Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Déploiement en un clic de Qwen2.5-Omni : vision, parole, audio et texte unifiés
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
Qwen2.5-Omni is an end-to-end multimodal model that processes text, images, audio, and video to generate streaming text and speech by combining block-wise encoders, TMRoPE for timestamp alignment, a Thinker-Talker architecture that decouples language modeling from audio generation, and a sliding-window DiT for low-latency decoding, thereby achieving state-of-the-art performance on Omni-Bench, matching Qwen2.5-VL on MMLU and GSM8K, and outperforming Qwen2-Audio in robust streaming speech generation.
Key Contributions
- Qwen2.5-Omni introduces a Thinker-Talker architecture that decouples text generation within a large language model from streaming speech synthesis in a dual-track autoregressive model, enabling end-to-end joint training without cross-modal interference.
- Audio and visual encoders employ a block-wise streaming approach to handle long sequences, while a novel TMRoPE position embedding synchronizes interleaved video and audio inputs. A sliding-window DiT further restricts the receptive field to minimize initial package delay during streaming audio decoding.
- Evaluations on OmniBench, AV-Odyssey Bench, MMLU, and GSM8K demonstrate state-of-the-art multimodal understanding and instruction-following parity between speech and text. The streaming speech generator achieves word error rates as low as 1.42% on seed-tts-eval, outperforming existing alternatives in robustness and naturalness.
Introduction
The provided input is empty, so I cannot generate the summary. Once you share the paper excerpt, I will outline the technical context and its practical significance, detail the limitations of existing methods, and explain how the authors leverage novel techniques to advance the field. The final response will remain concise, technical yet readable, and strictly adhere to your formatting guidelines.
Dataset

- Dataset Composition and Sources: The authors compile a post-training corpus formatted in ChatML, aggregating pure text dialogues, visual conversations, audio conversations, and mixed-modality interactions.
- Subset Details: The collection is divided into four modality-specific categories: text-only, vision-only, audio-only, and combined multimodal conversations. The provided excerpts do not specify exact sample counts, external repositories, or explicit filtering rules for each subset.
- Training Usage and Processing: This instruction-following collection is reserved for the post-training phase to fine-tune the Thinker module. The authors standardize all conversational turns into the ChatML schema to facilitate end-to-end joint training and ensure proper alignment across text, vision, and audio streams.
- Additional Processing Details: No cropping strategies, metadata construction pipelines, or specific mixture ratios are documented in the provided sections. The preprocessing workflow prioritizes format consistency and modality synchronization to support real-time streaming generation.
Method
The authors present Qwen2.5-Omni, a unified end-to-end multimodal model designed to perceive text, images, audio, and video while generating text and natural speech responses in a streaming fashion. The overall architecture, as illustrated in the framework diagram, is built around a dual-component design known as the Thinker-Talker architecture. This framework divides the model's responsibilities: the Thinker functions as a large language model responsible for processing multimodal inputs and generating high-level representations and text, while the Talker serves as a dual-track autoregressive model that generates streaming speech tokens directly from the Thinker’s hidden representations. This separation enables simultaneous text and speech generation without modality interference, with both components trained and inferred in an end-to-end manner.
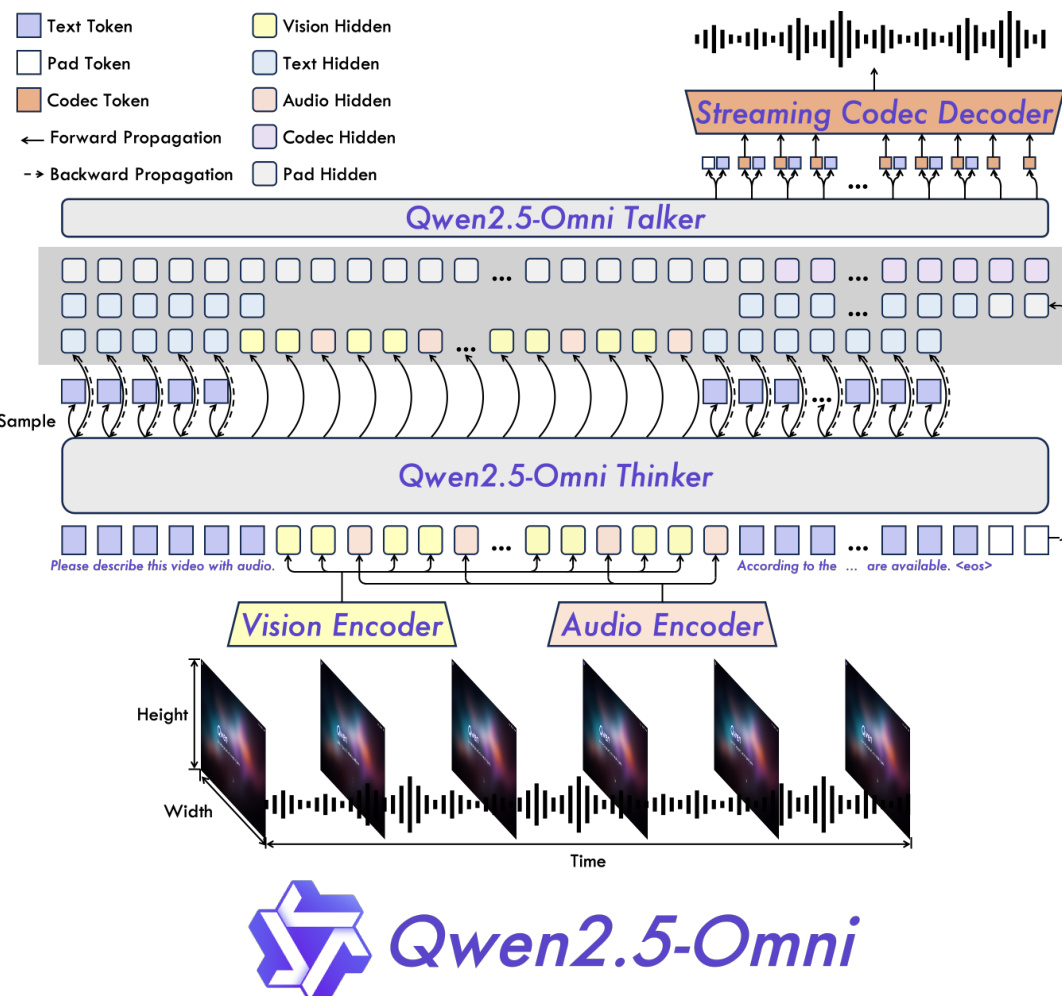
The Thinker component is a Transformer decoder that processes text, audio, and visual inputs. Text is tokenized using Qwen's byte-level byte-pair encoding, while audio is converted into a 128-channel mel-spectrogram at a 16kHz sampling rate, with each frame representing a 40ms segment. The vision encoder, derived from Qwen2.5-VL, is a Vision Transformer that processes both images and videos. To ensure synchronization between audio and video inputs, the model employs a time-interleaving strategy, where visual and audio representations are arranged in chunks of two seconds, with visual data preceding audio data. This synchronization is facilitated by a novel positional embedding method called TMRoPE (Time-aligned Multimodal RoPE), which explicitly encodes the 3D positional information of multimodal inputs. TMRoPE decomposes rotary embeddings into temporal, height, and width components, assigning unique position IDs to each modality while maintaining consistency across the sequence. For text and audio, identical position IDs are used, while for video, the temporal ID increments based on actual frame time, ensuring each temporal ID corresponds to 40ms, thus preserving temporal alignment.
The speech generation process is handled by the Talker, which receives both high-level representations from the Thinker and discrete text tokens. This integration allows the Talker to anticipate the tone and attitude of the speech before the full text is generated, enhancing naturalness. The Talker uses an efficient speech codec, qwen-tts-tokenizer, to represent speech information, which is then decoded into a speech stream. The Talker generates audio tokens autoregressively, with no requirement for word-level or timestamp-level alignment to the text, simplifying both training and inference.
To enable efficient streaming inference, the model incorporates several architectural improvements. For input processing, the audio and vision encoders are modified to support block-wise attention along the temporal dimension, allowing them to process data in 2-second chunks. This enables chunked-prefill support, reducing the initial processing delay. For audio generation, a sliding-window block attention mechanism is employed in a DiT (Diffusion Transformer) model. This mechanism restricts the receptive field of the model to a limited context, specifically four blocks (two lookback, one lookahead), which allows for real-time generation of mel-spectrograms in chunks. The generated mel-spectrogram is then reconstructed into a waveform using a modified BigVGAN, ensuring that the entire process remains causal and suitable for streaming.

The training process for Qwen2.5-Omni consists of three stages. In the first stage, the LLM parameters are locked, and only the vision and audio encoders are trained on image-text and audio-text pairs. In the second stage, all parameters are unfrozen, and the model is trained on a broader range of multimodal data. The final stage extends the training to sequences up to 32k tokens to enhance long-sequence understanding. The Talker component undergoes a three-stage training process: first, it learns context continuation; second, it uses DPO (Direct Preference Optimization) to enhance stability; and third, it undergoes multi-speaker instruction fine-tuning to improve naturalness and controllability. This comprehensive training strategy enables Qwen2.5-Omni to achieve strong performance across various multimodal tasks, including end-to-end speech instruction following and robust speech generation.
Experiment
The evaluation comprehensively assesses Qwen2.5-Omni across text, audio, image, video, and mixed-modality inputs, alongside its speech generation capabilities, utilizing a broad suite of established benchmarks. Qualitatively, the model demonstrates state-of-the-art cross-modal comprehension, consistently matching or surpassing leading specialized architectures in general reasoning, visual analysis, and temporal understanding. Its audio processing and conversational modules exhibit exceptional fluency and accuracy, while its speech generation achieves near-human naturalness and stability following fine-tuning and reinforcement learning. Collectively, these experiments validate Qwen2.5-Omni as a highly robust omnimodal system capable of seamlessly processing diverse inputs and delivering high-quality textual and vocal outputs.
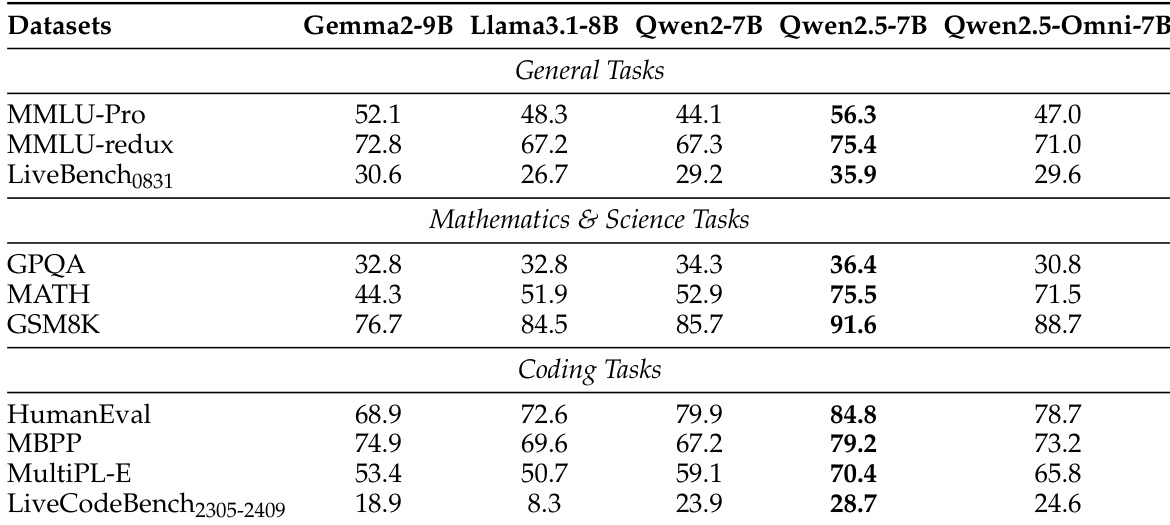
The authors evaluate Qwen2.5-Omni's text-to-text capabilities across general, mathematics & science, and coding tasks, comparing it to other 7B-sized models. Results show that Qwen2.5-Omni achieves performance comparable to or better than existing models on most benchmarks, particularly in coding and mathematics & science categories, indicating strong overall text understanding and generation abilities. Qwen2.5-Omni outperforms other 7B models on most coding and mathematics & science benchmarks. The model achieves competitive results in general evaluation tasks, generally ranking between Qwen2-7B and Qwen2.5-7B. Qwen2.5-Omni demonstrates strong performance in coding tasks, surpassing several other models on key benchmarks.
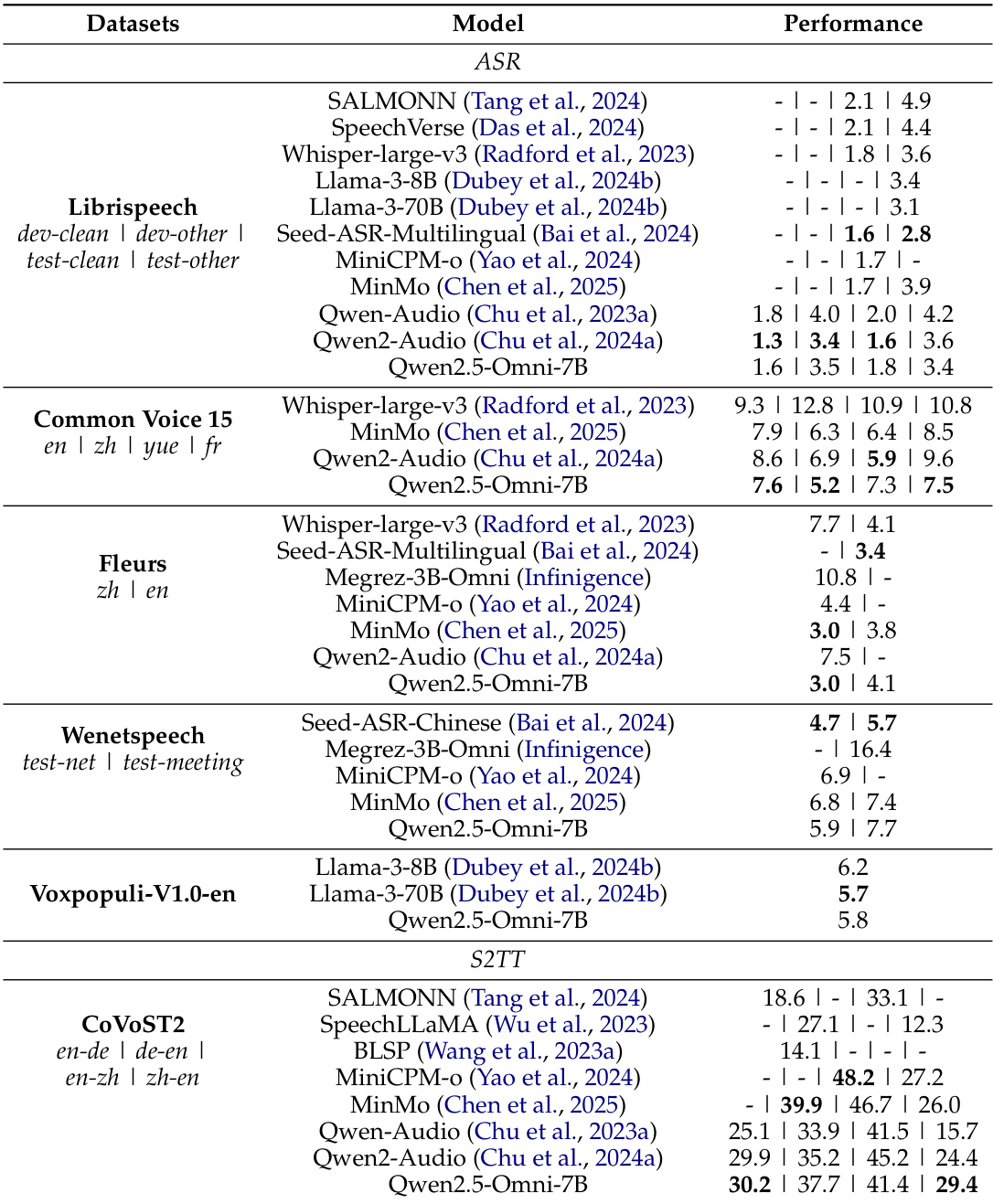
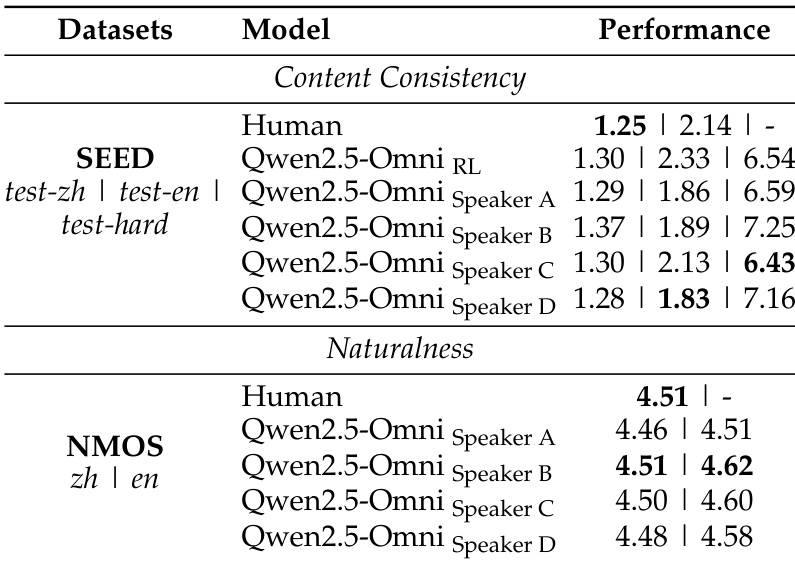
The authors evaluate Qwen2.5-Omni's performance in audio-to-text tasks, comparing it against various state-of-the-art models across multiple datasets. Results show that Qwen2.5-Omni achieves competitive or superior performance in automatic speech recognition and speech-to-text translation, particularly on datasets like Librispeech and CoVoST2. The model demonstrates strong capabilities in both zero-shot and single-speaker speech generation, with improvements after reinforcement learning and fine-tuning. Qwen2.5-Omni achieves competitive or superior performance in automatic speech recognition and speech-to-text translation compared to other models on multiple datasets. The model demonstrates strong zero-shot speech generation capabilities with highly competitive results on content consistency and speaker similarity. After reinforcement learning and speaker fine-tuning, Qwen2.5-Omni achieves performance that approaches human-level quality in single-speaker speech generation.
The authors evaluate the visual grounding capabilities of Qwen2.5-Omni across various benchmarks, comparing it to Gemini 1.5 Pro and Grounding DINO. The model demonstrates strong performance on multiple grounding tasks, particularly in point grounding and open-vocabulary object detection, achieving competitive results with leading models. It shows consistent improvements over other models on most benchmarks, highlighting its robust visual grounding capabilities. Qwen2.5-Omni achieves strong performance on multiple visual grounding benchmarks, including point grounding and open-vocabulary object detection. The model outperforms other models on most grounding tasks, particularly in point grounding and open-vocabulary detection. Qwen2.5-Omni demonstrates competitive results compared to state-of-the-art models like Gemini 1.5 Pro and Grounding DINO across various grounding benchmarks.
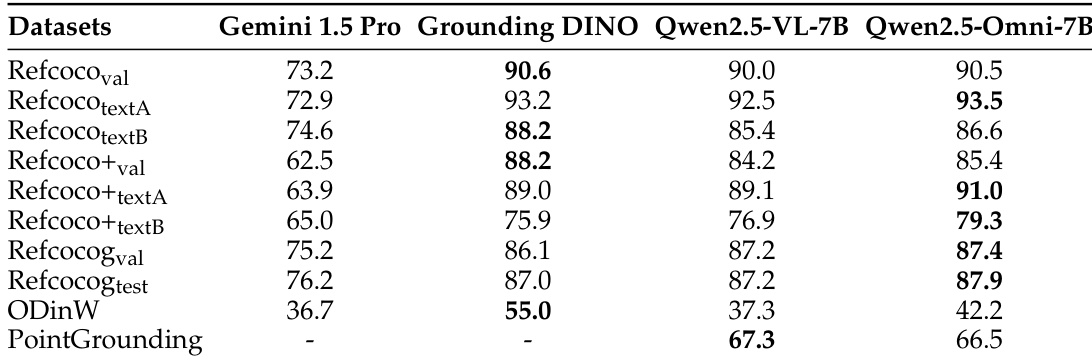
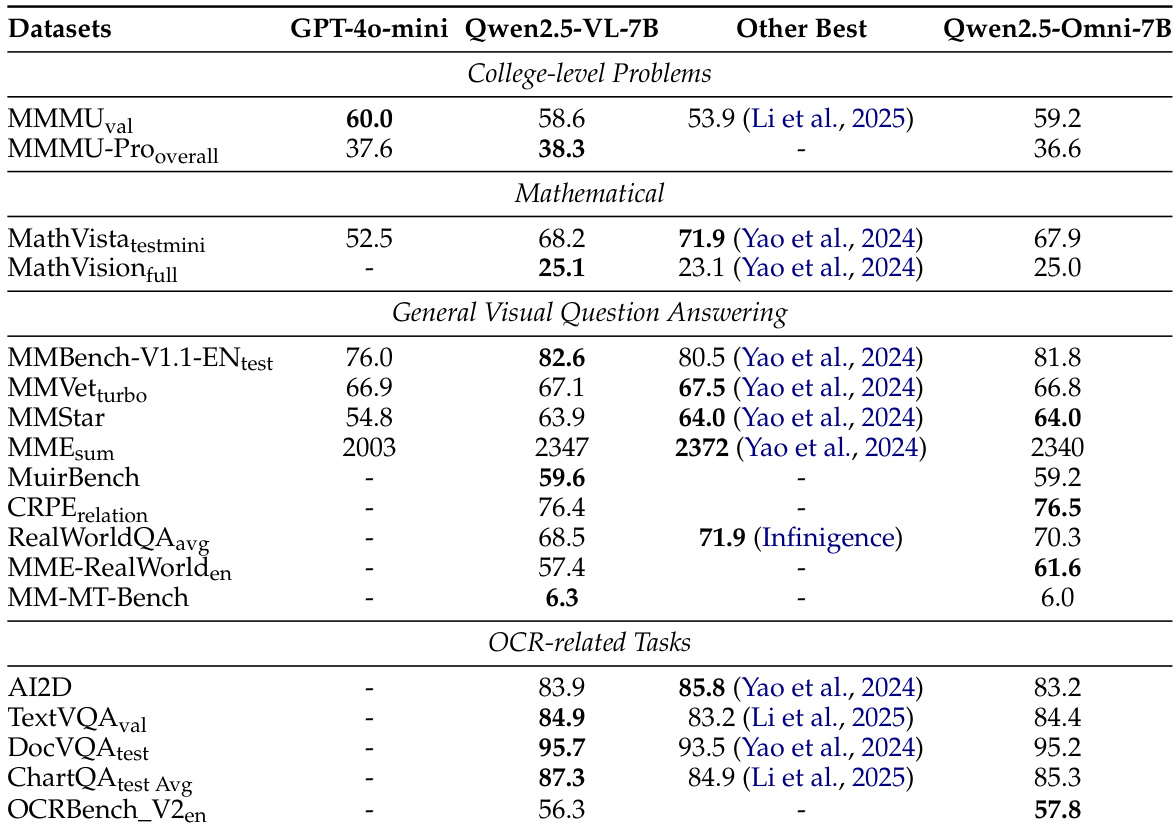
The authors evaluate Qwen2.5-Omni's performance across various multimodal tasks, focusing on text, audio, image, and video understanding, as well as speech generation. The results show that Qwen2.5-Omni achieves competitive or superior performance compared to other models, particularly in image and video understanding, and demonstrates strong capabilities in multimodal reasoning and speech generation. Qwen2.5-Omni achieves strong performance in image and video understanding, outperforming other open-sourced models and competing with state-of-the-art models. The model demonstrates superior multimodal reasoning capabilities, achieving state-of-the-art results on multimodal benchmarks. Qwen2.5-Omni shows high-quality speech generation, with performance approaching human-level quality after speaker fine-tuning.
The authors evaluate the speech generation capabilities of Qwen2.5-Omni, focusing on zero-shot and single-speaker scenarios. Results show that the model achieves competitive performance in zero-shot speech generation, with improvements after reinforcement learning. After speaker fine-tuning, the model produces speech that closely matches human-like naturalness and prosodic style across both objective and subjective metrics. Qwen2.5-Omni achieves competitive zero-shot speech generation performance with improvements after reinforcement learning The model demonstrates strong speaker similarity and content consistency in zero-shot speech generation After speaker fine-tuning, Qwen2.5-Omni achieves naturalness and prosodic style close to human-level quality
The evaluation compares Qwen2.5-Omni against competing 7B-sized and state-of-the-art models across standardized benchmarks covering text, audio, vision, and multimodal tasks. Experimental validation demonstrates robust text understanding and generation, particularly highlighting exceptional performance in coding and scientific reasoning alongside competitive general capabilities. Audio and visual assessments confirm strong automatic speech recognition, translation, and grounding abilities, while broader multimodal tests reveal superior reasoning and image understanding that rival leading systems. Overall, the model consistently delivers competitive or superior results across all evaluated domains, with reinforcement learning and speaker fine-tuning enabling human-level quality in single-speaker speech synthesis.