Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Déploiement en un clic de TripoSG : de l'image unique à la 3D haute fidélité en quelques secondes
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
TripoSG introduces a streamlined diffusion framework that generates high-fidelity 3D meshes with precise input-image correspondence by leveraging a large-scale rectified flow transformer trained on extensive high-quality data to achieve state-of-the-art fidelity.
Key Contributions
- TripoSG introduces a streamlined shape diffusion paradigm that leverages a large-scale rectified flow transformer to generate 3D meshes with precise alignment to input images.
- The framework adopts a geometry-expressive 3D representation alongside an improved diffusion architecture and training strategy to resolve prior limitations in conditional alignment and generalization.
- Trained on extensive, high-quality 3D datasets, the method achieves state-of-the-art fidelity and robust generalization for synthesizing both textured and texture-free shapes.
Introduction
The growing demand for production-ready 3D content has made high-fidelity shape synthesis a critical frontier in generative AI, yet the field continues to lag behind the rapid progress seen in 2D image and video generation. Prior approaches face significant hurdles, as reconstruction-based methods often suffer from view inconsistencies and occlusion artifacts, while diffusion-based techniques rely on occupancy representations that introduce aliasing, lack fine geometric detail, and struggle to align outputs with input images. These quality issues are further compounded by a severe shortage of curated 3D datasets, which forces aggressive filtering that drastically reduces training scale. To bridge this gap, the authors introduce TripoSG, a streamlined generation framework that leverages a large-scale rectified flow transformer trained on two million meticulously processed 3D samples. By combining the transformer with a hybrid supervised VAE strategy that integrates signed distance functions, surface normals, and eikonal losses, the model achieves superior geometric reconstruction, exceptional input alignment, and state-of-the-art fidelity in image-to-3D synthesis.
Dataset

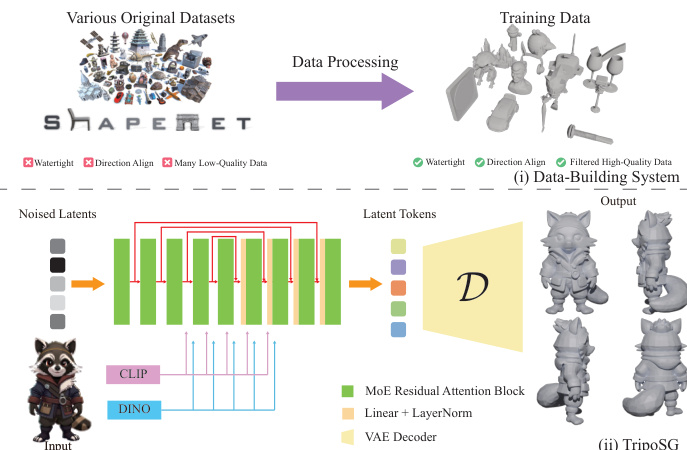
- Dataset Composition and Sources: The authors construct their training corpus primarily from Objaverse(-XL) and ShapeNet, beginning with an initial pool of approximately 10 million 3D models gathered from public internet sources.
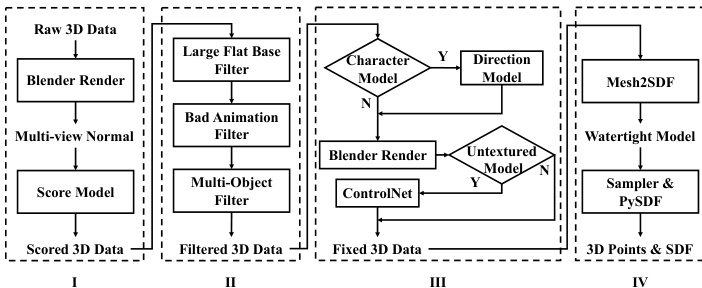
- Quality Control and Filtering Rules: To address inconsistent data quality, the team implements a four-stage preprocessing pipeline. A scoring model trained on CLIP and DINOv2 features ranks models using multi-view normal maps. Approved models then undergo strict filtering that removes assets with large planar bases, animation rendering errors, and multiple disconnected objects.
- Final Dataset Size: After applying these quality controls, the authors curate a final training collection of 2 million high-quality 3D objects.
- Orientation Fixing and Augmentation: Character models are automatically aligned to face forward using a DINOv2-based orientation estimator trained on 24 rotational poses. For untextured assets, the authors render multi-view normal maps and leverage ControlNet++ to synthesize corresponding RGB images, which serve as conditional inputs during training.
- Geometry Processing and Field Construction: To enable neural implicit field training, non-watertight meshes are converted into watertight representations. The authors generate a 512³ Unsigned Distance Function (UDF) grid, clear invisible voxel values, and extract surfaces using Marching Cubes with a threshold of 3/512. Small interior components are pruned using area and ambient occlusion metrics, followed by uniform sampling of surface normals and volume points.
- Training Configuration and Camera Parameters: The curated dataset trains the TripoSG flow model. For single-image conditioning, the authors render 8 random viewpoints positioned in front of each object. Camera parameters are randomized within an elevation range of -15° to 30°, an azimuth range of 0° to 180°, and a focal length selection drawn from orthogonal, 50mm, 85mm, 135mm, or two randomly chosen values between 35mm and 65mm. Ground-truth Signed Distance Functions are computed from the sampled points to supervise geometry learning.
Method
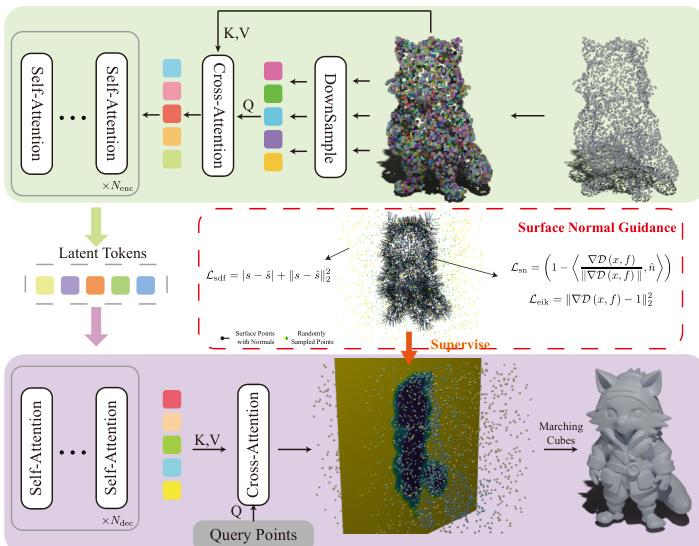
The TripoSG framework is structured around a rectified flow-based transformer architecture designed for image-conditioned 3D shape generation. The overall system, as illustrated in the framework diagram, consists of a data-building pipeline, a variational autoencoder (VAE) for encoding and decoding 3D shapes into latent representations, and a flow model that generates new 3D shapes conditioned on input images. The VAE, detailed in the accompanying diagram, operates on a set of surface points to produce multi-scale latent tokens, which are then processed by the flow model to generate the final 3D geometry.
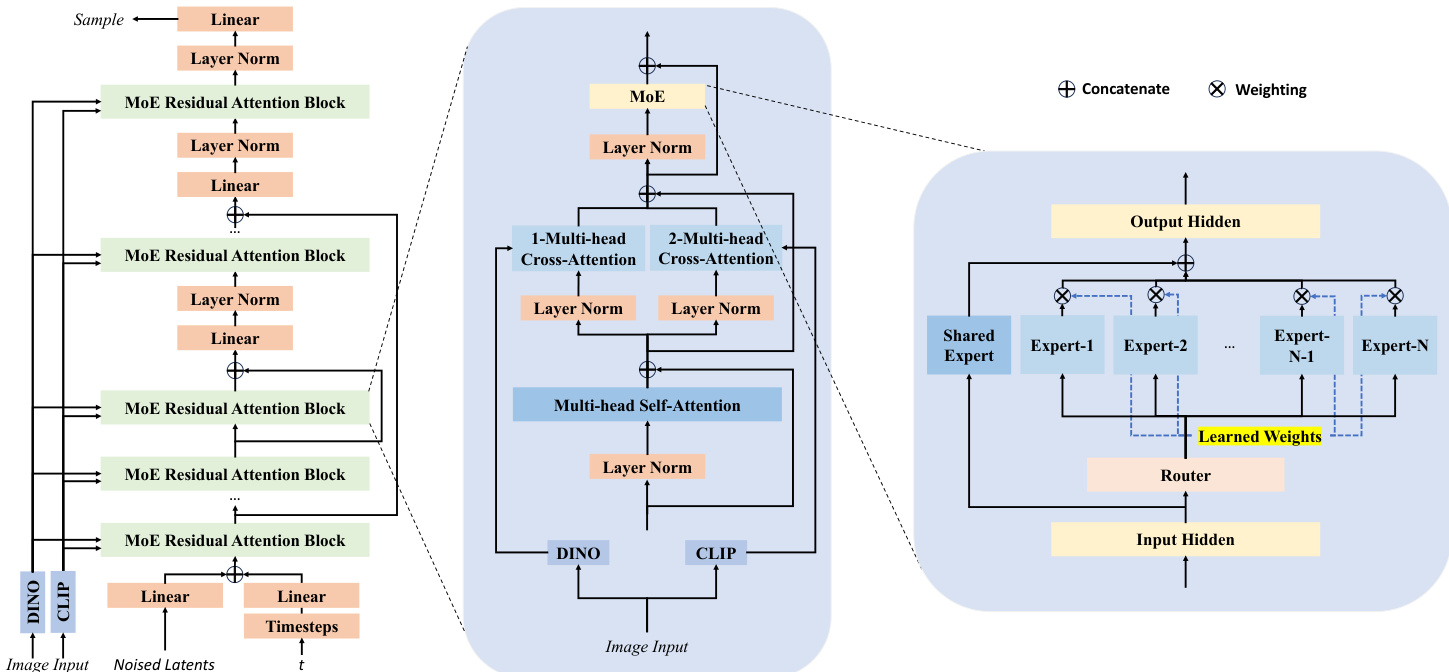
The core of the generation process is the Rectified Flow Transformer, which is built upon a transformer architecture inspired by DiT and 3DShape2VecSet. The backbone of this model is structured as an encoder-decoder with a central block, forming a total of 2N+1 transformer blocks with residual connections. This design incorporates long skip residual connections between corresponding encoder and decoder blocks to enhance feature fusion and representational capacity. The architecture employs N=10 blocks in both the encoder and decoder, with a hidden dimension W=2048 and 16 attention heads per block, resulting in a model of approximately 1.5 billion parameters. The flow architecture is designed to process latent representations X of dimensions L×C, where L∈{512,2048} and C=64, which are encoded and decoded by the VAE. The generation process is conditioned on both a timestep and an input image. The timestep t is encoded into a 1×W feature using a Timesteps layer and an MLP, while the latent X is projected to a L×W feature. These features are concatenated to form a (L+1)×W input for the flow backbone.
For image conditioning, the model uses a dual-attention mechanism to inject both global and local image features. Global features Iglobal are extracted from CLIP-ViT-L/14, while local features Ilocal are extracted from DINOv2-Large. These features are injected into each flow block via separate cross-attention mechanisms, allowing the model to attend to both global context and fine-grained details simultaneously. This approach enables faster training convergence and strong consistency between the generated 3D shape and the input image. The processing within each block follows a sequence of operations: concatenating the input latent and timestep features, applying self-attention, incorporating cross-attention with both global and local image features, and applying a feed-forward network, all with layer normalization and residual connections.
The generation process is driven by a rectified flow model, which learns a linear trajectory from noise to data, simplifying training compared to the curved trajectories of DDPM and EDM. This linear approach is more efficient and stable, and is enhanced by logit-normal sampling to increase the weight of intermediate steps during training. To handle higher resolutions, the model employs resolution-dependent shifting of the timestep, which remaps the timestep to maintain consistent uncertainty levels across different resolutions. This allows the model to scale effectively to higher resolutions without retraining.
To scale the model and improve performance, TripoSG employs a Mixture-of-Experts (MoE) strategy. This involves replacing the feed-forward networks (FFNs) in the transformer blocks with multiple parallel expert models, controlled by a gating module that selects the top-K experts for each token. The MoE architecture is applied to the final six layers of the decoder, where deep feature modeling is critical. This scaling increases the model parameters from 1.5B to approximately 4B while maintaining nearly constant inference latency due to the sparse activation of experts. The MoE design includes a shared expert branch across all tokens and an auxiliary loss to balance expert routing, ensuring efficient and effective scaling.
The VAE architecture, as shown in the figure, uses a transformer-based encoder-decoder structure. The encoder processes a dense point cloud of surface points, using cross-attention to integrate positional embeddings and surface normals into the latent queries. The decoder then uses these latent tokens to predict signed distance function (SDF) values for query points in 3D space. The model adopts neural SDF as the primary representation, which provides more precise and detailed geometry compared to occupancy-based methods, avoiding aliasing artifacts. To further enhance geometric detail, the VAE training incorporates surface normal guidance and eikonal regularization. The total VAE loss combines SDF loss, surface normal loss, eikonal regularization, and KL regularization in the latent space. This comprehensive supervision ensures the model learns fine-grained geometric details, resulting in high-quality 3D reconstructions.
Experiment
The evaluation setup benchmarks TripoSG against leading image-to-3D methods using qualitative visualizations and quantitative assessments across diverse, complex inputs to validate overall generation performance. Ablation studies on the flow model and VAE confirm that architectural improvements like skip connections and R-Flow sampling, alongside neural SDF representations guided by surface normals and eikonal regularization, substantially enhance geometric fidelity and reconstruction accuracy. Scaling experiments further demonstrate that prioritizing high-quality curated data yields greater initial gains than raw dataset expansion, while progressively increasing the volume of refined training data continues to drive performance improvements without saturation. Ultimately, TripoSG consistently outperforms existing approaches in semantic alignment, detail preservation, and cross-style generalization, establishing a robust foundation for high-fidelity 3D generation.
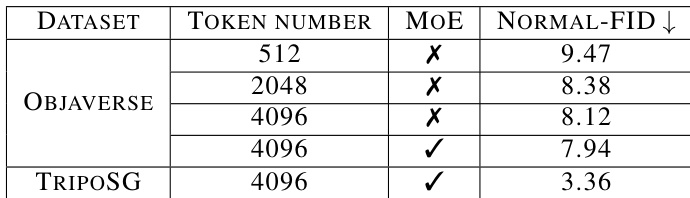
The authors evaluate the impact of data quality and quantity on 3D generation performance using Normal-FID as a metric. Results show that improving data quality through a data-building system leads to better performance compared to using raw, unprocessed data. Scaling up the size of high-quality data further enhances performance, with the largest improvement observed when increasing data from a smaller high-quality set to a larger one. Improving data quality through a data-building system enhances 3D generation performance compared to using raw, unprocessed data. Scaling up the size of high-quality data leads to significant improvements in generation performance. The performance gains from increasing high-quality data size are greater than those from improving data quality alone.

The authors conduct ablation experiments to evaluate the impact of data quality and model scaling on 3D generation performance. Results show that increasing data quality leads to better performance compared to using larger but lower-quality datasets, and scaling up the high-quality dataset size further improves results. The combination of high-quality data and larger model size achieves the best performance. Improving data quality leads to better generation results than using larger but lower-quality datasets. Scaling up the size of high-quality data significantly improves generation performance. Combining high-quality data with larger model size achieves the best overall performance.
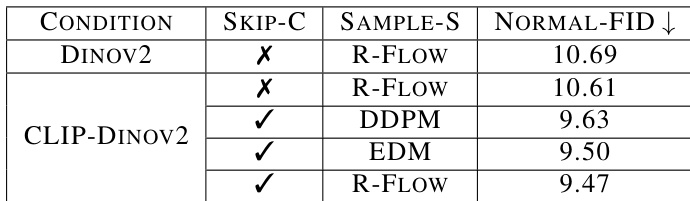
The authors conduct ablation experiments to evaluate the impact of different components on the flow model's performance, focusing on sampling methods, skip-connections, and conditioning. The results show that combining CLIP-DINOv2 conditioning with skip-connections and R-Flow sampling leads to the best performance, as indicated by the lowest Normal-FID score. The improvements from these components are significant, with skip-connections and the choice of sampling method having a clear impact on generation quality. Combining CLIP-DINOv2 conditioning with skip-connections and R-Flow sampling achieves the best Normal-FID performance. Skip-connections significantly improve generation results by enhancing feature fusion. R-Flow sampling outperforms other sampling methods like DDPM and EDM in 3D generation tasks.
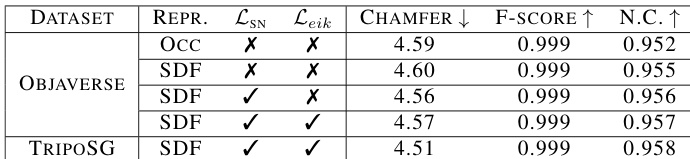
The authors conduct ablation experiments to evaluate the impact of different 3D representations, training supervision, and dataset quality on VAE reconstruction. The results show that using SDF representation with surface normal guidance and eikonal regularization leads to better reconstruction quality compared to occupancy-based methods. Additionally, increasing the size of the high-quality dataset significantly improves performance, demonstrating that data quality and quantity are both important factors in achieving superior results. SDF representation with surface normal guidance and eikonal regularization improves reconstruction quality over occupancy-based methods. Increasing the size of the high-quality dataset leads to significant performance improvements. Data quality is more important than raw dataset size, but performance continues to improve with increased data quantity after quality improvements.
Through systematic ablation studies, the authors evaluate how data curation, model scaling, architectural components, and 3D representation strategies influence generation and reconstruction performance. The experiments validate that prioritizing high-quality curated data consistently yields superior results compared to larger raw datasets, with performance improving substantially as quality data scales. Optimal outcomes emerge from combining expanded high-quality datasets with larger model capacities, while specific architectural choices like CLIP-DINOv2 conditioning, skip-connections, and R-Flow sampling significantly enhance generation fidelity. Additionally, SDF-based representations with geometric regularization demonstrate clear advantages for reconstruction, establishing that strategic data curation and targeted model design are the fundamental drivers of overall system success.