Command Palette
Search for a command to run...
Une étude en zéro-shot et few-shot des grands modèles de langage finetunés sur instruction appliqués aux tâches cliniques et biomédicales
Une étude en zéro-shot et few-shot des grands modèles de langage finetunés sur instruction appliqués aux tâches cliniques et biomédicales
Yanis Labrak Mickael Rouvier Richard Dufour
Modèles de langage à grande échelle, programmation par prompts et tâches few-shot
Résumé
L'émergence récente des grands modèles de langage (LLM) a permis des avancées significatives dans le domaine du traitement automatique des langues (NLP). Bien que ces nouveaux modèles aient démontré des performances supérieures sur diverses tâches, leur application et leur potentiel restent encore peu explorés, tant en termes de diversité des tâches qu'ils peuvent traiter que de leur domaine d'application. Dans ce contexte, nous évaluons quatre LLM de pointe ajustés par instruction (ChatGPT, Flan-T5 UL2, Tk-Instruct et Alpaca) sur un ensemble de 13 tâches réelles de NLP clinique et biomédical en anglais, incluant la reconnaissance d'entités nommées (NER), la réponse aux questions (QA), l'extraction de relations (RE), et d'autres. Nos résultats globaux montrent que ces LLM évalués approchent les performances des modèles de pointe dans des scénarios zero-shot et few-shot pour la plupart des tâches, se distinguant particulièrement dans la tâche QA, bien qu'ils n'aient jamais rencontré d'exemples de ces tâches auparavant. Cependant, nous observons également que les tâches de classification et de RE sont inférieures aux performances réalisables avec des modèles spécifiquement entraînés conçus pour le domaine médical, tels que PubMedBERT. Enfin, nous notons qu'aucun LLM unique ne surpasse tous les autres sur l'ensemble des tâches étudiées, certains modèles s'avérant plus adaptés à certaines tâches qu'à d'autres.
One-sentence Summary
Evaluating four instruction-tuned large language models (ChatGPT, Flan-T5 UL2, Tk-Instruct, and Alpaca) across thirteen English clinical and biomedical NLP tasks reveals that while these models approach state-of-the-art zero- and few-shot performance, particularly in question answering, they underperform domain-specific architectures like PubMedBERT in classification and relation extraction and demonstrate that no single model outperforms all others across the evaluated tasks.
Key Contributions
- This study evaluates four instruction-tuned large language models (ChatGPT, Flan-T5 UL2, Tk-Instruct, and Alpaca) across thirteen clinical and biomedical natural language processing tasks under zero- and few-shot conditions.
- A novel Recursive Chain-of-Thought (RCoT) prompting strategy is introduced to sequentially enrich input instructions, enabling named-entity recognition across diverse model architectures.
- Empirical analysis demonstrates that general-purpose models achieve competitive performance on most biomedical tasks, though they underperform domain-specialized architectures like PubMedBERT in classification and relation extraction while exhibiting distinct task-specific capabilities.
Introduction
The medical domain increasingly relies on natural language processing to analyze complex clinical records, yet deploying advanced models in healthcare remains difficult due to scarce, sensitive datasets and the high cost of expert annotation. Traditional masked language models require extensive labeled data and struggle with cross-task generalization, while prior evaluations of large language models in medicine have been limited to narrow task sets and non-standard automatic metrics. The authors address these gaps by benchmarking four instruction-tuned models across thirteen real-world clinical and biomedical tasks. They evaluate zero- and few-shot capabilities against a fine-tuned PubMedBERT baseline using standard accuracy and F1 scores. Furthermore, the authors introduce Recursive Chain-of-Thought prompting, a novel technique that sequentially enriches prompts to mimic human reasoning and enable named entity recognition across diverse large language model architectures.
Dataset
Dataset Composition and Sources
- The authors use five scientific and medical NLP datasets: MedMCQA, GAD, SciTail, HoC, and DEFT-2020. These sources span multiple-choice question answering, relation extraction, natural language inference, cancer hallmark classification, and semantic textual similarity.
Key Details for Each Subset
- MedMCQA provides science questions with four lettered options requiring single-character answers.
- GAD contains statements for gene-disease relation extraction, classified as positive or negative.
- SciTail offers premise-hypothesis pairs for natural language inference, labeled as entails or neutral.
- HoC documents are annotated with one or more of ten predefined cancer hallmarks or marked as none.
- DEFT-2020 Task 1 functions as the semantic textual similarity benchmark.
- The provided excerpts do not specify exact dataset sizes or training mixture ratios.
Data Usage and Processing
- The authors convert all subsets into structured instruction prompts for ChatGPT and Flan-T5 UL2.
- Each task is evaluated using both zero-shot and five-shot configurations.
- Raw class labels are manually optimized through trial and error to align with model expectations, such as changing entailment to entails for measurable performance gains.
- Strict output constraints are enforced across all prompts to prohibit justifications and guarantee format compliance.
Metadata and Additional Processing
- The authors inject standardized entity placeholders like @GENEand@DISEASE into the GAD inputs to streamline relation extraction.
- No cropping strategies or complex metadata construction pipelines are detailed in the provided text.
Method
The authors leverage a few-shot learning framework during inference, where a small number of task examples are provided as conditioning without updating the model's weights. These examples typically consist of an instruction, context, and desired completion, such as a premise, hypothesis, and corresponding label for natural language inference (NLI) tasks. The few-shot technique involves presenting the model with k examples of context and completion, followed by a final example of context for which the model must generate the completion. The value of k generally ranges from 3 to 100, constrained by the model’s context window size—Flan-UL2, for instance, supports up to 2,048 tokens.
To enhance few-shot performance beyond randomly selected examples, a retrieval-based module is introduced using Sentence-Transformers (Reimers and Gurevych, 2019). This module retrieves the k most semantically similar examples from the training set. The process begins by embedding each instruction prompt in the training set into a vector space using a fixed PubMedBERT (Gu et al., 2021) model. For a given test instance, the query is compared to all training examples via cosine distance, and the top k closest examples are selected. In the implementation, k is set to 5.
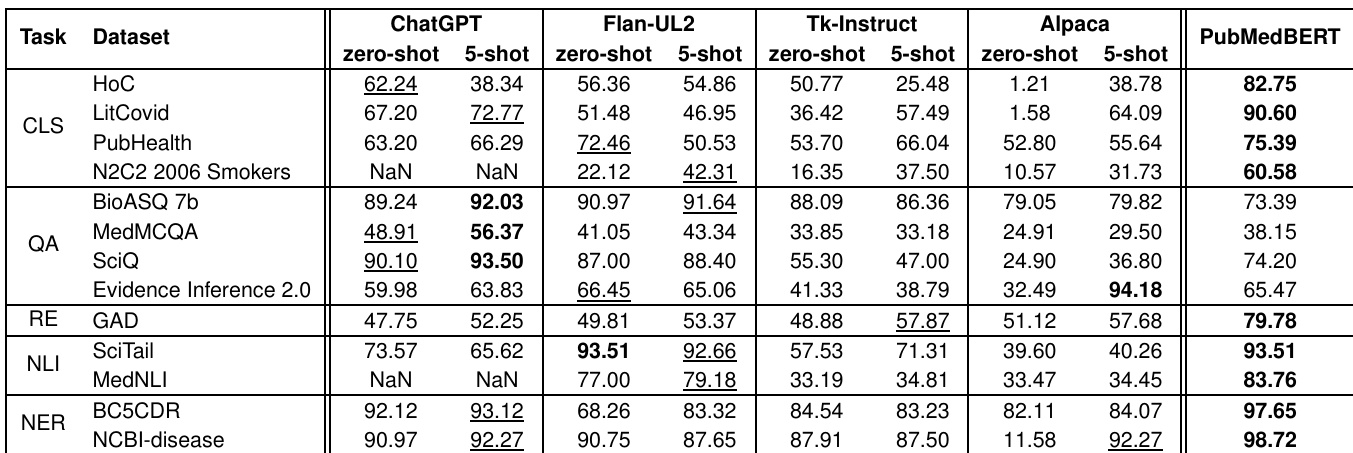
The input instruction prompt is constructed by concatenating three components: an instruction that specifies the task, describes the data, and outlines the expected model behavior; the input argument containing relevant information; and constraints on the output space to guide generation. This structured format improves model performance across diverse tasks.
For named entity recognition (NER), two inference methods are evaluated. The first, adapted from Ye et al. (2023), is applicable only to ChatGPT and uses a format where words are separated by double vertical bars and labels by single vertical bars. The second method, introduced as Recursive Chain-of-Thought (RCoT), is more general and works across all tested generative models. RCoT extends the Chain-of-Thought (CoT) framework (Wei et al., 2022b) and builds upon Wang et al. (2022b). It operates by iteratively processing each token in the sequence, using the current prediction state as input to generate the label for the next token. This ensures that every token receives a label and prevents omissions during generation. However, the method incurs a high computational cost due to its ON complexity, where N is the number of tokens in the sequence, in contrast to the O1 complexity of the ChatGPT-specific method.
An example of the RCoT prompt format includes a detailed instruction, constraints, and a set of five few-shot examples, followed by the current sentence and a query about the label of a specific token. This approach ensures precise entity labeling while maintaining consistency with the model’s reasoning process.
Experiment
The experimental setup evaluates four instruction-tuned large language models against a biomedical baseline across thirteen clinical and natural language processing tasks using zero- and few-shot prompting protocols. This evaluation validates the generalization capacity of generic models in specialized medical domains, revealing that while few-shot learning effectively mitigates hallucinations and boosts overall accuracy, the models still lag behind task-specific architectures in classification and relation extraction. Consequently, the findings conclude that question answering is the most reliable application for current LLMs, and since no single model excels across all tasks, practitioners must carefully match model capabilities to specific clinical requirements.
The authors evaluate multiple large language models on a range of clinical and biomedical tasks, including classification, question answering, relation extraction, and named entity recognition. Results indicate that while generative models perform well on question-answering tasks, they fall short on classification and relation extraction compared to domain-specific models, with performance varying significantly across tasks and models. Generative models perform better than domain-specific models on question-answering tasks in zero-shot settings. Classification and relation extraction tasks show inferior performance for generative models compared to specialized models. Performance varies across models, with some excelling in certain tasks while underperforming in others.
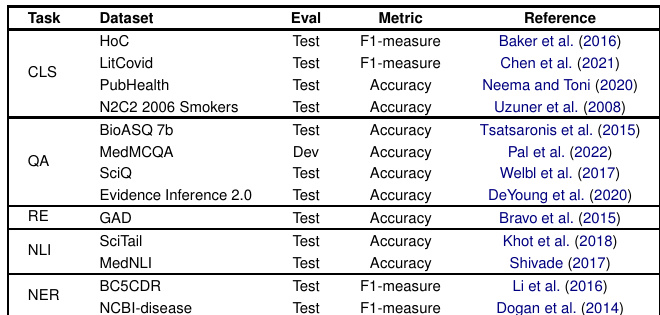
The authors evaluate multiple large language models on a range of clinical and biomedical tasks, comparing their performance in zero-shot and few-shot settings against a biomedical-specific model. Results show that generative models perform well on question-answering tasks, particularly in few-shot scenarios, while their performance on classification and relation extraction tasks remains limited compared to specialized models. Generative models achieve strong performance on question-answering tasks, especially in few-shot settings, outperforming specialized models in some cases. Classification and relation extraction tasks show consistently lower performance for generative models compared to the biomedical-specific baseline. Alpaca demonstrates significant improvement in few-shot scenarios across all tasks, indicating high adaptability to new instructions.
The study evaluates multiple large language models across clinical and biomedical tasks, including classification, question answering, and relation extraction, using both zero-shot and few-shot settings against a domain-specific baseline. These experiments validate the comparative effectiveness of generative versus specialized architectures across diverse task types and prompting conditions. Qualitatively, generative models demonstrate strong capabilities in question answering, particularly when leveraging few-shot examples, but consistently lag behind specialized models on classification and relation extraction tasks. Overall, performance proves highly task-dependent, with certain architectures like Alpaca exhibiting notable adaptability and improvement in few-shot scenarios.