Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Tutoriel de déploiement en un clic des algorithmes génétiques
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
GAPA is a distributed parallel framework that reconstructs genetic operations and provides an extensible library to accelerate genetic algorithms for perturbed substructure optimization, achieving an average fourfold speedup over Evox across 18 datasets spanning four graph mining tasks and ten algorithms.
Key Contributions
- GAPA is a PyTorch-based acceleration framework for genetic algorithm-driven perturbed substructure optimization that reconstructs core genetic operations and implements four parallel computation modes to enable efficient distributed execution.
- The framework provides an extensible library containing ten GA-based algorithms across four graph mining tasks, offering a simplified functional programming interface for rapid algorithm deployment.
- Evaluations across eighteen datasets demonstrate that the framework preserves solution quality while achieving an average fourfold acceleration over the Evox baseline.
Introduction
Genetic algorithms are increasingly applied to perturbed substructure optimization, a graph mining task that modifies network topologies to solve critical applications like community detection, link prediction, and node classification. While these algorithms excel at global search, they face severe computational bottlenecks when scaling to complex, real-world networks. Existing acceleration frameworks struggle with domain-specific genetic operations and enforce restrictive programming paradigms that hinder the iterative state modifications required for graph perturbation. To overcome these barriers, the authors introduce GAPA, a PyTorch-based framework that reconstructs genetic operations and implements four parallel computation modes specifically tailored for perturbed substructure optimization. By packaging these innovations into an extensible library that accelerates ten graph mining algorithms across four major tasks, the framework delivers up to four times faster execution than leading baselines while preserving solution quality.
Method
The authors leverage a parallel acceleration framework for genetic algorithms (GAs) tailored to perturbed substructure optimization (PSSO) problems, referred to as GAPA. The core of this framework is designed to optimize the genetic operations—population initialization, crossover, mutation, fitness calculation, and elitism—through a batched, matrix-based approach that enables efficient hardware acceleration. The overall workflow begins with the initialization of a population, where each individual is represented as a perturbation vector. These individuals are then transformed into a population matrix POP, which facilitates parallel execution of genetic operations. The framework operates by decomposing the traditional iterative process of perturbation evaluation into a series of matrix operations, allowing for simultaneous processing of multiple individuals in a single computational step.
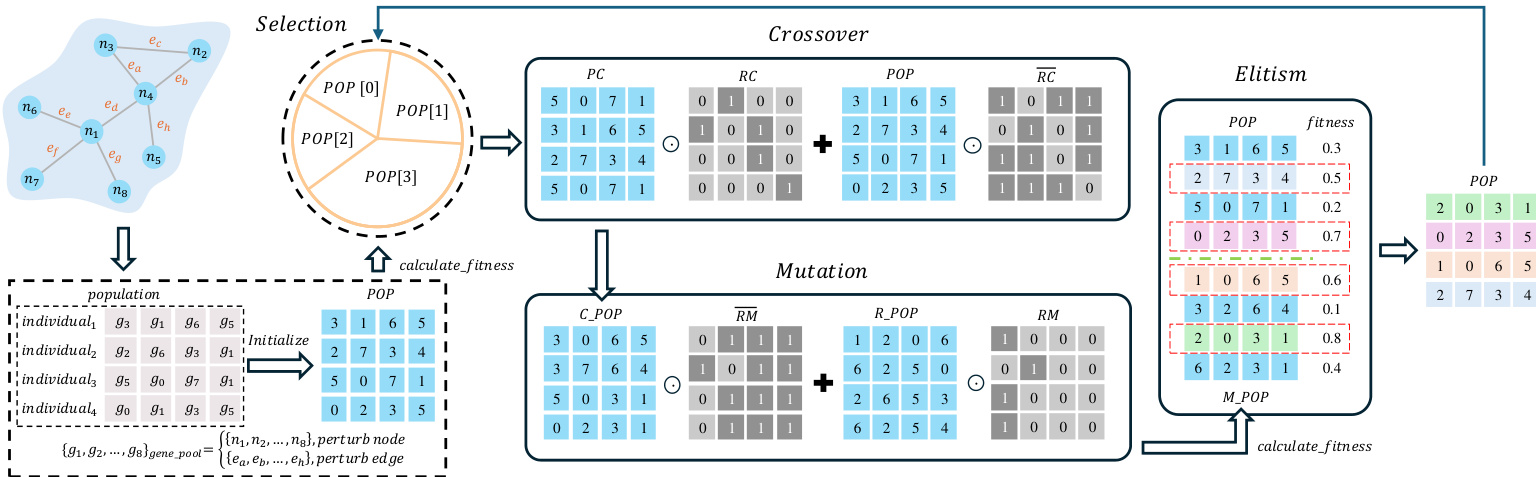
As shown in the figure below, the initialization phase converts individual perturbations into a matrix representation, enabling the subsequent genetic operations to be performed in parallel. The crossover operation is implemented as a matrix addition between two parent matrices, PC and RC, resulting in a new population matrix POP. Similarly, the mutation operation applies a mutation mask RM to the population matrix, producing a mutated population CPOP. These operations are designed to be executed efficiently on parallel hardware, such as GPUs, by exploiting the regular structure of matrices and the independence of individual elements.
The fitness calculation, a critical and time-intensive component of GA, is optimized by reformulating the evaluation process. Instead of iteratively updating and evaluating each perturbation, the framework computes the fitness of a population matrix in a single batch operation. This is achieved by converting the network into an adjacency matrix A and applying the perturbations directly through matrix operations. The fitness function, designed based on the Six Degrees of Separation Theorem, evaluates the network's connectivity by computing an accessibility matrix M. This matrix is derived from the sum of powers of the adjacency matrix, simplified using the binomial theorem to reduce computational complexity. The resulting matrix M provides a measure of each node's connectivity, with the maximum value serving as the fitness score. This approach significantly reduces the number of matrix multiplications required, from O(N⋅n3) to O(log2N⋅n3), enabling faster convergence.
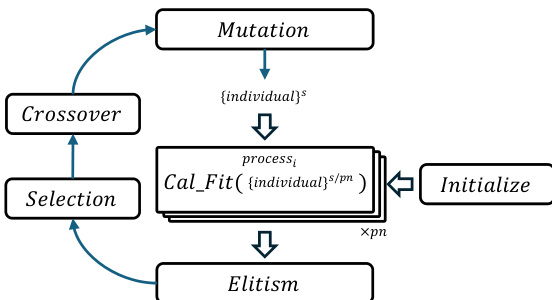
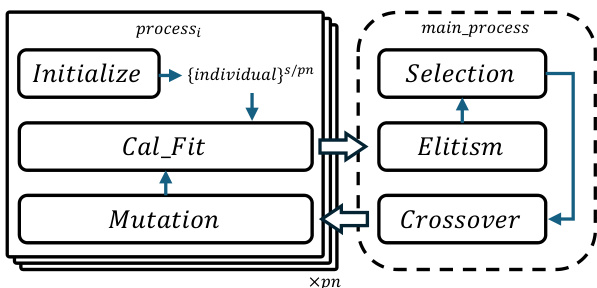
The framework further enhances efficiency by adopting a process-based parallelization strategy. The main process orchestrates the genetic operations, while multiple worker processes handle individual tasks in parallel. Each worker process initializes a subset of the population and computes the fitness for its assigned individuals. The results are then exchanged with the main process, which performs selection, crossover, and elitism. This distributed approach allows for dynamic load balancing and efficient utilization of computational resources. The framework supports both single-machine and multi-machine configurations, with data exchange between processes managed through a centralized main process. The modular design enables seamless integration of different genetic operations and fitness functions, making it adaptable to various PSSO problems.
Experiment
The evaluation setup tests GAPA across multiple network optimization tasks, datasets, and algorithms using CPU and multi-GPU environments to assess four distinct acceleration modes, varying population sizes, and distributed computing configurations. The experiments validate that the framework significantly accelerates genetic algorithm-based workloads, with the multi-process mode consistently delivering superior performance as data scale increases. Qualitative findings indicate that acceleration benefits scale positively with larger populations and datasets, though distributed deployments eventually encounter diminishing returns due to inter-process communication overhead. Overall, the results confirm that GAPA effectively balances computational efficiency and resource utilization, outperforming existing acceleration frameworks for large-scale evolutionary computing tasks.
The authors evaluate the performance of GAPA across different acceleration modes, datasets, and tasks, focusing on computation time and algorithmic efficiency. The results show that GPU acceleration significantly improves performance for large-scale datasets, with the M mode generally providing the best acceleration. The effectiveness of acceleration increases with larger population sizes and dataset scales, and GAPA outperforms Evox in most cases, particularly on larger datasets. The M mode consistently achieves the best acceleration performance across tasks and datasets, especially for large-scale problems. Acceleration effects become more pronounced as population size and dataset scale increase, with GAPA outperforming Evox in most cases. The S and M modes show significant speedups on large datasets, while overhead from data transfer limits gains at higher GPU counts.
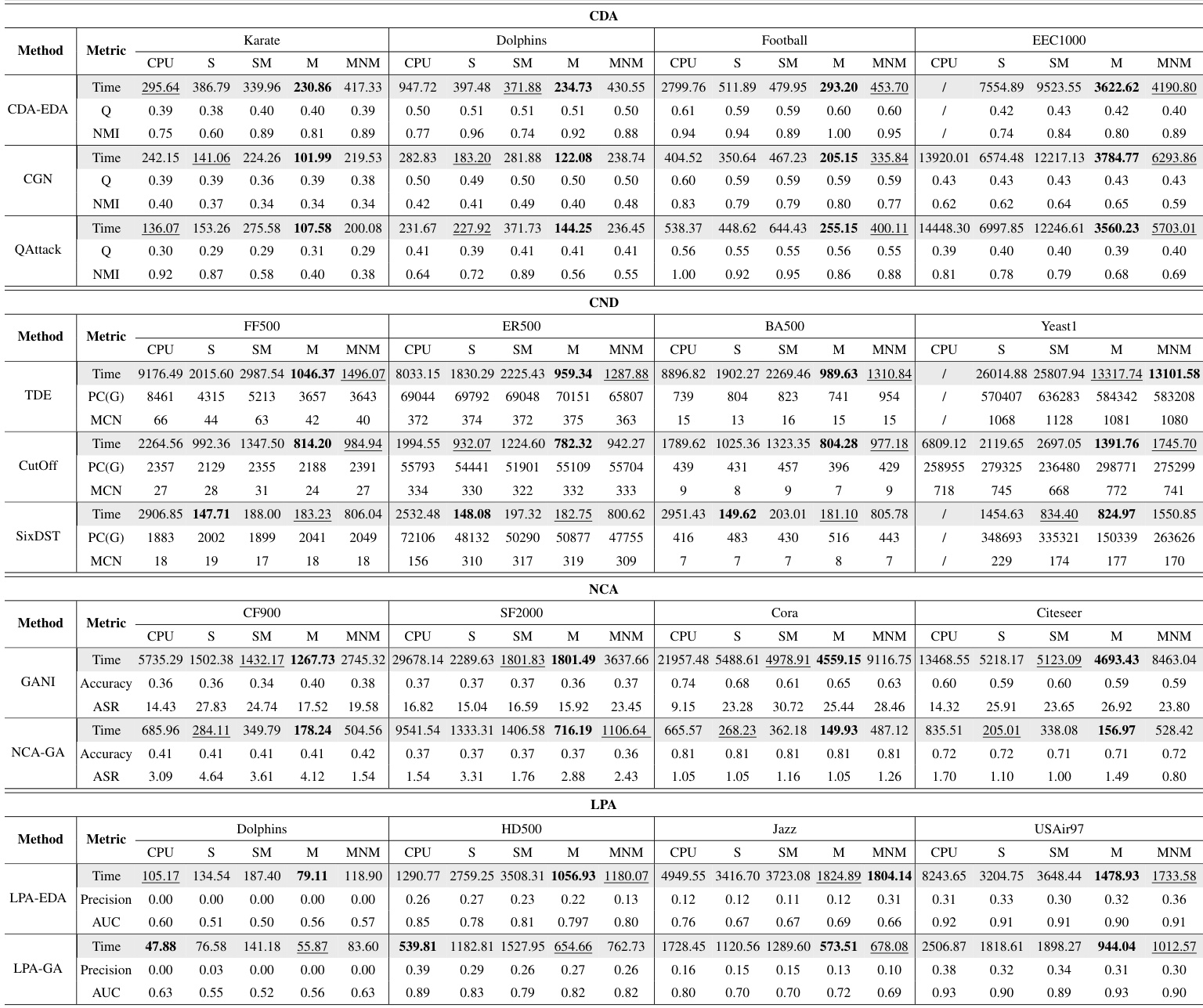
The authors evaluate the performance of GAPA across different acceleration modes, population sizes, and datasets, focusing on its ability to enhance computational efficiency for genetic algorithm-based problems. The experiments show that acceleration effectiveness varies with computational load, where larger datasets and population sizes lead to greater speedups, particularly in the M mode, while smaller-scale computations may not benefit from GPU acceleration. GAPA outperforms Evox in accelerating computationally intensive algorithms, especially on larger datasets. GAPA achieves significant acceleration on larger datasets and population sizes, with the M mode generally providing the best performance. The effectiveness of GPU acceleration increases with computational load, as lightweight tasks may not benefit from or may even be hindered by GPU processing. GAPA demonstrates superior acceleration compared to Evox, particularly on large-scale datasets and computationally intensive algorithms.

The authors evaluate the performance of GAPA across four task categories—CDA, CND, NCA, and LPA—using multiple algorithms and datasets, focusing on acceleration modes, population size, and distributed computing. The experiments reveal that GPU acceleration significantly improves computation time, especially for larger datasets and heavier workloads, with the M mode generally providing the best performance. As population size and dataset scale increase, the acceleration effect becomes more pronounced, while lightweight computations show minimal or even negative gains from GPU acceleration. Distributed acceleration further enhances performance, but diminishing returns occur with additional GPUs due to increased data transfer overhead. GPU acceleration significantly improves computation time for larger datasets and heavier workloads, with the M mode providing the best performance. The acceleration effect of GAPA increases with population size and dataset scale, while lightweight computations show minimal or negative gains from GPU acceleration. Distributed acceleration enhances performance, but adding more GPUs yields diminishing returns due to increased data transfer overhead.
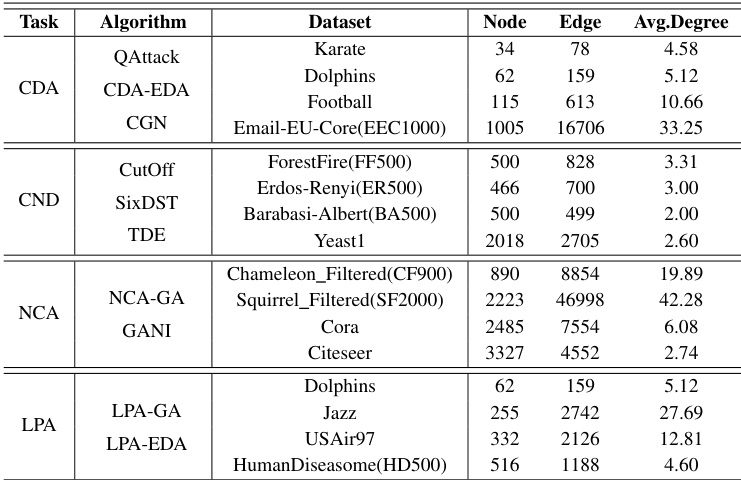
The authors evaluate the performance of GAPA across four acceleration modes and multiple datasets, focusing on computational efficiency and scalability. Results show that the M mode generally provides the best acceleration, especially for larger datasets and population sizes, while the S mode is less effective due to higher overhead. The acceleration effect improves significantly as dataset scale and population size increase, with GAPA demonstrating superior performance compared to Evox in most cases. The the the table highlights that GPU-based acceleration outperforms CPU in heavy computations, but the benefits diminish when data transfer overhead becomes significant. The M mode consistently achieves the best acceleration performance, particularly for large-scale datasets and population sizes. GPU acceleration significantly outperforms CPU for heavy computations, but the benefits decrease when data transfer overhead increases. GAPA demonstrates superior acceleration compared to Evox, especially on large-scale datasets like EEC1000 and Yeast1.
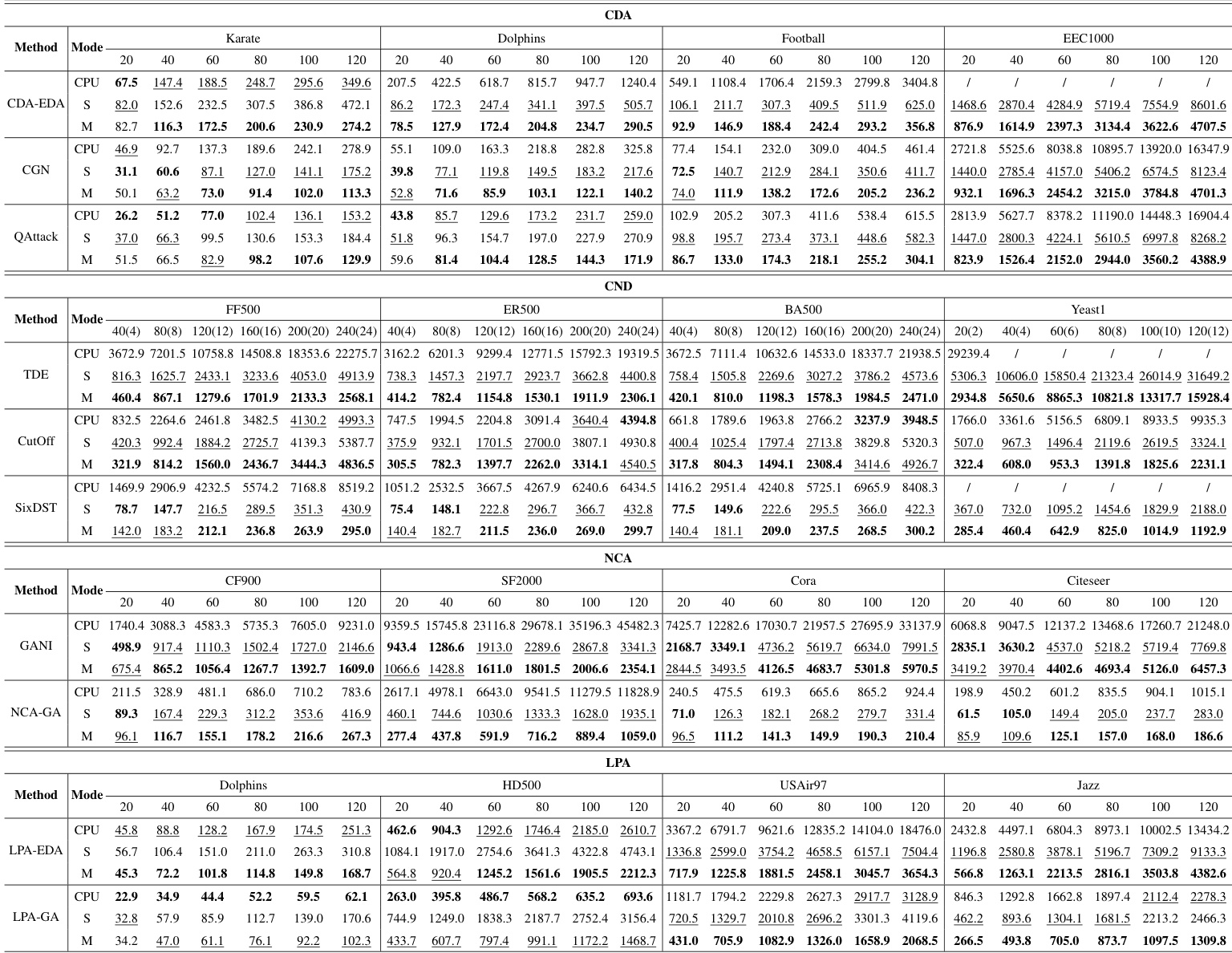
The experiments evaluate GAPA across multiple acceleration modes, datasets, and population sizes to validate its computational efficiency and scalability across varying task categories. Results demonstrate that GPU acceleration substantially enhances performance, particularly in the M mode, as benefits scale positively with larger datasets and heavier computational workloads. Conversely, lightweight tasks and configurations utilizing excessive GPUs experience diminishing returns due to data transfer overhead. Overall, GAPA consistently delivers superior acceleration and scalability, establishing its effectiveness for large-scale genetic algorithm applications.