Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Introduction aux plongements et à la mise en œuvre des plongements sémantiques
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
The authors advance large language model semantic caching by introducing a novel synthetic data generation pipeline that enables compact, domain-specific embedding models fine-tuned for a single epoch to surpass state-of-the-art open-source and proprietary alternatives in precision and recall while maintaining an optimal balance between computational overhead and retrieval accuracy.
Key Contributions
- This work introduces a fine-tuning strategy for compact embedding models, including ModernBERT, that restricts training to a single epoch, enabling these architectures to outperform state-of-the-art open-source and proprietary alternatives in precision and recall.
- A novel synthetic data generation pipeline is developed to produce targeted training samples for semantic caching, compensating for limited domain annotations and improving precision by 9% over untrained baselines.
- Evaluations on medical and Quora datasets demonstrate that constraining the gradient norm to 0.5 during fine-tuning mitigates catastrophic forgetting, preserving cross-domain generalization while achieving a 4% precision gain on the medical dataset.
Introduction
Large language models power modern applications but demand heavy compute, making semantic caching a critical technique for reducing latency and costs when handling repeated user queries. Selecting an optimal embedding model remains difficult because open-source options are computationally intensive while closed-source services introduce expense and network latency. Efficient small models offer a promising alternative but typically underperform without fine-tuning, which requires scarce high-quality datasets and risks catastrophic forgetting during extended training. To overcome these limitations, the authors leverage lightweight embedding models fine-tuned for a single epoch with constrained gradient norms to preserve general knowledge. They also introduce a synthetic data generation pipeline that creates domain-specific training examples, enabling compact models to match or exceed state-of-the-art proprietary and open-source embeddings in semantic caching precision.
Dataset

- Dataset Composition and Sources: The authors construct a synthetic dataset from unlabeled query logs sourced from open repositories in specialized domains like medicine, addressing the scarcity of high-quality labeled data for semantic caching.
- Subset Details: The dataset contains two LLM-generated categories. Positive pairs consist of paraphrased queries that retain original intent but vary in phrasing, labeled as duplicates. Negative pairs include topically related queries that diverge in clinical focus or subdomain, labeled as distinct.
- Data Usage and Training Strategy: The authors use the synthetic pairs to fine-tune embedding models, improving near-duplicate detection while reducing false positives and negatives. Training is deliberately constrained to a single epoch with moderated gradient norms to prevent catastrophic forgetting and preserve cross-domain generalization.
- Processing and Pipeline Details: A dual-labeling framework guides the LLM through structured prompts to simultaneously produce both subsets. This pipeline captures semantic edge cases and domain-specific terminology, streamlining the preparation process without requiring manual cropping or external metadata construction.
Method
The authors leverage a three-component methodology to enhance the effectiveness of semantic caching through specialized embedding models. At the core of their approach is the selection and fine-tuning of a compact, efficient transformer-based embedding model, which is designed to operate under the computational constraints typical of production caching systems. They choose ModernBERT, a 149-million-parameter encoder-only transformer, due to its favorable balance of performance and efficiency compared to larger models like BERT, RoBERTa, and NomicBERT. This model serves as the foundation for their domain-adapted embedding system, which is specifically optimized for semantic similarity tasks in specialized domains.

The framework diagram illustrates the process of generating paraphrased queries from an original input, which is a critical step in constructing the training data for domain-specific fine-tuning. The system takes an original query and generates multiple semantically equivalent variations that explore different subtopics, perspectives, or clinical contexts, ensuring diversity while preserving the core meaning. For instance, given the query "What are the best ways to reduce stress?", the model produces paraphrased versions such as "How can a person effectively manage stress?" and "What strategies help in reducing stress levels?". These generated queries are then used to create a dataset of positive pairs—semantically similar query instances—essential for contrastive learning.
Fine-tuning is performed using an online contrastive loss function, which is particularly effective for training models to distinguish subtle semantic differences. This approach, as shown in the figure below, focuses on the "hardest" examples within each training batch—positive pairs that the model currently ranks as dissimilar and negative pairs that it ranks as similar. By concentrating the training objective on these challenging cases, the model learns more discriminatively, leading to faster convergence and improved precision in identifying duplicate queries. This is crucial for semantic caching, where the accuracy of detecting semantically equivalent queries directly impacts cache hit rates. The fine-tuned model, referred to as LangCache-Embed, is evaluated against both its non-fine-tuned baseline and state-of-the-art models, demonstrating significant gains in precision and recall, particularly on domain-specific data.
Experiment
The evaluation fine-tunes ModernBERT on both general and specialized medical datasets, benchmarking it against top open-source and proprietary embedding models under realistic hardware constraints. The experiments validate that targeted domain adaptation significantly enhances semantic matching capabilities, while synthetic data generation successfully bridges annotation gaps without compromising accuracy. Ultimately, the approach achieves an optimal balance between high retrieval precision and minimal embedding latency, proving highly effective for real-time semantic caching systems.
The authors evaluate the performance of LangCache-Embed, a fine-tuned version of ModernBERT, on two datasets, demonstrating that domain-specific fine-tuning significantly improves key metrics such as precision, recall, and average precision. The results show that LangCache-Embed outperforms both open-source and closed-source models across multiple evaluation metrics, with particularly strong gains in precision and average precision. Additionally, the model achieves low embedding generation overhead, making it suitable for real-time semantic caching applications. Domain-specific fine-tuning significantly enhances LangCache-Embed's performance across precision, recall, and average precision on both Quora and medical datasets. LangCache-Embed outperforms leading open-source and closed-source embedding models in key metrics, including average precision and precision. LangCache-Embed achieves low embedding generation overhead, making it an optimal choice for real-time semantic caching applications.
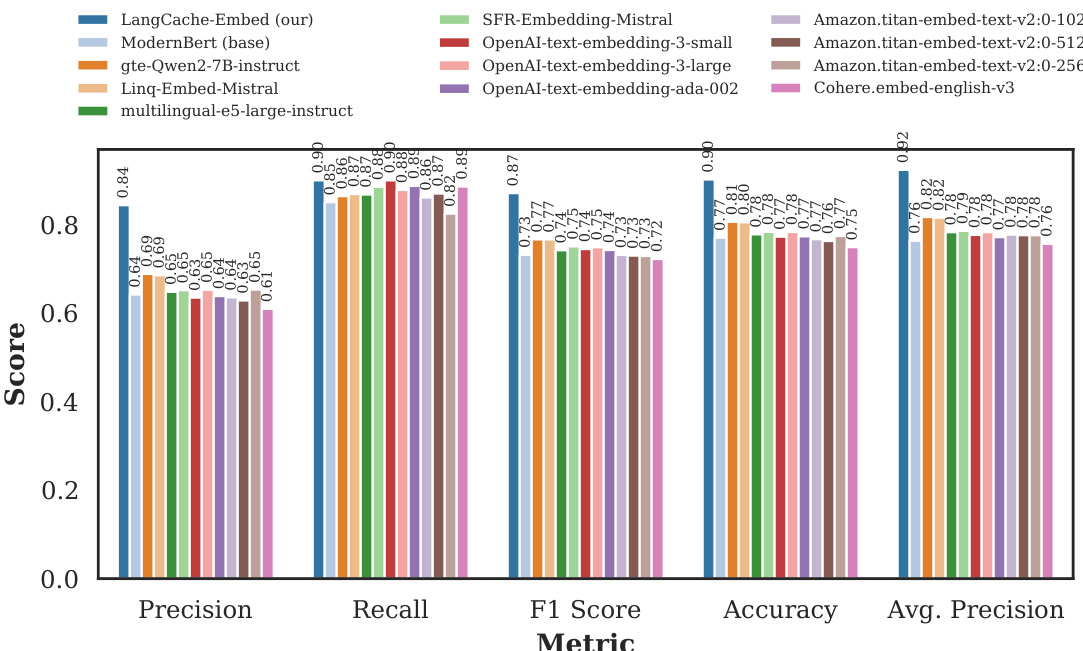
The authors evaluate the performance of LangCache-Embed, a fine-tuned version of ModernBERT, on semantic similarity tasks using two datasets, Quora and a medical domain dataset. Results show that domain-specific fine-tuning significantly improves performance across multiple metrics, and the model achieves competitive results against state-of-the-art open-source and closed-source embedding models, particularly on the medical dataset. A synthetic data generation pipeline further enhances in-domain performance, allowing the model to match or surpass larger proprietary models. Domain-specific fine-tuning significantly improves performance on both Quora and medical datasets, with substantial gains in precision and average precision. LangCache-Embed outperforms leading closed-source models and state-of-the-art open-source models on the medical dataset, especially when fine-tuned on synthetic data. The model achieves a favorable trade-off between embedding generation speed and accuracy, making it suitable for real-time semantic caching applications.
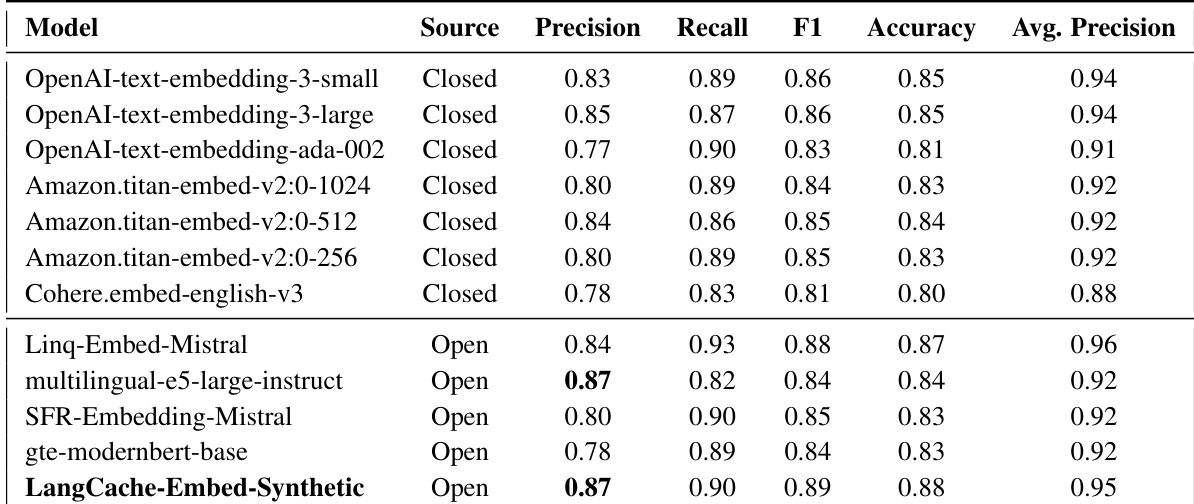
The authors evaluate a fine-tuned version of ModernBERT, referred to as LangCache-Embed, on two datasets, demonstrating significant performance improvements across multiple metrics. The model achieves state-of-the-art results, outperforming both open-source and proprietary embedding models, and shows that domain-specific fine-tuning and synthetic data generation enhance its capabilities. Domain-specific fine-tuning significantly improves performance across precision, recall, F1-score, accuracy, and average precision on both Quora and medical datasets. LangCache-Embed surpasses leading proprietary models, including OpenAI's best embedding model, in terms of precision and average precision. The model achieves the lowest embedding generation overhead while maintaining high performance, making it suitable for real-time semantic caching applications.
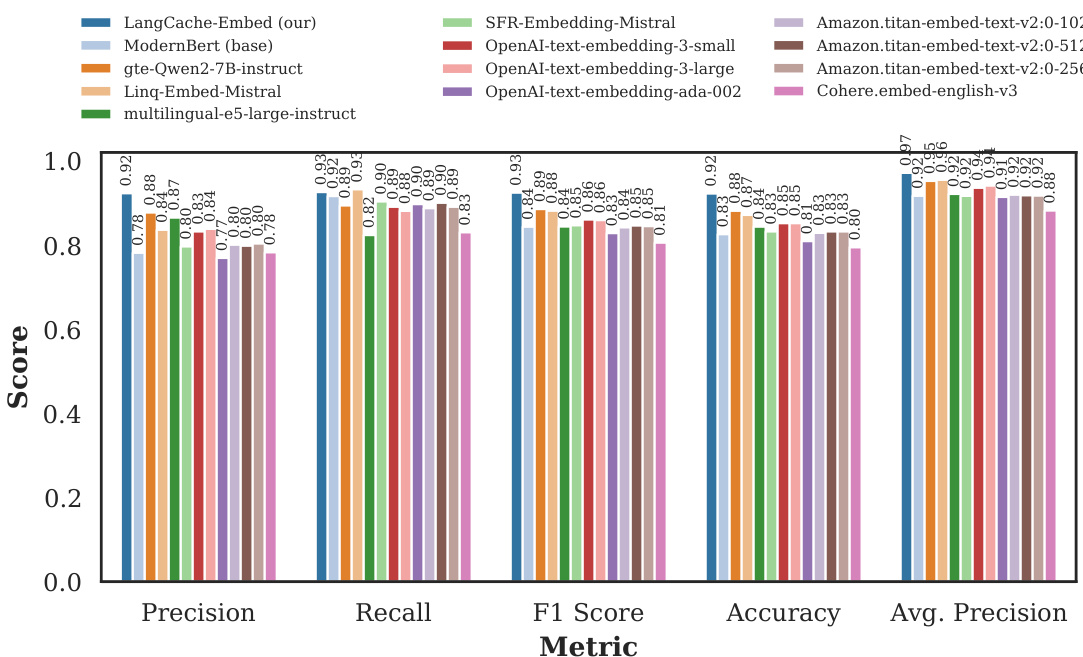
The authors evaluate the performance of a fine-tuned version of ModernBERT, referred to as LangCache-Embed, on two datasets: Quora and a medical domain dataset. The results show that fine-tuning significantly improves performance across multiple metrics, with the finetuned model outperforming the base model in both extensive and moderate fine-tuning scenarios. The finetuned model achieves higher precision, recall, F1-score, accuracy, and average precision, demonstrating the effectiveness of domain-specific adaptation. Fine-tuning ModernBERT leads to substantial improvements in precision, recall, F1-score, accuracy, and average precision on both Quora and medical datasets. The finetuned model outperforms the base model across all evaluated metrics in both extensive and moderate fine-tuning setups. The finetuned model achieves higher performance with lower embedding generation overhead, making it suitable for real-time semantic caching applications.
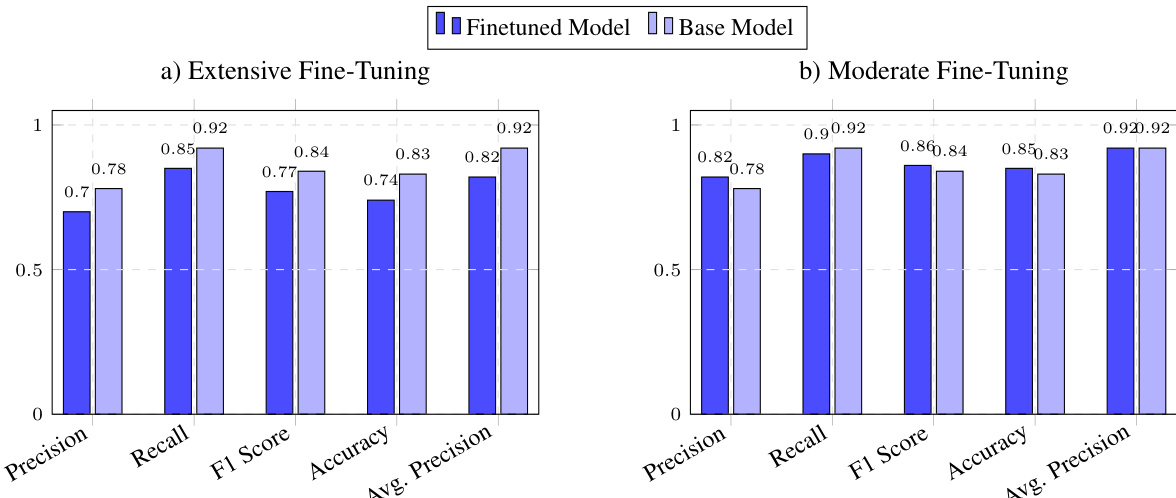
The authors evaluate LangCache-Embed, a fine-tuned ModernBERT model, on Quora and medical domain datasets to assess its effectiveness for semantic similarity and caching tasks. These experiments validate that domain-specific fine-tuning and synthetic data augmentation substantially enhance model capabilities compared to both base architectures and existing open-source or proprietary alternatives. Qualitatively, the approach demonstrates superior accuracy and efficiency, achieving a highly favorable balance between performance and computational overhead. Ultimately, the results confirm that LangCache-Embed serves as a robust and practical solution for real-time semantic caching applications.