Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
RNN avancés : RNN bidirectionnels
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
By applying transfer learning and long-short term memory recurrent neural networks to over twelve years of daily meteorological and pollutant data from five Macau monitoring stations, this study develops a predictive framework that forecasts future air pollutant concentrations while compensating for data scarcity at specific air quality stations.
Key Contributions
- A long-short term memory (LSTM) recurrent neural network framework is developed to forecast future air pollutant concentrations in Macau by integrating historical pollutant measurements with meteorological variables.
- Transfer learning and pre-trained neural network architectures are employed to mitigate data scarcity at air quality monitoring stations, ensuring robust model training despite limited observational records.
- The methodology is validated using over twelve years of daily measurements from five monitoring sites, establishing a computational intelligence-based prediction system for regional air quality forecasting.
Introduction
Accurate forecasting of air pollutant concentrations is critical for public health planning, yet many monitoring stations operate with sparse or incomplete historical records. Traditional machine learning approaches typically require large, continuous datasets to train effectively, which severely limits their predictive accuracy and increases computational overhead when deployed in data-scarce environments. To address this, the authors leverage transfer learning combined with Long Short-Term Memory recurrent neural networks. They pre-train models on data-rich nearby stations and transfer the learned weights to data-limited targets, demonstrating that this strategy yields higher forecast accuracy and faster convergence than randomly initialized networks.
Dataset

-
Dataset Composition and Sources: The authors use a daily time series dataset sourced from Macau’s Automatic Weather Stations (AWS) and multiple Air Quality Monitoring Stations (AQMS). The records were acquired through an official application to SMG and span 4,656 days from October 1, 2001, to July 1, 2014. Each timestamp contains 41 features that combine meteorological readings, observed pollutant concentrations, and predicted pollutant values.
-
Subset Details and Station Coverage: The dataset focuses on five target pollutants: PM2.5, PM10, NO2, NO, and CO. PM2.5 observations are available across all monitored stations, while the High Density Residential area in Taipa contains sparser records. The authors provide pre-trained neural networks for PM2.5 across all stations, alongside PM10 models for the Roadside, Residential, and Ambient (Taipa) stations.
-
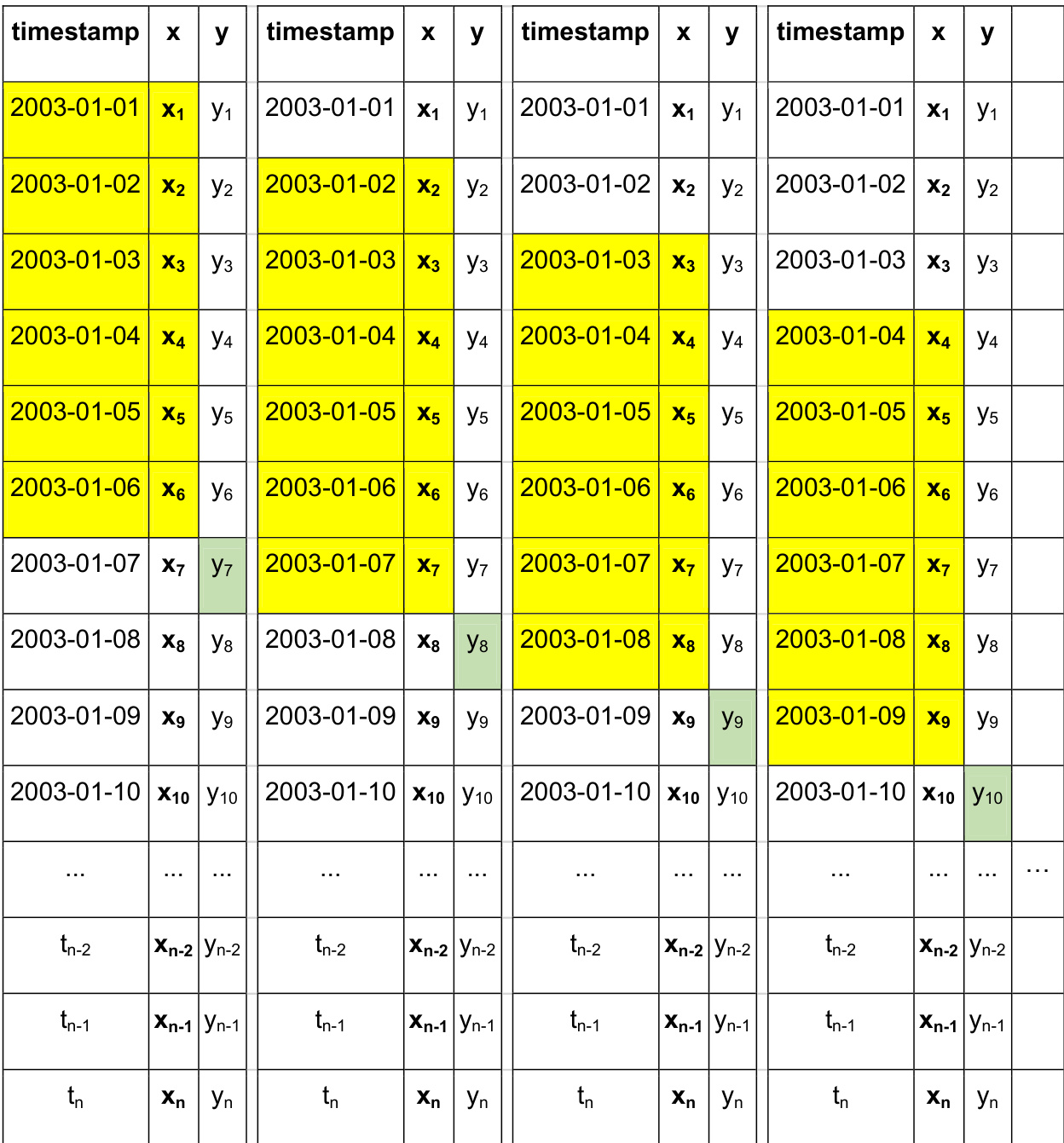
Sequence Construction and Processing: To prepare the data for supervised learning, the authors apply a fixed six-day sliding window. Each sample uses observations from the previous six days to predict the concentration value for the following day, structured as (x1,x2,x3,x4,x5,x6,y7). All feature values undergo min-max rescaling to fit a strict [0, 1] range before being fed into the networks.
-
Training Splits and Model Usage: The timeline is partitioned chronologically into a training set (71 percent covering nine years), a validation set (25 percent covering three years), and a testing set (5 percent covering 0.75 years). Each air pollutant is assigned a dedicated RNN or LSTM architecture. The authors train these models from random initialization and compare them against the provided pre-trained networks to evaluate standard training versus transfer learning across different stations and pollutant types.
Method
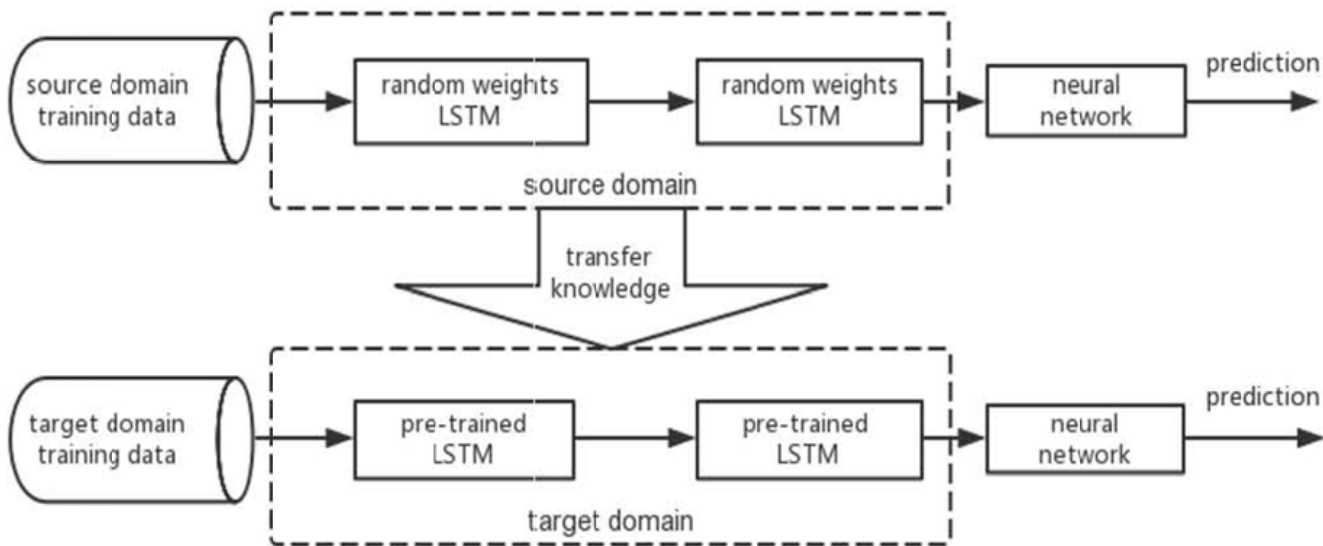
The authors leverage Long Short-Term Memory Recurrent Neural Networks (LSTM RNNs) to model the concentration of air pollutants (APS) as a time series prediction problem. The framework is designed to address scenarios where certain air quality monitoring stations (AQMSs) have limited observed data, which can hinder effective model training. To overcome this limitation, the proposed methodology incorporates transfer learning, enabling the transfer of knowledge from a source domain with abundant data to a target domain with sparse observations. The overall architecture consists of two primary stages: the source domain training and the target domain adaptation.
In the source domain, a standard LSTM network is constructed with randomly initialized weights. This network is trained using historical observations from AWSs and AQMSs in Macao, with the goal of predicting the concentration of a specific air pollutant at a given AQMS. The training process involves feeding the model with time-series data, where each input sequence corresponds to a window of past observations, as illustrated in the figure below. The model learns to map these sequences to future pollutant concentrations.

After training, the resulting LSTM becomes a pre-trained network, representing the learned knowledge from the source domain. This pre-trained model serves as the initialization for the target domain task. The target domain involves predicting the concentration of an air pollutant—potentially different from the source domain—at another AQMS, which may have fewer observations. In this stage, a new LSTM network is constructed, and the weights of the pre-trained model are used as the initial state. The target domain training data is then used to fine-tune the network, allowing it to adapt to the new task while leveraging the general patterns learned from the source domain.
The architecture of the LSTM network is structured to process sequential data effectively. The model comprises multiple LSTM layers, with the first layer receiving input data that includes features from the observed time series. The input data is structured as a sequence of time steps, as shown in the framework diagram, where the model processes data from time t-B to t-1 to predict the concentration at time t. The architecture is further detailed in the diagram below, which shows the flow of data through the layers.
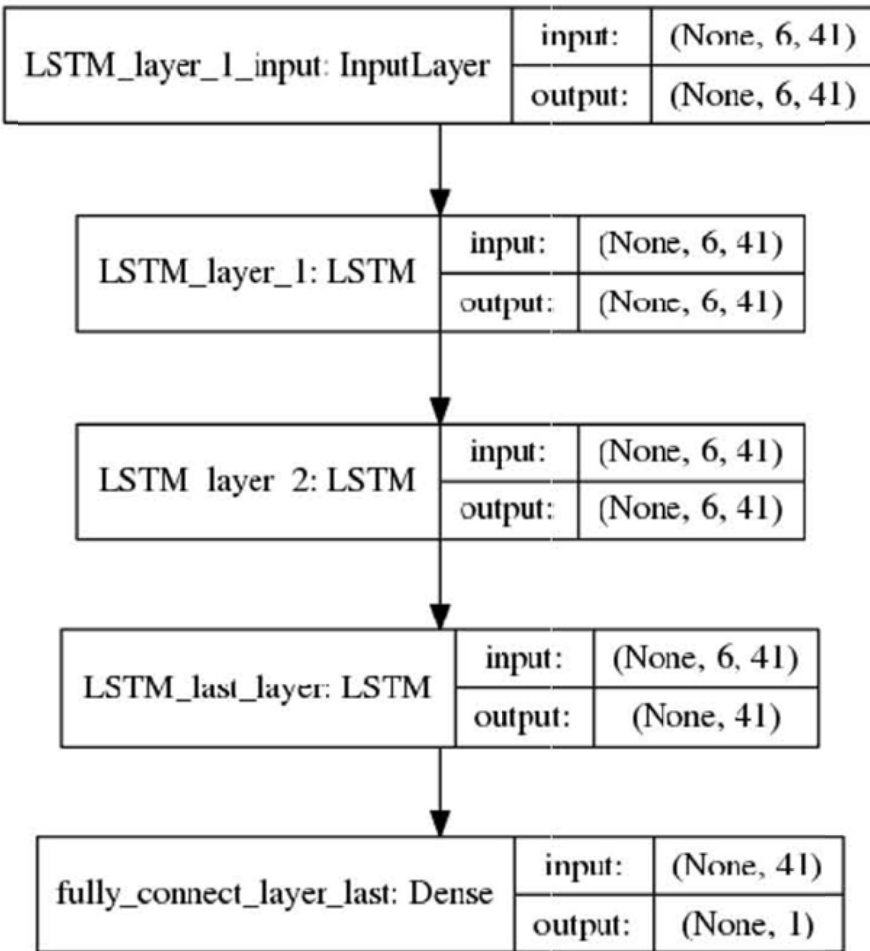
The network consists of an input layer followed by two LSTM layers and a final dense layer. The input layer processes the time-series data, which is then passed through the LSTM layers to capture temporal dependencies. The final dense layer produces the prediction output. The diagram below illustrates the specific configuration of the network, including the input and output dimensions of each layer. The input dimension is (None, 6, 41), indicating that the network processes sequences of length 6 with 41 features per time step. The output dimension of the final layer is (None, 1), corresponding to the predicted concentration value.
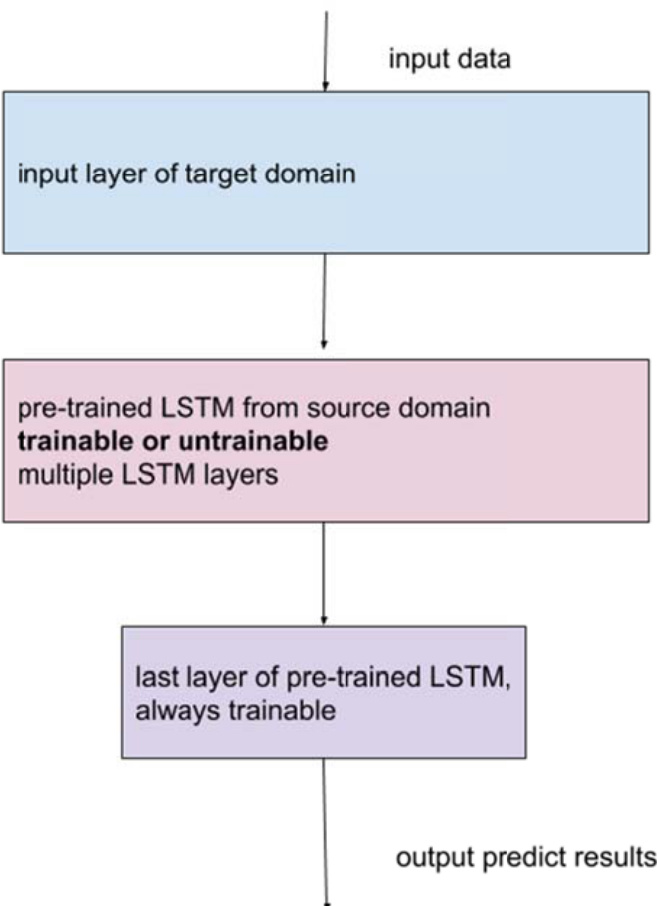
During the transfer learning process, the pre-trained LSTM weights are transferred to the target domain, where the model is fine-tuned using the target domain data. The diagram below shows the process of adapting the pre-trained model for the target domain. The input data from the target domain is fed into the pre-trained LSTM layers, which are either trainable or untrainable depending on the specific transfer learning strategy. The last layer of the pre-trained LSTM is always trainable, allowing the model to adapt its final output layer to the new task. This approach enables the model to achieve better initial states, leading to faster convergence and higher prediction accuracy, particularly in scenarios with limited training data.
Experiment
The experiments evaluate transfer learning approaches against randomly initialized neural networks and LSTMs by leveraging correlated air quality data from nearby monitoring stations. The base scenario validates whether pre-training improves prediction accuracy, convergence speed, and initial learning states, while the alternative scenario tests the impact of making the target domain input layer either trainable or fixed. Across both setups, pre-trained models consistently outperform random initialization by delivering more stable convergence and higher predictive accuracy. Although transfer learning requires marginally more computational time, it reliably enhances overall model performance, particularly under standard pollution conditions.
The authors compare pre-trained neural networks with randomly initialized networks for air quality prediction, showing that pre-trained models achieve better performance and faster convergence. The results vary across different locations and pollutants, with pre-trained models generally outperforming random initialization in terms of accuracy and training efficiency. The study also explores two variants of pre-trained models—trainable and untrainable—finding that both are superior to random initialization, though with different computational costs. Pre-trained neural networks consistently outperform randomly initialized networks in prediction accuracy and training speed. The performance of pre-trained models varies by location and pollutant type, with some configurations showing significantly better results. Both trainable and untrainable pre-trained models improve prediction performance compared to random initialization, with differences in computational efficiency.
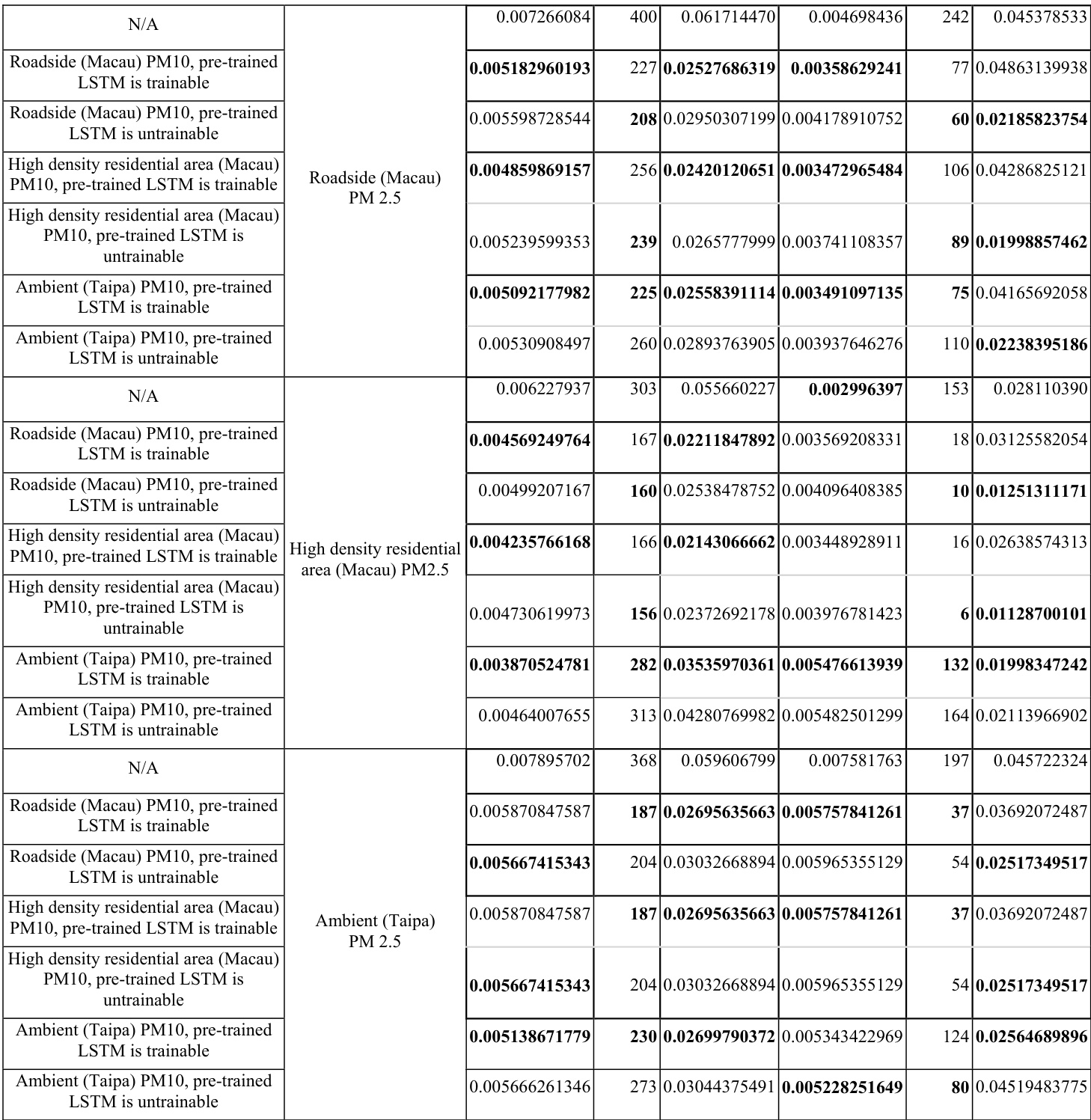
The authors compare the performance of randomly initialized neural networks with pre-trained networks using transfer learning, focusing on prediction accuracy and training efficiency. Results show that pre-trained networks generally achieve lower error rates and require fewer training epochs compared to random initialization, with some variations across different air quality monitoring stations and pollutants. The study also evaluates two configurations of pre-trained models—trainable and untrainable—finding that both outperform random initialization, though with differences in computational cost. Pre-trained networks consistently achieve lower prediction errors compared to randomly initialized networks across multiple air quality monitoring stations and pollutants. Pre-trained models require fewer training epochs to reach optimal performance, indicating faster convergence. Both trainable and untrainable configurations of pre-trained models outperform random initialization, with differences in computational cost between the two approaches.
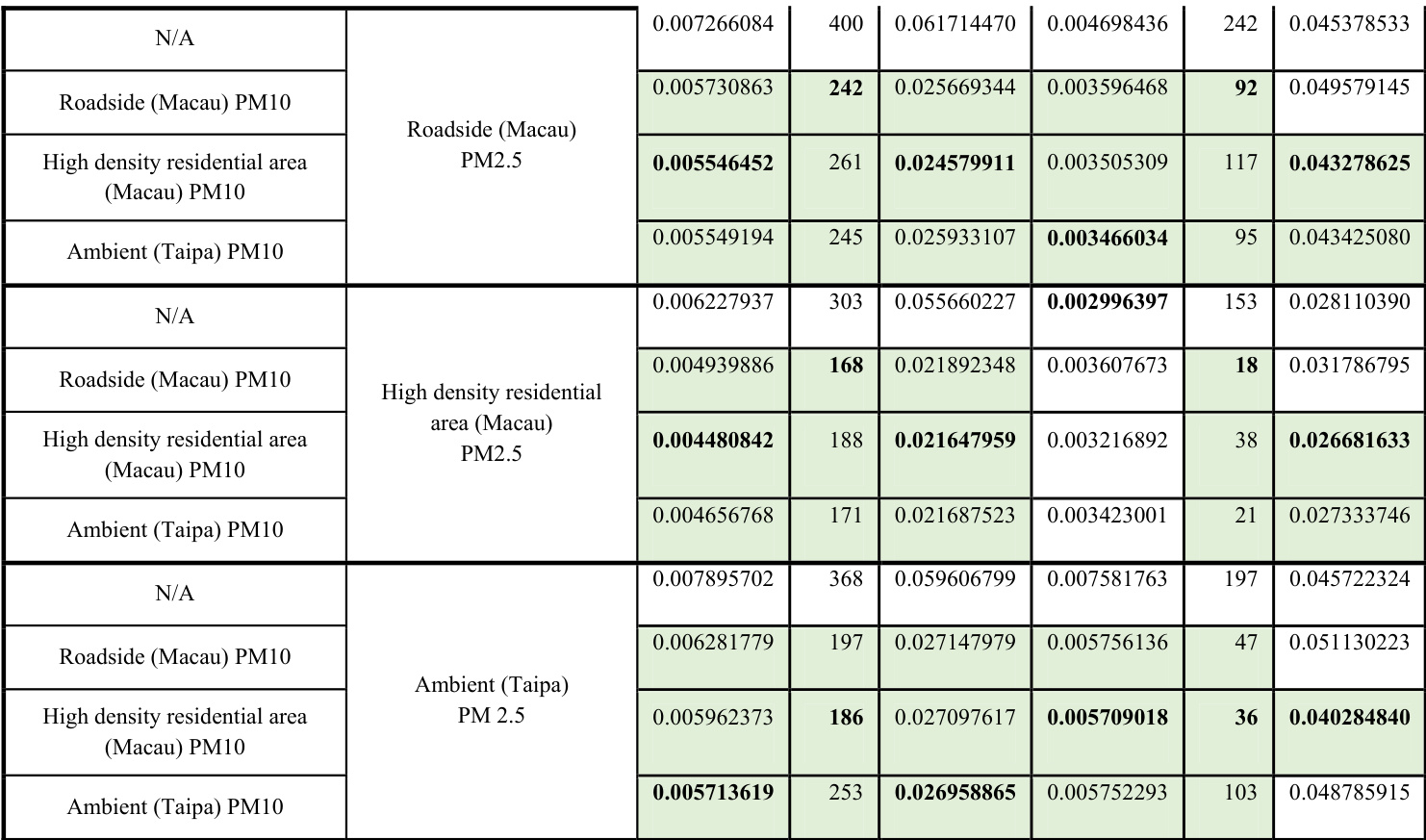
The authors compare a pre-trained neural network approach with a randomly initialized one, using transfer learning from related domains to improve prediction accuracy and training efficiency. Results show that pre-trained models achieve better performance and faster convergence compared to random initialization, with consistent improvements across different air quality monitoring stations and pollutants. Pre-trained models achieve better prediction accuracy and faster convergence compared to randomly initialized networks. Transfer learning from related domains improves the initial learning state and reduces the number of epochs needed for convergence. The benefits of pre-training are consistent across different target domains and pollutants, as shown in both training and validation results.

The authors compare a pre-trained neural network approach with a randomly initialized one, showing that the pre-trained method achieves better performance in terms of prediction accuracy and learning efficiency. The results indicate that using transfer learning from related stations improves the initial state and convergence speed of the model, particularly for air quality predictions. Pre-trained networks show better prediction accuracy and faster convergence compared to randomly initialized networks. Transfer learning from similar pollutants and nearby stations improves the initial learning state and model performance. The pre-trained approach reduces the number of epochs required for convergence and enhances predictive ability.
The authors compare a pre-trained neural network approach with a randomly initialized one, showing that pre-training leads to better initial performance, faster convergence, and improved predictive accuracy. The results are presented across different air quality monitoring stations and pollutants, with pre-trained models consistently outperforming random initialization in both training and validation metrics. Pre-trained neural networks achieve better initial performance and faster convergence compared to randomly initialized networks. The proposed method using transfer learning from related domains improves predictive accuracy and reduces training time. Pre-trained models consistently outperform random initialization across different target domains and pollutants.

The experiments compare pre-trained neural networks against randomly initialized models across multiple air quality monitoring stations and pollutants to validate the effectiveness of transfer learning. Results consistently demonstrate that leveraging knowledge from related domains significantly improves prediction accuracy and accelerates convergence compared to standard initialization. Both trainable and untrainable pre-trained configurations prove effective, offering reliable performance gains with distinct computational trade-offs. Ultimately, transfer learning optimizes the initial learning state and reduces overall training demands across diverse environmental conditions.