Command Palette
Search for a command to run...
SMOL : Données parallèles professionnellement traduites pour 115 langues sous-représentées
SMOL : Données parallèles professionnellement traduites pour 115 langues sous-représentées
Résumé
Nous mettons en open source SMOL (Set of Maximal Overall Leverage), un ensemble de données d’entraînement destiné à rendre la traduction automatique accessible pour les langues peu dotées. SMOL a été traduit dans 124 langues sous-dotées (soit 125 paires de langues), et ce nombre est en augmentation, dont de nombreuses langues pour lesquelles il n’existait aucune ressource publique antérieure, représentant au total 6,1 millions de tokens traduits. SMOL comprend deux sous-ensembles de données, chacun soigneusement sélectionné pour maximiser son impact compte tenu de sa taille : SMOLSENT, un ensemble de phrases choisi pour assurer une couverture maximale et unique des tokens, et SMOLDOC, une ressource au niveau document axée sur une large couverture thématique. Ces ensembles rejoignent GATITOS, déjà publié, pour former un trio complémentaire couvrant respectivement les niveaux paragraphe, phrase et token. Nous démontrons que l’utilisation de SMOL pour l’activation par prompt (prompting) ou le réglage fin (fine-tuning) des grands modèles de langage (LLM) permet d’obtenir des améliorations robustes en termes de score CHRF. Par ailleurs, en plus des traductions, nous fournissons des évaluations de factualité ainsi que des justifications pour tous les documents de SMOLDOC, constituant ainsi les premiers jeux de données de factualité disponibles pour la plupart de ces langues.
One-sentence Summary
The authors open-source SMOL, a suite of professionally translated parallel data designed to unlock machine translation for 124 under-resourced languages totaling 6.1M tokens across the sentence-level SMOLSENT and document-level SMOLDOC sub-datasets that yield robust CHRF improvements when prompting or fine-tuning Large Language Models and provide the first factuality ratings and rationales for most included languages.
Key Contributions
- This work introduces SMOL, an open-source suite of training data designed to unlock machine translation for low-resource languages. SMOL comprises SMOLSENT and SMOLDOC sub-datasets covering 124 under-resourced languages with 6.1M translated tokens.
- Experiments demonstrate that utilizing SMOL to prompt or fine-tune Large Language Models yields robust CHRF improvements in translation tasks.
- Factuality ratings and rationales are provided for all documents within SMOLDOC. This addition yields the first factuality datasets available for most of the covered languages.
Introduction
Machine translation models often lack support for Low-Resource Languages, defined here as those beyond the 104 languages supported by Google Translate prior to 2020. Existing datasets typically rely on web crawls or legacy machine translation outputs that lack the quality and volume needed for effective training. To address this, the authors present SMOL, a dataset of professionally translated parallel data for 115 under-represented languages. They leverage volunteer contributions and professional translation to create high-quality resources for languages previously excluded from major systems.
Dataset
The authors introduce SMOL, a professionally translated dataset suite designed to unlock machine translation for 124 low-resource languages. The collection totals 6.1M translated tokens across two complementary subsets.
-
Dataset Composition and Sources
- The suite targets 125 language pairs with source text selected or generated in English to streamline quality control.
- It complements the existing GATITOS token-level resource by adding sentence and document-level content.
- Translations were produced by contracted professional translators paid fair wages, alongside volunteer contributions for specific languages like Cantonese.
-
Subset Details
- SMOLSENT: Contains 863 English sentences selected from CommonCrawl to maximize unique token coverage (5.5k tokens). These are translated into 88 languages.
- SMOLDOC: Comprises 584 English documents generated by an LLM using diverse templates covering various topics, tones, and domains. These are translated into 106 languages.
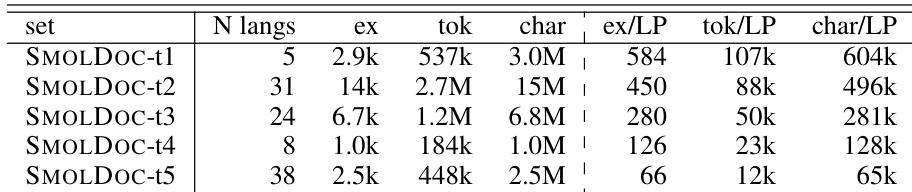
- Language Tiers: SMOLDOC data is distributed across five tiers based on speaker population size, with larger subsets for languages with more speakers.
-
Model Usage
- The authors utilize the data for fine-tuning and prompting Large Language Models, demonstrating robust CHRF improvements on Gemini 2.0 Flash.
- SMOLDOC includes factuality ratings and rationales for all documents, creating the first factuality dataset for most covered languages.
-
Processing and Verification
- Selection Strategy: SMOLSENT employs a greedy token set-cover algorithm refined by a Researcher-in-the-Loop process to eliminate honeypots and short sentence bias.
- Diversity Filtering: SMOLDOC documents are ranked by character 9-gram Inverse Document Frequency to remove redundancy, subtracting the BREAD score to down-weight internal repetition.
- Quality Control: Deliveries are checked for duplicates, anomalous length ratios, and similarity to Google Translate outputs.
- Validation: FUNLANGID verifies language identity, while manual inspection corrects orthography and script issues for languages like West African and Santali.
- Factuality Audit: Each SMOLDOC document is rated by three human raters, assigning codes for minor issues, clear issues, or ok status.
Method
The authors extend the greedy set cover approach through a Researcher In the Loop mechanism. Rather than always picking the highest-scoring sentence, the system iteratively shows the researcher a batch of the 20 highest scoring sentences according to several scores. The researcher then picks and optionally edits each sentence at each iteration. At each iteration, the researcher may also remove any number of this batch sentences from the reservoir. Allowing the researcher to see and edit the sentences ensures that the sentences are of high quality. To deal with the length bias issue, the system shows not only sentences that maximize coverage percent but also those that maximize heuristics that weighted the coverage with the number of new tokens hit, like log(coverage_percent)∗n_hits. This approach is designed to combat issues such as honeypot sentences. Example Honeypot sentences are presented below:

CommonCrawl has many sentences packed with content words but with no clear semantics or grammar.
To have a strong baseline for N-shot results, the authors adopt a RAG-based approach that resembles the greedy set-cover algorithm. For each sentence in the eval set, the goal is the best coverage of the source sentence n-grams as possible, with the least redundancy among exemplars. Therefore, the system iteratively chooses the exemplar whose source side has the minimum ChRF to the eval source. However, when counting the true positives in the ChRF calculation, the count of each ngram ni is weighted by (1+ci)−α. Here ci∈[0,∞] is the number of times ni has been seen among the exemplars chosen so far, and α is a parameter to control how close this algorithm is to ngram set-cover. The authors use α=2. The set of exemplars chosen from is the concatenation of SMOLSENT and SMOLDOCSPLIT.
For 0-shot prompting, the authors used a fairly wordy prompt where the SL and TL stand for the source and target language name respectively. The prompt instructs the model to act as an expert translator and provides example pairs of text snippets. After the example pairs, the model is provided another sentence in SL and asked to translate it into TL. The instruction specifies to give only the translation and no extra commentary. For finetuned models, there is no need for such a wordy prompt as it risks overfitting. Therefore, a minimalist prompt is used instead, simply stating Translate from SLto{TL}:.
Experiment
The study assesses the SMOL dataset through fine-tuning and in-context learning experiments on Gemini 2.0 Flash, utilizing CHRF metrics across FLORES-200 and NTREX benchmarks to validate data utility. Findings show that combining dataset subsets yields the strongest performance gains, particularly for low-resource languages, while in-context learning on untuned models achieves results similar to fine-tuned zero-shot decoding. Additionally, selection process experiments confirmed the effectiveness of a set-cover approach, though reverse translation tasks revealed severe overfitting that necessitates restricting focus to English-to-other-language directions.
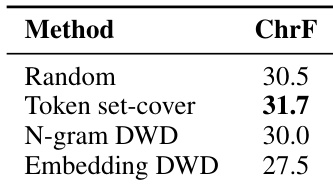
The authors evaluated different data selection strategies for fine-tuning a machine translation model to validate the effectiveness of the SMOLSENT dataset. They compared Token set-cover against N-gram DWD, Embedding DWD, and a random baseline to determine the optimal selection method. The results indicate that Token set-cover is the most effective approach, achieving superior performance compared to the other techniques. Token set-cover achieved the highest performance among all tested selection methods. Embedding DWD resulted in the lowest performance compared to the other approaches. Random selection performed better than N-gram DWD and Embedding DWD but remained inferior to the set-cover method.
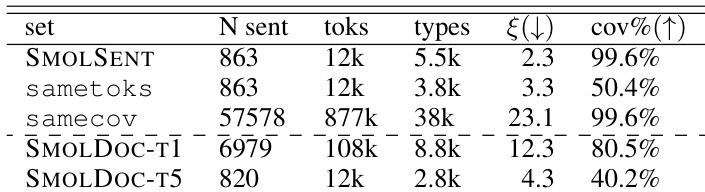
The authors evaluate the efficiency of the SMOLSENT data selection process by comparing it against baselines constrained by token count or coverage. The SMOLSENT set achieves near-complete coverage with a minimal number of sentences and a low metric value, whereas matching this coverage with other methods requires a drastically larger dataset. Conversely, limiting the baseline to the same token count results in significantly lower coverage compared to the SMOLSENT set. The SMOLSENT set achieves near-perfect coverage using a very small number of sentences. Matching the coverage of the SMOLSENT set requires the baseline to use a dataset orders of magnitude larger. The SMOLSENT set maintains a lower metric value than the baseline when constrained to the same token count.
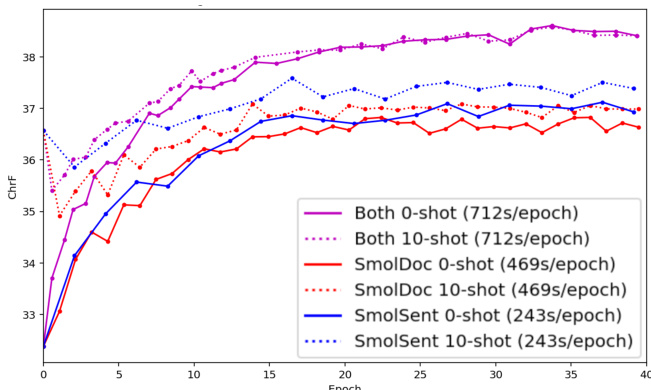
The authors evaluate the impact of finetuning Gemini 2.0 Flash on the SMOL dataset across numerous language pairs. Results indicate that finetuning generally yields positive gains in translation quality, particularly for languages that are under-resourced or not covered by major translation services. Combining dataset subsets and including additional data sources further enhances these improvements, often outperforming standard baselines. Finetuning on SMOL data leads to consistent performance gains for languages included in the training set, while languages outside the set show negligible or negative improvements. Performance improvements are most pronounced for low-resource languages that are not supported by major translation services like Google Translate. Combining sentence and document level data subsets along with additional sources like GATITOS yields the strongest overall performance gains compared to using subsets individually.
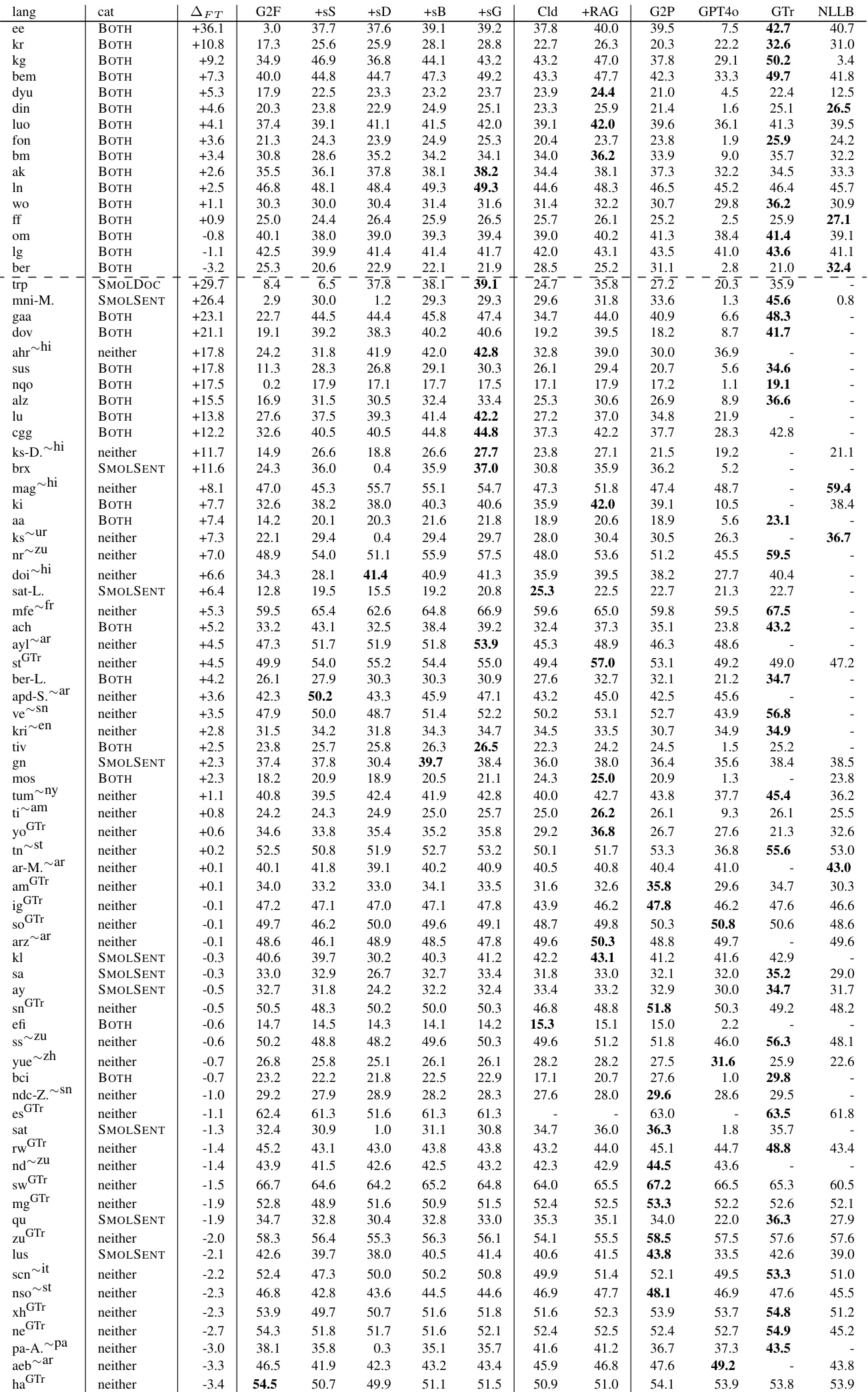
The the the table details the composition of SMOLDOC subsets, illustrating that as the number of languages increases, the amount of data per language pair decreases. The associated experiments show that fine-tuning on these datasets improves translation quality, with the best results achieved by combining multiple data sources and targeting languages not covered by major translation services. Combining the SMOLDOC and SMOLSENT datasets leads to higher performance gains than using either dataset individually. Data volume per language pair drops significantly in subsets that include a larger number of languages. Fine-tuning provides the most significant improvements for low-resource languages excluded from Google Translate, while high-resource languages show minimal gains.
The authors present per-language evaluation results showing that fine-tuning on the SMOL dataset yields varying performance changes across different language pairs. The data indicates negative gains for specific pairs, suggesting that fine-tuning did not improve performance over the base model for these languages. Strong baselines like Google Translate frequently outperform the fine-tuned models in these scenarios. Fine-tuning resulted in negative performance changes for the listed language pairs, indicating a decline in quality compared to the base model. Google Translate consistently achieved the highest scores across most language pairs, often outperforming the fine-tuned models. Retrieval-augmented generation (+RAG) demonstrated superior performance for specific language pairs, outperforming fine-tuned baselines in those instances.
The authors evaluated data selection strategies and found that Token set-cover outperforms alternative methods, allowing the SMOLSENT dataset to achieve near-complete coverage with minimal sentences. Fine-tuning on this data generally improves translation quality, particularly for low-resource languages excluded from major services, with combined datasets yielding the strongest performance gains. However, per-language results indicate varying outcomes where some pairs show negative improvements and strong baselines like Google Translate or retrieval-augmented generation remain superior.