Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Déploiement en un clic du modèle d'observation de la Terre multi-temporel Prithvi-EO-2.0
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
TimeSenCLIP is a lightweight vision-language model that aligns multispectral Sentinel-2 time series with geo-tagged ground imagery through a cross-view temporal contrastive framework without requiring textual annotations, prioritizing spectral and temporal signals over spatial context to enable zero-shot classification across land cover, land use, habitat mapping, and crop type tasks.
Key Contributions
- The paper introduces TimeSenCLIP, a lightweight vision-language model for remote sensing time series that mitigates the spatial bias of generic architectures by prioritizing spectral and temporal dynamics.
- The framework employs a cross-view temporal contrastive learning strategy to align multispectral Sentinel-2 sequences with geo-tagged ground-level photographs without textual annotations, establishing that single-pixel time series contain sufficient information for diverse geospatial tasks.
- Evaluations on the LUCAS and Sen4Map datasets across land cover, land use, habitat mapping, and crop classification benchmarks demonstrate effective zero-shot performance, while ablation studies confirm that temporal dropout enhances robustness to missing observations.
Introduction
Remote sensing vision-language models have emerged as powerful tools for land-use and ecosystem mapping, enabling zero-shot classification and text-driven retrieval without relying on exhaustive class-specific supervision. These models facilitate scalable environmental monitoring by allowing users to query satellite imagery with natural language descriptions, which is particularly valuable for capturing fine-grained ecological nuances that traditional taxonomies often miss. Despite this potential, prior work faces significant hurdles, including a heavy dependence on expensive and vocabulary-biased caption datasets that limit semantic granularity. Additionally, most existing models are adapted from generic architectures designed for very high-resolution imagery, causing them to prioritize large spatial contexts over the multispectral and temporal signatures that are more informative for medium-resolution sensors like Sentinel-2. This bias toward spatial features reduces performance in fragmented landscapes and increases computational costs. To address these challenges, the authors present TimeSenCLIP, a lightweight vision-language model that aligns multispectral Sentinel-2 time series with geo-tagged ground-level photographs using a cross-view temporal contrastive framework. Unlike previous approaches, TimeSenCLIP operates without textual annotations and emphasizes single-pixel spectral-temporal dynamics over spatial context. The model achieves robust zero-shot performance across tasks such as habitat mapping, crop classification, and bioregion delineation, demonstrating that temporal-spectral signals can effectively compensate for reduced spatial footprint while supporting efficient, scalable remote sensing pipelines.
Dataset
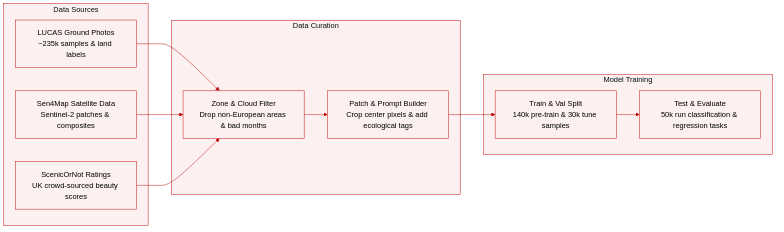
- Dataset Composition & Sources: The authors combine ground-level imagery from the 2018 LUCAS survey with multi-temporal Sentinel-2 observations from the Sen4Map collection, creating a unified European geo-referenced dataset.
- Subset Details & Filtering: LUCAS provides approximately 235,000 sampling points across 28 countries, each paired with four-directional ground photos and CORINE-aligned land use and crop annotations. Sen4Map supplies 64×64 pixel Sentinel-2 patches covering 10 spectral bands, aggregated into 12 monthly median composites to ensure cloud-free annual coverage. Ecological labels are derived from the European Environment Agency, with biogeographical zones filtered to exclude Arctic, Anatolian, Macaronesian, and non-European regions due to missing LUCAS coverage. The scenicness evaluation subset matches 2,411 UK-based Sen4Map samples to crowd-sourced aesthetic ratings from the ScenicOrNot dataset within a 100-meter radius.
- Data Usage & Processing: The Sen4Map collection is divided into 140,000 training, 30,000 validation, and 50,000 test samples. The authors use the training split for contrastive pre-training and reserve the test split for downstream evaluation across classification, habitat mapping, and perceptual regression tasks. Metadata is constructed using standardized ecological descriptors and scenicness-oriented textual prompts, with late prompt ensembling applied to capture concept-level aesthetics.
- Cropping & Input Strategy: Although the pipeline processes 64×64 patches, the model primarily extracts single-pixel (1×1) inputs from the center of each sample to minimize computational overhead and focus on temporal-spectral signatures. The authors also test 5×5 and 9×9 patches during ablation studies to quantify how broader spatial context influences model performance.
Method
The authors leverage a dual-encoder architecture for TimeSenCLIP, designed to align satellite-derived time series with ground-level visual semantics through contrastive learning. The framework is structured around two primary modules: a frozen ground-level encoder and a trainable satellite encoder, which operate in a shared embedding space. During training, the ground-level encoder processes multiple directional images of a location using a frozen CLIP image encoder, aggregating their embeddings via average pooling to produce a single, semantically rich representation. This module, which is only active during training, serves as a text-aligned proxy target by leveraging the CLIP model's ability to map natural images to textual descriptions in a shared latent space.
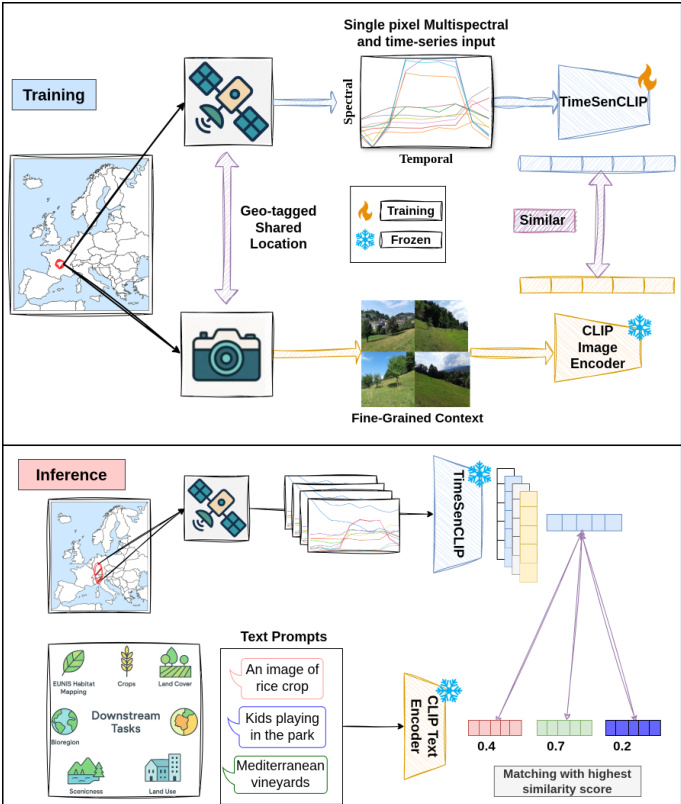
As shown in the figure below, the satellite encoder processes Sentinel-2 multispectral time series data represented as tensors of shape T×C×H×W, where T is the number of temporal observations, C is the number of spectral bands, and H×W is the spatial extent. In the single-pixel setting, H=1 and W=1. The input time series undergo per-band min-max normalization to the range [0, 1], followed by linear patch embedding and the addition of learnable temporal positional embeddings. This sequence, augmented with a CLS token, is then processed by a 6-layer Transformer encoder with 8 attention heads, a hidden dimension of 256, and a latent size of 512. The Transformer employs GELU activations and LayerNorm, and the final class token output is projected into a 512-dimensional satellite embedding via a lightweight two-layer MLP projection head. The resulting satellite embedding and the ground embedding are projected into a shared 512-dimensional space and aligned using a contrastive objective.
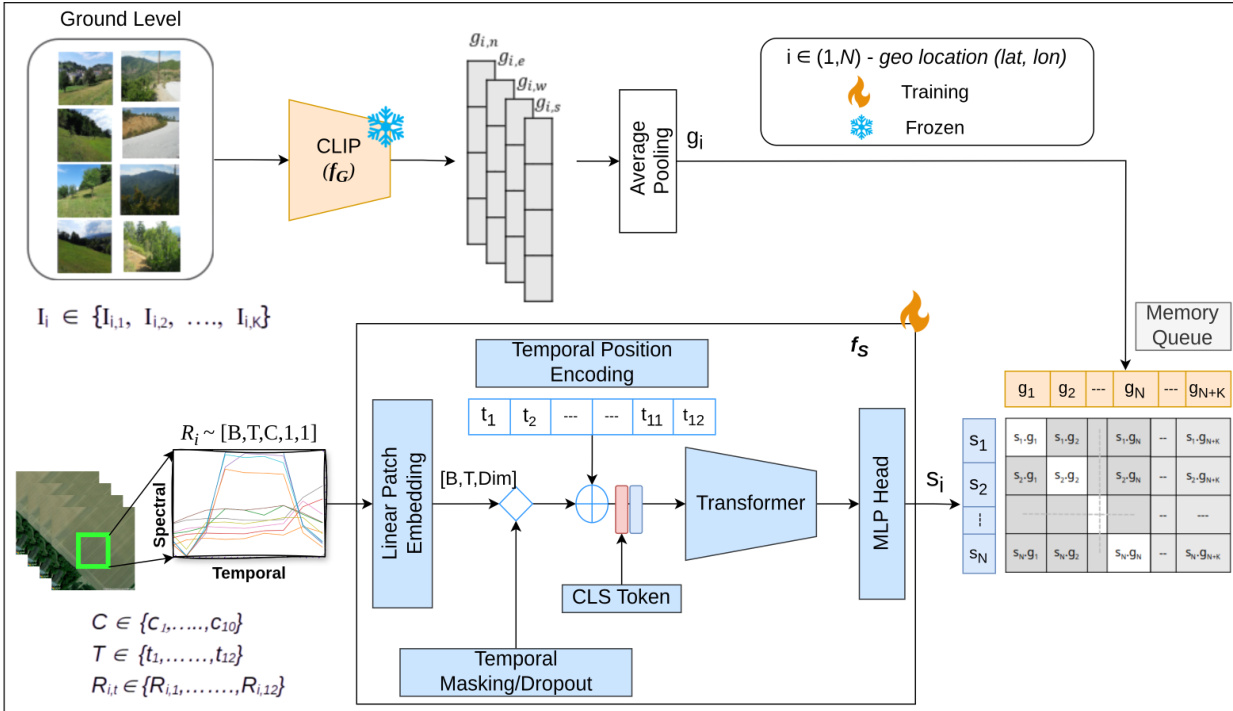
To enhance robustness to incomplete or irregular satellite observations, the model employs a stochastic temporal masking strategy during training. This augmentation is applied on-the-fly with a 50% probability per batch, simulating various forms of temporal data gaps. Three distinct masking strategies are randomly applied with equal probability: median pooling, which aggregates all temporal frames into a single median vector to simulate annual composites; random quarter masking, which masks a contiguous subset of frames to simulate seasonal gaps; and random temporal masking, which randomly masks between 1 and 11 frames while ensuring at least one frame remains, enabling the model to handle variable-length sequences. These augmentations are applied to the linear patch embeddings before being fed into the Transformer. The contrastive alignment is performed using the InfoNCE loss, where positive pairs consist of satellite and ground embeddings from the same geo-tagged location, and negative samples are drawn from both the current batch and a momentum-based memory queue of size 2048. This memory queue is updated through an en-queue-dequeue mechanism to maintain a constant size. The model is trained using the AdamW optimizer with a learning rate of 10−4, weight decay of 1×10−6, and a cosine annealing schedule over 200 epochs with 10 warm-up epochs and a batch size of 1024.
Experiment
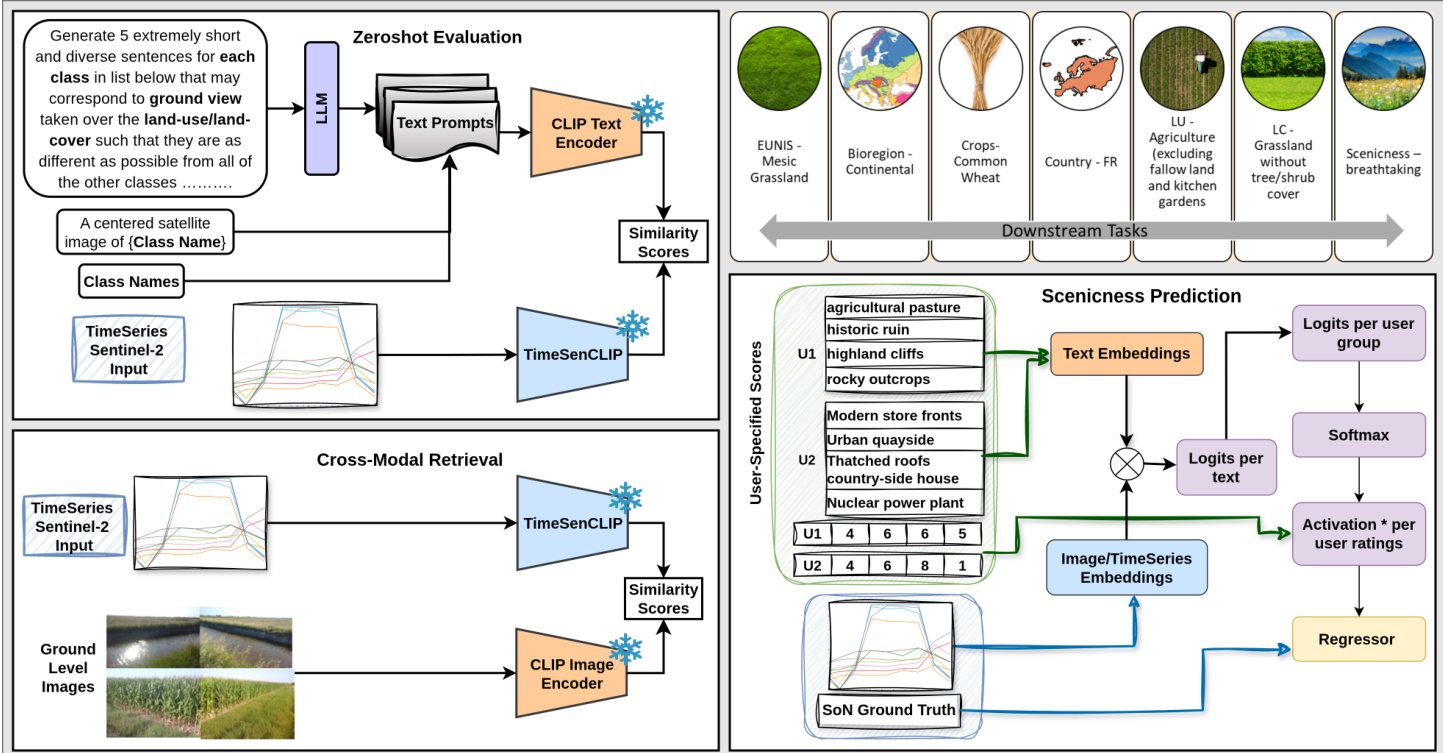
The evaluation framework assesses the model across zero-shot classification, cross-modal retrieval, and scenicness regression, validating its capacity to align satellite time-series with textual descriptions and ground-level imagery for categorical, cross-view, and perceptual tasks respectively. Qualitative findings demonstrate that temporal dynamics consistently serve as the dominant discriminative signal, enabling single-pixel sequences to match or exceed larger spatial contexts across diverse ecological and aesthetic applications. The integration of descriptive natural language prompts significantly enhances generalization by leveraging ground-level training, while targeted temporal regularization effectively maintains robustness under sparse observational conditions. Ultimately, the approach establishes that rich spectral-temporal modeling combined with semantic alignment yields highly efficient, scalable representations capable of capturing complex phenological patterns and landscape qualities.
The experiment evaluates the performance of TimeSenCLIP across various remote sensing tasks using different model configurations and prompt types. Results show that single-pixel time series with temporal modeling achieve competitive accuracy, often matching or exceeding larger spatial patches, particularly in tasks driven by phenological patterns. The model demonstrates strong generalization in zero-shot classification and cross-modal retrieval, with performance benefits from temporal aggregation and descriptive prompts. Single-pixel time series with temporal modeling achieve competitive performance, often matching or exceeding larger spatial patches in zero-shot classification and retrieval tasks. Temporal aggregation significantly improves performance across tasks, with monthly inputs yielding the best results and demonstrating the importance of temporal dynamics for phenology-driven categories. Descriptive prompts enhance zero-shot classification, and the model shows strong generalization in cross-modal retrieval, effectively aligning satellite and ground-level embeddings across diverse semantic categories.
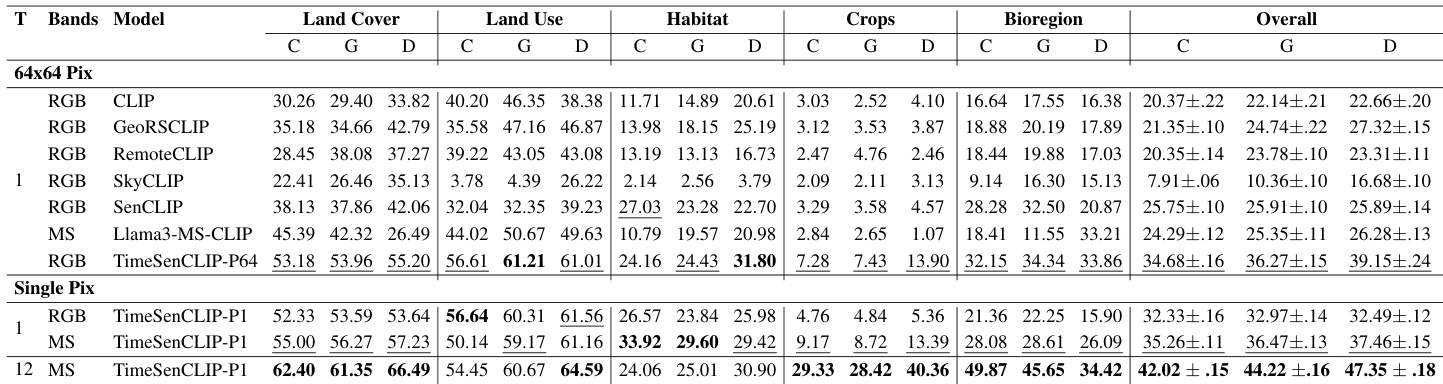
The experiment evaluates the impact of temporal and multispectral dropout strategies on zero-shot classification performance across various geospatial tasks. Results show that applying temporal dropout consistently improves accuracy, especially with limited temporal data, while multispectral dropout provides minimal gains and can degrade performance. The combination of both dropout methods does not yield additional benefits, indicating that temporal regularization is the primary driver of robustness. Temporal dropout significantly improves zero-shot classification accuracy, particularly when temporal coverage is limited. Multispectral dropout offers minimal gains and can reduce performance, suggesting spectral cues are critical for distinguishing classes. Combining temporal and multispectral dropout does not enhance performance, highlighting temporal regularization as the dominant factor for robustness.
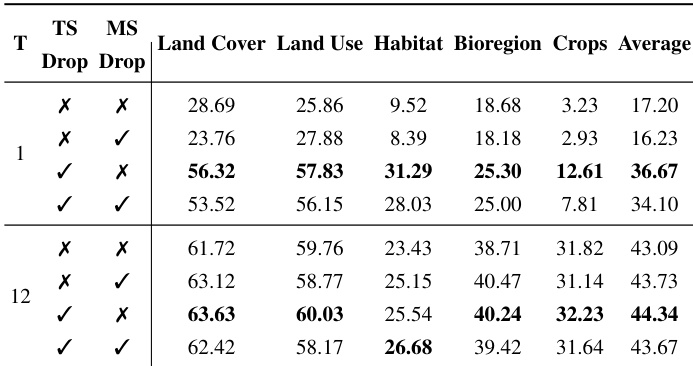
The authors evaluate the impact of temporal and multispectral dropout strategies on zero-shot classification performance across various geospatial tasks, using different temporal aggregation levels. Results show that temporal dropout consistently improves performance, especially with limited temporal data, while multispectral dropout provides minimal benefits and can degrade performance. The combined use of both dropout methods does not yield additional improvements. Temporal dropout significantly enhances zero-shot classification performance, particularly with single-timestamp inputs. Multispectral dropout offers little benefit and can reduce performance, indicating that spectral information is critical for accurate classification. The combination of temporal and multispectral dropout does not improve results beyond temporal dropout alone.
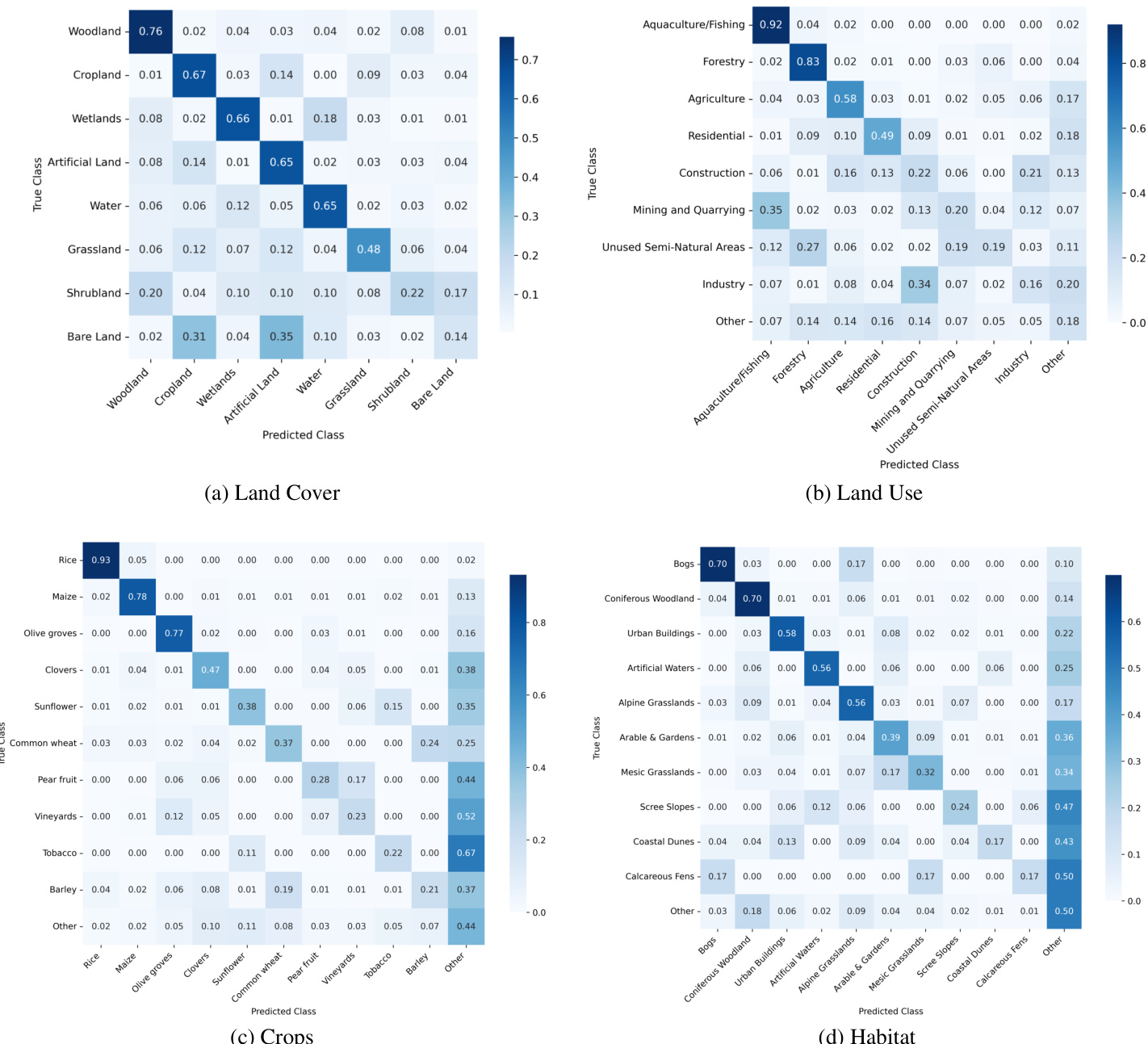
The authors present a series of confusion matrices that illustrate the performance of the TimeSenCLIP model in zero-shot classification across various land cover, land use, crop, and habitat categories. The results show that the model achieves high accuracy for dominant and well-defined classes, with most errors occurring between semantically or structurally similar categories, indicating that the model's limitations stem from intrinsic ambiguities in the data rather than systematic failures. The model demonstrates consistent performance across different classification tasks, with particularly strong results for broad categories like Land Cover and Land Use, while also showing the ability to distinguish fine-grained crop types and ecological habitats. The model achieves high accuracy for dominant classes and makes errors primarily between semantically similar categories, reflecting inherent data ambiguities. Performance is consistent across diverse tasks, with strong results for broad categories like Land Cover and Land Use. The model successfully distinguishes fine-grained crop types and ecological habitats, demonstrating robust zero-shot generalization.
The authors evaluate the impact of ground image aggregation strategies on cross-modal retrieval performance, comparing average pooling across multiple images to using a single randomly selected image. Results show that average pooling provides a slight improvement over using a single image, but the difference is minimal across all tasks, indicating that a single representative image is sufficient for effective retrieval. This suggests that the method can be deployed efficiently without requiring extensive ground-image data collection. Average pooling of ground images provides a slight improvement over using a single image for retrieval performance. The performance difference between pooling strategies is minimal, indicating a single image is sufficient. The findings support a scalable approach that reduces data collection and computational overhead for cross-modal retrieval.

The experiments evaluate TimeSenCLIP across diverse remote sensing tasks by testing various model configurations, prompt strategies, dropout regularizations, and aggregation methods. Results demonstrate that temporal modeling and aggregation significantly enhance zero-shot classification and cross-modal retrieval, often outperforming larger spatial patches and benefiting from descriptive prompts. Temporal dropout consistently improves robustness under data constraints, whereas spectral dropout provides minimal gains, underscoring the primacy of temporal dynamics for phenology-driven tasks. The model exhibits strong generalization across broad and fine-grained categories, with errors primarily reflecting inherent semantic ambiguities, while single-image ground retrieval remains highly effective, supporting efficient and scalable deployment.