Command Palette
Search for a command to run...
Étendre le benchmark VSR pour VLLM afin d'expertiser dans les règles spatiales
Étendre le benchmark VSR pour VLLM afin d'expertiser dans les règles spatiales
Peijin Xie Lin Sun Bingquan Liu Dexin Wang Xiangzheng Zhang Chengjie Sun Jiajia Zhang
Déployez QwQ-32B avec vLLM
Résumé
Distinguer les relations spatiales constitue une composante fondamentale de la cognition humaine, qui exige une perception fine à travers les instances. Bien que des jeux de référence tels que MME, MMBench et SEED aient évalué de manière exhaustive diverses capacités, incluant le raisonnement spatial visuel (VSR), il existe toujours un manque de jeux de données d'évaluation et d'optimisation en quantité et en qualité suffisantes pour les grands modèles de langage visuel (VLLM), spécifiquement ciblant le raisonnement positionnel visuel. Pour remédier à cette situation, nous avons d'abord diagnostiqué les VLLM actuels à l'aide du jeu de données VSR et proposé un jeu de test unifié. Nous avons constaté que les VLLM actuels présentent une contradiction entre une hypersensibilité aux instructions linguistiques et une sous-sensibilité aux informations positionnelles visuelles. En élargissant le jeu de référence initial sous deux aspects, à savoir les données de réglage (tuning) et la structure du modèle, nous avons atténué ce phénomène. À notre connaissance, nous avons été les premiers à étendre de manière contrôlée les données d'images positionnées spatialement en utilisant des modèles de diffusion, et à intégrer l'encodeur visuel original (CLIP) avec trois autres encodeurs visuels puissants (SigLIP, SAM et DINO). Après avoir mené des expériences de combinaison sur l'augmentation des données et des modèles, nous avons obtenu un VLLM Expert en raisonnement spatial visuel (VSRE) qui non seulement généralise mieux à différentes instructions, mais distingue également avec précision les différences dans les informations positionnelles visuelles. VSRE a enregistré une augmentation de plus de 27 % de la précision sur le jeu de test VSR.
One-sentence Summary
The authors propose VSRE, a Vision Large Language Model that mitigates the over-sensitivity to language instructions and under-sensitivity to visual positional information through diffusion-based data expansion and the integration of CLIP with SigLIP, SAM, and DINO, achieving over a 27% accuracy increase on the VSR test set.
Key Contributions
- A unified evaluation test set for visual spatial reasoning is introduced, alongside a diffusion-based approach to controllably expand spatially positioned image data for vision large language model optimization.
- The architecture integrates CLIP with SigLIP, SAM, and DINO visual encoders and applies targeted data tuning to mitigate the conflicting tendency of vision models to over-rely on textual instructions while underutilizing visual positional cues.
- The proposed VSRE model achieves over a 27% accuracy gain on the visual spatial reasoning test set and demonstrates improved generalization across diverse instructions for fine-grained positional perception tasks.
Introduction
Visual spatial reasoning is a foundational capability for Vision Large Language Models, yet current benchmarks lack the high-quality, targeted datasets required to properly evaluate and optimize positional understanding. Prior models typically struggle with a pronounced capability gap, showing excessive reliance on textual instructions while remaining under-sensitive to actual visual location cues. To address this, the authors diagnose the imbalance and leverage diffusion models to controllably expand spatially aware image data. They then integrate CLIP with SigLIP, SAM, and DINO visual encoders within a scaled architecture to develop VSRE. This approach significantly improves instruction generalization and positional discrimination, delivering a 27 percent accuracy gain on VSR benchmarks while providing an open-source dataset and model to advance the field.
Dataset
-
Dataset Composition and Sources: The authors build their foundation on the VSR dataset, which curates over 10,000 natural image-text pairs sampled from MSCOCO. They employ contrastive caption generation followed by a second round of manual validation to ensure clear positional relationships and balanced representation across 66 distinct spatial relation types.
-
Subset Details and Sizing: The training core consists of 11,000 structured triplets containing a subject, a spatial relation, and an object. These seed multiple subsets: pre-100k and pre-500k for pre-training, turn-g 500k, turn-g 11k, and turn-s 11k for instruction fine-tuning, and two evaluation sets named Test-G and Test-S. Test-G randomizes prompts across 50 templates to measure instruction-following generalization, while Test-S locks to a specific true/false caption format to assess peak spatial reasoning performance.
-
Training Usage and Data Mixing: During pre-training, the authors combine three image augmentation strategies in a 5:3:2 ratio to scale the dataset to either 100,000 or 500,000 samples. For instruction fine-tuning, they expand the 11,000 base triplets roughly 50 times using 50 distinct prompt templates to reach 500,000 samples. The unexpanded 11,000 samples serve as controlled baselines, with one version applying a random template per sample and the other using a fixed template.
-
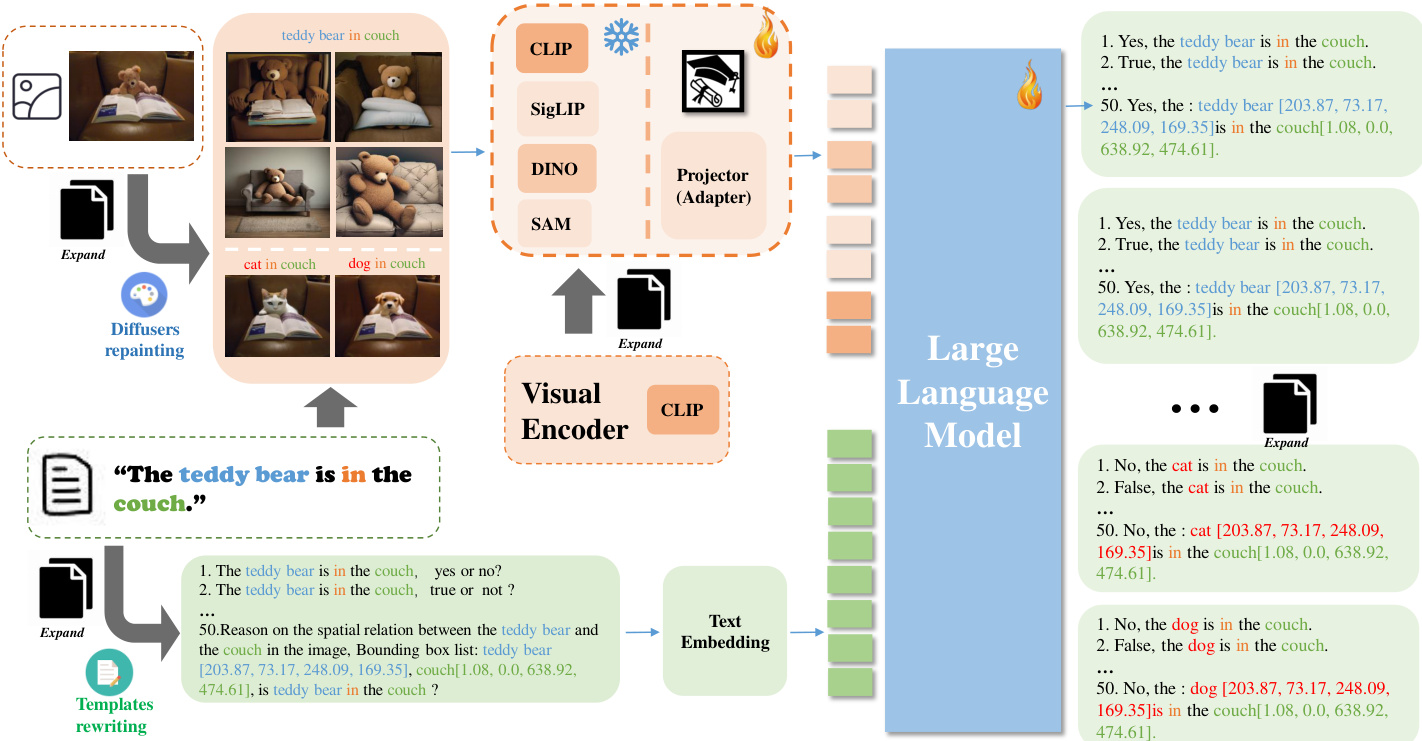
Processing and Metadata Construction: Each original sample is parsed with spaCy to extract subject-relation-object triplets alongside bounding box coordinates for the subject and object. To boost spatial perception, the authors freeze the original captions and use SDXL to generate diverse image variants. They apply three sequential augmentation strategies: image-to-image repaint to preserve background consistency, text-to-image generation to vary styles and colors, and bounding-box-guided inpainting to swap subjects and objects. Text data is simultaneously diversified through a mix of 30 manually curated and 20 GPT-4o generated prompt templates to improve instruction-following robustness.
Method
The authors leverage a merged vision encoder architecture to enhance visual spatial reasoning capabilities in vision-language models. This framework integrates multiple pre-trained visual backbones—specifically CLIP, SigLIP, DINOv2, and SAM—each contributing distinct strengths to the overall visual feature representation. The design is motivated by empirical evidence showing that combining diverse vision encoders improves performance on vision-centric tasks, particularly those requiring fine-grained visual detail perception. As shown in the figure below, each backbone is processed through a dedicated projector or adapter module to align their respective visual tokens into a unified representation space. These aligned features are then concatenated along the feature dimension, forming a composite visual embedding that captures both high-level semantic information and fine-grained spatial details. This approach builds upon prior work such as MoF, MG-LLaVA, and Cambrian, which demonstrated the benefits of multi-encoder fusion for visual grounding.
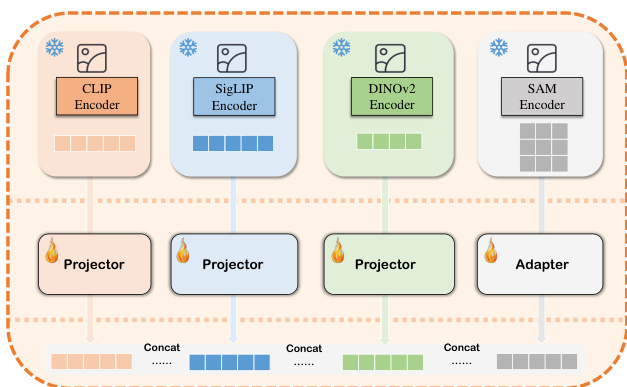
The expansion of the visual encoder is complemented by a data augmentation pipeline that generates diverse image-text pairs to improve the model's generalization. This involves controlled image generation techniques, including text-to-image, image-to-image, and image inpainting, which are used to produce new visual inputs conditioned on textual prompts and existing images. The generated images are then paired with rewritten text descriptions that emphasize spatial relationships and object positions. This process enriches the training data with variations in object placement, scene composition, and contextual cues, thereby strengthening the model’s ability to reason about visual spatial configurations. The integration of these augmented data and the merged vision encoder is designed to address limitations in existing vision-language models, such as hypersensitivity to textual prompts and a lack of sensitivity to visual positional information. The overall framework is structured to enable the model to develop a more robust and specialized understanding of spatial reasoning through both enhanced data and a more capable visual encoder.
Experiment
Initial re-evaluations isolate performance inconsistencies in vision-language models, revealing that text hypersensitivity, visual insensitivity, and answer bias severely hinder spatial reasoning. Subsequent experiments validate that a two-stage optimization strategy combining extensive instruction and visual data augmentation with a merged multi-backbone encoder architecture effectively resolves these deficits. These interventions qualitatively improve the model's generalization across diverse question formats, sharpen fine-grained spatial feature discrimination, and significantly mitigate response bias by redirecting attention from textual co-occurrence to actual visual positional relationships. Ultimately, the approach demonstrates robust cross-benchmark generalization, confirming that targeted data scaling and encoder integration successfully overcome core perception and reasoning limitations.
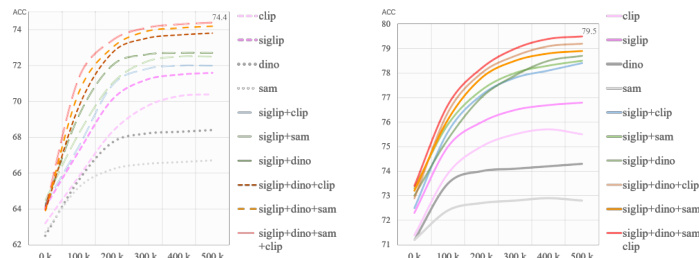
The authors conducted experiments to improve visual spatial reasoning in vision-language models by scaling training data and combining multiple vision encoders. Results show that increasing data diversity and using a merged visual encoder lead to better performance in distinguishing spatial relationships and reduced sensitivity to text prompts. The final model achieves higher accuracy and more balanced responses across different question types. Increasing training data size improves model performance in spatial reasoning tasks. Combining multiple vision encoders enhances the model's ability to perceive spatial details. The final model reduces response bias and shows more balanced accuracy across different question formats.
The authors evaluate the performance of various models on spatial reasoning tasks, focusing on improving visual sensitivity and reducing answer bias. Results show that the proposed model achieves higher accuracy across multiple benchmarks compared to baseline models, indicating improved generalization and better discrimination of spatial relationships. The proposed model outperforms baseline models on multiple benchmarks, demonstrating improved spatial reasoning capabilities. The model shows reduced answer bias, with a narrower gap between accuracy on yes and no questions. The model exhibits better visual feature discrimination, with more distinct clustering of spatial relationship categories.
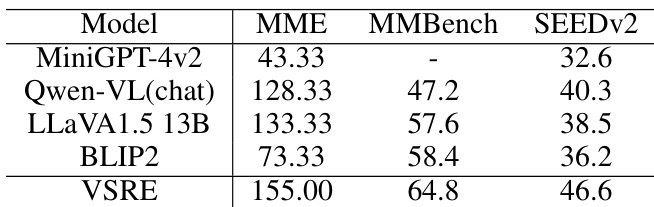
The authors compare the performance of a baseline model and an enhanced model on spatial reasoning tasks, showing that the enhanced model achieves significantly higher accuracy and better distinguishes between different spatial relationships. The results indicate improved visual sensitivity and reduced answer bias, with more consistent responses across various question formats. The enhanced model shows substantially higher accuracy and better discrimination of spatial relationships compared to the baseline model. The enhanced model reduces answer bias, with more balanced performance on yes and no questions. The enhanced model demonstrates greater visual sensitivity, with clearer separation of visual features for different spatial relations.
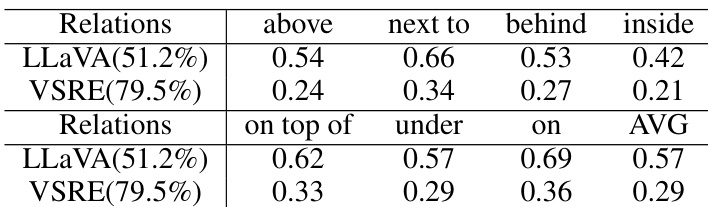
The authors conducted experiments to improve visual spatial reasoning in vision-language models by scaling data and combining multiple vision encoders. Results show that increasing the amount of training data leads to improved performance on both general and spatial reasoning tasks, and combining multiple visual backbones enhances the model's ability to perceive spatial details. The final model, VSRE, achieves higher accuracy and better generalization compared to baseline models. Increasing training data size leads to consistent improvements in model accuracy on both general and spatial reasoning tasks. Combining multiple vision encoders enhances the model's sensitivity to visual spatial information. The final model achieves higher accuracy and reduced response bias compared to baseline models.
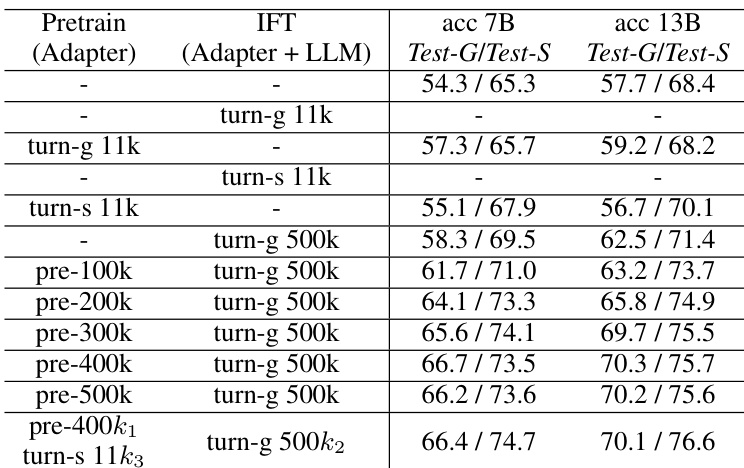
The authors conducted experiments to improve visual spatial reasoning in vision-language models by expanding training data and enhancing visual encoders. Results show that increasing data diversity and combining multiple vision backbones led to significant improvements in model accuracy and generalization across various question formats and benchmarks. The enhanced model demonstrated better sensitivity to visual positional information and reduced response bias. Increasing training data size and diversity improved model generalization and accuracy on spatial reasoning tasks. Combining multiple vision encoders enhanced the model's ability to perceive fine-grained spatial details. The optimized model showed reduced response bias and better distinction between visual positional relationships.
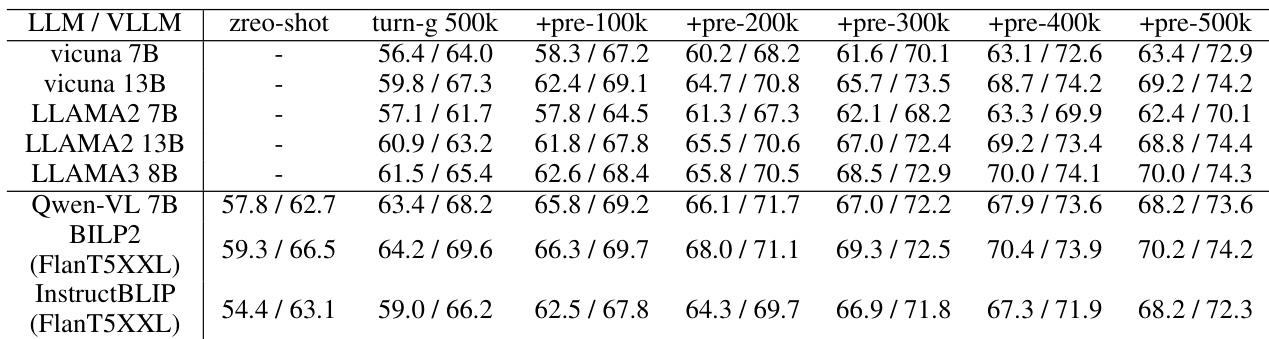
The authors evaluate vision-language models on spatial reasoning tasks by systematically scaling training data and integrating multiple vision encoders. These experiments validate that expanding data diversity consistently enhances model generalization and spatial perception, while combining visual backbones significantly improves sensitivity to fine-grained positional details. Ultimately, the optimized model demonstrates superior accuracy and markedly reduced response bias across diverse benchmarks and question formats compared to baseline approaches.