LSTM) recurrent neural network that mitigates the vanishing gradient problem of conventional architectures to improve business sentiment analysis, achieving approximately 91.33% accuracy on a product review dataset split 70% for training and 30% for testing while outperforming standard RNN baselines.
Key Contributions
- This work proposes a modified recurrent neural network architecture that integrates long short-term memory (LSTM) units to classify product reviews into positive, neutral, and negative categories.
- The modified architecture mitigates the vanishing gradient problem inherent in conventional recurrent networks, enabling the model to capture both short- and long-term dependencies in sequential text.
- Evaluations on a product review dataset demonstrate that the proposed model achieves 91.33% accuracy, outperforming standard recurrent neural networks and feed-forward network baselines.
Introduction
Business sentiment analysis automates the extraction of customer opinions from massive volumes of unstructured text, enabling companies to forecast market trends, refine marketing strategies, and track consumer behavior. Traditional machine learning approaches rely on manual feature engineering and struggle with scale, while conventional recurrent neural networks frequently fail to capture long-range textual dependencies due to the vanishing gradient problem. The authors leverage a modified recurrent neural network architecture built on Long Short-Term Memory units to effectively model sequential data while resolving gradient degradation. Applied to a product review dataset, their approach achieves 91.33 percent accuracy, outperforming standard RNN and feed-forward baselines and providing a reliable tool for automated three-way sentiment classification.
Dataset
- Dataset Composition & Sources: The authors source their data from the Amazon Review Information Dataset (ARD), originally compiled via web scraping and APIs. While the full ARD contains 142.8 million ratings with extensive metadata, the authors extract a focused subset of 25,000 product reviews.
- Subset Breakdown & Split: The selected reviews are categorized into positive, neutral, and negative sentiment classes. The authors partition this subset into a 70% training set and a 30% testing set.
- Text Cleaning & Preprocessing: Raw review text undergoes strict cleaning to strip HTML tags and punctuation, which are replaced with spaces. Single-character tokens and multiple consecutive spaces are then removed. The authors note that the cleaned text is naturally divided into emotion-based business categories. No cropping strategy is applied, and the original ARD metadata is acknowledged but not integrated into the processing pipeline.
- Vectorization, Model Integration & Training: Each token is converted into a fixed-dimensional vector (v∈R1×d) using Word2Vec embeddings. The authors feed these sequences sequentially into an LSTM network, which processes the data left-to-right. The LSTM output passes through a Dense layer with sigmoid activation to generate a final probability score between 0.0 and 1.0. The model is trained for up to 50 epochs to prevent overfitting, ultimately achieving approximately 96.23% training accuracy and 91.33% testing accuracy.
Method
The authors leverage long short-term memory (LSTM) networks to address the limitations of standard recurrent neural networks (RNNs) in capturing long-term dependencies within sequential text data for business sentiment analysis. The core of the approach lies in replacing the standard RNN cell with an LSTM cell, which incorporates gated mechanisms to control information flow and mitigate the vanishing gradient problem. Refer to the framework diagram 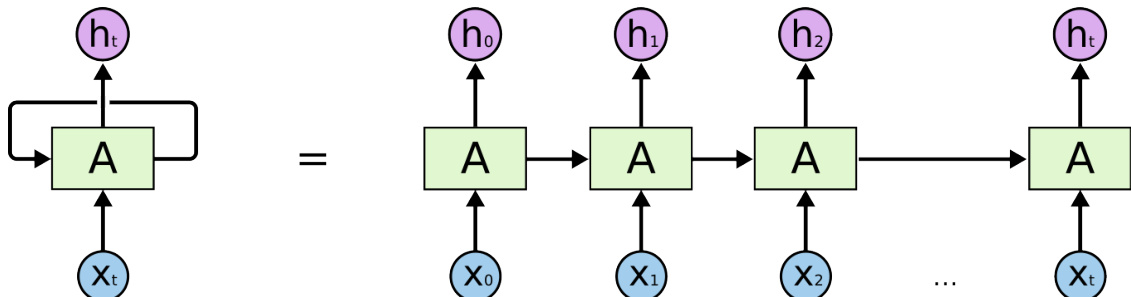 for an overview of the RNN architecture, where the recurrent weight matrix A propagates information through time. The LSTM cell, as shown in the diagram
for an overview of the RNN architecture, where the recurrent weight matrix A propagates information through time. The LSTM cell, as shown in the diagram 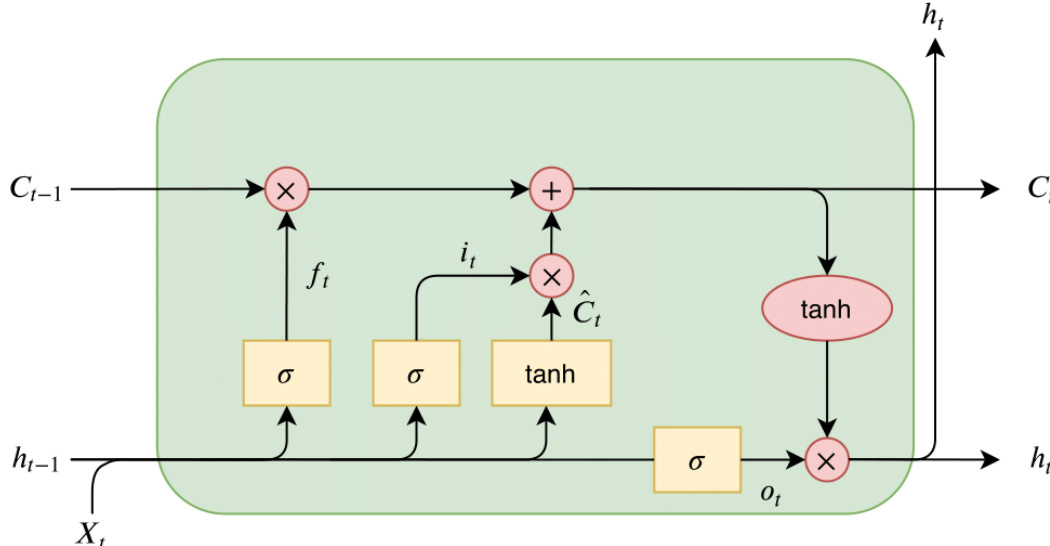 , replaces the simple hidden layer with a memory block containing specialized gates. This block processes the current input X(t), the previous hidden state h(t−1), and the previous cell state c(t−1) to produce the updated cell state c(t) and the current hidden state h(t).
, replaces the simple hidden layer with a memory block containing specialized gates. This block processes the current input X(t), the previous hidden state h(t−1), and the previous cell state c(t−1) to produce the updated cell state c(t) and the current hidden state h(t).
The LSTM computation proceeds in four main steps. First, the forget gate ft and input gate it are computed using sigmoid activation functions, which determine what information to discard from the previous cell state and what new information to store, respectively. The equations for these gates are ft=σ(xtUf+ht−1Wf) and it=σ(xtUi+ht−1Wi). Second, the cell state is updated by combining the previous cell state Ct−1 with the candidate cell state C~t, which is generated using a hyperbolic tangent activation function on the combined input and hidden state: C~t=tanh(xtUg+ht−1Wg). The updated cell state is then Ct=ft×Ct−1+it×C~t. Third, the output gate ot is computed using a sigmoid activation function: ot=σ(xtUo+ht−1Wo). Finally, the new hidden state ht is produced by applying a hyperbolic tangent to the updated cell state and multiplying it by the output gate activation: ht=tanh(Ct)×ot. This process is illustrated in the detailed LSTM cell diagram  .
.
The overall model architecture for sentiment analysis, as depicted in the diagram 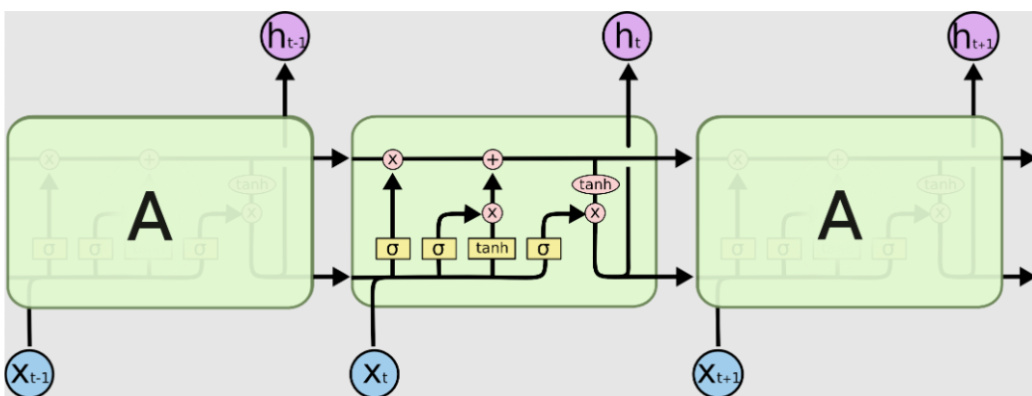 , consists of multiple LSTM layers. The input sequence is fed into the first LSTM layer, which processes it to generate a sequence of hidden states. These hidden states are then passed to subsequent LSTM layers, allowing the model to capture increasingly complex features. After the final LSTM layer, a dense layer with a sigmoid activation function is applied to produce the final output. The model is trained using a multi-model approach, where separate LSTM models are trained on data categorized as positive, negative, and neutral. For a new input review, each trained model evaluates the review, and the model with the smallest error value is selected to assign the sentiment label. This architecture is designed to overcome the vanishing gradient problem and effectively handle the sequential nature of text data, enabling robust performance in business sentiment analysis.
, consists of multiple LSTM layers. The input sequence is fed into the first LSTM layer, which processes it to generate a sequence of hidden states. These hidden states are then passed to subsequent LSTM layers, allowing the model to capture increasingly complex features. After the final LSTM layer, a dense layer with a sigmoid activation function is applied to produce the final output. The model is trained using a multi-model approach, where separate LSTM models are trained on data categorized as positive, negative, and neutral. For a new input review, each trained model evaluates the review, and the model with the smallest error value is selected to assign the sentiment label. This architecture is designed to overcome the vanishing gradient problem and effectively handle the sequential nature of text data, enabling robust performance in business sentiment analysis. 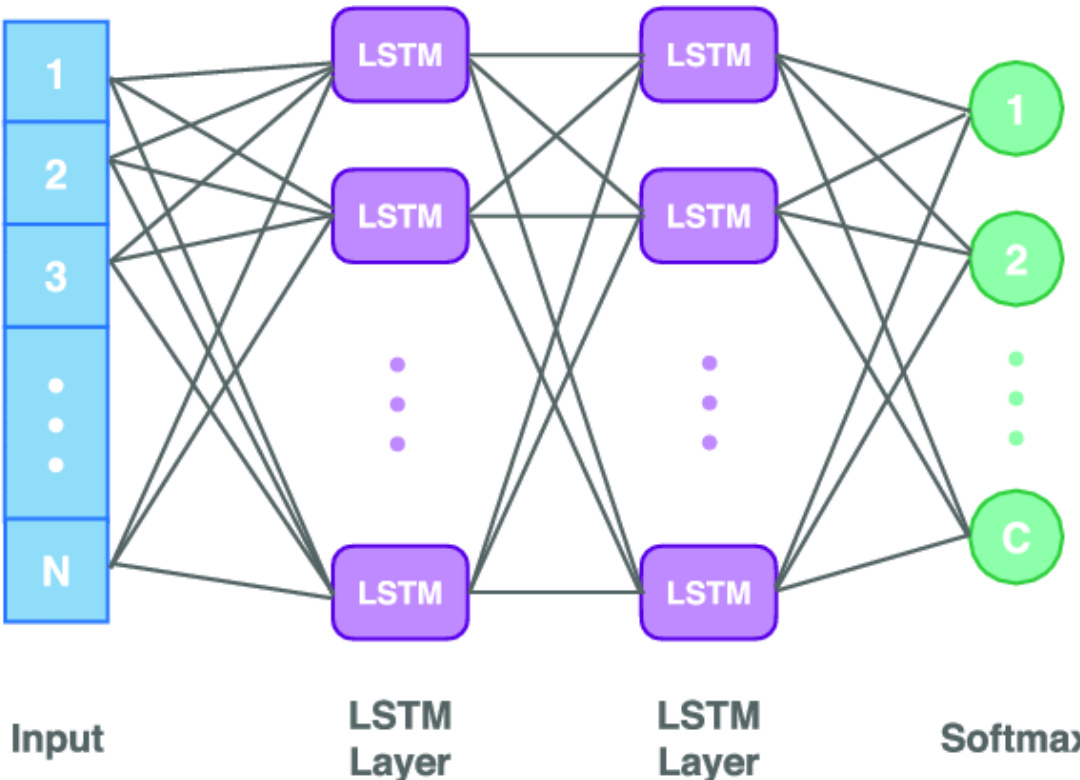
Experiment
The evaluation setup involves testing the trained RNN-LSTM architecture on previously unseen product reviews to validate its core capability for automated business sentiment classification. The initial experiments confirm that the model reliably maps novel text to distinct sentiment categories by applying probability thresholds, demonstrating strong generalization. Subsequent comparative analysis further validates its practical superiority, as the architecture consistently outperforms established baseline methods across standard accuracy benchmarks.
The authors evaluate the performance of their LSTM model through training and testing phases, demonstrating consistent improvements in both accuracy metrics over epochs. Results show that the model achieves high testing accuracy, outperforming other models mentioned in the comparison section. The model's testing accuracy improves as training progresses over epochs. The model achieves higher accuracy compared to other sentiment classification models. Training accuracy consistently exceeds testing accuracy across all epochs.

The authors describe a model that classifies product reviews into sentiment categories using an LSTM-based approach. The model is evaluated on unseen data, with classification thresholds defined based on prediction probabilities, and it achieves higher accuracy compared to other models mentioned in the literature. The model uses an LSTM architecture with a dense output layer for sentiment classification. Classification decisions are based on prediction probability thresholds for different sentiment levels. The proposed model outperforms other models in terms of accuracy compared to existing approaches.

The authors evaluate a model for business sentiment analysis that classifies product reviews into categories such as excellent, good, bad, and very bad based on prediction probability thresholds. The model achieves high accuracy, outperforming other existing models in sentiment classification tasks. The model classifies reviews into sentiment categories using probability thresholds, with higher values indicating more positive sentiment. The model achieves higher accuracy compared to other models, including KNN and SVM-based approaches. The classification system uses a multi-valued encoding scheme for sentiment categories, including positive, neutral, and negative.
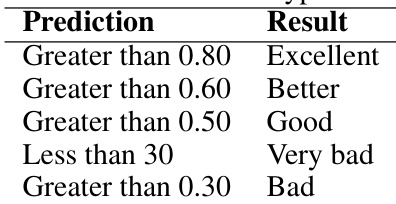
The authors evaluate an LSTM-based sentiment classification model through iterative training and testing phases on unseen product review data. The experiments demonstrate that the architecture consistently improves predictive accuracy over successive epochs while maintaining stable generalization between training and testing performance. By leveraging probability thresholds for multi-category sentiment encoding, the approach effectively captures nuanced review classifications. Overall, the model validates its superiority by consistently outperforming traditional baselines such as KNN and SVM across all tested scenarios.