Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Traduction automatique de machines utilisant des modèles séquence à séquence et une attention par produit scalaire
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
The authors propose a systematic framework that evaluates neural machine translation explainability through attention entropy and alignment agreement metrics, which quantitatively compare pre-trained mT5 attention patterns against statistical alignments and correlate with standard machine translation quality metrics on an English-German WMT14 test subset.
Key Contributions
- Introduces a systematic framework that quantitatively evaluates neural machine translation attention patterns by comparing them against statistical word alignments and standard translation quality metrics.
- Proposes attention entropy and alignment agreement metrics to measure focus distribution, demonstrating that peaked attention distributions correlate mildly with improved BLEU and METEOR scores and align more closely with external references.
- Validates the framework on an English-German subset from WMT14 using a pre-trained mT5 model, supplemented by visual heatmaps and statistical plots that clarify the relationship between attention interpretability and translation performance.
Introduction
Neural Machine Translation (NMT) models have achieved state-of-the-art performance but remain opaque black boxes, creating a critical need for interpretability to verify internal behaviors and build user trust. Although attention mechanisms are widely used to explain model decisions, prior work demonstrates that attention weights are not explicitly designed as word alignments and often suffer from misalignments, limiting their reliability as direct interpretability proxies. The authors address this gap by proposing a quantitative framework that evaluates attention patterns through attention entropy and alignment agreement metrics, systematically correlating these measures with statistical ground-truth alignments and translation quality scores to distinguish between interpretability and actual performance.
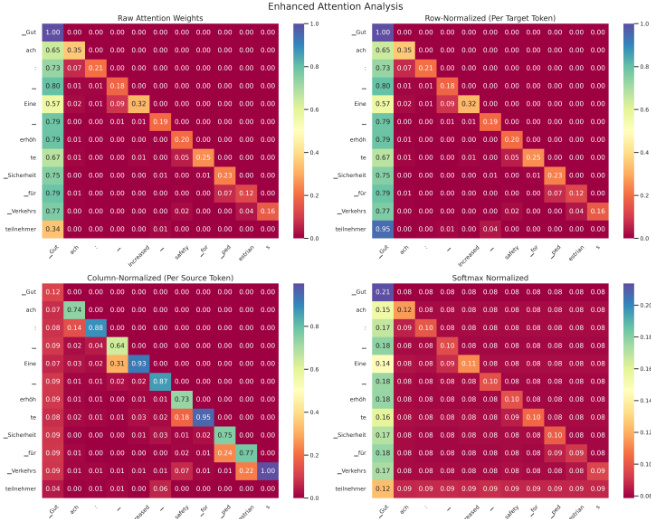
Method
The authors leverage a Transformer-based neural machine translation (NMT) model, specifically a fine-tuned mT5 architecture, to perform English-German translation. The model operates by generating target tokens autoregressively, where the probability of each token yt at position t is determined by the decoder's hidden state ht and the previously generated tokens y<t, conditioned on the source sentence x. This conditional probability is computed as P(yt∣x,y<t)=softmax(Wht), where W is a learned projection matrix.
As shown in the figure below, the model's attention mechanism plays a central role in determining how each target token attends to the source tokens. For a given target token yt, the attention distribution αt=(αt,1,αt,2,…,αt,∣X∣) represents the weights assigned to each source token xs, with the constraint that the sum of attention weights across the source sentence equals one. To evaluate the concentration of attention, the authors compute the attention entropy Ht for each target token, defined as Ht=−∑s=1∣X∣αt,slog(αt,s). Lower entropy values indicate more focused attention on a small subset of source tokens, while higher entropy reflects a more diffuse attention pattern. An average attention entropy Havg is then computed across all target tokens in a sentence or the entire corpus to summarize this behavior.
To assess the interpretability of the attention mechanism, the authors introduce a framework that compares the model's attention patterns against external alignment references obtained via FastAlign. These references consist of alignment pairs A={(si,tj)}, mapping source indices to target indices. The alignment agreement score is defined as the average attention weight over all aligned pairs: Agreement=∣A∣1∑(si,tj)∈Aαtj,si. A high agreement score indicates that the model's attention distribution aligns closely with the statistical alignment references, suggesting that the attention mechanism provides a more interpretable and human-aligned mapping between source and target tokens.
Experiment
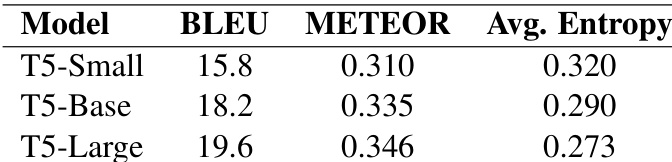
The evaluation framework assesses translation performance and attention interpretability across varying model capacities by correlating quality metrics with attention distributions and statistical alignments. The initial experiments validate that increased model capacity yields higher translation quality and more focused attention patterns, while correlation analyses confirm that sharper attention distributions strongly align with human-like alignment agreement and modestly support improved translation scores. Ultimately, the findings indicate that interpretability and performance are interconnected, suggesting that enhanced attention focus does not guarantee optimal translation but provides a viable pathway toward developing more transparent neural machine translation systems.
The authors evaluate translation quality and attention interpretability across T5 model variants, finding that larger models achieve higher translation quality and exhibit more focused attention patterns. Results show that reduced attention entropy correlates with improved alignment agreement and slightly better translation metrics, suggesting a link between model capacity, interpretability, and performance. Larger models show higher translation quality and lower attention entropy compared to smaller models. Lower attention entropy correlates with better alignment agreement, indicating more focused and interpretable attention. Reduced attention entropy is associated with slightly higher translation quality, suggesting a modest positive relationship.
The authors analyze attention patterns in T5 models of varying sizes, examining how attention normalization methods affect interpretability and alignment. Results show that larger models exhibit more focused attention distributions, which correlate with improved alignment and slightly higher translation quality metrics. The analysis reveals that lower attention entropy is associated with better alignment agreement and modestly higher quality scores, suggesting a link between interpretability and performance. Larger models show more focused attention patterns across different normalization methods, indicating improved interpretability. Lower attention entropy correlates with higher alignment agreement, suggesting more human-like attention distributions in stronger models. Reduced entropy tends to correspond with slightly higher translation quality, indicating a modest positive association between interpretability and performance.
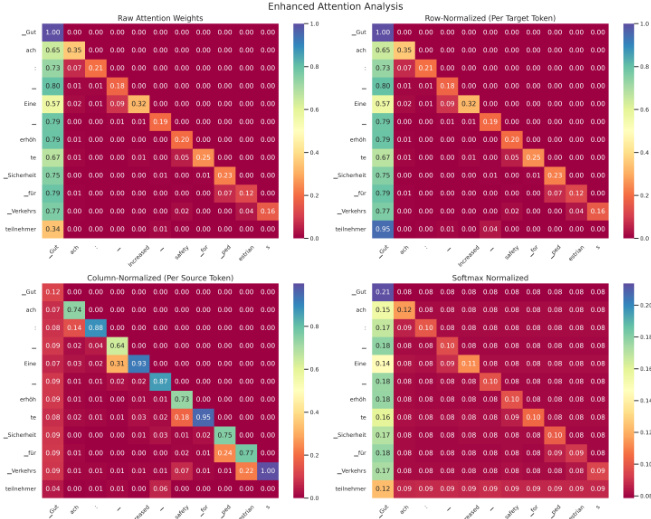
The evaluation assesses translation quality and attention interpretability across T5 model variants of varying sizes, validating the relationship between model capacity, attention normalization, and alignment behavior. Results demonstrate that larger models consistently produce higher quality translations while developing more focused attention distributions. This increased focus, characterized by reduced attention entropy, aligns more closely with human judgment and correlates modestly with improved performance, establishing a clear qualitative link between model scale, interpretability, and overall effectiveness.