Command Palette
Search for a command to run...
SpeechPrompt : Incitation des modèles de langage de parole pour les tâches de traitement de la parole
SpeechPrompt : Incitation des modèles de langage de parole pour les tâches de traitement de la parole
Kai-Wei Chang Haibin Wu Yu-Kai Wang Yuan-Kuei Wu Hua Shen Wei-Cheng Tseng Iu-thing Kang Shang-Wen Li Hung-yi Lee
Déploiement en un clic du modèle de génération de voix pour dialogues à deux personnes CSM
Résumé
Le prompting est devenu une méthode pratique pour exploiter les modèles de langage pré-entraînés (LM). Cette approche offre plusieurs avantages. Elle permet à un LM de s’adapter à de nouvelles tâches avec un entraînement et des mises à jour de paramètres minimaux, assurant ainsi une efficacité tant en termes de stockage que de calcul. De plus, le prompting modifie uniquement les entrées du LM et exploite les capacités génératives des modèles de langage pour traiter diverses tâches en aval de manière unifiée. Cela réduit considérablement le besoin de travail humain dans la conception de modèles spécifiques à chaque tâche. Ces avantages deviennent encore plus évidents à mesure que le nombre de tâches prises en charge par le LM augmente. Motivés par les forces du prompting, nous sommes les premiers à explorer le potentiel du prompting appliqué aux modèles de langage de la parole (speech LMs) dans le domaine du traitement de la parole. Récemment, un intérêt croissant s’est manifesté pour la conversion de la parole en unités discrètes destinées à la modélisation linguistique. Notre recherche pionnière démontre que ces unités de parole quantifiées sont hautement polyvalentes au sein de notre cadre de prompting unifié. Non seulement elles peuvent servir d’étiquettes de classe, mais elles contiennent également une riche information phonétique qui peut être resynthétisée en signaux de parole pour des tâches de génération de parole. Spécifiquement, nous reformulons les tâches de traitement de la parole en tâches de génération d’unités à partir de la parole. Par conséquent, nous pouvons intégrer de manière transparente des tâches telles que la classification de la parole, la génération de séquences et la génération de parole au sein d’un seul et même cadre de prompting unifié. Les résultats expérimentaux montrent que la méthode de prompting peut atteindre des performances compétitives par rapport à la méthode de fine-tuning robuste basée sur des modèles d’apprentissage auto-supervisé, avec un nombre similaire de paramètres entraînables. La méthode de prompting présente également des résultats prometteurs dans un contexte few-shot. De plus, avec l’arrivée des modèles de langage de la parole avancés, le cadre de prompting proposé révèle un grand potentiel.
One-sentence Summary
SpeechPrompt introduces the first unified prompting framework for speech language models that reformulates classification, sequence generation, and speech generation into a single speech-to-unit generation process, leveraging quantized discrete speech units as both class labels and reconstructible outputs to achieve competitive performance compared to fine-tuning methods with similar parameter counts and promising few-shot results.
Key Contributions
- This work introduces the first unified prompting framework for speech language models, reformulating diverse speech processing objectives into a consistent speech-to-unit generation paradigm.
- The method leverages quantized speech units that function as both discrete classification tokens and re-synthesizable phonetic representations, unifying speech classification, sequence generation, and speech synthesis within a single architecture.
- Evaluations on the SUPERB benchmark demonstrate that the prompting approach achieves performance competitive with parameter-matched fine-tuned self-supervised models while maintaining robust few-shot capabilities.
Introduction
The authors leverage prompt engineering to streamline speech processing, an application domain that traditionally depends on resource-heavy fine-tuning pipelines. While self-supervised speech models deliver robust foundational representations, the standard pre-train and fine-tune paradigm requires extensive manual design of task-specific architectures and loss functions. This approach quickly becomes computationally prohibitive and difficult to scale as the number of downstream tasks grows. To overcome these limitations, the authors introduce a unified prompting framework built on textless speech language models trained with discrete speech units. By reformulating classification, sequence generation, and speech synthesis into a single speech-to-unit generation task, they eliminate the need for custom downstream heads. A learnable verbalizer efficiently maps the rich phonetic and acoustic information within discrete units to task-specific labels, enabling competitive performance across diverse benchmarks while significantly reducing storage, computation, and human engineering overhead.
Dataset
-
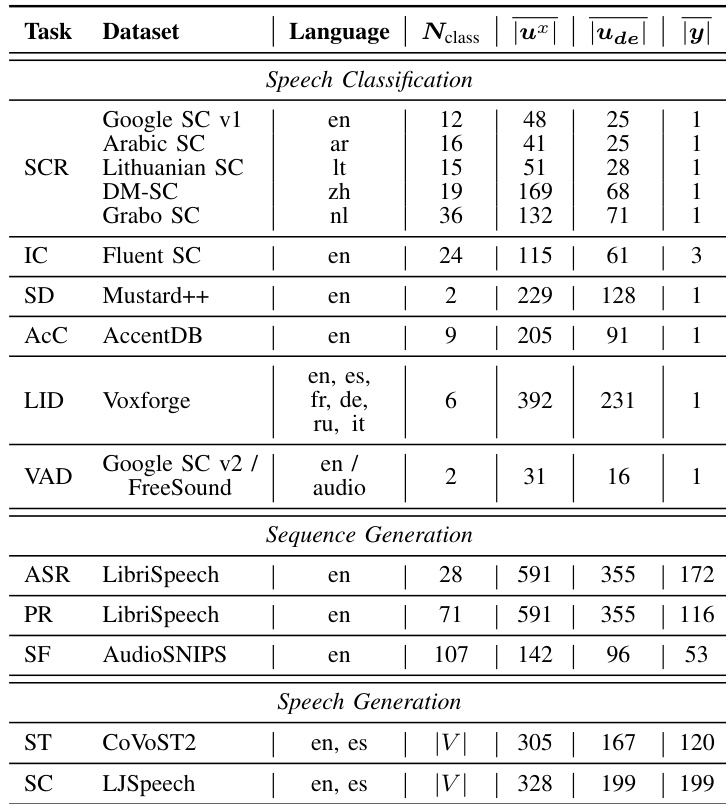
Dataset Composition and Sources: The authors compile a multi task corpus spanning three categories. Speech classification draws from Google Speech Commands, Grabo Speech Commands, Lithuanian Speech Commands, Dysarthric Mandarin Speech Commands, Arabic Speech Commands, Fluent Speech Commands, Mustard++, AccentDB, and Voxforge. Sequence generation relies on LibriSpeech and AudioSNIPS. Speech generation utilizes the Spanish to English subset of CoVoST2 and LJSpeech.
-
Key Details for Each Subset: The AccentDB subset contains four Indian English, four native English, and one metropolitan Indian English accents. Voxforge covers six languages. LJSpeech provides approximately twenty four hours of single speaker English audio. The Fluent Speech Commands subset includes triple labels for action, object, and location. The CoVoST2 subset provides parallel text for Spanish and English translation.
-
Training Splits and Data Processing: For automatic speech recognition and phoneme recognition, the authors reserve the train-clean-100 split for training and test-clean for evaluation. The LJSpeech corpus is divided into training, validation, and testing sets. The voice activity detection task uses a custom mixed dataset called GFSound, which combines Google Speech Commands version two with FreeSound background noise recordings. All classification tasks are evaluated using accuracy, while generation tasks rely on word error rate, character error rate, phoneme error rate, F1 score, BLEU, and perplexity.
-
Cropping Strategy and Metadata Construction: The authors apply a cropping strategy to the speech continuation task by designating the initial fraction of each utterance as a conditional seed segment. For speech translation, they convert parallel text into audio using an off the shelf text to speech system, then transcribe the generated audio with an off the shelf automatic speech recognition model to compute BLEU scores and naturalness predictions. Speaker similarity metadata is constructed by calculating cosine distances between Resemblyzer embeddings extracted from seed and generated segments.
Method
The proposed framework leverages textless speech language models (speech LMs) to unify diverse speech processing tasks under a single generative paradigm. The core architecture, as illustrated in the framework diagram, begins with the conversion of an input speech waveform into a sequence of discrete units. This is achieved through a speech-to-unit encoder, which combines a self-supervised learning (SSL) representation model, such as HuBERT, with a quantizer like K-means. The SSL model extracts continuous acoustic features, which are then clustered into discrete units. These units are designed to encapsulate phonetic and linguistic information, forming the basis of the model's vocabulary. As shown in the figure below, these discrete units are then fed into a unit language model (ULM), which performs autoregressive generation conditioned on task-specific prompts. The ULM can be either a decoder-only model, similar to GPT, or an encoder-decoder model, similar to BART, both of which are built upon Transformer architecture. The decoder-only variant processes the source speech units and the prompt sequentially, using a separation token to distinguish them, while the encoder-decoder variant uses the encoder to process the source units and the decoder to generate the target units conditioned on the encoder's output. 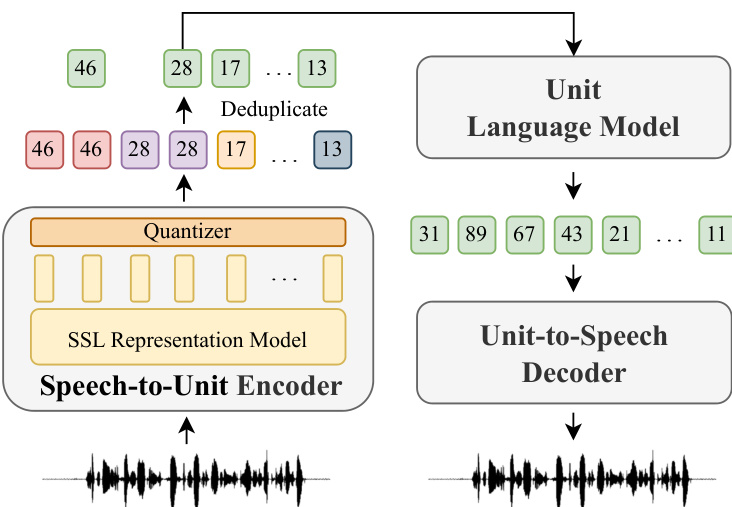
The generation of units is directed by task-specific prompts, which are designed to guide the unit language model towards the desired downstream task. The framework supports two primary prompt tuning strategies: input prompt tuning and deep prompt tuning. Input prompt tuning involves prepending continuous prompt vectors to the input sequence of the unit LM, which are then integrated at the embedding layer. This approach modifies the initial context provided to the model. Deep prompt tuning, inspired by prefix-tuning, involves inserting trainable prompt vectors directly into the attention mechanism of each Transformer layer. Specifically, these vectors are concatenated with the input to the key and value matrices of the self-attention module, thereby influencing the attention weights and guiding the model's internal representations without altering the original parameters. In both methods, only the prompt vectors are trainable, while the unit LM and its embedding table remain frozen, ensuring parameter efficiency. 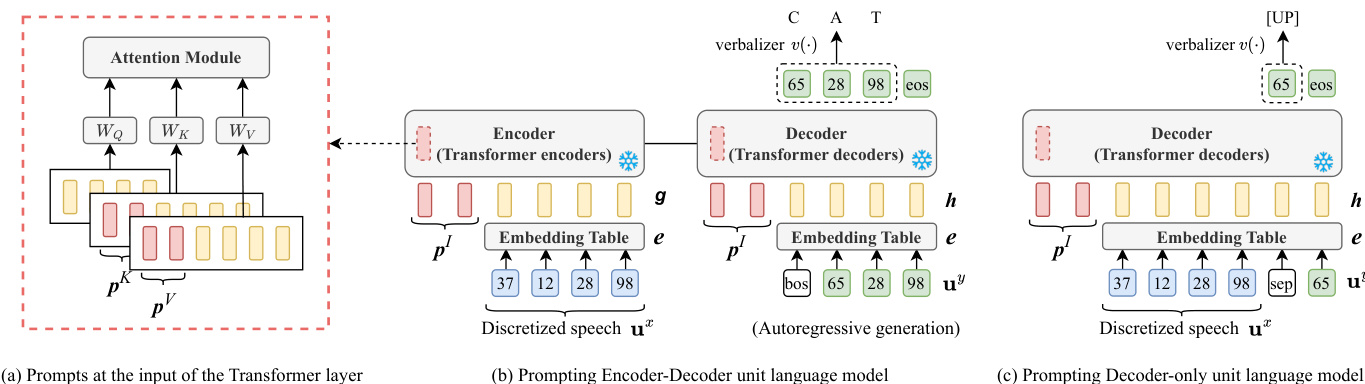
The framework reformulates various downstream tasks into a unified speech-to-unit generation task. For sequence generation tasks like automatic speech recognition (ASR), the model generates a sequence of discrete units that correspond to the target transcription. For speech classification tasks such as spoken command recognition (SCR), the model generates a single unit sequence, which is then mapped to a class label. For speech generation tasks, the generated unit sequence is synthesized back into a speech waveform using a pre-trained, off-the-shelf unit-to-speech decoder. The final output is obtained through a verbalizer or speech decoder. The verbalizer acts as a label-mapping module that connects the discrete units to the downstream task's labels. It can be a fixed mapping, such as a random or frequency-based heuristic, or a learnable module that is trained to find the optimal correspondence between units and labels. The learnable verbalizer, as shown in the figure below, uses a linear transformation to map the generated units to the final output, improving performance by learning the relevant associations. 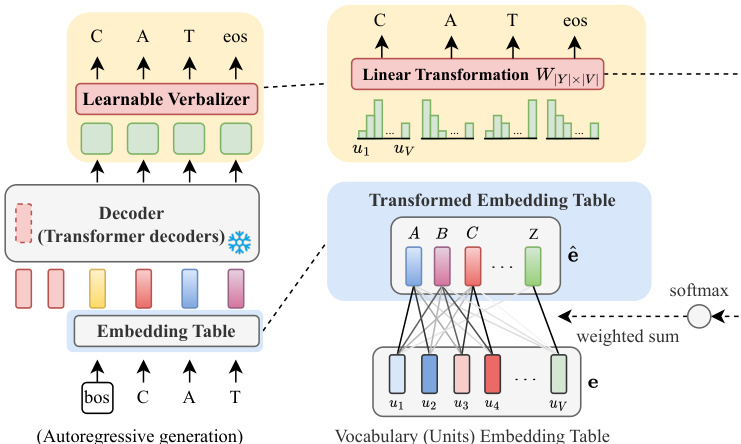
Experiment
The study evaluates the prompting paradigm against traditional pre-train and fine-tune approaches across speech classification, sequence generation, and speech generation tasks. Results indicate that prompting consistently matches or surpasses fine-tuning in classification tasks, particularly when utilizing learnable verbalizers. For sequence generation, outcomes are highly architecture-dependent, with decoder-only models struggling under prompting while encoder-decoder models achieve competitive or superior performance. Ultimately, prompting emerges as a robust and parameter-efficient alternative to fine-tuning, demonstrating strong viability for speech translation and continuation when paired with advanced encoder-decoder speech language models.
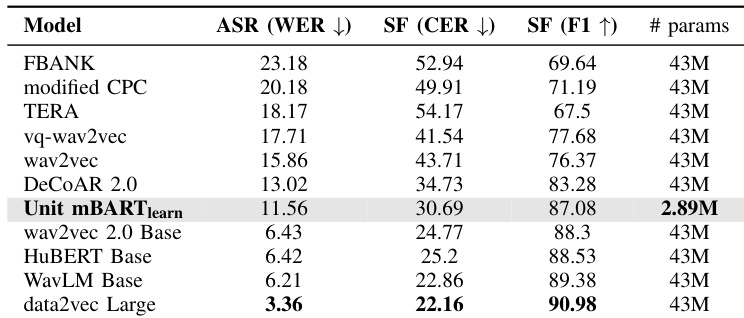
The authors compare the performance of different models on sequence generation tasks, focusing on automatic speech recognition and slot filling. Results show that the Unit mBART model with a learnable verbalizer achieves competitive results in both tasks, outperforming other models in slot filling while showing a slight drop in ASR compared to the best-performing model. The model with the learnable verbalizer has significantly fewer parameters than others, highlighting its efficiency. Unit mBART with a learnable verbalizer achieves high performance in slot filling while using fewer parameters than other models. The model shows competitive results in automatic speech recognition, though it slightly underperforms the best-performing model in this task. The learnable verbalizer enhances performance across multiple metrics, particularly in slot filling, with a significant improvement over the fixed verbalizer approach.
The authors compare the prompting paradigm with the pre-train, fine-tune paradigm across speech classification, sequence generation, and speech generation tasks. The results show that prompting generally performs competitively or better than fine-tuning for speech classification tasks, while for sequence generation, prompting with an encoder-decoder model achieves competitive results, but prompting a decoder-only model underperforms. In speech generation, prompting with an encoder-decoder model yields reasonable translations and diverse speech continuations, whereas other approaches fail to produce meaningful outputs. Prompting outperforms fine-tuning in most speech classification tasks, especially with encoder-decoder models. Prompting with an encoder-decoder model achieves competitive results in sequence generation, while prompting a decoder-only model underperforms significantly. Prompting enables reasonable speech translation and continuation, but other methods fail to produce meaningful outputs in speech generation tasks.
The authors compare the prompting paradigm with the pre-train, fine-tune paradigm across speech classification tasks, showing that prompting generally achieves competitive or superior performance. In most cases, prompting outperforms fine-tuning, particularly for certain models and datasets, with minimal differences in a few scenarios. Prompting often outperforms fine-tuning in speech classification tasks, especially for specific models and datasets. Performance differences between prompting and fine-tuning are minimal in some cases, with only slight variations observed. The prompting approach achieves competitive results across various datasets and models, with notable improvements in several scenarios.

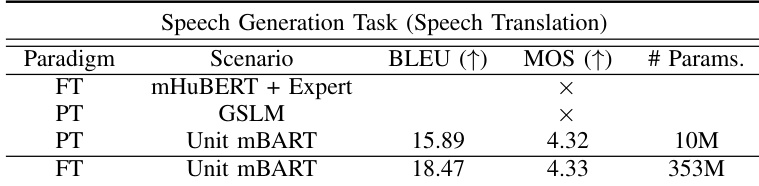
The authors compare the performance of prompting and fine-tuning paradigms for speech generation tasks, specifically speech translation. Results show that prompting Unit mBART achieves competitive translation quality with significantly fewer trainable parameters compared to fine-tuning the full model. In contrast, prompting GSLM and fine-tuning mHuBERT with an expert model do not yield reasonable results for this task. Prompting Unit mBART achieves competitive translation performance with substantially fewer parameters than fine-tuning the full model. Prompting GSLM and fine-tuning mHuBERT with an expert model fail to produce reasonable results for speech translation. Prompting Unit mBART demonstrates proficiency in speech translation, yielding a non-trivial BLEU score despite a performance drop compared to full fine-tuning.
The authors compare the performance of GSLM and Unit mBART in speech continuation tasks under different conditional rates. Results show that GSLM achieves lower perplexity than Unit mBART across all conditions, while Unit mBART produces more diverse and speaker-similar outputs compared to the original utterances. Both models yield comparable speech quality in terms of mean opinion score and speaker similarity. GSLM outperforms Unit mBART in perplexity across all conditional rates. Unit mBART generates outputs with higher diversity and speaker similarity compared to the original utterances. Both models achieve comparable speech quality in terms of mean opinion score and speaker similarity.

The experiments evaluate speech-language models and training paradigms across classification, sequence generation, translation, and continuation tasks, primarily contrasting parameter-efficient prompting against traditional fine-tuning. Results demonstrate that prompting generally matches or exceeds fine-tuning performance, particularly when using encoder-decoder architectures, while decoder-only variants struggle with sequence and speech generation. Model-specific analyses reveal that Unit mBART with a learnable verbalizer delivers highly efficient and accurate slot filling alongside competitive automatic speech recognition, whereas GSLM achieves lower perplexity in speech continuation compared to Unit mBART's superior output diversity and speaker similarity. Collectively, these findings establish that strategic architectural design and prompting-based training offer robust, parameter-efficient alternatives to full fine-tuning across diverse speech processing applications.