Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Comment entraîner un nouveau modèle de langage à partir de zéro avec des transformateurs et des tokenizers
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
The authors introduce the trial-and-demonstration (TnD) framework, an interactive paradigm that integrates student trials, teacher demonstrations, and competence-conditioned rewards to accelerate word acquisition from scratch for models of equal or smaller parameter counts, demonstrating that this approach outperforms non-interactive post-training methods, shows that teacher word selection influences word-specific learning efficiency, and reveals a practice-makes-perfect effect where trial frequency strongly correlates with learning curves.
Key Contributions
- A trial-and-demonstration (TnD) learning framework is introduced to simulate interactive language acquisition by integrating student trials, teacher demonstrations, and competence-conditioned rewards.
- Systematic experiments demonstrate that the TnD framework accelerates word acquisition, yielding faster learning curves for architectures with equal or fewer parameters than standard baselines.
- Controlled ablation studies isolate the distinct contributions of student trials and teacher demonstrations, while teacher-selected vocabulary modulates learning efficiency through a practice-makes-perfect effect where trial frequency strongly correlates with word-specific learning trajectories.
Introduction
Modern large language models are typically trained non-interactively on massive text corpora before receiving post-hoc alignment, which contrasts sharply with how humans efficiently acquire language through social interaction and corrective guidance. Prior computational studies have largely relied on passive learning setups, domain-specific constraints, or simple success metrics that lack explicit teacher demonstrations and targeted corrective feedback. The authors leverage a trial-and-demonstration framework to train neural language models from scratch through interactive loops of student generation, teacher correction, and a developmental-stage-conditioned reward signal. Their experiments demonstrate that this interactive paradigm significantly accelerates word acquisition, proving that structured practice and explicit demonstrations offer a more efficient alternative to traditional self-supervised pretraining.
Dataset

- Dataset Sources & Composition: The authors build their evaluation framework using two publicly available text corpora: BookCorpus and the BabyLM dataset.
- Subset Details & Filtering Rules: They construct two targeted vocabulary sets for assessment. The Common (CMN) set captures high-frequency words spanning diverse parts of speech across both corpora. The Communicative Development Inventories (CDI) set draws from standardized child language assessments. To ensure reliable evaluation, they exclude multi-word tokens that disrupt tokenization, remove words appearing fewer than 100 times in the evaluation splits, and cap each word at 512 instances. This results in 309 CMN words, 345 CDI words for BookCorpus, and 243 CDI words for BabyLM.
- Data Usage & Processing Pipeline: The authors reserve these subsets exclusively for evaluation rather than training. They compute mean surprisal to track prediction quality and plot learning curves across logarithmic training steps. To measure acquisition speed, they calculate the neural age of acquisition using surprisal thresholds from 0.50 to 0.95, then average the results for robustness. They also monitor effective vocabulary growth by counting words once their acquisition threshold is met.
- Additional Processing & Modeling Details: The workflow handles tokenizer constraints by strictly filtering compound items and relies on double-sigmoid curve fitting to capture learning plateaus. All metrics are derived from standardized surprisal calculations, and the evaluation splits are extracted directly from the original corpora without additional mixing or augmentation.
Method
The authors present a Trial-and-Demonstration (TnD) learning framework designed to simulate interactive language acquisition with corrective feedback in a human-free setting. This framework operates through a cycle of three key components: student model trials, teacher model demonstrations, and reward evaluation. The overall process begins with a student model, initialized as a randomly initialized GPT-2, which is prompted with the first five tokens of a sentence from a training corpus to generate a continuation. This generated text constitutes the student's trial. Concurrently, a teacher model, also based on the GPT-2 architecture and pre-trained with the causal language modeling (CLM) objective, is prompted with the same five tokens to produce a natural language demonstration. The student's trial and the teacher's demonstration are then evaluated by a reward model that assesses the developmental stage of the language output. This reward is derived from a neural age predictor, which estimates the training step at which a given text output typically emerges, and is adjusted by the current training step to form an age-conditioned reward. The framework alternates between interactive and non-interactive learning phases. In the non-interactive phase, the student model learns through standard causal language modeling, predicting the next token in a sequence to minimize the CLM loss. In the interactive phase, the student model is trained via reinforcement learning using the Proximal Policy Optimization (PPO) algorithm. The training batch for PPO includes both the student's trials and the teacher's demonstrations, allowing the student to learn from both its own outputs and the teacher's superior examples. The PPO algorithm employs a clipped surrogate objective and generalized advantage estimation to update the policy, with the value function trained via mean squared error. Notably, the KL-divergence penalty, common in reinforcement learning from human feedback, is omitted to encourage more significant updates and prevent over-adherence to a reference model. This alternating schedule, with three steps of causal language modeling followed by one step of reinforcement learning, is designed to emulate both passive language exposure and active, corrective learning. The entire process is illustrated in the framework diagram.
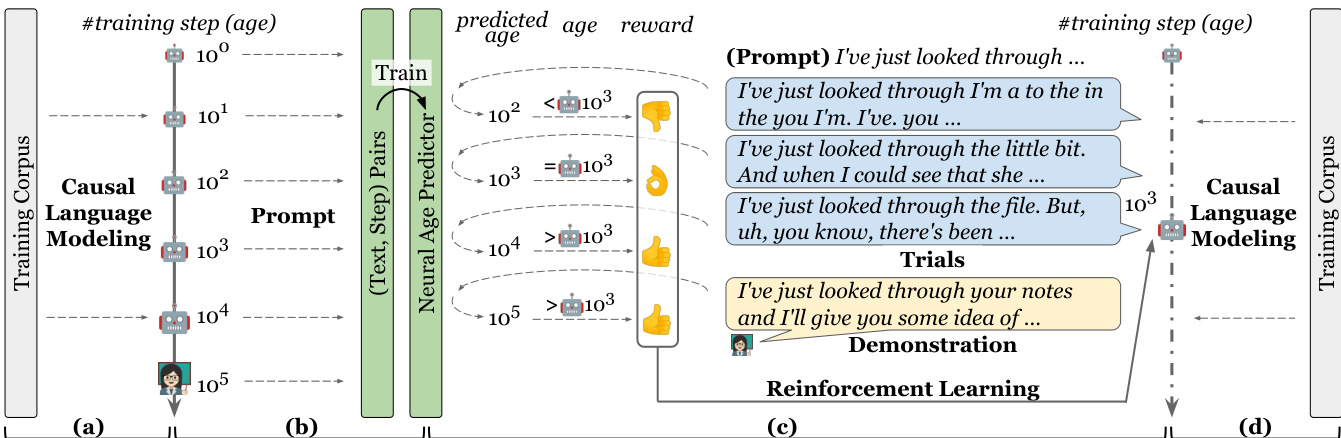
Experiment
Experiments conducted across two distinct training corpora evaluate a trial-and-demonstration framework against standard causal language modeling baselines to validate how corrective feedback, model scaling, and active practice influence neural word acquisition. The results demonstrate that combining student trials with teacher demonstrations significantly accelerates early-stage vocabulary learning, although final model capacity and downstream task performance eventually converge with standard pre-training. Further ablations confirm that both interactive trials and explicit demonstrations are essential for this accelerated learning, with active practice proving particularly beneficial for functional words and predicates. These findings validate that structured corrective feedback and iterative practice efficiently streamline word acquisition across varying model sizes while maintaining robust performance.
The authors compare the performance of different models on downstream natural language understanding tasks, using two training corpora. The results show that the TnD model achieves comparable or slightly better performance than the CLM model across most tasks, with notable improvements on some tasks and slight declines on others. The TnD model performs on par with the CLM model on most downstream NLU tasks. The TnD model shows a significant improvement on the Recognizing Textual Entailment task compared to the CLM model. The TnD model underperforms the CLM model on the Question-Answering NLI task.

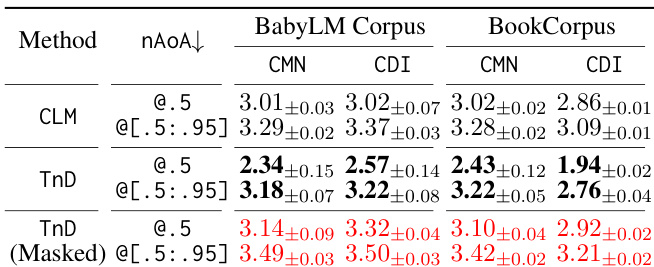
The authors analyze the neural age of acquisition (nAoA) across different surprisal thresholds to evaluate word learning efficiency in language models. Results show that the TnD framework significantly improves early-stage word acquisition compared to the CLM baseline, but the performance gap narrows as the learning process progresses, indicating convergence in long-term learning outcomes. The TnD model achieves faster learning in initial stages, particularly at lower surprisal thresholds, while both models eventually reach similar levels of vocabulary mastery. The TnD framework accelerates early word acquisition, showing significantly lower nAoA than the CLM baseline at lower surprisal thresholds. The performance gap between TnD and CLM narrows at higher surprisal thresholds, indicating eventual convergence in learning outcomes. TnD enables faster acquisition of words in the initial training phases, but both models reach comparable levels of mastery over time.
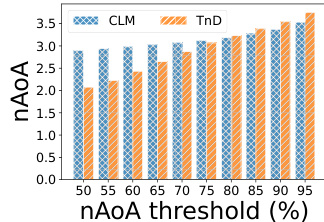
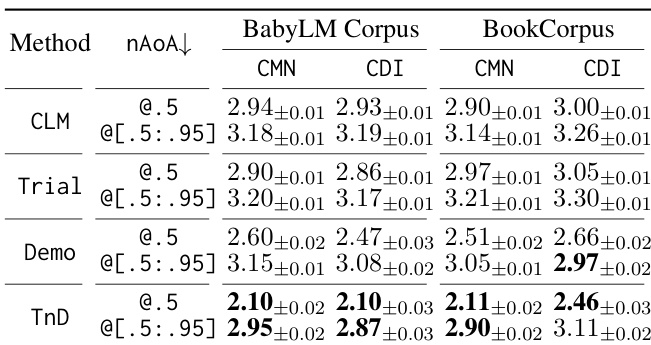
The authors compare different learning frameworks on two corpora and two test vocabularies, evaluating their impact on word acquisition through learning curves, neural age of acquisition, and effective vocabulary size. Results show that the TnD framework accelerates early word learning compared to baselines, particularly in terms of acquisition speed and vocabulary growth, though performance converges over time. The findings are consistent across different model sizes and training conditions, highlighting the importance of corrective feedback in language learning. The TnD framework accelerates early word acquisition compared to baseline models. The TnD model shows faster vocabulary growth in the initial training stages but converges with baselines over time. The benefits of the TnD framework are consistent across different model sizes and training corpora.
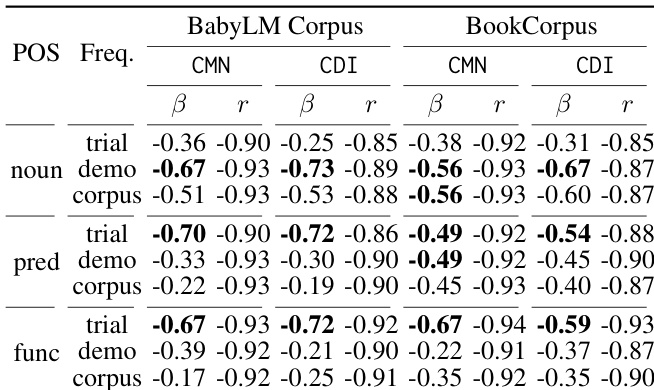
The authors analyze the contribution of different sources of word exposure—student trials, teacher demonstrations, and corpus frequency—to word acquisition in neural language models, focusing on how these sources correlate with learning curves across different parts of speech. They find that the frequency of words in student trials has a significant negative correlation with surprisal, particularly for functional words and predicates, indicating that active practice plays a key role in learning these word types. This effect is less pronounced for nouns, suggesting that different learning mechanisms may be at play depending on word category. The frequency of words in student trials significantly correlates with learning curves, especially for functional words and predicates. The contribution of trials to word acquisition varies by part of speech, with stronger effects observed for functional words and predicates than for nouns. Teacher demonstrations and corpus frequency show weaker and more collinear relationships with learning compared to trials.
The authors compare the performance of different language models on two corpora, evaluating word acquisition using neural age of acquisition and effective vocabulary size. The TnD model shows improved early learning compared to the CLM baseline, particularly in the BabyLM Corpus, but the performance differences diminish as training progresses. The masked version of the TnD model demonstrates further improvements in early acquisition metrics across both corpora. The TnD model accelerates early word acquisition compared to the CLM baseline, especially on the BabyLM Corpus. The performance gap between TnD and CLM narrows over time, with convergence in later stages of training. The masked TnD variant achieves better early acquisition metrics than both the standard TnD and CLM models.
The experiments evaluate the TnD framework against standard language model baselines across multiple corpora, downstream natural language understanding tasks, and word acquisition metrics to assess learning efficiency and long-term mastery. The downstream task evaluations validate that TnD matches or slightly improves baseline performance with notable task-specific variations, while the acquisition analyses confirm that the framework significantly accelerates early vocabulary growth and learning speed. These findings demonstrate that active student trials drive initial language acquisition, particularly for functional words and predicates, though performance gradually converges with baselines over extended training. Ultimately, the results indicate that targeted early-stage feedback enhances initial learning efficiency without altering final proficiency outcomes.